MySQL 慢查询及SQL执行时间监控
慢查询定义及作用
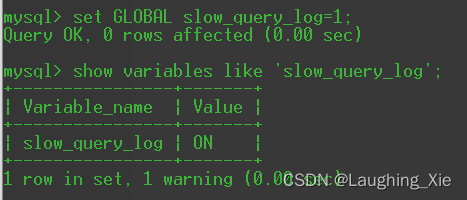
查询慢的日志,指mysql记录所有执行超过long_query_time参数设定的时间阈值的SQL语句的日志,该日志能为SQL语句的优化带来很好的帮助,默认情况下慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能。
show variables like 'slow_query_log';

将其开启
但是多慢算慢?MySQL中可以设定一个阈值,将月星时间超过该值的所有SQL语句都记录到慢查询日志中。long_query_time参数就是这个阈值,默认值为10 ,代表10秒。如下图:

# 默认10秒,这里自测 可设为0
set global long_query_time=0 ; 同时,表中可能有SQL没走索引走的全表扫描,但是由于数据量少,又达不到慢查询的时间标准,但后续表数据可能越来越大,对于这种情况而言,可以通过控制参数,让 MySQL对于没有使用索引的SQL语句也会记录到慢查询日志文件中
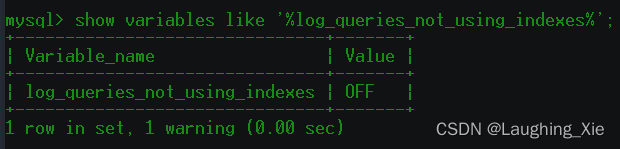
show variables like '%log_queries_not_using_indexes%'; --默认可能关闭的
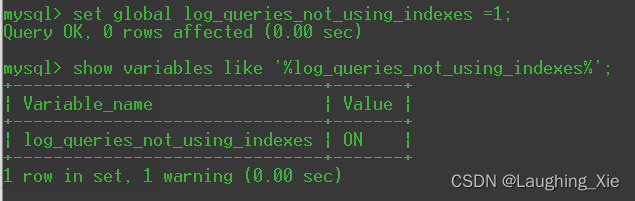
通过设置全局变量的值,来开启此功能
对于产生的慢查询日志,可以指定输出的位置,通过参数log_output来控制,可以输出到表(一般不推荐)或者文件或者一起都保存。(推荐放到文件中),一般都会放到data中,文件名末尾有-slow.log; 其中会有执行的时间,sql语句的名字,Rows_sent: 返回出去的结果行数,Rows_examined:为了获取到结果,扫描了多少数据量。日志文件是所有的数据,可通过bin目录下的 mysqldumpslow工具去查看慢查询日志去分析。可用
# 查看此工具的使用命令
./mysqldumpslow --help
# -s 对结果排序 t 按时间 -t 10 取前10条 把这个慢查询日志中 总耗时排前10位的拿出来看
./mysqldumpslow -s t -t 10 /home/mysql/mysql158/data/sefddkj-slow.log
# -g 加上正则表达式,通过grep来筛选,只关心select语句
./mysqldumpslow -s t -t 10 /home/mysql/mysql158/data/sefddkj-slow.log -g select慢查询的根本原因是访问的数据太多了,优化的目的都是减少mysql访问的数据量。
业务层:是否请求了不需要的数据?
1.查询不需要的记录 2.总是取出全部列 3.重复查询相同的数据
(如果数据时需要缓存起来,以后要用可直接查询所有的,也可用select *,*是肯定要走回表的或者直接全表扫)
执行层:是否在扫描额外的记录?典型的limit 10000,10 ,mysql扫了10010条记录,取了10条
1.响应时间 2.扫描的行数和返回的行数差距很大 3.扫描的行数和访问类型(每一行的成本是否达到了最优,通过explain可看到sql访问的类型获得的方式,type越靠前越好,扫描的记录数越少。尽可能只扫描所需要的数据行)
重构查询方法:
1.一个复杂查询还是多个简单查询?部分逻辑可交由代码层处理,更易扩展
2.切分查询。查询语句数据量太大了,切分成小查询,分而治之,一条sql返回的数据量一般5000~10000条数据最好。
3.分解关联查询?a.常用数据进行缓存,让缓存的效率更高,减少冗余记录的查询,关联可放在应用层,更易扩展。b.可减少锁竞争。c.更容易做到高性能和可扩展 d.相当于在应用中实现了哈希关联
TCP协议角度来说是全双工的。MySQL的协议,在应用层来说,是半双工的,客户端发送完了数据给服务器,服务器才能发送数据给客户端。同时,发完了,客户端才能再发命令给服务端。(没法做流量控制的)
对于java程序来说,很有可能由于mysql给的数据量过大过多,需要花很多的时间和内存来存储所有的结果集,很有可能发生OOM,所以MySQL的JDBC里提供了setFetchSize()之类的功能来解决这个问题。
A.当statement设置以下属性时,采用的是流数据接收方式,每次只从服务器接收部分数据,直到所有数据处理完成,不会发生JVM OOM 。
setResultSetType(ResultSet.TYPE_FORWARD_ONLY);
setFetchSize(Integer.MIN_VALUE);
B.调用statement的enableStreamingResults方法,实际上enableStreamingResult方法内部封装的就是第一种方式
C.设置连接属性useCursorFetch=true(5.0版本驱动开始支持),statement以TYPE_FORWARD_ONLY打开,再设置fetch size参数,表示采用服务器端游标,每次从服务器取fetch_size条数据。
具体SQL语句数据监控
MySQL查出来一条数据就会给一条数据给客户端,客户端库函数会有缓存数据;如果是将数据查全了再返回,会显得MySQL很慢,同时一次性给太多,会加载很多数据页到内存中再返回给客户端,占用内存。
可通过命令,来查看某条sql执行的时候MySQL底层执行的线程的具体工作情况,时间都花在哪的。
select @@profiling;
select count(*) FROM user_bak;
show profiles;
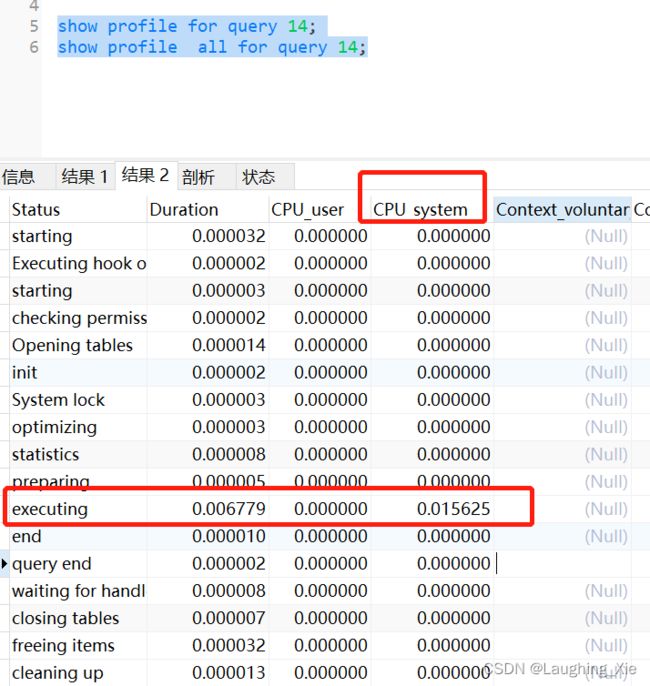
show profile for query 14;
show profile all for query 14;Select @@have_profiling;查看是否支持profile功能

如果是关闭状态,可以 Set profiling =1 ; 自行打开。
执行sql语句,并show profiles,看看这条sql执行的编号是多少?

再去查找这条sql的相应的内部线程执行情况。
Show profile for query 14; 执行这条sql的时候各个线程(阶段)花费的时间是多少

show profile all for query 55,显示更加详细的花费时间记录,这个线程大部分时间花在哪里了?包括cpu的时间