【计算机视觉|生成对抗】StackGAN:使用堆叠生成对抗网络进行文本到照片逼真图像合成
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处
标题:StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
链接:[1612.03242] StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks (arxiv.org)
摘要
从文本描述合成高质量图像是计算机视觉中的一个具有挑战性的问题,具有许多实际应用。现有的文本到图像方法生成的样本大致能够反映出给定描述的意思,但它们缺乏必要的细节和生动的物体部分。在本文中,我们提出了堆叠生成对抗网络(StackGAN)来生成基于文本描述的 256×256 照片逼真图像。我们通过一个素描精化过程将这个难题分解为更易管理的子问题。第一阶段生成对抗网络(Stage-I GAN)根据给定的文本描述勾勒出物体的原始形状和颜色,生成第一阶段的低分辨率图像。第二阶段生成对抗网络(Stage-II GAN)以第一阶段的结果和文本描述作为输入,生成带有照片逼真细节的高分辨率图像。它能够通过精化过程矫正第一阶段结果中的缺陷,并添加引人注目的细节。为了提高合成图像的多样性并稳定条件生成对抗网络的训练,我们引入了一种新颖的条件增强技术,鼓励在潜在条件空间中的平滑性。在基准数据集上进行的大量实验和与最先进方法的比较表明,所提出的方法在基于文本描述生成照片逼真图像方面取得了显著的改进。
1. 引言
从文本生成逼真的图像是一个重要的问题,具有广泛的应用,包括照片编辑、计算机辅助设计等。近年来,生成对抗网络(GAN)[8, 5, 23] 在合成真实世界图像方面取得了有希望的结果。在给定文本描述的条件下,条件生成对抗网络(conditional GANs)[26, 24] 能够生成与文本意义高度相关的图像。
然而,通过文本描述训练GAN生成高分辨率逼真图像是非常困难的。仅仅在最先进的GAN模型中添加更多的上采样层用于生成高分辨率(例如 256×256)图像通常会导致训练不稳定并产生荒谬的输出(见图1©)。GAN生成高分辨率图像的主要困难在于自然图像分布的支持和隐含模型分布的支持在高维像素空间中可能不重叠[31, 1]。随着图像分辨率的增加,这个问题变得更加严重。Reed等人仅在给定文本描述的情况下成功生成了可信的 64×64 图像[26],但这些图像通常缺乏细节和生动的物体部分,例如鸟类的嘴和眼睛。此外,他们无法在不提供额外物体注释的情况下合成更高分辨率(例如 128×128)的图像[24]。
图1。比较所提出的 StackGAN 与普通的单阶段 GAN 生成 256×256 图像的效果。(a)在给定文本描述的情况下,StackGAN 的第一阶段勾画出对象的粗略形状和基本颜色,生成低分辨率图像。(b)StackGAN 的第二阶段以第一阶段的结果和文本描述作为输入,生成带有逼真细节的高分辨率图像。(c)普通的 256×256 GAN 的结果,它仅仅在现有的 GAN-INT-CLS [26] 的基础上添加了更多的上采样层。它无法生成任何具有 256×256 分辨率的可信图像。

类比于人类画家的绘画方式,我们使用堆叠生成对抗网络(StackGAN)将文本到逼真图像合成问题分解为两个更易处理的子问题。首先,低分辨率图像由第一阶段生成对抗网络(Stage-I GAN)生成(见图1(a))。在第一阶段生成对抗网络的基础上,我们堆叠第二阶段生成对抗网络(Stage-II GAN),以生成基于第一阶段结果和文本描述的逼真高分辨率(例如 256×256)图像(见图1(b))。通过再次基于第一阶段结果和文本描述进行条件化,第二阶段生成对抗网络学会捕捉第一阶段生成对抗网络遗漏的文本信息,并为物体绘制更多细节。从大致对齐的低分辨率图像生成的模型分布支持更可能与图像分布的支持交叉。这就是为什么第二阶段生成对抗网络能够生成更好的高分辨率图像的根本原因。
此外,在文本到图像生成任务中,有限数量的训练文本-图像对往往导致文本条件空间中的稀疏性,这种稀疏性使得训练GAN变得困难。因此,我们提出了一种新颖的条件增强技术,以鼓励潜在条件空间的平滑性。它允许在条件空间中进行小的随机扰动,并增加合成图像的多样性。
所提出方法的贡献有三个方面:
- 我们提出了一种新颖的堆叠生成对抗网络,用于从文本描述合成逼真的图像。它将生成高分辨率图像的困难问题分解为更易管理的子问题,并显著改进了现有技术水平。StackGAN首次能够从文本描述中生成具有逼真细节的 256×256 分辨率图像。
- 提出了一种新的条件增强技术,用于稳定条件生成对抗网络的训练,同时也提高了生成样本的多样性。
- 大量的定性和定量实验证明了整体模型设计的有效性,以及各个组件的效果,这为设计未来的条件生成对抗网络模型提供了有用的信息。我们的代码可在 https://github.com/hanzhanggit/StackGAN 上获取。
2. 相关工作
生成图像模型是计算机视觉中的一个基本问题。随着深度学习技术的出现,这方向取得了显著的进展。变分自编码器(VAE)[13, 28] 使用概率图模型来制定问题,其目标是最大化数据似然的下界。自回归模型(例如,PixelRNN)[33] 利用神经网络来建模像素空间的条件分布,也生成了吸引人的合成图像。最近,生成对抗网络(GAN)[8] 在生成更锐利的图像方面表现出有希望的性能。但是,训练不稳定性使得GAN模型难以生成高分辨率(例如 256×256)图像。已经提出了几种技术[23, 29, 18, 1, 3] 来稳定训练过程并生成引人注目的结果。基于能量的GAN[38] 也被提出用于更稳定的训练行为。
在这些生成模型的基础上,还研究了条件图像生成。大多数方法使用简单的条件变量,如属性或类标签[37, 34, 4, 22]。还有以图像为条件生成图像的工作,包括照片编辑[2, 39]、域转移[32, 12] 和超分辨率[31, 15]。然而,超分辨率方法[31, 15] 只能对低分辨率图像添加有限的细节,无法像我们提出的StackGAN那样纠正大的缺陷。近期,已经开发了几种从非结构化文本生成图像的方法。Mansimov等人[17] 构建了一个AlignDRAW模型,通过学习估计文本和生成画布之间的对齐。Reed等人[27] 使用条件PixelCNN根据文本描述和物体位置约束生成图像。Nguyen等人[20] 使用近似的Langevin采样方法生成基于文本的图像。然而,他们的采样方法需要一个低效的迭代优化过程。通过条件GAN,Reed等人[26] 成功地基于文本描述为鸟类和花朵生成了可信的 64×64 图像。他们的后续工作[24] 能够通过利用物体部位位置的额外注释生成 128×128 图像。
除了使用单个GAN生成图像外,还有一些工作[36, 5, 10] 使用一系列GAN来生成图像。Wang等人[36] 使用提出的 S 2 − G A N S^2-GAN S2−GAN,将室内场景生成过程分解为结构生成和样式生成。相反,我们的StackGAN的第二阶段旨在基于文本描述完善物体细节并矫正第一阶段结果的缺陷。Denton等人[5] 在拉普拉斯金字塔框架内构建了一系列GAN。在金字塔的每个层级中,基于前一阶段的图像条件生成了一个剩余图像,然后将其添加回输入图像,生成下一阶段的输入。与我们的工作同时进行,Huang等人[10] 也展示了通过堆叠多个GAN来重构预训练鉴别模型的多级表示,从而生成更好的图像。然而,他们只成功地生成了 32×32 图像,而我们的方法利用了更简单的架构,生成了具有逼真细节的 256×256 图像,像素数量增加了64倍。
3. 堆叠生成对抗网络
为了生成具有逼真细节的高分辨率图像,我们提出了一个简单但有效的堆叠生成对抗网络(Stacked GANs)。它将文本到图像生成过程分解为两个阶段(见图2)。
图2。所提出的 StackGAN 的架构。第一阶段生成器通过从给定的文本勾画出对象的粗略形状和基本颜色,并从随机噪声向量中绘制背景来生成低分辨率图像。在第一阶段的结果的条件下,第二阶段生成器修复缺陷并将引人注目的细节添加到第一阶段的结果中,从而生成更加逼真的高分辨率图像。
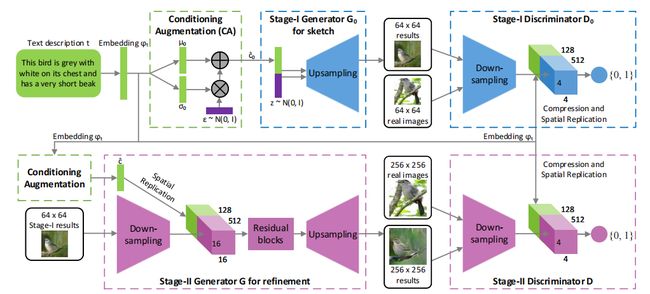
- 第一阶段生成对抗网络(Stage-I GAN):它根据给定的文本描述勾勒出物体的原始形状和基本颜色,并从随机噪声向量中生成背景布局,生成低分辨率图像。
- 第二阶段生成对抗网络(Stage-II GAN):它纠正了第一阶段低分辨率图像中的缺陷,并通过再次读取文本描述来完善物体的细节,生成高分辨率照片逼真的图像。
3.1. 预备知识
生成对抗网络(GAN)[8] 由两个模型组成,它们交替训练以相互竞争。生成器 G 优化以重现真实数据分布 pdata,通过生成对判别器 D 难以与真实图像区分的图像。与此同时,判别器 D 优化以区分真实图像和生成器 G 生成的合成图像。整体而言,训练过程类似于一个两人零和博弈,其目标函数如下:
min G max D V ( D , G ) = E x ∼ p data [ log D ( x ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] (1) \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)] + \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))] \tag{1} GminDmaxV(D,G)=Ex∼pdata[logD(x)]+Ez∼pz[log(1−D(G(z)))](1)
其中 x x x 是来自真实数据分布 p d a t a p_{data} pdata 的真实图像, z z z 是从分布 p z p_z pz(例如均匀分布或高斯分布)中采样的噪声向量。
条件生成对抗网络(Conditional GAN)[7, 19] 是GAN的一个扩展,其中生成器和判别器都接收额外的条件变量 c c c,得到 G ( z , c ) G(z, c) G(z,c) 和 D ( x , c ) D(x, c) D(x,c)。这种表述允许生成器 G 基于变量 c c c 生成图像。
3.2. 条件增强
如图2所示,首先通过编码器对文本描述 t t t 进行编码,得到文本嵌入 ϕ t \phi_t ϕt。在以前的工作中[26, 24],文本嵌入被非线性地转化为生成器的输入条件潜变量。然而,文本嵌入的潜在空间通常是高维的(> 100维)。在有限数量的数据情况下,它通常会导致潜在数据流形中的不连续性,这对于学习生成器是不可取的。为了缓解这个问题,我们引入了一种“条件增强”技术来生成额外的条件变量 c ^ \hat{c} c^。与[26, 24]中固定的条件文本变量 c c c 不同,我们从独立的高斯分布 N ( μ ( ϕ t ) , Σ ( ϕ t ) ) N(\mu(\phi_t), \Sigma(\phi_t)) N(μ(ϕt),Σ(ϕt)) 随机采样潜在变量 c ^ \hat{c} c^,其中均值 μ ( ϕ t ) \mu(\phi_t) μ(ϕt) 和对角协方差矩阵 Σ ( ϕ t ) \Sigma(\phi_t) Σ(ϕt) 是文本嵌入 ϕ t \phi_t ϕt 的函数。所提出的条件增强在少量图像-文本对的情况下产生更多的训练对,从而鼓励对条件流形上的小扰动具有稳健性。为了进一步强制在条件流形上实现平滑性并避免过拟合[6, 14],我们在训练过程中为生成器的目标函数添加了以下正则化项:
D K L ( N ( μ ( ϕ t ) , Σ ( ϕ t ) ) ∣ ∣ N ( 0 , I ) ) (2) D_{KL}(N(\mu(\phi_t), \Sigma(\phi_t)) || N(0, I)) \tag{2} DKL(N(μ(ϕt),Σ(ϕt))∣∣N(0,I))(2)
其中 D K L D_{KL} DKL 是标准高斯分布和条件高斯分布之间的Kullback-Leibler散度(KL散度)。条件增强引入的随机性有助于模型文本到图像的翻译,因为同一句子通常对应于具有不同姿势和外观的物体。
3.3. 第一阶段生成对抗网络(Stage-I GAN)
与直接在文本描述的条件下生成高分辨率图像不同,我们将任务简化为首先使用我们的第一阶段生成对抗网络生成低分辨率图像,该阶段仅关注为物体绘制粗糙的形状和正确的颜色。
设文本描述 t t t 的文本嵌入为 ϕ t \phi_t ϕt,在本文中由预训练的编码器[25]生成。用于文本嵌入的高斯条件变量 c 0 ^ \hat{c_0} c0^ 从 N ( μ 0 ( ϕ t ) , Σ 0 ( ϕ t ) ) N(\mu_0(\phi_t), \Sigma_0(\phi_t)) N(μ0(ϕt),Σ0(ϕt)) 中采样,以捕捉 ϕ t \phi_t ϕt 的含义及其变化。在给定 c 0 ^ \hat{c_0} c0^ 和随机变量 z z z 的条件下,通过交替地最大化 Eq. (3) 中的 L D 0 LD0 LD0 和最小化 Eq. (4) 中的 L G 0 LG0 LG0,第一阶段生成对抗网络训练判别器 D 0 D0 D0 和生成器 G 0 G0 G0:
L D 0 = E ( I 0 , t ) ∼ p data [ log D 0 ( I 0 , ϕ t ) ] + E ( z , t ) ∼ p z , p data [ log ( 1 − D 0 ( G 0 ( z , c 0 ^ ) , ϕ t ) ) ] (3) L_{D_0} = \mathbb{E}_{(I_0,t) \sim p_{\text{data}}}[ \log D_0(I_0, \phi_t)] + \mathbb{E}_{(z,t) \sim p_z, p_{\text{data}}}[ \log(1 - D_0(G_0(z, \hat{c_0}), \phi_t))] \tag{3} LD0=E(I0,t)∼pdata[logD0(I0,ϕt)]+E(z,t)∼pz,pdata[log(1−D0(G0(z,c0^),ϕt))](3)
L G 0 = E ( z , t ) ∼ p z , p data [ log ( 1 − D 0 ( G 0 ( z , c 0 ^ ) , ϕ t ) ) ] + λ D K L ( N ( μ 0 ( ϕ t ) , Σ 0 ( ϕ t ) ) ∣ ∣ N ( 0 , I ) ) (4) L_{G_0} = \mathbb{E}_{(z,t) \sim p_z, p_{\text{data}}}[ \log(1 - D_0(G_0(z, \hat{c_0}), \phi_t))] + \lambda D_{KL}(N(\mu_0(\phi_t), \Sigma_0(\phi_t))|| N(0, I)) \tag{4} LG0=E(z,t)∼pz,pdata[log(1−D0(G0(z,c0^),ϕt))]+λDKL(N(μ0(ϕt),Σ0(ϕt))∣∣N(0,I))(4)
其中真实图像 I 0 I0 I0 和文本描述 t t t 来自真实数据分布 p data p_{\text{data}} pdata。 z z z 是从给定分布 p z p_z pz(在本文中为高斯分布)中随机采样的噪声向量。 λ \lambda λ 是在 Eq. (4) 中平衡两项的正则化参数。我们在所有实验中都将 λ \lambda λ 设置为 1。利用 [13] 中引入的重新参数化技巧, μ 0 ( ϕ t ) \mu_0(\phi_t) μ0(ϕt) 和 Σ 0 ( ϕ t ) \Sigma_0(\phi_t) Σ0(ϕt) 与网络的其余部分一起联合学习。
模型架构:对于生成器 G 0 G0 G0,为了获得文本条件变量 c 0 ^ \hat{c_0} c0^,首先将文本嵌入 ϕ t \phi_t ϕt 输入到一个全连接层中,以生成 Gaussian 分布 N ( μ 0 , Σ 0 ) N(\mu_0, \Sigma_0) N(μ0,Σ0) 的 μ 0 \mu_0 μ0 和 Σ 0 \Sigma_0 Σ0( Σ 0 \Sigma_0 Σ0 是 Σ 0 \Sigma_0 Σ0 对角线上的值)。然后,从高斯分布中采样得到 c 0 ^ \hat{c_0} c0^。我们的 Ng 维条件向量 c 0 ^ \hat{c_0} c0^ 通过 c 0 ^ = μ 0 + Σ 0 ⊙ ε \hat{c_0} = \mu_0 + \Sigma_0 \odot \varepsilon c0^=μ0+Σ0⊙ε 计算得出(其中 ⊙ \odot ⊙ 是逐元素乘法, ε ∼ N ( 0 , I ) \varepsilon \sim N(0, I) ε∼N(0,I))。然后,通过一系列上采样块生成一个 W 0 × H 0 W_0 × H_0 W0×H0 图像,其中 c 0 ^ \hat{c_0} c0^ 与一个 N z N_z Nz 维噪声向量连接在一起。
对于判别器 D 0 D_0 D0,首先使用全连接层将文本嵌入 ϕ t \phi_t ϕt 压缩为 Nd 维,然后进行空间复制,形成一个 M d × M d × N d M_d × M_d × N_d Md×Md×Nd 张量。与此同时,图像通过一系列下采样块直到具有 M d × M d M_d × M_d Md×Md 的空间尺寸。然后,图像滤波器映射沿着通道维度与文本张量连接。所得到的张量进一步输入到一个 1 × 1 1×1 1×1 卷积层中,以共同学习图像和文本之间的特征。最后,使用一个节点的全连接层产生决策分数。
3.4. 第二阶段生成对抗网络(Stage-II GAN)
由第一阶段生成对抗网络生成的低分辨率图像通常缺乏生动的物体部分,并可能包含形状扭曲。一些文本中的细节在第一阶段可能也被忽略了,而这些细节对于生成逼真的图像至关重要。我们的第二阶段生成对抗网络基于第一阶段的结果生成高分辨率图像。它在低分辨率图像的基础上以及再次使用文本嵌入来纠正第一阶段结果的缺陷。第二阶段生成对抗网络完善先前被忽略的文本信息,以生成更多逼真的细节。
在低分辨率结果 s 0 = G 0 ( z , c 0 ^ ) s0 = G0(z, \hat{c_0}) s0=G0(z,c0^) 和高斯潜变量 c ^ \hat{c} c^ 的条件下,通过交替地最大化 Eq. (5) 中的 L D LD LD 和最小化 Eq. (6) 中的 L G LG LG,第二阶段生成对抗网络训练判别器 D D D 和生成器 G G G:
L D = E ( I , t ) ∼ p data [ log D ( I , ϕ t ) ] + E ( s 0 , t ) ∼ p G 0 , p data [ log ( 1 − D ( G ( s 0 , c ˆ ) , ϕ t ) ) ] (5) L_D = \mathbb{E}_{(I,t) \sim p_{\text{data}}}[ \log D(I, \phi_t)] + \mathbb{E}_{(s_0,t) \sim p_{G_0}, p_{\text{data}}}[ \log(1 - D(G(s_0, cˆ), \phi_t))] \tag{5} LD=E(I,t)∼pdata[logD(I,ϕt)]+E(s0,t)∼pG0,pdata[log(1−D(G(s0,cˆ),ϕt))](5)
L G = E ( s 0 , t ) ∼ p G 0 , p data [ log ( 1 − D ( G ( s 0 , c ˆ ) , ϕ t ) ) ] + λ D K L ( N ( μ ( ϕ t ) , Σ ( ϕ t ) ) ∣ ∣ N ( 0 , I ) ) (6) L_G = \mathbb{E}_{(s_0,t) \sim p_{G0}, p_{\text{data}}}[ \log(1 - D(G(s_0, cˆ), \phi_t))] + \lambda D_{KL}(N(\mu(\phi_t), \Sigma(\phi_t))|| N(0, I)) \tag{6} LG=E(s0,t)∼pG0,pdata[log(1−D(G(s0,cˆ),ϕt))]+λDKL(N(μ(ϕt),Σ(ϕt))∣∣N(0,I))(6)
与原始的 GAN 公式不同,假设随机噪声 z z z 在这个阶段没有被使用,因为随机性已经由 s 0 s0 s0 保留。在此阶段使用的高斯条件变量 c ^ \hat{c} c^ 与第一阶段的 c 0 ^ \hat{c_0} c0^ 共享相同的预训练文本编码器,生成相同的文本嵌入 ϕ t \phi_t ϕt。然而,第一阶段和第二阶段的条件增强使用不同的全连接层来生成不同的均值和标准差。通过这种方式,第二阶段生成对抗网络学习捕捉在文本嵌入中被第一阶段忽略的有用信息。
模型架构:我们将第二阶段生成器设计为一个带有残差块[9]的编码器-解码器网络。与前一阶段类似,文本嵌入 ϕ t \phi_t ϕt 用于生成 N g N_g Ng 维文本条件向量 c ^ \hat{c} c^,将其进行空间复制,形成一个 M g × M g × N g M_g×M_g×N_g Mg×Mg×Ng 张量。与此同时,由第一阶段生成对抗网络生成的 s 0 s_0 s0 通过多个下采样块(即编码器)传递,直到具有 M g × M g M_g × M_g Mg×Mg 的空间尺寸。图像特征与文本特征沿通道维度进行拼接。编码的图像特征与文本特征结合在一起,传递到多个残差块,这些块旨在学习跨图像和文本特征的多模态表示。最后,使用一系列上采样层(即解码器)来生成一个 W × H W × H W×H 的高分辨率图像。这样的生成器能够在修正输入图像的缺陷的同时添加更多的细节,以生成逼真的高分辨率图像。
对于判别器,其结构与第一阶段判别器类似,只是在此阶段由于图像尺寸更大,额外的下采样块。为了明确地强制GAN学习图像和条件文本之间更好的对齐,而不是使用传统的判别器,我们对两个阶段都采用了 Reed 等人提出的匹配感知判别器[26]。在训练过程中,判别器将真实图像及其对应的文本描述作为正样本对,而负样本对则包括两组。第一组是带有不匹配文本嵌入的真实图像,而第二组则是带有对应文本嵌入的合成图像。
3.5. 实现细节
上采样块由最近邻上采样和一个 3 × 3 3×3 3×3 步长 1 的卷积组成。在每个卷积之后都应用批归一化 [11] 和 ReLU 激活函数,最后一个卷积之后没有应用。残差块由 3 × 3 3×3 3×3 步长 1 的卷积、批归一化和 ReLU 组成。在 128 × 128 128×128 128×128 的 StackGAN 模型中使用两个残差块,而在 256 × 256 256×256 256×256 的模型中使用四个残差块。下采样块由 4 × 4 4×4 4×4 步长 2 的卷积、批归一化和 LeakyReLU 组成,只有第一个下采样块没有批归一化。
默认情况下, N g = 128 N_g = 128 Ng=128, N z = 100 N_z = 100 Nz=100, M g = 16 M_g = 16 Mg=16, M d = 4 M_d = 4 Md=4, N d = 128 N_d = 128 Nd=128, W 0 = H 0 = 64 W_0 = H_0 = 64 W0=H0=64, W = H = 256 W = H = 256 W=H=256。对于训练,首先通过固定第二阶段生成对抗网络,迭代地训练第一阶段生成对抗网络的 D 0 D_0 D0 和 G 0 G_0 G0,共进行 600 个 epochs。然后通过固定第一阶段生成对抗网络,迭代地训练第二阶段生成对抗网络的 D D D 和 G G G,共进行另外 600 个 epochs。所有网络都使用批量大小为 64 的 ADAM 求解器进行训练,初始学习率为 0.0002。学习率每经过 100 个 epochs 衰减到其前一个值的一半。
4. 实验
为了验证我们的方法,我们进行了广泛的定量和定性评估。我们将我们的方法与两种最先进的文本到图像合成方法 GAN-INT-CLS [26] 和 GAWWN [24] 进行比较。我们使用这两种比较方法的作者发布的代码生成了它们的结果。此外,我们设计了一些基线模型,以调查我们提出的 StackGAN 的整体设计和重要组件。首先,我们直接训练 Stage-I GAN 生成 64×64 和 256×256 的图像,以调查所提出的堆叠结构和条件增强是否有益。然后,我们修改了我们的 StackGAN 以生成 128×128 和 256×256 的图像,以调查通过我们的方法生成更大图像是否会导致更高的图像质量。我们还调查了在 StackGAN 的两个阶段都输入文本是否有用。
4.1. 数据集和评估指标
CUB [35] 包含 200 种鸟类,共 11,788 张图像。由于该数据集中 80% 的鸟类的对象-图像大小比小于 0.5 [35],作为预处理步骤,我们裁剪了所有图像,以确保鸟类的边界框具有大于 0.75 的对象-图像大小比。Oxford-102 [21] 包含 8,189 张来自 102 种不同类别的花朵图像。为了展示我们方法的泛化能力,我们还使用了更具挑战性的 MS COCO 数据集 [16] 进行评估。与 CUB 和 Oxford-102 不同,MS COCO 数据集包含具有多个对象和各种背景的图像。它有一个包含 80,000 张图像的训练集和包含 40,000 张图像的验证集。COCO 数据集中的每个图像都有 5 个描述,而 CUB 和 Oxford-102 数据集中的每个图像都有 10 个描述。根据 [26] 中的实验设置,我们直接使用了 COCO 数据集的训练集和验证集,同时将 CUB 和 Oxford-102 数据集拆分成类不相交的训练和测试集。
评估指标。评估生成模型(例如 GAN)的性能是困难的。我们选择了最近提出的数值评估方法 “Inception Score” [29] 进行定量评估。
I = exp ( E x D KL ( p ( y ∣ x ) ∣ ∣ p ( y ) ) ) I = \exp\left(\mathbb{E}_x D_{\text{KL}}\left(p(y|x) || p(y)\right)\right) I=exp(ExDKL(p(y∣x)∣∣p(y)))
其中, x x x 表示一个生成的样本, y y y 是 Inception 模型 [30] 预测的标签。这个指标背后的思想是,良好的模型应该生成多样但有意义的图像。因此,边际分布 p ( y ) p(y) p(y) 与条件分布 p ( y ∣ x ) p(y|x) p(y∣x) 之间的 KL 散度应该很大。在我们的实验中,我们直接使用预训练的 Inception 模型来评估 COCO 数据集。对于细粒度数据集 CUB 和 Oxford-102,我们为每个数据集微调了一个 Inception 模型。正如 [29] 中所建议的,我们对每个模型评估这个指标,使用大量样本(例如,随机选择的 30,000 个样本)。
尽管 Inception Score 已经显示与人类对样本视觉质量的感知有很好的相关性 [29],但它无法反映生成的图像是否在给定的文本描述条件下良好。因此,我们还进行了人类评估。我们从 CUB 和 Oxford-102 的每个类别的测试集中随机选择了 50 个文本描述。对于 COCO 数据集,我们从其验证集中随机选择了 4,000 个文本描述。对于每个句子,我们由 10 名用户(不包括任何作者)来排名不同方法的结果。计算人类用户的平均排名来评估所有比较方法。
4.2. 定量和定性结果
我们将我们的 StackGAN 与 CUB、Oxford-102 和 COCO 数据集上的最先进文本到图像方法 [24, 26] 进行了比较。我们提供的 StackGAN 和比较方法的 Inception Score 和人类平均排名在 表1 中报告。在 图3 和 图4 中比较了一些代表性的示例。
表1。我们的 StackGAN、GAWWN [24] 和 GAN-INT-CLS [26] 在 CUB、Oxford-102 和 MS-COCO 数据集上的 Inception 分数和平均人类排名。
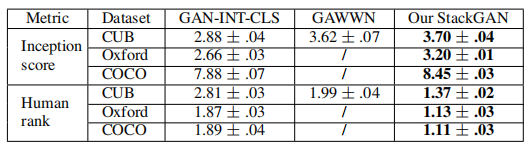
图3。使用 CUB 测试集中的文本描述为条件,我们的 StackGAN、GAWWN [24] 和 GAN-INT-CLS [26] 生成的示例结果。

图4。使用 Oxford-102 测试集(最左边的四列)和 COCO 验证集(最右边的四列)的文本描述作为条件,我们的 StackGAN 和 GAN-INT-CLS [26] 生成的示例结果。

我们的 StackGAN 在所有三个数据集上都获得了最佳的 Inception Score 和平均人类排名。与 GAN-INT-CLS [26] 相比,在 CUB 数据集上,StackGAN 的 Inception Score 提高了 28.47%(从 2.88 提高到 3.70),在 Oxford-102 上提高了 20.30%(从 2.66 提高到 3.20)。我们的 StackGAN 的更好的平均人类排名也表明,我们提出的方法能够生成更真实的、基于文本描述的样本。
正如 图3 所示,GAN-INT-CLS [26] 生成的 64×64 样本只能反映鸟类的一般形状和颜色。它们的结果在大多数情况下缺乏生动的部分(例如嘴巴和腿部)和令人信服的细节,使它们既不足够逼真也没有足够高的分辨率。通过在位置约束上使用额外的条件变量,GAWWN [24] 在 CUB 数据集上获得了更好的 Inception Score,但
仍略低于我们的方法。它生成的高分辨率图像比 GAN-INT-CLS 更具细节,如 图3 所示。然而,正如其作者所提到的,当只基于文本描述条件时,GAWWN 无法生成任何合理的图像 [24]。相比之下,我们的 StackGAN 可以仅从文本描述生成 256×256 的照片逼真图像。
图5 展示了我们的 StackGAN 生成的 Stage-I 和 Stage-II 图像的一些示例。正如 图5 的第一行所示,在大多数情况下,Stage-I GAN 能够在给定文本描述的情况下绘制对象的大致形状和颜色。然而,Stage-I 图像通常是模糊的,有各种缺陷和缺失的细节,特别是前景对象。如第二行所示,Stage-II GAN 生成 4 倍分辨率的图像,其中包含更有说服力的细节,更好地反映了相应的文本描述。对于 Stage-I GAN 已经生成合理形状和颜色的情况,Stage-II GAN 完成了细节。例如,在 图5 的第一列中,对于一个令人满意的 Stage-I 结果,Stage-II GAN 专注于绘制短嘴和文本中描述的白色颜色,以及尾巴和腿部的细节。在所有其他示例中,Stage-II 图像都添加了不同程度的细节。在许多其他情况下,Stage-II GAN 能够通过再次处理文本描述来纠正 Stage-I 结果的缺陷。例如,在第 5 列的 Stage-I 图像中,其冠是蓝色的,而不是文本中描述的红棕色冠。这个缺陷被 Stage-II GAN 纠正了。在一些极端情况下(例如 图5 的第 7 列),即使 Stage-I GAN 无法绘制出合理的形状,Stage-II GAN 也能够生成合理的对象。我们还观察到 StackGAN 有能力从 Stage-I 图像中转移背景,并在 Stage-II 中将其微调以获得更高分辨率和更真实的图像。
图5。使用 CUB 测试集中的未见文本生成的样本,每列列出了文本描述,以及由 StackGAN 的 Stage-I 和 Stage-II 生成的图像。

重要的是,StackGAN 并不是通过简单地记住训练样本来实现好的结果,而是通过捕捉复杂的底层语言-图像关系。我们从我们生成的图像和所有训练图像中提取视觉特征,然后使用我们的 StackGAN 的 Stage-II 判别器 D。对于每个生成的图像,可以检索出与训练集中的最近邻。通过检查检索出的图像(见 图6),我们可以得出结论,生成的图像具有一些与训练样本类似的特征,但实质上是不同的。
图6。对于生成的图像(第一列),通过利用 Stage-II 判别器 D 提取视觉特征来检索其最近的训练图像(第2-6列)。使用特征之间的 L2 距离进行最近邻检索。

4.3. 组件分析
在这个小节中,我们使用我们的基线模型在 CUB 数据集上分析了 StackGAN 的不同组件。这些基线模型的 Inception Score 在 表2 中报告。
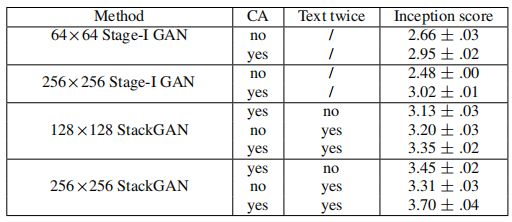
表2。使用不同的基线模型生成的30,000个样本计算的我们的 StackGAN 的 Inception 分数。
**StackGAN 的设计。**如 表2 的前四行所示,如果直接使用 Stage-I GAN 生成图像,Inception Score 明显下降。这种性能下降可以通过 图7 中的结果很好地说明。正如 图7 的第一行所示,如果不使用条件增强(CA),Stage-I GAN 无法生成任何合理的 256×256 样本。尽管带有 CA 的 Stage-I GAN 能够生成更多样的 256×256 样本,但这些样本不如由 StackGAN 生成的样本逼真。这证明了所提出的堆叠结构的必要性。此外,通过将输出分辨率从 256×256 减小到 128×128,Inception Score 从 3.70 下降到 3.35。请注意,在计算 Inception Score 之前,所有图像都缩放到 299 × 299。因此,如果我们的 StackGAN 只是增加图像尺寸而没有添加更多信息,不同分辨率的样本的 Inception Score 将保持相同。因此,128×128 StackGAN 的 Inception Score 下降表明,我们的 256×256 StackGAN 确实在更大的图像中添加了更多细节。对于 256×256 StackGAN,如果仅在 Stage-I 阶段输入文本(标记为 “no Text twice”),则 Inception Score 从 3.70 下降到 3.45。这表明在 Stage-II 阶段再次处理文本描述有助于改进 Stage-I 结果。从 128×128 StackGAN 模型的结果中也可以得出相同的结论。
**条件增强。**我们还调查了所提出的条件增强(CA)的有效性。通过从 StackGAN 256×256 中删除它(在 表2 中标记为 “no CA”),Inception Score 从 3.70 下降到 3.31。图7 也显示了具有 CA 的 256×256 Stage-I GAN(和 StackGAN)可以根据相同的文本描述生成具有不同姿势和视角的鸟类图像。相比之下,没有使用 CA,在没有稳定训练动态的情况下,256×256 Stage-I GAN 生成的样本会坍缩成无意义的图像。因此,所提出的条件增强有助于稳定条件 GAN 训练,并提高了生成样本的多样性,因为它能够鼓励对潜在流形上的小扰动具有鲁棒性。
图7。条件增强(CA)有助于稳定条件 GAN 的训练,并提高了生成样本的多样性。(第一行)没有使用 CA,Stage-I GAN 无法生成可信的 256×256 样本。尽管每列使用不同的噪声向量 z,但生成的样本对于每个输入的文本描述来说都是相同的。(第2-3行)使用了 CA 但固定噪声向量 z,方法仍然能够生成具有不同姿势和视角的鸟类图像。

**句子嵌入插值。**为了进一步证明我们的 StackGAN 学习了一个平滑的潜在数据流形,我们使用它从线性插值的句子嵌入中生成图像,如 图8 所示。我们固定噪声向量 z,因此生成的图像仅根据给定的文本描述推断。第一行的图像是由我们自己构造的简单句子生成的。这些句子仅包含简单的颜色描述。结果显示,从插入的嵌入中生成的图像可以准确地反映颜色变化并生成合理的鸟类形状。第二行展示了从更复杂的句子生成的样本,这些句子包含有关鸟类外观的更多细节。生成的图像将主要颜色从红色变为蓝色,并将翅膀颜色从黑色变为褐色。
图8。从左到右:通过插值两个句子嵌入而生成的图像。可以观察到从第一个句子的含义到第二个句子的含义的逐渐变化。每行的噪声向量 z 被固定为零。

5 结论
本文提出了具有条件增强的堆叠生成对抗网络(StackGAN),用于合成逼真的图像。所提出的方法将文本到图像的合成分解为一种新颖的草图细化过程。第一阶段 GAN 根据给定的文本描述从基本颜色和形状约束中勾勒出对象的草图。第二阶段 GAN 修正了第一阶段结果中的缺陷,并添加了更多细节,生成了更高分辨率、更具图像质量的图像。广泛的定量和定性结果表明了我们提出的方法的有效性。与现有的文本到图像生成模型相比,我们的方法生成更高分辨率(例如 256×256)的图像,具有更多逼真的细节和多样性。
References
-
Arjovsky, M., & Bottou, L. (2017). Towards principled methods for training generative adversarial networks. In ICLR.
-
Brock, A., Lim, T., Ritchie, J. M., & Weston, N. (2017). Neural photo editing with introspective adversarial networks. In ICLR.
-
Che, T., Li, Y., Jacob, A. P., Bengio, Y., & Li, W. (2017). Mode regularized generative adversarial networks. In ICLR.
-
Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In NIPS.
-
Denton, E. L., Chintala, S., Szlam, A., & Fergus, R. (2015). Deep generative image models using a Laplacian pyramid of adversarial networks. In NIPS.
-
Doersch, C. (2016). Tutorial on variational autoencoders. arXiv preprint arXiv:1606.05908.
-
Gauthier, J. (2015). Conditional generative adversarial networks for convolutional face generation. Technical report.
-
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In NIPS.
-
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In CVPR.
-
Huang, X., Li, Y., Poursaeed, O., Hopcroft, J., & Belongie, S. (2017). Stacked generative adversarial networks. In CVPR.
-
Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML.
-
Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In CVPR.
-
Kingma, D. P., & Welling, M. (2014). Auto-encoding variational Bayes. In ICLR.
-
Larsen, A. B. L., Sønderby, S. K., Larochelle, H., & Winther, O. (2016). Autoencoding beyond pixels using a learned similarity metric. In ICML.
-
Ledig, C., Theis, L., Huszar, F., Caballero, J., Aitken, A., Tejani, A., … & Shi, W. (2017). Photo-realistic single image super-resolution using a generative adversarial network. In CVPR.
-
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., … & Zitnick, C. L. (2014). Microsoft coco: Common objects in context. In ECCV.
-
Mansimov, E., Parisotto, E., Ba, L. J., & Salakhutdinov, R. (2016). Generating images from captions with attention. In ICLR.
-
Metz, L., Poole, B., Pfau, D., & Sohl-Dickstein, J. (2017). Unrolled generative adversarial networks. In ICLR.
-
Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
-
Nguyen, A., Yosinski, J., Bengio, Y., Dosovitskiy, A., & Clune, J. (2017). Plug & play generative networks: Conditional iterative generation of images in latent space. In CVPR.
-
Nilsback, M. E., & Zisserman, A. (2008). Automated flower classification over a large number of classes. In ICCVGIP.
-
Odena, A., Olah, C., & Shlens, J. (2017). Conditional image synthesis with auxiliary classifier GANs. In ICML.
-
Radford, A., Metz, L., & Chintala, S. (2016). Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR.
-
Reed, S., Akata, Z., Mohan, S., Tenka, S., Schiele, B., & Lee, H. (2016). Learning what and where to draw. In NIPS.
-
Reed, S., Akata, Z., Schiele, B., & Lee, H. (2016). Learning deep representations of fine-grained visual descriptions. In CVPR.
-
Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., & Lee, H. (2016). Generative adversarial text-to-image synthesis. In ICML.
-
Reed, S., van den Oord, A., Kalchbrenner, N., Bapst, V., Botvinick, M., & de Freitas, N. (2016). Generating interpretable images with controllable structure. Technical report.
-
Rezende, D. J., Mohamed, S., & Wierstra, D. (2014). Stochastic backpropagation and approximate inference in deep generative models. In ICML.
-
Salimans, T., Goodfellow, I. J., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved techniques for training GANs. In NIPS.
-
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In CVPR.
-
Sønderby, C. K., Caballero, J., Theis, L., Shi, W., & Huszar, F. (2017). Amortised map inference for image super-resolution. In ICLR.
-
Taigman, Y., Polyak, A., & Wolf, L. (2017). Unsupervised cross-domain image generation. In ICLR.
-
van den Oord, A., Kalchbrenner, N., & Kavukcuoglu, K. (2016). Pixel recurrent neural networks. In ICML.
-
van den Oord, A., Kalchbrenner, N., Vinyals, O., Espeholt, L., Graves, A., & Kavukcuoglu, K. (2016). Conditional image generation with PixelCNN decoders. In NIPS.
-
Wah, C., Branson, S., Welinder, P., Perona, P., & Belongie, S. (2011). The Caltech-UCSD Birds-200-2011 Dataset. Technical Report CNS-TR-2011-001.
-
Wang, X., & Gupta, A. (2016). Generative image modeling using style and structure adversarial networks. In ECCV.
-
Yan, X., Yang, J., Sohn, K., & Lee, H. (2016). Attribute2image: Conditional image generation from visual attributes. In ECCV.
-
Zhao, J., Mathieu, M., & LeCun, Y. (2017). Energy-based generative adversarial network. In ICLR.
-
Yan, X., Yang, J., Sohn, K., & Lee, H. (2016). Attribute2image: Conditional image generation from visual attributes. In ECCV.
-
Zhao, J., Mathieu, M., & LeCun, Y. (2017). Energy-based generative adversarial network. In ICLR.
-
Zhu, J., Kr¨ahenb¨uhl, P., Shechtman, E., & Efros, A. A. (2016). Generative visual manipulation on the natural image manifold. In ECCV.