python爬虫从0到1(第四天)——带着饼干去旅行
python爬虫从0到1(第四天)——带着饼干去旅行
坚持到了第四天,终于我们已经算是一只脚迈入了爬虫的门内,简单的请求对我们来说基本上已经是没有问题啦,那今天我们就进一步来探讨一下与前几篇文章中不同的请求情况。先来看这样一个情况,泉某平时喜欢在各论坛逛,偶尔看到一些亮眼的内容就会想着点赞评论收藏,那也就意味着需要在对应的论坛进行登录之后才能进行“一键三连”的操作,而前几天的文章中我们并没有接触过类似的情况,那在代码中需要登录的话我们又应该如何解决呢?其实问题也不是特别的复杂,简单来说就是我们在代码中正常的请求基本都是一个全新的请求,也就是说每次在访问服务器的时候服务器根本不知道我们是“合法”用户,要让服务器知道我们是合法用户的话就需要用到我们今天要说的小饼干——Cookie,这个小饼干是什么,能吃吗,它的作用又是什么呢?接下来我们就来正确食用这美味的小饼干了。
一、cookie的简单介绍
1.1 会话状态保持
什么是状态?就像谈恋爱一样,初见面时一个状态、看电影时一个状态、吃饭时一个状态、深入交流时一个状态…咳咳,扯远了。

总的来说就是当用户(爬虫)向服务器发起请求然后服务器返回响应给我们的这个过程中,用户和服务器就处于一个“通话”状态,如果我们换了一个环境再去向服务器请求的时候服务器就不知道我们在本次请求之前做过什么。这就相当于和老婆打着电话,然后老板突然打电话来要求要开会,没办法先挂了吧,开完会回来再和老婆打电话你说你去开会了,那老婆信不信呢?这就有待商榷了。
那老婆不信咋办,很简单,现在的手机基本上都有个通话保持功能,那就不挂断电话,和老婆一直通着电话(当然是不涉及商业机密的会议才这样干哈,要是讨论好几个亿的项目那种的会议就还是别了),这样你每次和老婆说话的时候她都知道你之前去做什么了。这叫做什么,这叫做“会话保持”。
说了这么多,那我们在进行网络请求的时候如何实现会话保持呢?主要是以下两种方式:
- 客户端的Cookie存储信息
- 服务器端的Session存储信息
1.2 什么是Cookie
先来看官方说法(引自百度百科)

很完美,介绍得很彻底,但是有点难理解。
总结下来就是——Cookie是由服务器生成的存储在用户本地的一段纯文本信息,这些信息可以包括用户名、密码、注册账户、手机号等。
那其特性呢,请往下看。
1.3 cookie的特性
-
跨域限制
cookie在同一域名下的网页能够共享,但是不能够在多个不同域名下使用同一cookie。
-
时间限制
cookie是存在一定有效期的,根据其有效期可分为会话cookie和持久cookie两类。
会话cookie:指浏览器关闭后cookie会自动删除。
持久cookie:浏览器退出、计算机重启都会一直存在于硬盘上,直到有效时间结束。
-
空间限制
cookie的存储大小只有4Kb左右,由此可见其能够存储的数据其实是非常小的。
-
数据类型限制
cookie能够存储的数据类型只能是字符串
-
数量限制
每个域最多不能超过50个cookie,当然啦有的浏览器能够存储的cookie可能会超过50个,比如firefox、safari等,但是其都有一个最大值,超出了的话就会自动剔除最老的cookie以留下一定的空间给最新的cookie。
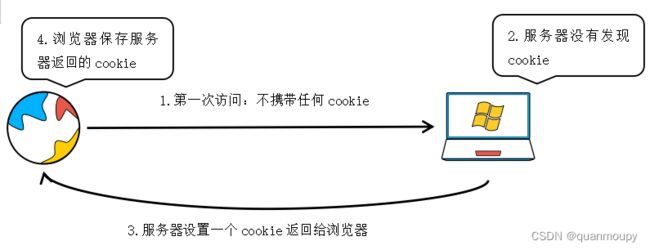
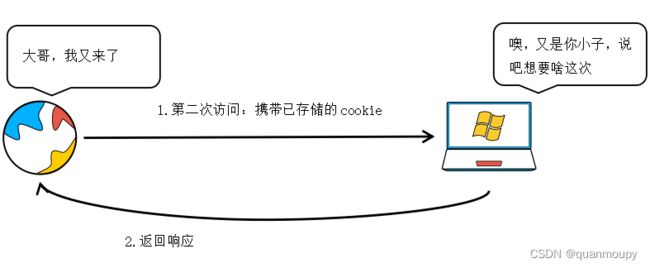
1.4 cookie的执行流程
在1.2小节已经知道了cookie是由服务器生成的,也就是说当我们访问一个新的网站(本机以前从来没有访问过的)的时候是没有携带任何cookie进行访问的,那么这个时候服务器接收到请求在响应的时候就会通过set-cookie来设置cookie,浏览器接收到之后就会将其保存起来,下次再访问的时候就会携带着cookie来到服务器,而服务器就会根据cookie信息来验证用户身份、行为等属性。如下图:
二、爬虫中的cookie
在爬虫中就是通过cookie来实现用户的登录状态,接下来就来看看在爬虫中的cookie应用
2.1 爬虫中使用cookie的利弊
-
携带cookie的利
- 能够实现网站中必须进行登录后的操作
- 能够成功处理部分反爬(如用户认证等)
-
携带cookie的弊
我们已经知道了cookie往往是对应了用户信息,并且还是一一对应的,那么也就意味着我们携带了cookie的爬虫如果被对方识别的话就可能会带来账号封禁的风险。
要解决上述问题的话我们可以搭建一个账号池,同时将我们的爬虫尽可能的拟人化去访问服务器,尽可能的去规避服务器对爬虫的检测。具体手段今后案例中会有所分享。
2.2 requests携带cookie方式
使用requests处理cookie有以下几种方法:
-
将cookie直接封装在headers中
... headers = { ... 'Cookie': 'xxx' } response = requests.get(url, headers=headers) -
将cookie传入到请求方法中
在python中,cookie是以键值对的形式而存在。所以在构造cookie的时候需要以字典来进行定义。
... cookies = { 'a': 'b', 'c': 'd', ... } response = requests.get(url, cookies=cookies) -
基于requests中的session模块实现会话保持
2.3 网站中的cookie
网页中的cookie位置在第二章里已经有过讲解,在这里不再详细阐述。
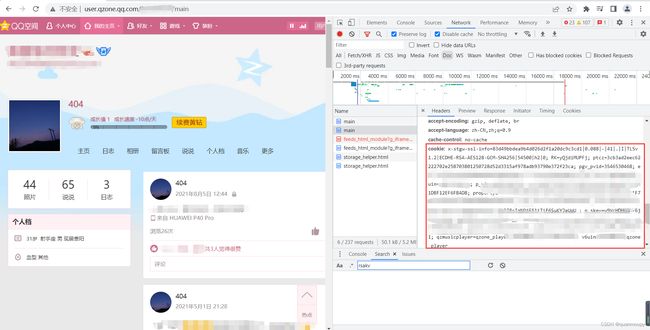
不难看出在此处的cookie是以分号’;'来隔开,然后以a=b的形式表示一个cookie键值,等号左边为键(key)右边为值(value)。
每个字段的相关信息在选中的包中可以进行查看,如下:
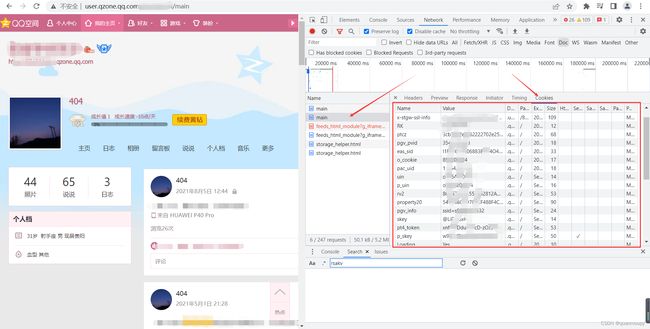
接下来直接上代码看效果。
三、会话保持实际应用案例
3.1 某鹅空间获取登录后的数据
-
分析网站,打开空间并打开开发者工具

-
刷新网页,分析数据所在的包目标数据为图中第二条动态内容。

-
分析抓到的包的基本信息
目标地址

cookie信息

注意cookie冒号右面全部的值都要复制!
目标url有了,cookie也有了,接下来就可以撸码然后运行了,效果如下:
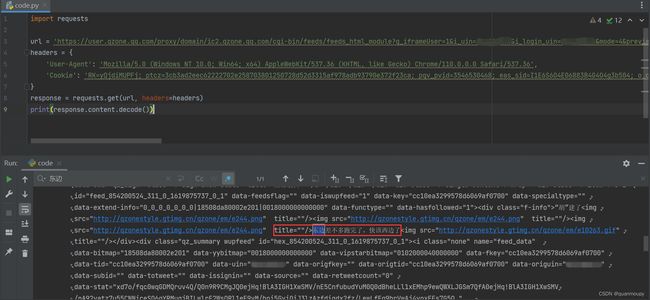
代码:
import requests url = '替换自己的url' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36', 'Cookie': '替换自己的cookie' } response = requests.get(url, headers=headers) print(response.content.decode())上方为基于headers实现cookie的携带,接下来看cookie字典封装的形式。

图中红框可以看到每一个cookie的键值对(name和value),接下来就是要把这每一个键值对添加到一个字典中然后发起请求。过程过于单调无趣,不再详细描述,直接上结果。
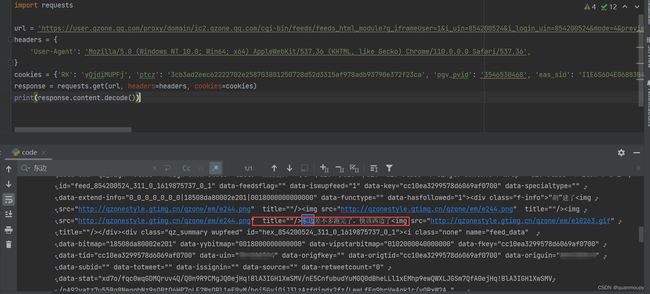
代码如下:
import requests url = '替换成自己的url' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36', } cookies = {'替换成自己的cookie键值对'} response = requests.get(url, headers=headers, cookies=cookies) print(response.content.decode())以上为cookie的两种使用方式,那么我们还提到了requests中的session模块也能够用来实现会话保持操作,如何实现呢?不要急,我们继续往下看。
3.2 某书网登录案例
网站地址(已脱敏处理):aHR0cHM6Ly93d3cucWlzaHV0YS5uZXQvP3Q9MjcyOTU=
-
老规矩,分析网站先打开开发者工具

-
找目标地址
注意此处是找登录接口,所以不要刷新页面,不然包太多不利于我们分析。找登录接口很简单,只需要任意填入账号密码点击登录即可。

点击登录后由于密码错误会跳转到如下页面。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SjQO8LP1-1677147285583)(G:\文章\爬虫从0到1专栏\第四天——会话保持\python爬虫从0到1(第四天)]——带着饼干去旅行.assets!在这里插入图片描述
)过来后可以看到抓到了两个数据包,一个一个分析(有经验的话其实这里可以直接判断登录一定就是第一个数据包,因为第二个包的扩展是gif动图),点击查看。

-
再看传递的参数(选择payload,低版本浏览器则在headers翻到最下方)。

分析到这里就可以开始敲代码了,首先是登录的代码,先看实现效果(响应内容已写到本地页面)。
代码如下:
import requests url = '登录地址' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36', } session = requests.session() # 实例化session,通过session来发起请求会自动保持会话状态 data = { 'LoginForm[username]': '用户名', 'LoginForm[password]': '密码' } # 构建表单数据 response = session.post(url, headers=headers, data=data) # 传入data进行请求 text_html = response.content.decode() # 保存响应内容 print(text_html) with open('qishu.html', 'w', encoding='utf-8')as f: f.write(text_html) # 将响应内容写到本地html页面中查看结果接下来再通过session发起请求的话就已经是登录的状态了,例如查看书架中收藏的小说,篇幅有限不再详细分析。
四、结语
本篇文章到这就结束啦,通过本篇文章相信大家已经了解了爬虫代码中如何实现会话状态的保持,空闲时间多加练习相信大家对于一些简单的需要登录的网站已经能够有一定的思路去进行处理了。文章会持续更新直到本专栏结束,不用担心泉某断更,每周会保持三更,咱们追求的是精而不是多。
文章内容仅供学习使用!若用于其他用途产生的法律责任一律自负。