Python批量爬虫下载PDF文件代码实现
本文的背景是:大学关系很好的老师问我能不能把Excel中1000个超链接网址对应的pdf文档下载下来。虽然可以手动一个一个点击下载,但是这样太费人力和时间了。我想起了之前的爬虫经验,给老师分析了一下可行性,就动手实践了。
没想到刚开始就遇到了困难,Excel中的超链接读到Python中直接显示成了中文。所以第一步就是把超链接对应的网址梳理出来,再用Python去爬取对应网址的pdf。第一步已经在上一篇文章中进行了详细说明,本文分享批量爬虫下载文件的第二步,详细代码介绍。
文章目录
-
- 一、读取数据
- 二、模拟登录网址点击下载pdf的按钮
- 三、写循环批量下载所有文件
一、读取数据
首先读取数据,代码如下:
import os
import numpy as np
import pandas as pd
#设置文件存放的地址
os.chdir(r'F:\老师\下载文件')
#读取数据
link_date = pd.read_csv('import.csv',encoding='gbk')
link_date.head(2)
得到结果:

二、模拟登录网址点击下载pdf的按钮
接着模拟使用Chrome浏览器登录,用代码打开第一个网址,并模拟人进行点击下载,具体代码如下:
import json
import time
import random
from captcha import *
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import wait
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions as EC
#导入库
print('程序开始时间:', datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
#模拟使用Chrome浏览器登陆
options = webdriver.ChromeOptions()
options.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(10)
#打开搜索页
driver.get(link_date['网址'][0])
time.sleep(20) # 暂停20s
#点击下载pdf的按钮
driver.find_element_by_xpath('//*[@id="mdiv"]/div[3]/div[2]/a').click()
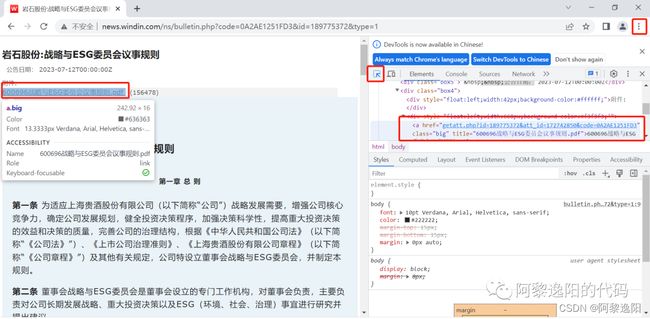
打开的网址如下图,左击最右边红框中的三个点,左击【更多工具】,将鼠标移至【开发者工具】并左击,即可看到下图右边展示栏。接着左击红框中的箭头,将鼠标移至最左边红框中的pdf上并左击,可看到右边红框中href对应的模块。右击该模块,左击【Copy】,再左击【Copy Xpath】即可得到driver.find_element_by_xpath中的路径。
三、写循环批量下载所有文件
写循环批量下载所有文件,最简单的方式是遍历所有网址,模拟点击下载pdf,代码如下:
for i in range(0,1000):
print(i)
#打开搜索页
driver.get(link_date['超链接'][i])
time.sleep(20) # 暂停20s
driver.find_element_by_xpath('//*[@id="mdiv"]/div[3]/div[2]/a').click()
但是这个代码有一个问题,一旦有一个网址出现意外,容易代码中断,会得到如下报错:
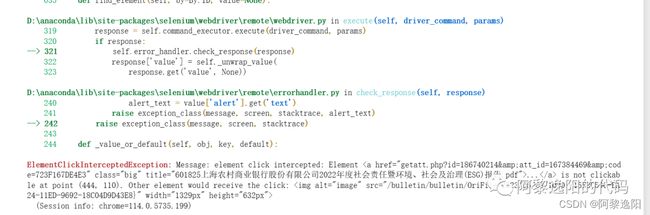
这时需要人为看已经下载到哪一个文件了,然后调整range中的数值接着下载。如果不想盯着代码,可以写成try的模式,在lab中记录已经下载的标签。如果碰到意外,直接跳到下一个网址,全量下载完后,再梳理哪个网址没有下载,具体语句如下:
lab = []
for i in range(1, 1000):
try:
print(i)
#打开搜索页
driver.get(link_date['网址'][i])
time.sleep(20) # 暂停20s
driver.find_element_by_xpath('//*[@id="mdiv"]/div[3]/div[2]/a').click()
lab.append(i)
except:
pass
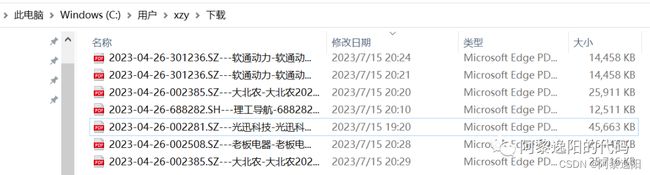
最终得到下载结果如下:
至此,Python批量爬虫下载PDF文件代码实现已经讲解完毕,感兴趣的同学可以自己实现一遍图片。
【限时免费进群】群内提供学习Python、玩转Python、风控建模、人工智能、数据分析相关招聘内推信息、优秀文章、学习视频,也可交流学习工作中遇到的相关问题。需要的朋友添加微信号19967879837,加时备注想进的群,比如风控建模。
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
Python人脸识别—我的眼里只有你
Python画好看的星空图(唯美的背景)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)