MySQL常用函数及语法
一、非常用聚合函数
| 名称 | 描述 |
|---|---|
| GROUP_CONCAT() | 返回一个连接的字符串 |
| JSON_ARRAYAGG() | 将结果集作为json数组返回 |
| JSON_OBJECTAGG() | 将结果集作为json对象返回 |
注意:聚合函数会忽略null值,以avg函数为例:
test1是成绩表,其中有两行的成绩为null
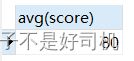
select * from test1;

使用avg获取成绩的平均值,结果为(80+80+80+80)/4 = 80,说明null值被忽略了
select avg(score) from test1;
1、GROUP BY WITH ROLLUP
- GROUP BY子句允许跟一个
WITH ROLLUP修饰符,这会输出更高级别汇总操作的额外行。 因此,可以通过单个查询回答多个分析级别的问题。例如,ROLLUP可用于为 OLAP(在线分析处理)操作提供支持
SELECT A,B,C FROM table GROUP BY A,B,C;
等同于
SELECT A,B,C FROM table GROUP BY A,B,C
UNION
SELECT A,B,NULL FROM table GROUP BY A,B
UNION
SELECT A,NULL,NULL FROM table GROUP BY A
UNION
SELECT NULL,NULL,NULL FROM table;
- 示例
SELECT
c_id,
s_id,
sum( s_score )
FROM
score
GROUP BY
c_id,
s_id WITH ROLLUP;
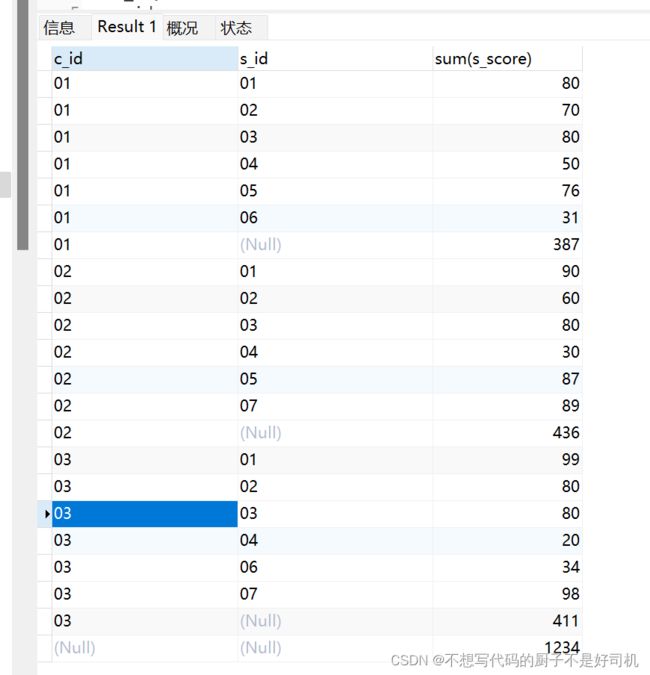
- 所以说,按照多个条件分组后,每个子分组都会进行一次超级汇总
2、GROUP_CONCAT()
- 此函数返回一个字符串,其由分组内的非空结果值拼接而成。如果没有非空值,则返回NULL。完整的语法如下:
-- DISTINCT、ORDER BY、SEPARATOR子句可以省略
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
- 示例
SELECT student_name,
GROUP_CONCAT(DISTINCT test_score
ORDER BY test_score DESC SEPARATOR ' ')
FROM student
GROUP BY student_name;
要消除重复值,请使用 DISTINCT 子句。要对结果中的值进行排序,请使用 ORDER BY 子句。组中值之间的默认分隔符是逗号 ( ,)。要显式指定分隔符,请使用SEPARATOR后跟应插入组值之间的字符串文字值。要完全消除分隔符,请指定 SEPARATOR ''
二、窗口函数
1、在GROUP BY中使用开窗函数
有student(学生信息)表,score(学生成绩)表,现需要查询学生平均成绩及其名次
SELECT
s_id,
s_name,
round( avg( s_score ), 2 ) AS avg_score,
row_number ( ) over ( ORDER BY avg( s_score ) DESC ) AS '名次'
FROM
score s
LEFT JOIN student USING ( s_id )
GROUP BY
s_id;
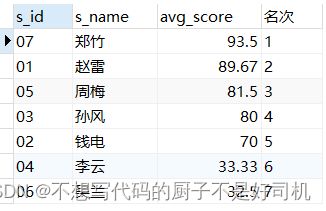
- 分析:窗口函数与group by一起使用并不冲突。
窗口函数是基于整个group by后的查询结果(而不是基于每组组内的查询结果) - 也就是说,group by先执行,开窗函数后执行,开窗函数将group by后的结果当做一个分组,窗口数就是group by后的分组数
2、语法
要使用窗口函数,需要在窗口函数之后,调用OVER子句,OVER子句两种形式:
-- over子句
over_clause:
{OVER (window_spec) | OVER window_name}
-- over子句括号中的内容
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]
-- 分组表达式
partition_clause:
PARTITION BY expr [, expr] ...
-- 排序表达式
order_clause:
ORDER BY expr [ASC|DESC] [, expr [ASC|DESC]] ...
两种形式都定义了窗口函数应该如何处理查询行。它们的区别在于窗口是直接在OVER子句中定义,还是由查询中其他地方定义的命名窗口的引用提供:
-
在第一种情况下,窗口规范直接出现在OVER子句中的括号之间。
-
在第二种情况下,是由查询中其他地方的子句window_name 定义的窗口规范的名称
3、常用窗口函数
| 名称 | 说明 |
|---|---|
| CUME_DIST() | 累计分配值 |
| DENSE_RANK() | 当前行在其分区内的排名,没有间隙 |
| FIRST_VALUE() | 窗口框架第一行的参数值 |
| LAG() | 来自分区内滞后当前行的行的参数值 |
| LAST_VALUE() | 窗口框架最后一行的参数值 |
| LEAD() | 分区内行前导当前行的参数值 |
| NTH_VALUE() | 来自第 N 行窗口框架的参数值 |
| NTILE() | 其分区内当前行的桶数 |
| PERCENT_RANK() | 百分比排名值 |
| RANK() | 当前行在其分区内的排名,有间隙 |
| ROW_NUMBER() | 其分区内的当前行数 |
(1) CUME_DIST()
返回一个值在一组值中的累积分布;即分区值小于或等于当前行值的百分比。这表示在窗口分区的窗口排序中在当前行之前或与当前行对等的行数除以窗口分区中的总行数。返回值范围从 0 到 1。
此函数应用于ORDER BY将分区行排序为所需的顺序。如果没有ORDER BY,所有行都是对等的并且具有值 N/ N= 1,其中N是分区大小。
以下查询显示,将numbers表中的所有数据分为一组,对每组中的每行数据使用CUME_DIST()窗口函数:
mysql> SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
CUME_DIST() OVER w AS 'cume_dist',
PERCENT_RANK() OVER w AS 'percent_rank'
FROM numbers
WINDOW w AS (ORDER BY val);
+------+------------+--------------------+--------------+
| val | row_number | cume_dist | percent_rank |
+------+------------+--------------------+--------------+
| 1 | 1 | 0.2222222222222222 | 0 |
| 1 | 2 | 0.2222222222222222 | 0 |
| 2 | 3 | 0.3333333333333333 | 0.25 |
| 3 | 4 | 0.6666666666666666 | 0.375 |
| 3 | 5 | 0.6666666666666666 | 0.375 |
| 3 | 6 | 0.6666666666666666 | 0.375 |
| 4 | 7 | 0.8888888888888888 | 0.75 |
| 4 | 8 | 0.8888888888888888 | 0.75 |
| 5 | 9 | 1 | 1 |
+------+------------+--------------------+--------------+
(2) DENSE_RANK()
返回当前行在其分区中的排名,没有间隙。
此函数应用于ORDER BY将分区行排序为所需的顺序。没有ORDER BY,所有行都是对等的。
mysql> SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
RANK() OVER w AS 'rank',
DENSE_RANK() OVER w AS 'dense_rank'
FROM numbers
WINDOW w AS (ORDER BY val);
+------+------------+------+------------+
| val | row_number | rank | dense_rank |
+------+------------+------+------------+
| 1 | 1 | 1 | 1 |
| 1 | 2 | 1 | 1 |
| 2 | 3 | 3 | 2 |
| 3 | 4 | 4 | 3 |
| 3 | 5 | 4 | 3 |
| 3 | 6 | 4 | 3 |
| 4 | 7 | 7 | 4 |
| 4 | 8 | 7 | 4 |
| 5 | 9 | 9 | 5 |
+------+------------+------+------------+
(3) FIRST_VALUE(expr) [null_treatment]
返回当前分组中第一行的expr值
FIRST_VALUE返回第一行的值,LAST_VALUE返回最后一行的值,NTH_VALUE返回第N行的值
mysql> SELECT
time, subject, val,
FIRST_VALUE(val) OVER w AS 'first',
LAST_VALUE(val) OVER w AS 'last',
NTH_VALUE(val, 2) OVER w AS 'second',
NTH_VALUE(val, 4) OVER w AS 'fourth'
FROM observations
WINDOW w AS (PARTITION BY subject ORDER BY time
ROWS UNBOUNDED PRECEDING);
+----------+---------+------+-------+------+--------+--------+
| time | subject | val | first | last | second | fourth |
+----------+---------+------+-------+------+--------+--------+
| 07:00:00 | st113 | 10 | 10 | 10 | NULL | NULL |
| 07:15:00 | st113 | 9 | 10 | 9 | 9 | NULL |
| 07:30:00 | st113 | 25 | 10 | 25 | 9 | NULL |
| 07:45:00 | st113 | 20 | 10 | 20 | 9 | 20 |
| 07:00:00 | xh458 | 0 | 0 | 0 | NULL | NULL |
| 07:15:00 | xh458 | 10 | 0 | 10 | 10 | NULL |
| 07:30:00 | xh458 | 5 | 0 | 5 | 10 | NULL |
| 07:45:00 | xh458 | 30 | 0 | 30 | 10 | 30 |
| 08:00:00 | xh458 | 25 | 0 | 25 | 10 | 30 |
+----------+---------+------+-------+------+--------+--------+
(4) LAG(expr [, N[, default]]) [null_treatment]
返回当前分组内滞后当前行N行的expr值,如果没有这样的行,则返回default的值。如果N或default缺失,默认值分别为 1 和NULL
LAG()(和类似的 LEAD()函数)通常用于计算行之间的差异。以下查询显示了一组按时间排序的观察结果,以及相邻行的LAG()和 LEAD()值,以及当前行和相邻行之间的差异:
mysql> SELECT
t, val,
LAG(val) OVER w AS 'lag',
LEAD(val) OVER w AS 'lead',
val - LAG(val) OVER w AS 'lag diff',
val - LEAD(val) OVER w AS 'lead diff'
FROM series
WINDOW w AS (ORDER BY t);
+----------+------+------+------+----------+-----------+
| t | val | lag | lead | lag diff | lead diff |
+----------+------+------+------+----------+-----------+
| 12:00:00 | 100 | NULL | 125 | NULL | -25 |
| 13:00:00 | 125 | 100 | 132 | 25 | -7 |
| 14:00:00 | 132 | 125 | 145 | 7 | -13 |
| 15:00:00 | 145 | 132 | 140 | 13 | 5 |
| 16:00:00 | 140 | 145 | 150 | -5 | -10 |
| 17:00:00 | 150 | 140 | 200 | 10 | -50 |
| 18:00:00 | 200 | 150 | NULL | 50 | NULL |
+----------+------+------+------+----------+-----------+
(5) LAST_VALUE(expr) [null_treatment]
返回当前分组中最后一行的expr值
mysql> SELECT
time, subject, val,
FIRST_VALUE(val) OVER w AS 'first',
LAST_VALUE(val) OVER w AS 'last',
NTH_VALUE(val, 2) OVER w AS 'second',
NTH_VALUE(val, 4) OVER w AS 'fourth'
FROM observations
WINDOW w AS (PARTITION BY subject ORDER BY time
ROWS UNBOUNDED PRECEDING);
+----------+---------+------+-------+------+--------+--------+
| time | subject | val | first | last | second | fourth |
+----------+---------+------+-------+------+--------+--------+
| 07:00:00 | st113 | 10 | 10 | 10 | NULL | NULL |
| 07:15:00 | st113 | 9 | 10 | 9 | 9 | NULL |
| 07:30:00 | st113 | 25 | 10 | 25 | 9 | NULL |
| 07:45:00 | st113 | 20 | 10 | 20 | 9 | 20 |
| 07:00:00 | xh458 | 0 | 0 | 0 | NULL | NULL |
| 07:15:00 | xh458 | 10 | 0 | 10 | 10 | NULL |
| 07:30:00 | xh458 | 5 | 0 | 5 | 10 | NULL |
| 07:45:00 | xh458 | 30 | 0 | 30 | 10 | 30 |
| 08:00:00 | xh458 | 25 | 0 | 25 | 10 | 30 |
+----------+---------+------+-------+------+--------+--------+
(6) LEAD(expr [, N[, default]]) [null_treatment]
返回当前分组内领先于当前行的N行的expr值。如果没有这样的行,则返回值为 default。如果 N或 default缺失,默认值分别为 1 和NULL。
mysql> SELECT
t, val,
LAG(val) OVER w AS 'lag',
LEAD(val) OVER w AS 'lead',
val - LAG(val) OVER w AS 'lag diff',
val - LEAD(val) OVER w AS 'lead diff'
FROM series
WINDOW w AS (ORDER BY t);
+----------+------+------+------+----------+-----------+
| t | val | lag | lead | lag diff | lead diff |
+----------+------+------+------+----------+-----------+
| 12:00:00 | 100 | NULL | 125 | NULL | -25 |
| 13:00:00 | 125 | 100 | 132 | 25 | -7 |
| 14:00:00 | 132 | 125 | 145 | 7 | -13 |
| 15:00:00 | 145 | 132 | 140 | 13 | 5 |
| 16:00:00 | 140 | 145 | 150 | -5 | -10 |
| 17:00:00 | 150 | 140 | 200 | 10 | -50 |
| 18:00:00 | 200 | 150 | NULL | 50 | NULL |
+----------+------+------+------+----------+-----------+
(7) NTH_VALUE(expr, N) [from_first_last] [null_treatment]
mysql> SELECT
time, subject, val,
FIRST_VALUE(val) OVER w AS 'first',
LAST_VALUE(val) OVER w AS 'last',
NTH_VALUE(val, 2) OVER w AS 'second',
NTH_VALUE(val, 4) OVER w AS 'fourth'
FROM observations
WINDOW w AS (PARTITION BY subject ORDER BY time
ROWS UNBOUNDED PRECEDING);
+----------+---------+------+-------+------+--------+--------+
| time | subject | val | first | last | second | fourth |
+----------+---------+------+-------+------+--------+--------+
| 07:00:00 | st113 | 10 | 10 | 10 | NULL | NULL |
| 07:15:00 | st113 | 9 | 10 | 9 | 9 | NULL |
| 07:30:00 | st113 | 25 | 10 | 25 | 9 | NULL |
| 07:45:00 | st113 | 20 | 10 | 20 | 9 | 20 |
| 07:00:00 | xh458 | 0 | 0 | 0 | NULL | NULL |
| 07:15:00 | xh458 | 10 | 0 | 10 | 10 | NULL |
| 07:30:00 | xh458 | 5 | 0 | 5 | 10 | NULL |
| 07:45:00 | xh458 | 30 | 0 | 30 | 10 | 30 |
| 08:00:00 | xh458 | 25 | 0 | 25 | 10 | 30 |
+----------+---------+------+-------+------+--------+--------+
返回当前分组中第N行的expr值。如果没有这样的行,则返回值为 NULL。
(8) NTILE(N)
**将分区划分为N组(桶),为分区中的每一行分配其桶号,并返回其分区内当前行的桶号**。例如,如果 N为 4, NTILE()则将行分成四个桶。如果N为 100, NTILE()则将行分成 100 个桶。
对于列中的一组值,以下查询显示了 val将行分成两组或四组所产生的百分位值。作为参考,查询还使用以下方式显示行号 ROW_NUMBER():
mysql> SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
NTILE(2) OVER w AS 'ntile2',
NTILE(4) OVER w AS 'ntile4'
FROM numbers
WINDOW w AS (ORDER BY val);
+------+------------+--------+--------+
| val | row_number | ntile2 | ntile4 |
+------+------------+--------+--------+
| 1 | 1 | 1 | 1 |
| 1 | 2 | 1 | 1 |
| 2 | 3 | 1 | 1 |
| 3 | 4 | 1 | 2 |
| 3 | 5 | 1 | 2 |
| 3 | 6 | 2 | 3 |
| 4 | 7 | 2 | 3 |
| 4 | 8 | 2 | 4 |
| 5 | 9 | 2 | 4 |
+------+------------+--------+--------+
(9) PERCENT_RANK()
返回分区值小于当前行中的值的百分比,不包括最大值。返回值范围从 0 到 1,表示行相对排名,计算结果如下公式,其中rank是行排名, rows是分区行数:
(rank - 1) / (rows - 1)
此函数应用于ORDER BY将分区行排序为所需的顺序。没有ORDER BY,所有行都是对等的。
mysql> SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
CUME_DIST() OVER w AS 'cume_dist',
PERCENT_RANK() OVER w AS 'percent_rank'
FROM numbers
WINDOW w AS (ORDER BY val);
+------+------------+--------------------+--------------+
| val | row_number | cume_dist | percent_rank |
+------+------------+--------------------+--------------+
| 1 | 1 | 0.2222222222222222 | 0 |
| 1 | 2 | 0.2222222222222222 | 0 |
| 2 | 3 | 0.3333333333333333 | 0.25 |
| 3 | 4 | 0.6666666666666666 | 0.375 |
| 3 | 5 | 0.6666666666666666 | 0.375 |
| 3 | 6 | 0.6666666666666666 | 0.375 |
| 4 | 7 | 0.8888888888888888 | 0.75 |
| 4 | 8 | 0.8888888888888888 | 0.75 |
| 5 | 9 | 1 | 1 |
+------+------------+--------------------+--------------+
(10) RANK()
返回当前行在其分区中的排名,有间隔。结果是不连续的排名数字。
此函数应用于ORDER BY将分区行排序为所需的顺序。没有ORDER BY,所有行都是对等的。
mysql> SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
RANK() OVER w AS 'rank',
DENSE_RANK() OVER w AS 'dense_rank'
FROM numbers
WINDOW w AS (ORDER BY val);
+------+------------+------+------------+
| val | row_number | rank | dense_rank |
+------+------------+------+------------+
| 1 | 1 | 1 | 1 |
| 1 | 2 | 1 | 1 |
| 2 | 3 | 3 | 2 |
| 3 | 4 | 4 | 3 |
| 3 | 5 | 4 | 3 |
| 3 | 6 | 4 | 3 |
| 4 | 7 | 7 | 4 |
| 4 | 8 | 7 | 4 |
| 5 | 9 | 9 | 5 |
+------+------------+------+------------+
(11) ROW_NUMBER() over_clause
返回其分区中当前行的编号。行数范围从 1 到分区行数。
ORDER BY影响行编号的顺序。没有ORDER BY,行编号是不确定的。
mysql> SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
CUME_DIST() OVER w AS 'cume_dist',
PERCENT_RANK() OVER w AS 'percent_rank'
FROM numbers
WINDOW w AS (ORDER BY val);
+------+------------+--------------------+--------------+
| val | row_number | cume_dist | percent_rank |
+------+------------+--------------------+--------------+
| 1 | 1 | 0.2222222222222222 | 0 |
| 1 | 2 | 0.2222222222222222 | 0 |
| 2 | 3 | 0.3333333333333333 | 0.25 |
| 3 | 4 | 0.6666666666666666 | 0.375 |
| 3 | 5 | 0.6666666666666666 | 0.375 |
| 3 | 6 | 0.6666666666666666 | 0.375 |
| 4 | 7 | 0.8888888888888888 | 0.75 |
| 4 | 8 | 0.8888888888888888 | 0.75 |
| 5 | 9 | 1 | 1 |
+------+------------+--------------------+--------------+
4、窗口函数框架
- 与窗口函数一起使用窗口可以包含一个框架子句。框架是当前分组的子集,框架子句说明了如何定义分组的子集
(1) 框架子句语法
-- 框架子句
frame_clause:
frame_units frame_extent
-- frame_units指定了当前行和框架行关系的种类
frame_units:
{ROWS | RANGE}
- ROWS:框架是由起始行和终止行的位置定义
- RANGE:框架是由起始行、终止行的值区间定义
frame_extent指定了框架的起始行和终止行。可以只指定起始行(此时,默认结束行为当前行);或者使用BETWEEN指定起始行和终止行
-- frame_extent指定了框架行的起点和终点
frame_extent:
{frame_start | frame_between}
-- frame_between指定了框架行的范围
frame_between:
BETWEEN frame_start AND frame_end
-- 框架起始行、框架终止行
frame_start, frame_end: {
CURRENT ROW
| UNBOUNDED PRECEDING
| UNBOUNDED FOLLOWING
| expr PRECEDING
| expr FOLLOWING
}
使用BETWEEN语法,frame_start不得晚于frame_end
frame_start和frame_end值具有以下含义:
- CURRENT ROW:对于ROWS,框架行是当前行;对于RANGE框架行是和当前行的值相等的行
- UNBOUNDED PRECEDING:对于ROWS,框架行是分组第一行到当前行;对于RANGE,框架行是数值介于分组第一行、当前行的行
- UNBOUNDED FOLLOWING:对于ROWS,框架行是分组最后一行到当前行;对于RANGE,框架行是数值介于分组最后一行、当前行的行
- expr PRECEDING:对于ROWS,框架行是当前行之前的expr行到当前行;对于RANGE,框架行是数值介于当前行之前的expr行到当前行的行
- expr FOLLOWING:对于ROWS,框架行是当前行之后的expr行到当前行;对于RANGE,框架行是数值介于当前行之后的expr行到当前行的行
以下查询演示 FIRST_VALUE(), LAST_VALUE()和NTH_VALUE()。
分别获取分组内第一行到当前行的第一个值、最后一个值、第二个值、第四个值
(2) 框架子句用法
mysql> SELECT
time, subject, val,
FIRST_VALUE(val) OVER w AS 'first',
LAST_VALUE(val) OVER w AS 'last',
NTH_VALUE(val, 2) OVER w AS 'second',
NTH_VALUE(val, 4) OVER w AS 'fourth'
FROM observations
WINDOW w AS (PARTITION BY subject ORDER BY time
ROWS UNBOUNDED PRECEDING);
+----------+---------+------+-------+------+--------+--------+
| time | subject | val | first | last | second | fourth |
+----------+---------+------+-------+------+--------+--------+
| 07:00:00 | st113 | 10 | 10 | 10 | NULL | NULL |
| 07:15:00 | st113 | 9 | 10 | 9 | 9 | NULL |
| 07:30:00 | st113 | 25 | 10 | 25 | 9 | NULL |
| 07:45:00 | st113 | 20 | 10 | 20 | 9 | 20 |
| 07:00:00 | xh458 | 0 | 0 | 0 | NULL | NULL |
| 07:15:00 | xh458 | 10 | 0 | 10 | 10 | NULL |
| 07:30:00 | xh458 | 5 | 0 | 5 | 10 | NULL |
| 07:45:00 | xh458 | 30 | 0 | 30 | 10 | 30 |
| 08:00:00 | xh458 | 25 | 0 | 25 | 10 | 30 |
+----------+---------+------+-------+------+--------+--------+
以下查询演示了SUM()和AVG()获取框架行内的总分和平均分
mysql> SELECT
time, subject, val,
-- 分组内第一行到当前行的总分
SUM(val) OVER (PARTITION BY subject ORDER BY time
ROWS UNBOUNDED PRECEDING)
AS running_total,
-- 分组内当前行的上一行到下一行的平均分
AVG(val) OVER (PARTITION BY subject ORDER BY time
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
AS running_average
FROM observations;
+----------+---------+------+---------------+-----------------+
| time | subject | val | running_total | running_average |
+----------+---------+------+---------------+-----------------+
| 07:00:00 | st113 | 10 | 10 | 9.5000 |
| 07:15:00 | st113 | 9 | 19 | 14.6667 |
| 07:30:00 | st113 | 25 | 44 | 18.0000 |
| 07:45:00 | st113 | 20 | 64 | 22.5000 |
| 07:00:00 | xh458 | 0 | 0 | 5.0000 |
| 07:15:00 | xh458 | 10 | 10 | 5.0000 |
| 07:30:00 | xh458 | 5 | 15 | 15.0000 |
| 07:45:00 | xh458 | 30 | 45 | 20.0000 |
| 08:00:00 | xh458 | 25 | 70 | 27.5000 |
+----------+---------+------+---------------+-----------------+
(3) 默认框架子句
在没有显示指定框架子句的情况下,默认的框架取决于是否存在ORDER BY子句
- 有ORDER BY子句:框架行为数值介于当前分组第一行到当前行的值
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
- 没有ORDER BY子句:框架行为分组内所有行
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
(4) 可以使用框架子句的窗口函数
聚合函数可以使用框架子句
可以使用框架子句的窗口函数
- FIRST_VALUE()
- LAST_VALUE()
- NTH_VALUE()
MySQL允许以下函数使用框架,但会忽略框架子句
- CUME_DIST()
- DENSE_RANK()
- LAG()
- LEAD()
- NTILE()
- PERCENT_RANK()
- RANK()
- ROW_NUMBER()
三、控制流函数
| 名称 | 说明 |
|---|---|
| CASE | 类似于Java中的switch-case |
| IF | 类似于三目运算符 |
| IFNULL | 如果expr1为NULL,则返回expr2 |
| NULIF | 如果expr1=expr2,则返回NULL |
1、NULLIF
- 语法
NULLIF(expr1,expr2)
- 用法
如果expr1=expr2,则返回NULL,否则返回expr1
mysql> SELECT NULLIF(1,1);
-> NULL
mysql> SELECT NULLIF(1,2);
-> 1
四、字符串函数
1、substr、substring
substr和subtring用法一样,都是用来截取字符串:
第一个参数是要截取的字符串,第二个参数是开始截取的位置,第三个参数是截取的长度
第一个字符的下标从1开始
SUBSTR(str,pos), , , SUBSTR(str FROM pos)SUBSTR(str,pos,len)SUBSTR(str FROM pos FOR len)
mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically'
mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica'
mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila'
mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki'
mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki'
需要注意的是,当第二个参数为负数时,则总字符串右边开始截取
2、substring_index
SUBSTRING_INDEX(str,delim,count)
从【str】中获取分隔符【delim】出现次数在【count】之前的字符串
count为正数,从左边开始计数;count为负数,从右边开始计数
mysql> SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);
-> 'www.mysql'
mysql> SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2);
-> 'mysql.com'
五、其他用法
1、JOIN USING(COLUMN_NAME)
SELECT * FROM score LEFT JOIN course USING ( c_id );
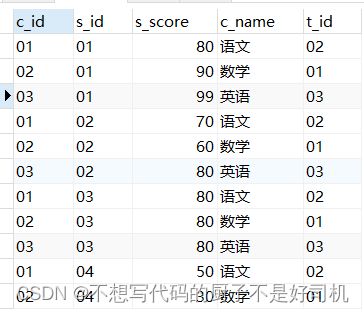
使用join using(column_name)等同于join on a.c_id = b.c_id,但是前者会将c_id放在第一列,且对c_id去重
2、WITH AS
如果一整句查询中多个子查询都需要使用同一个子查询的结果,那么就可以用with as,将共用的子查询提取出来,加个别名。后面查询语句可以直接用,对于大量复杂的SQL语句起到了很好的优化作用。
- 相当于一个临时表,要与select配合使用。
- 可以有多个临时表,写一个with就可以,用逗号隔开
- with子句要用括号括起来
WITH tmp1 AS ( SELECT * FROM student ),
tmp2 AS ( SELECT * FROM score )
SELECT
*
FROM
tmp1
JOIN tmp2 USING ( s_id );