python知识点记录
目录
1、get和post是两个不同的请求体,get直接简单,但不安全,post有一层包装,更安全。
2、一个测试服务器实例代码:
3、HTTP请求格式:
5、json格式化快捷方式
6、referer反爬
7、Pycharm快捷方式:
8、Cookie反爬,这里是指静态Cookie,动态的爬不了
9、get请求参数
10、post请求体
11、爬图片和视频
12、m3u8网页视频爬取方法
13、滑动验证工具
14、cmd退出命令:exit()
15、动行记事本,py的文件方法:
16、浏览器分析,network就是浏览器的一个抓包工具
17、requests发送get请求:
18、resquests发送post请求:
19、测验爬取肯德基餐厅位置信息
20、正则表达式-上
21、正则表达式下:
22、正则表达式实例 -爬虫中经常用到的正则表达式
23、查看python的请求头
编辑
24、re.S 可以让re匹配到换行符
25、去掉空格、换行符、制表符
26、正则表达式使用方法,resp.encoding = 'utf-8'
27、将数据写入文件。2023.12.05
28、python中的url循环,for循环
1、get和post是两个不同的请求体,get直接简单,但不安全,post有一层包装,更安全。
get请求,没有请求体,POST请求有请求体。
2、一个测试服务器实例代码:
import socket
sock =socket.socket()
sock.bind(("127.0.0.1",8080))
sock.listen(5)
while 1:
conn,addr = sock.accept()
data = conn.recv(1024)
print('data:::',data)
conn.send(b'HTTPS/1.1 200 OK\r\n\r\n1111')
在浏览器里面输入:127.0.0.1:8080即可访问,并返回:1111.

3、HTTP请求格式:

4、反爬机制三要素:UA,cookie,referer
5、json格式化快捷方式
6、referer反爬
import requests
my_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36",
'Referer': 'https://movie.douban.com/explore'
}
url = 'https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%22%E7%B1%BB%E5%9E%8B%22:%22%E7%8A%AF%E7%BD%AA%22%7D&uncollect=false&tags=%E7%8A%AF%E7%BD%AA'
res = requests.get(url,headers=my_headers)
print(res.text)7、Pycharm快捷方式:
ctrl+/ 注释代码
8、Cookie反爬,这里是指静态Cookie,动态的爬不了
import requests
url = "https://stock.xueqiu.com/v5/stock/screener/quote/list.json?type=sha&order_by=percent&order=desc&size=10&page=1"
my_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36",
'Referer': 'https://xueqiu.com/hq',
"Cookie": "s=ce1691zr64; xq_a_token=cf755d099237875c767cae1769959cee5a1fb37c; xq_r_token=e073320f4256c0234a620b59c446e458455626d9; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTcwMTk5NTg4MCwiY3RtIjoxNzAwNDgyODU2MTUwLCJjaWQiOiJkOWQwbjRBWnVwIn0.ahoNtkL30exAv-5UuI6_lC0iGfIhaH70FLFI1Z9A8TlVG3dXxDPHnT43IJo36pwmd6s9kGAIHlz7IU-f1bWQ5czH6W77as69qG6OThYTUVatXS0bvBVBVS-uzMSmXWvweqSPjFKAJHaHQH38F8SfjssNYXbEyGwXp2XfdieueRrgZVdjPwZ-sgczrolrJg-K-3XYa87gtcLzmM9vl5_8aKfsyUt5XTiSFADNQe-31aj8lm-ciiYHqabPsS19y8Gv9k2UMknYCEwaZlwc4_HUxU4BNgIqk1CU3cVVykeom5V3ggQ-W10OCzUkArX-fp26VjctK0cvKJNHDQF7_DnGVA; cookiesu=771700482860303; u=771700482860303; device_id=5196ccf1e7f4009737785bc93860f84e; Hm_lvt_1db88642e346389874251b5a1eded6e3=1700482887; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1700482936"
}
res = requests.get(url,headers=my_headers)
print(res.text)9、get请求参数
import requests
my_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36",
'Referer': 'https://movie.douban.com/explore'
}
url = 'https://m.douban.com/rexxar/api/v2/movie/recommend'
tags = input('请输入电影类型:'),
print(tags)
my_params = {
'start': 0,
'count': 60,
'tags': tags
}
res = requests.get(url,headers=my_headers,params=my_params)
# params是get请求参数
# print(res.text)
print(res.json())10、post请求体
import requests
rul = 'https://aidemo.youdao.com/trans'
# 有道智云网站
word = input('请输入要翻译的单词:')
my_data = {
'q': word,
'from': 'Auto',
'to': 'Auto'
}
res = requests.post(rul,data=my_data)
# data是POST的请求体
print(res.json().get('translation'))11、爬图片和视频
import requests
url = 'http://img.netbian.com/file/2023/1113/224050jZgYd.jpg'
my_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36",
}
res = requests.get(url,headers=my_headers)
print(res.content)
with open('1.png','wb') as f:
f.write(res.content)
# 这里需要注意:1.b换成wb 2.res.test换成res.content。 视频也一样。12、m3u8网页视频爬取方法

13、滑动验证工具

14、cmd退出命令:exit()
15、动行记事本,py的文件方法:

16、浏览器分析,network就是浏览器的一个抓包工具

17、requests发送get请求:
import requests
# 爬取百度页面
url = 'https://www.baidu.com'
# 发送请求
resq = requests.get(url)
# 设置字符集
resq.encoding = 'utf-8'
print(resq.text) #拿到页面源代码
# 把页面源代码写入到文件
with open('mybaidu.html',mode='w',encoding='utf-8') as f:
f.write(resq.text)
print('over!!')18、resquests发送post请求:
import requests
url ='https://fanyi.baidu.com/sug'
header={
'Cookie':'BIDUPSID=46CEC11AD82217D4BB76C43C2F4B7DEB; PSTM=1693228328; BAIDUID=46CEC11AD82217D46EFB562AB1C5A2D0:FG=1; BAIDUID_BFESS=46CEC11AD82217D46EFB562AB1C5A2D0:FG=1; ZFY=ZnJ:BM9C6:BBdfAVKWMTeuOSeLr5OAEtVLTi7EQRUgyms:C; H_PS_PSSID=39633_39671_39663_39695_39676_39678_39712_39738_39779_39789_39703_39674_39687; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1701087393; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1701087393; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; ab_sr=1.0.1_OGMwNTA2NWFlYjdlYjQxMzNhNjYzYmY3YzEyZDZmMzI2MzhiNTlhNTRjMzEwZmQyZDEzYTYyM2ZjMGU2ZDJiMDNlMjJmNDFhZmE0ZDZkOGM0YmUzMzkxOTAwZGExZWUyYzQ5NWY4ZDVmYmU1YjgwZTNhMDA1MDE4MDlkYmQwODkyZTE4YTA4NjJiMTdiYzFhZjc2MDMxNzhiZDI3YzkzNg==',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
'Referer':'https://fanyi.baidu.com/'
}
data={
# 'kw':'apple'
'kw':input('请输入你想查询的内容:')
}
resq=requests.post(url,headers=header,data=data)
# print(resq.text)
print(resq.json()) #直接拿到json数据19、测验爬取肯德基餐厅位置信息
import requests
url='https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
data={
'cname':'',
'pid':'',
'keyword': '黄浦区',
'pageIndex': 1,
'pageSize': 10
}
resq=requests.post(url,data=data)
print(resq.json())20、正则表达式-上

21、正则表达式下:

22、正则表达式实例 -爬虫中经常用到的正则表达式

23、查看python的请求头

24、re.S 可以让re匹配到换行符

25、去掉空格、换行符、制表符

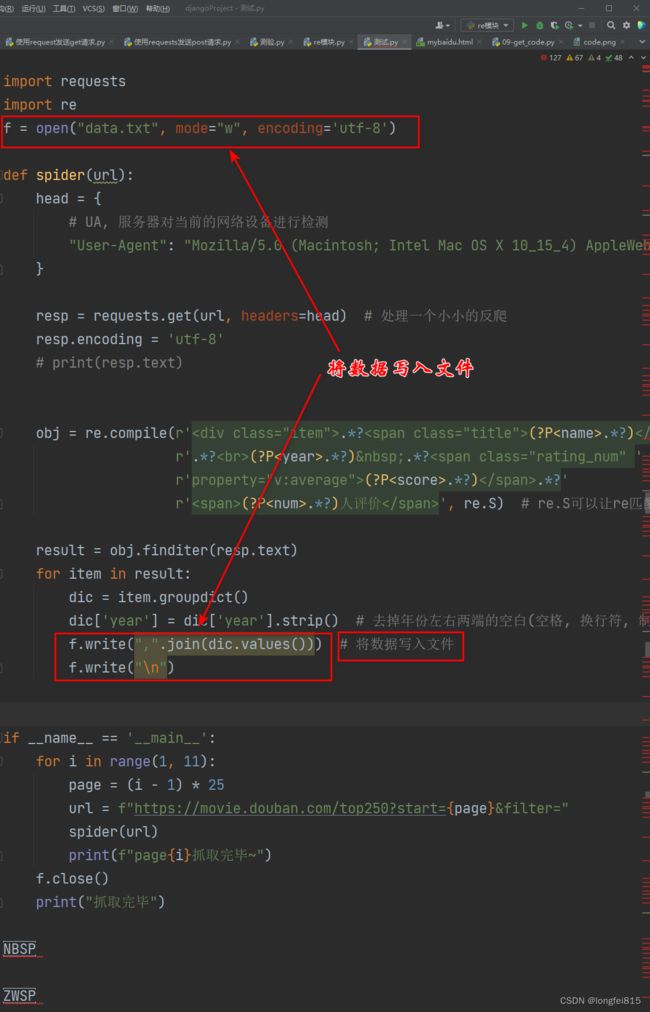
26、正则表达式使用方法,resp.encoding = 'utf-8'
import requests
import re
f = open("data.txt", mode="w", encoding='utf-8')
def spider(url):
head = {
# UA, 服务器对当前的网络设备进行检测
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"
}
resp = requests.get(url, headers=head) # 处理一个小小的反爬
resp.encoding = 'utf-8'
# print(resp.text)
obj = re.compile(r'.*?(?P.*?) '
r'.*?
(?P.*?) .*?.*?'
r'(?P.*?)人评价 ', re.S) # re.S可以让re匹配到换行符
result = obj.finditer(resp.text)
for item in result:
dic = item.groupdict()
dic['year'] = dic['year'].strip() # 去掉年份左右两端的空白(空格, 换行符, 制表符)
f.write(",".join(dic.values())) # 将数据写入文件
f.write("\n")
if __name__ == '__main__':
for i in range(1, 11):
page = (i - 1) * 25
url = f"https://movie.douban.com/top250?start={page}&filter="
spider(url)
print(f"page{i}抓取完毕~")
f.close()
print("抓取完毕")

27、将数据写入文件。2023.12.05
28、python中的url循环,for循环

29、etree的两种导入方法
