mysql学习(五)-- 数学、日期、字符串以及窗口函数的使用
1.聚合函数
1.1 count():求数量
count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
count(列名)和count(*)的区别:
count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
1.2 sum():求和
1.3 min():最小值
1.4 max():最大值
1.5 avg():平均值
1.6 group_concat():行的合并
1.6.1 解释:
group_concat()函数首先根据group by指定的列进行分组,并且用分隔符分隔,将同一个同组中的值连起来,返回一个字符串结果
1.6.2 格式:
group_concat([distinct] 字段名 [order by 排序字段 asc/desc] [separator '分隔符'])
说明:
- 使用distinct可以排除重复值;
- 如果需要对结果中的值进行排序,可以使用order by子句
- separator是一个字符串值,默认为逗号
1.6.3 案例:
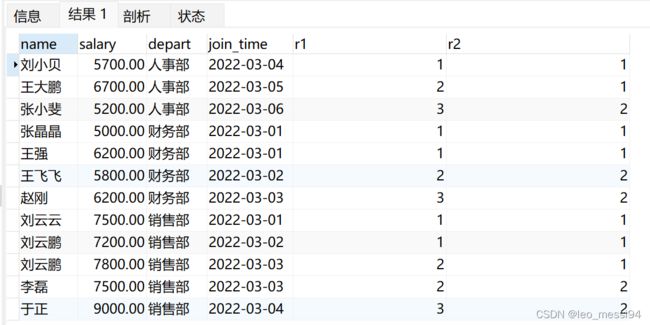
表:

查询语句:
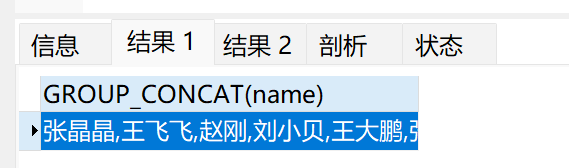
select GROUP_CONCAT(name) from t_user;
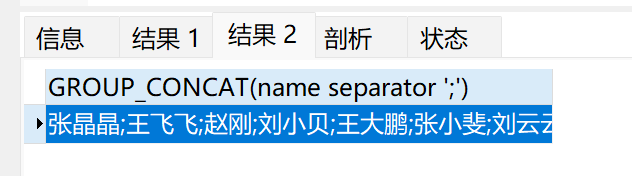
select GROUP_CONCAT(name separator ';') from t_user;
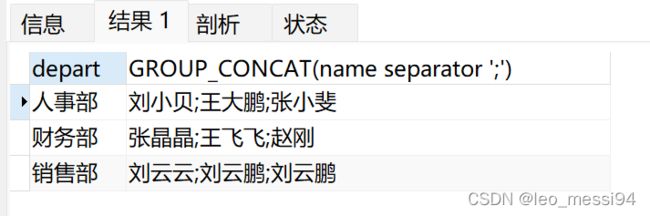
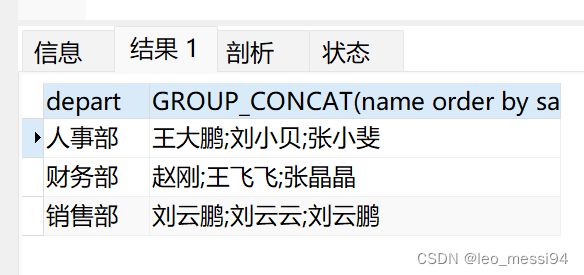
select depart, GROUP_CONCAT(name separator ';') from t_user group by depart;
select depart, GROUP_CONCAT(name order by salary desc separator ';') from t_user group by depart;
结果:
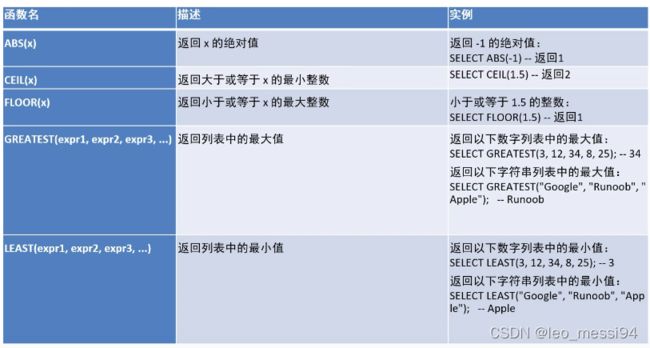
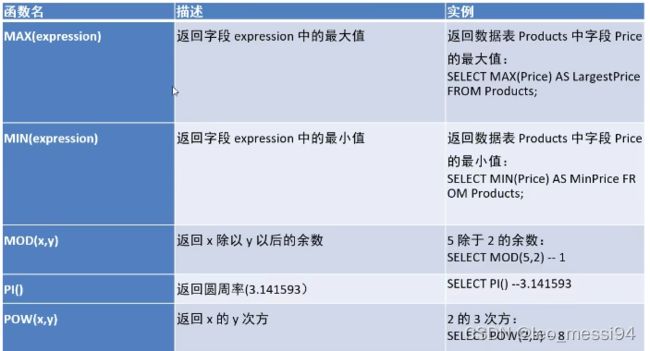
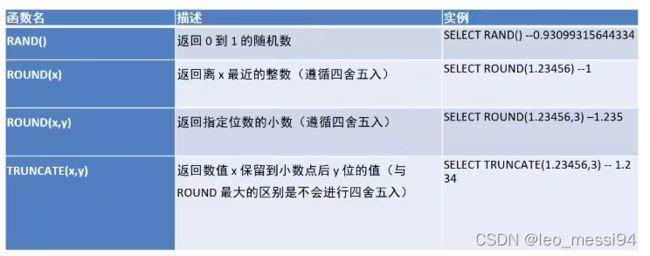
2. 数学函数
2.1 Rand()函数:
- 用于获取0到1之间的随机数;
select RAND(), RAND(),RAND();
结果集:

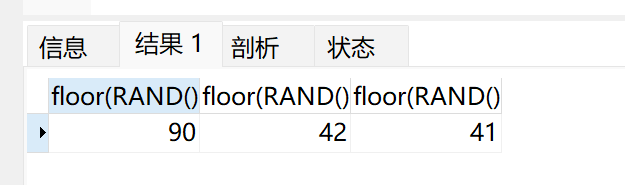
- 获取0到100之间的随机数:
select floor(RAND() * 100),floor(RAND() * 100),floor(RAND() * 100);
- 获取一个随机的结果集:
select * from words order by RAND() limit 5;
结果集1: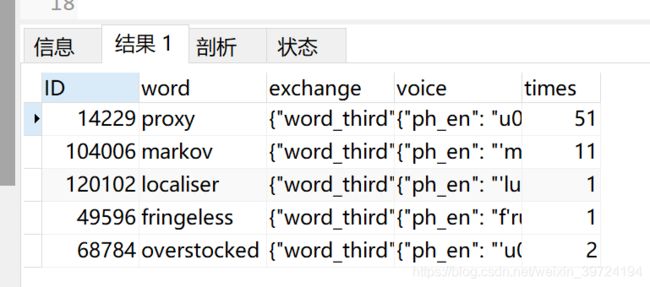
结果集2:

3. 字符串函数
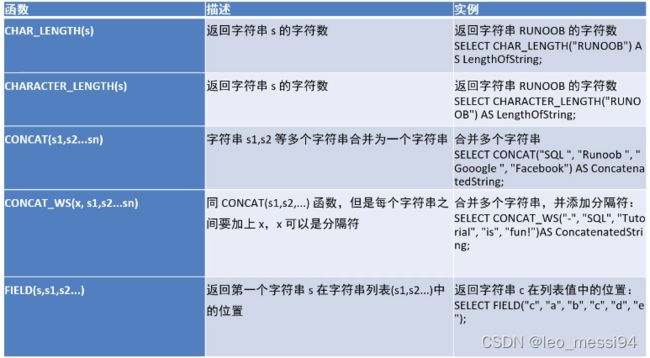
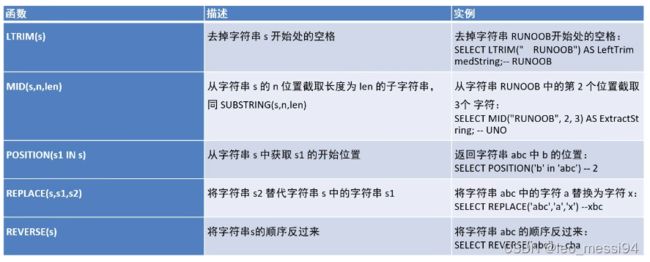

3.1 char_length()函数:
注意下char_length和length()的区别:
-- 1. CHAR_LENGTH(str)
select CHAR_LENGTH('hello'); -- 5
select CHAR_LENGTH('你好'); -- 2
select LENGTH('hello'); -- 5
select LENGTH('你好'); -- 6
3.2 field()函数:
需要全匹配:
-- 3. field()
select FIELD('a','a','b','c'); -- 1
select FIELD('a','aa','a','b','c'); -- 2
4. 日期函数
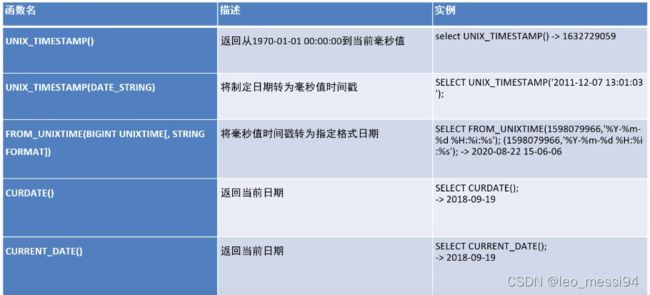
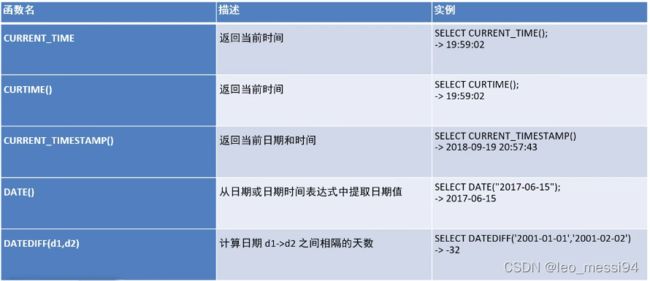

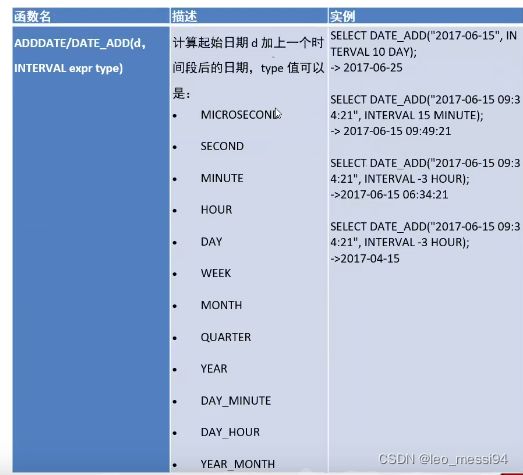
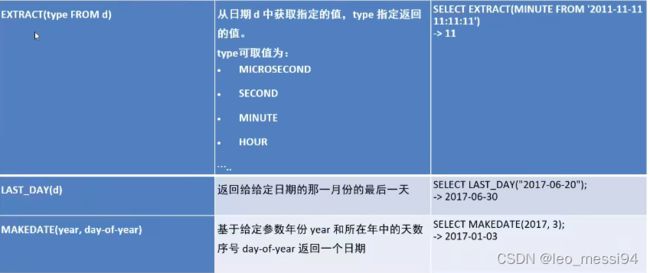
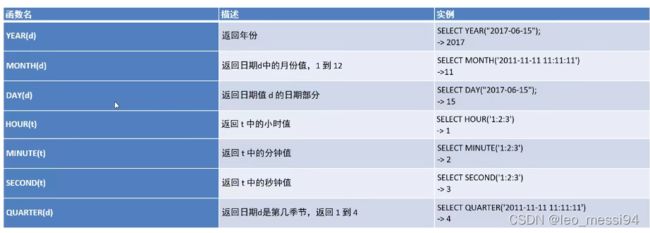


4.1 日期函数的使用,获取昨天今天等
今天
select * from 表名 where to_days(时间字段名) = to_days(now());
昨天
SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1
7天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名)
近30天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名)
本月
SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) , '%Y%m' )
上一月
SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1
#查询本季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(now());
#查询上季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(DATE_SUB(now(),interval 1 QUARTER));
#查询本年数据
select * from `ht_invoice_information` where YEAR(create_date)=YEAR(NOW());
#查询上年数据
select * from `ht_invoice_information` where year(create_date)=year(date_sub(now(),interval 1 year));
查询当前这周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now());
查询上周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now())-1;
查询当前月份的数据
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(now(),'%Y-%m')
查询距离当前现在6个月的数据
select name,submittime from enterprise where submittime between date_sub(now(),interval 6 month) and now();
查询上个月的数据
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(DATE_SUB(curdate(), INTERVAL 1 MONTH),'%Y-%m')
select * from ` user ` where DATE_FORMAT(pudate, ' %Y%m ' ) = DATE_FORMAT(CURDATE(), ' %Y%m ' ) ;
select * from user where WEEKOFYEAR(FROM_UNIXTIME(pudate,'%y-%m-%d')) = WEEKOFYEAR(now())
select *
from user
where MONTH (FROM_UNIXTIME(pudate, ' %y-%m-%d ' )) = MONTH (now())
select *
from [ user ]
where YEAR (FROM_UNIXTIME(pudate, ' %y-%m-%d ' )) = YEAR (now())
and MONTH (FROM_UNIXTIME(pudate, ' %y-%m-%d ' )) = MONTH (now())
select *
from [ user ]
where pudate between 上月最后一天
and 下月第一天
where date(regdate) = curdate();
select * from test where year(regdate)=year(now()) and month(regdate)=month(now()) and day(regdate)=day(now())
SELECT date( c_instime ) ,curdate( )
FROM `t_score`
WHERE 1
LIMIT 0 , 30
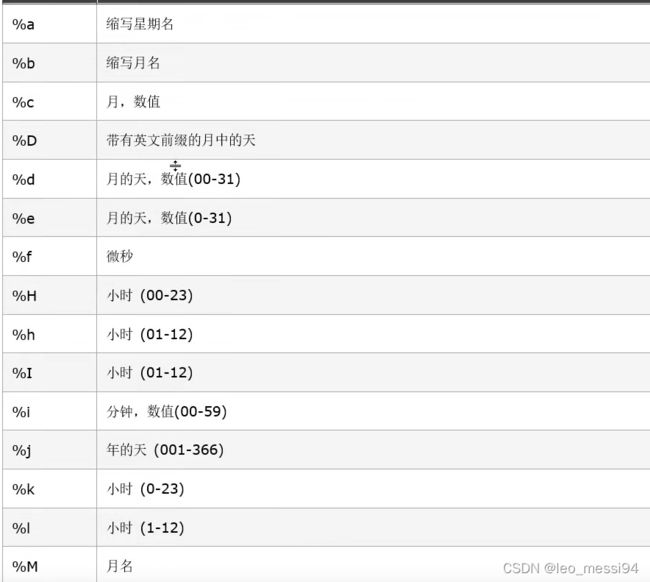
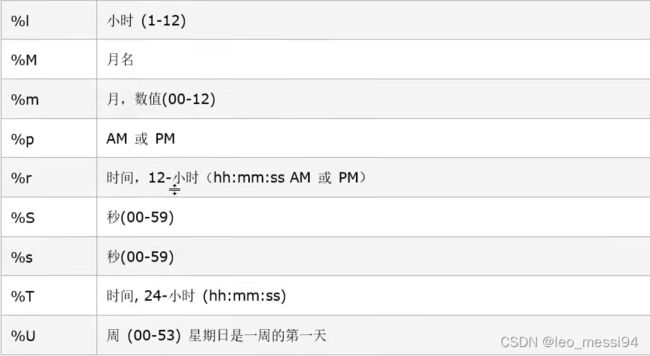
4.2 from_unixtime的参数:

4.3 获取时间差值:
timediff:只返回时分秒
select DATEDIFF(now(),'2017-03-04'), TIMEDIFF('17:25:38','17:25:30'),TIMEDIFF('17:25:38','12:25:30'), TIMEDIFF(NOW(),'2020-03-04 17:25:30');

5. if逻辑判断语句:
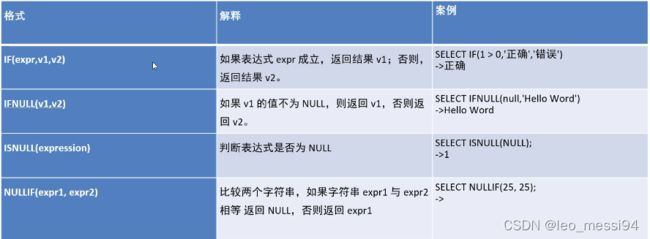
6. 控制流函数

7. 窗口函数
7.1 介绍:
- mysql8.0新增窗口函数,窗口函数又称开窗函数
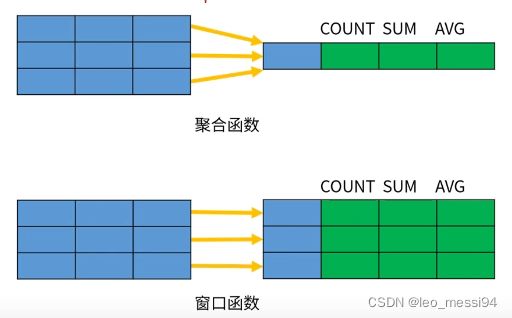
- 非聚合窗口函数式相对于窗口函数来说的。聚合函数是对一组数据计算后返回单个值(即分组),非聚合函数一次只会处理一行数。窗口聚合函数在行记录上计算某个字段的结果时,可将窗口范围内的数据输入到聚合函数中,并不改变行数。
7.2 分类:
7.3 语法结构

其中window_function是窗口函数的名称;expr是参数,有些函数不需要参数;over子句包含三个选项:
- 分区(PARTITION BY。。):
分区选项用于将数据行拆分成多个分区(组),它的作用类似于group by分组。如果忽略了partition by,所有的数据作为一个组进行计算 - 排序(ORDER BY)
over子句中的order by选项用于指定分区内的排序方式,与order by子句作用类似 - 窗口大小(fram_clause)
fram_clause选项作用于在当前分区内指定一个计算窗口,也就是一个与当前行相关的数据子集
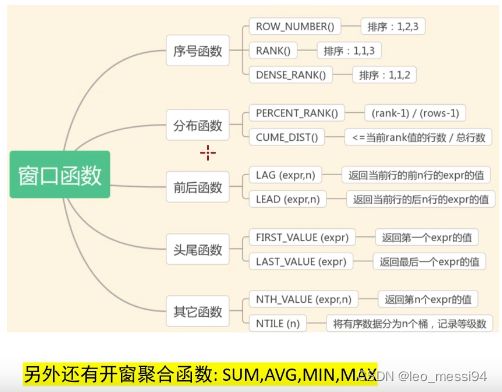
7.4 序号函数
序号函数可以用来实现分组排序,并添加序号,主要有三个:
- ROW_NUMBER()
- RANK()
- DENSE_RANK()
格式:

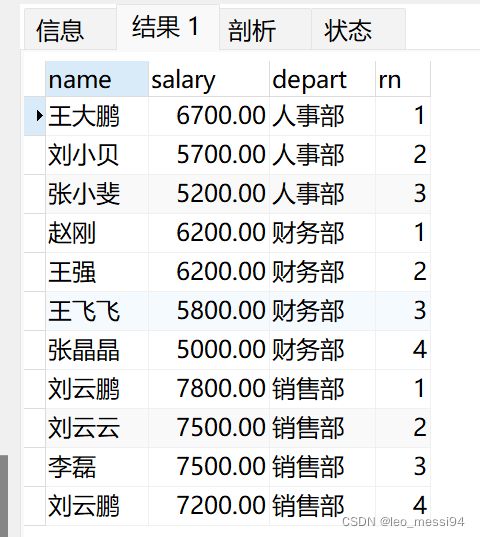
7.4.1 ROW_NUMBER()
查询:
SELECT name,salary,depart,
row_number() over(partition by depart order by salary desc) as rn
from t_user ;
结果:
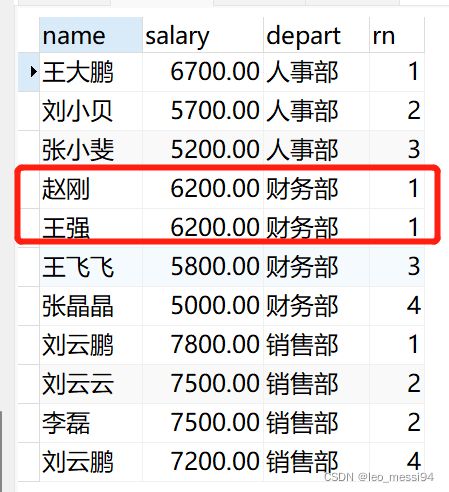
7.4.2 rank()
查询:
SELECT name,salary,depart,
rank() over(partition by depart order by salary desc) as rn
from t_user ;
结果:可以看到rank在排序的时候,如果排序字段相等,就并列排名;如果有并列的下一位排名的时候,就是去掉并列人数进行排名。
7.4.3 DENSE_RANK()
代码:
SELECT name,salary,depart,
dense_rank() over(partition by depart order by salary desc) as rn
from t_user ;
结果:可以看到并列之后还是根据并列的名词来排名

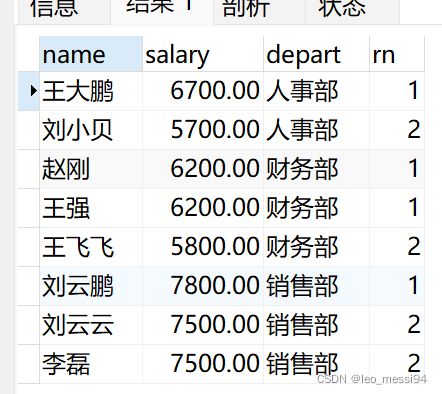
7.4.4 练习:查询每个部门薪资前2的:
select * from
(SELECT name,salary,depart,dense_rank() over(partition by depart order by salary desc) as rn from t_user ) a
where a.rn < 3
7.4.5 不进行分组排序
不加PARTITION BY表示全局排序:
SELECT name,salary,depart,row_number() over(order by salary desc) as rn from t_user ;
结果:

7.5 聚合函数
在窗口中每条记录动态地应用聚合函数,可以动态计算在指定的窗口内的各种聚合函数值,聚合函数主要有:
- sum()
- avg()
- max()
- min()
- count()
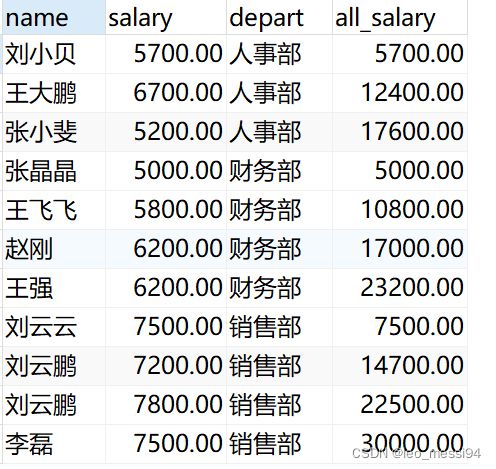
7.5.1 sum()
示例一:order by id
select name,salary,depart,
sum(salary) over(PARTITION by depart order by id) as all_salary
from t_user
结果:可以看到,统计的salary是根据每一组的数据进行了累加
示例2:order by salary:
select name,salary,depart,
sum(salary) over(PARTITION by depart order by salary) as order_salary
from t_user
结果:可以看到由于薪资有并列,所以总和是并列相加后的值

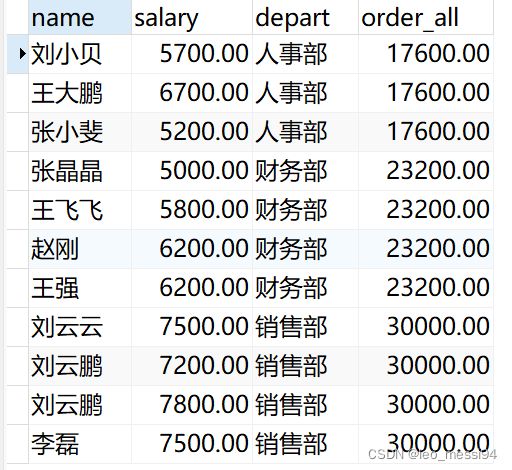
示例3:不加order by:
select name,salary,depart,
sum(salary) over(PARTITION by depart) as order_all
from t_user
结果:可以看到是总数相加,通过这个我们可以计算所占比例等
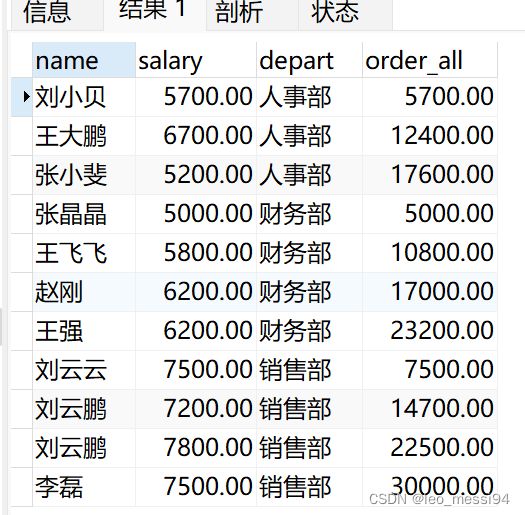
示例4:指定范围:从开头到当前行
select name,salary,depart,
sum(salary) over(PARTITION by depart order by id rows BETWEEN unbounded preceding and current row) as order_all
from t_user
示例5:从当前行的上面3行开始相加,加到当前行
select name,salary,depart,
sum(salary) over(PARTITION by depart order by id rows BETWEEN 3 preceding and current row) as order_all
from t_user;
结果:可以看出于正的总和是于正上面3行加上自己的总和,不算刘云云,因为刘云云是上面四行了

示例6:向上3行和向下1行:
select name,salary,depart,
sum(salary) over(PARTITION by depart order by id rows BETWEEN 3 preceding and 1 following) as order_all
from t_user;
结果:通过李磊可以看出,总和=上面3行+自己+下面一行
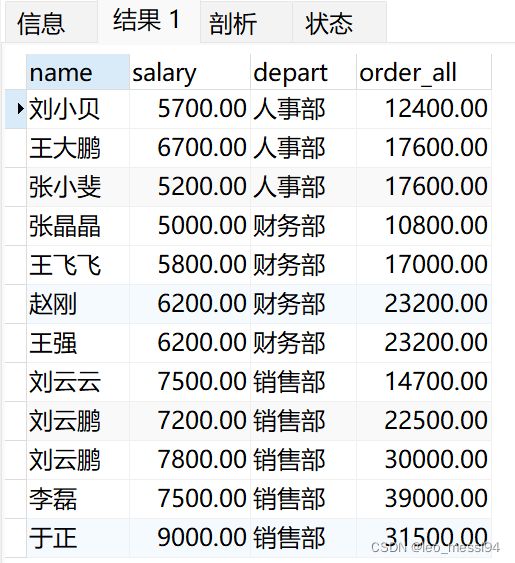
示例7:当前行加到最后:
select name,salary,depart,
sum(salary) over(PARTITION by depart order by id rows BETWEEN current row and unbounded following) as order_all
from t_user;
结果:
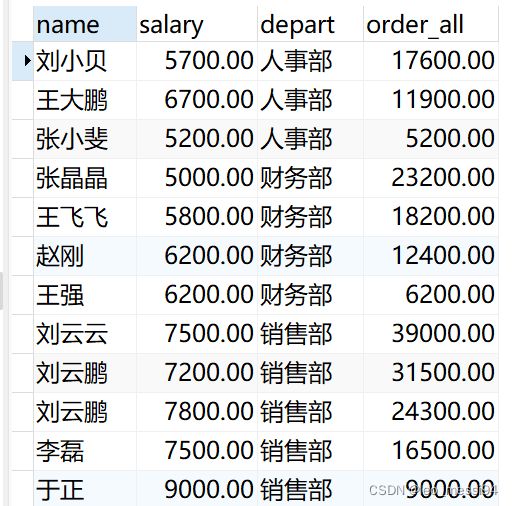
7.5.2 其他的几个作用相似,不再演示
7.6 分布函数:
包括cume_dist和percent_rank
7.6.1 cume_dist:
- 用途:分组内小于、等于当前rank值的行数/分组内总行数
- 应用场景:查询小于等于当前薪资的比例
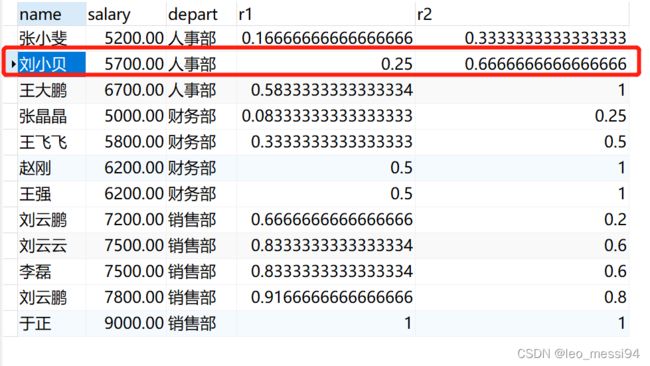
应用:
select name,salary,depart,
-- 把所有数据当成一组
cume_dist() over(order by salary) as r1,
-- 根据部门进行分组
cume_dist() over(PARTITION by depart order by salary) as r2
from t_user;
结果:
- 总人数:12人
- 以刘小贝来看
- r1:比刘小贝工资少的人有2个,加上刘小贝一共3人,结果即3/12=0.25
- r2:同一组内比刘小贝少的人有1个,加上刘小贝共2人,结果即2/3=0.6666
7.6.2 percent_rank:
- 用途:每行按照公式(rank-1)/(row-1)进行计算。其中,rank为Rank()函数产生的序号,rows为当前窗口的记录总行数
- 应用场景:不常用
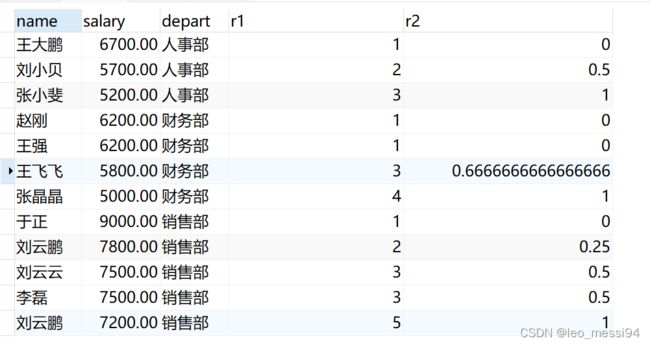
应用:
select name,salary,depart,
rank() over(PARTITION by depart order by salary desc) as r1,
percent_rank() over(PARTITION by depart order by salary desc) as r2
from t_user;
结果说明:即用rank排序的值减去1之后除以总数减去1之后的值
- 第一行:(rank - 1) / (总人数 - 1) 即 (1 - 1) / (3- 1) = 0
- 第二行:(2- 1) / (3 - 1) = 0.5
- 第三行:(3- 1) / (3 - 1) = 1
7.7 前后函数
包括lag和lead
- 用途:返回位于当前行的前n行(LAG(expr,n))或后n行(LEAD(expr,n))的expr值
- 应用场景:查询前1名同学的成绩和当前同学成绩的差值
应用:
select name,salary,depart,
-- 相当于把上一行的薪资,放到了自己的那一行,用作比较来进行一些其他操作
-- 3000是给定的一个默认值,上一行的默认值,如果不给默认为null
lag(salary, 1, 3000) over(PARTITION by depart order by salary) as r1,
-- 相当于把上2行的薪资,放到了自己的那一行
lag(salary, 2) over(PARTITION by depart order by salary) as r2
from t_user;
-- lead就是下一个,不多演示
结果:

7.8 头尾函数:
包括first_value和last_value
- 用途:返回第一个(FIRST_VALUE(expr))和最后一个(LAST_VALUE(expr))expr的值
- 应用场景:截止到目前,按照日期排序查询第一个入职和最后一个入职员工的薪资
应用:
select name,salary,depart,join_time,
-- 到今天为止,第一个入职的薪资
first_value(salary) over(PARTITION by depart order by join_time) as r1,
-- 到今天为止,最后一个入职的薪资
last_value(salary) over(PARTITION by depart order by join_time) as r2
from t_user;
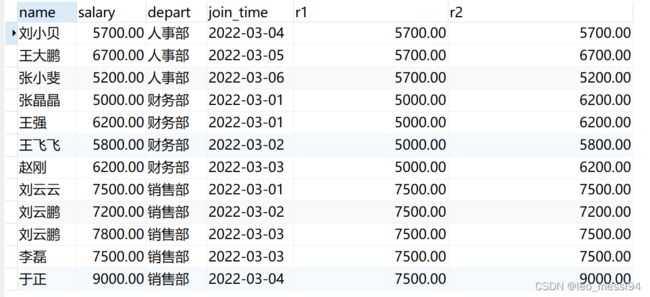
7.9 其他函数
包括nth_value(expr,n),ntile(n)
7.9.1 nth_value(expr,n)
- 用途:返回窗口中第n个expr的值,expr可以是表达式,也可以是别名
- 应用场景:截止到当前薪资,显示每个员工的薪资中排名第二或者第三的薪资
应用:
select name,salary,depart,join_time,
-- 到今天为止,按照入职日期排名第二的薪资
nth_value(salary, 2) over(PARTITION by depart order by join_time) as r1,
-- 到今天为止,按照入职日期排名第三的薪资
nth_value(salary, 3) over(PARTITION by depart order by join_time) as r2
from t_user;

7.9.2 ntile(n)
- 用途:将分区中的有序数据分为n个等级,记录等级数
- 应用场景:将每个部门员工按照入职日期分成3组
应用:
select name,salary,depart,join_time,
-- 根据日期把数据分为3组, 平均分配,
ntile(3) over(PARTITION by depart order by join_time) as r1,
-- 根据日期把数据分为2组,优先前面分配(即向上取整:3/2 = 2,5/2= 3,4/3= 2)
ntile(2) over(PARTITION by depart order by join_time) as r2
from t_user;
结果: