Python爬虫从0到1——第三天
Python爬虫从0到1——第三天
在前两篇文章中已经大致的了解了爬虫以及爬虫中的一个关键模块requests,也就是说我们已经初步的掌握了通过python代码对网站发起请求并接收其响应内容的技能,那么今天我们要学习的内容就是学习浏览器中的开发者工具以及请求时的参数传递。注:文章中所说的浏览器皆指Google Chrome(谷歌浏览器)
一、浏览器开发者工具
关于浏览器开发者工具的打开方式如下:
1.快捷键F12、CTRL+SHIFT+I
2.页面空白处点击鼠标右键然后选中“检查”或在浏览器右上角找到“更多”或“三个小点”点击后选中更多工具然后点击开发者工具即可。
打开开发者工具后显示效果如下:

本篇文章中着重说明一下network

请注意观察上图中箭头所指。前三个箭头指向表示的含义依次为:是否记录网络资源信息(抓包开关,红色亮点时表示是);页面重载时是否清空资源信息(勾选时表示否);刷新页面时是否使用本地缓存(勾选时表示否,即每次重载页面都是从服务器获取资源);配置好之后刷新页面,就能够看到一系列的网络请求过程中的资源信息,这些信息其实就是浏览器在请求过程中访问的数据包。刷新后如下图:

在过滤器过滤抓到的包:
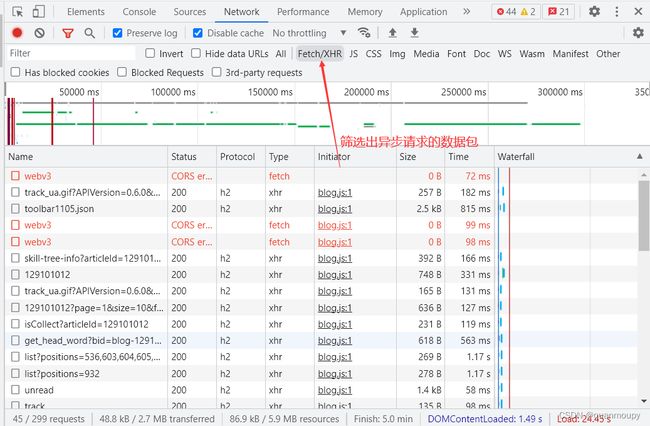
XHR之后可以筛选出js文件、css文件、图片、媒体文件、字体文件等。
当然还可以按照属性来进行过滤,例如仅显示状态码为200的数据包:
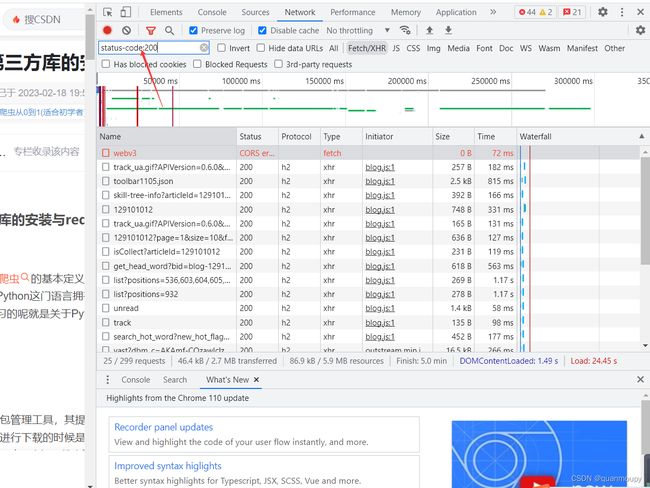
其他常用属性如下:
domain:仅显示来自指定域的资源。可以用通配符*来表示多个域
method:仅显示指定请求方式的数据包
mime-type:显示指定的MIME类型的资源
多个属性之间可以通过AND进行操作,例如:status-code:200 AND method:GET
单个资源内容详情
可以通过点击单个资源的名称查看资源详情。

Headers:查看头部信息,包括请求头和响应头。
Payload:该资源包请求时的负载参数,包括参数params和表单form data等
Preview:预览响应正文,可以查看该数据包在浏览器中大致的显示样式并且也可初步判断目标数据的存在情况。
Response:查看响应内容(正文)
Timing:时间分布
Cookies:查看选择的资源在请求和响应过程中存在的Cookie信息
关于开发者工具的Network就先说到这里,接下来补充几个常见的状态码表示的含义:
- 200:请求成功被服务器响应,正常状态。
- 302:临时重定向
- 301:永久重定向
- 404:资源不存在
- 403:请求被服务器拒绝
- 500:服务器内部错误导致无法完成对请求的处理。这种情况一般是服务器源代码出错导致。
详细含义及其他状态码可查看https://baike.baidu.com/item/HTTP%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin
二、“带头”请求
所谓“带头”请求,表示在代码中封装自定义的请求头信息携带在请求中对服务器进行请求,此操作可以实现对爬虫程序的初步伪装(通过构造服务器需要验证的头部参数实现)。
2.1 请求头Request headers
请求头信息可以根据浏览器开发者工具中选择数据包进行查看,然后逐个构造。
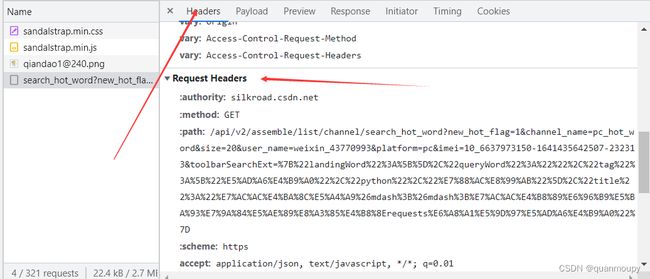
在python中构造的请求头,可直接添加到请求的方法中,headers的类型为一个字典。如下(以某度首页为例):
import requests
url = 'https://www.baidu.com'
headers = {
} # 构造请求头
response = requests.get(url, headers=headers) # 添加请求头的时候参数名即为headers,将自行构造的headers作为参数传入get方法中即可
2.2 UA伪装
UA伪装即初步隐藏爬虫身份(注意:并不是说进行UA伪装之后服务器就不会再认出爬虫),UA是User-Agent(用户代理)的首字母缩写,其作用表示明面上的用户身份,其内容存在于请求头之中,如下所示:

其中包含了操作系统版本、CPU类型、浏览器版本等信息,服务器则是通过UA来给用户发送不同类型的页面。同时服务器也是通过UA来判断是否是爬虫访问网站,如果是的话可能会在一定次数的访问后被禁止访问。
UA可以从网络上大量进行获取以构造一个“池”,称作“UA池”,代码执行时就可以随机从“池”中选择出一个UA封装到一个请求中。
代码中实现UA伪装:
import requests
url = 'https://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
} # 构造请求头
response = requests.get(url, headers=headers) # 添加请求头的时候参数名即为headers,将自行构造的headers作为参数传入get方法中即可
其他的请求头参数可以观察开发者工具中分析后添加,请求的时候并不是所有的请求头参数都需要添加到请求中。
三、带参请求
在网络请求过程中,有的地址需要我们携带指定的参数才能够获取到响应内容,否则请求可能会被服务器拒绝或者返回无用数据。
在本篇文章中先来看GET请求中的带参请求,如在某度进行搜索的时候。那我们要怎么才能知道需要什么参数呢?在这里我们先来看一下URL的结构。
3.1 URL参数
我们先来看两个url:
https://www.baidu.com/s和https://www.baidu.com/s?wd=美女
从上方两个url中我们可以发现他们的区别就在于后面个url多了"?wd=美女"部分,这部分就是请求这个url时携带的参数,可称为查询参数。在上方url中的参数是经过我优化的,大家第一次搜索的时候可以看到包括“wd”在内的多个参数,但只有“wd”参数直接影响了搜索页面的结果。参数与url地址之间以“?”间隔,参数之间以“&”连接,如下:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=美女&oq=%25E7%25BE%258E%25E5%25A5%25B3&rsv_pq=be5c836800029c60&rsv_t=3a99m4iCsoXo94KrGk22zkV4ubmvJpjIfN%2BzR7qfqNwC85UCYHW4s%2Fshtns&rqlang=cn&rsv_dl=tb&rsv_enter=1&rsv_sug2=0&rsv_btype=t&inputT=1311&rsv_sug4=2346
也就是说在代码中如果要携带查询参数请求的话可以在url中直接拼接,代码如下所示:
import requests
url = 'https://www.baidu.com/s?wd=美女'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'Cookie': 'xxxxxx' # 粘贴浏览器中的Cookie值在此处
} # 构造请求头
response = requests.get(url, headers=headers) # 添加请求头的时候参数名即为headers,将自行构造的headers作为参数传入get方法中即可
print(response.content.decode())
注意:由于某度搜索页面有反爬措施,会出现安全验证,可以在headers中添加Cookie解决,Cookie的值可在搜索页面开发者工具抓到包后找到对应的包,再从这个包里找到request headers然后直接将cookie全部复制粘贴到代码中即可。

红框中的Cookie键对应的值全部复制。
查询参数也可以以另一种形式进行传递——构造params参数,等同于直接放在url中请求,如下方代码所示:
import requests
url = 'https://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'Cookie': 'xxxxx'
} # 构造请求头
params = {
'wd': '美女'
}
response = requests.get(url, params=params, headers=headers) # 添加请求头的时候参数名即为headers,将自行构造的headers作为参数传入get方法中即可
print(response.content.decode())
3.2 url转义
大家在复制url的时候可能会发现一个问题,就是url中的“美女”变成了“%E7%BE%8E%E5%A5%B3”这样的形式,二者的含义是一致的,只不过是其在不同环境下的编码方式不同而发生的显示变化,那么也就是说二者之间是可以进行相互转换的。
python中就可以使用quote和unquote来进行转换,代码如下所示:
from urllib.parse import quote, unquote
# quote表示明变暗
word = '美女'
result = quote(word) # 结果为:%E7%BE%8E%E5%A5%B3
word = '%E7%BE%8E%E5%A5%B3'
result = unquote(word) # 结果为:美女
四、结语
本章节对于浏览器开发者工具的说明并没有完完全全进行详写,只提出了在爬虫开发中常用的一些功能,如有不理解的地方可以私我解决。目前还没有正式进入到案例阶段,所以代码部分比较少,数据在网页中的分析过程也比较少,但大家不要担心,后面案例的时候我们会有详细的网站分析步骤。目前重要的是先打牢基础。