2023 年牛客多校第九场题解
B Semi-Puzzle: Brain Storm
题意:给定 a , m a,m a,m,构造一个非负整数 u u u,使得 a u ≡ u ( m o d m ) a^u \equiv u \pmod m au≡u(modm)。 1 ≤ a < m ≤ 1 0 9 1 \le a
解法:首先定义记号 ∞ a ^\infty a ∞a 表示 a a a ⋯ a^{a^{a^\cdots}} aaa⋯,即 a a a 叠无穷多层指数塔。首先不难注意到一个最简单的性质:
a ∞ a = ∞ a a^{^\infty a}=^\infty a a∞a=∞a
这个数字显然是不可计算的无穷大,但是考虑在模意义下,由于模运算内参与运算的元素个数有限,并且由下面的扩展欧拉定理:
a b ≡ { a b m o d φ ( m ) , gcd ( a , m ) = 1 a b , gcd ( a , m ) ≠ 1 , b ≤ φ ( m ) a b m o d φ ( m ) + φ ( m ) , gcd ( a , m ) ≠ 1 , b > φ ( m ) a^b\equiv \begin{aligned} \begin{cases} a^{b \bmod \varphi(m)}, &\gcd(a,m)=1\\ a^b, &\gcd(a,m) \ne1, b \le \varphi(m)\\ a^{b \bmod \varphi(m)+\varphi(m)}, &\gcd(a, m) \ne 1, b>\varphi(m) \end{cases} \end{aligned} ab≡⎩ ⎨ ⎧abmodφ(m),ab,abmodφ(m)+φ(m),gcd(a,m)=1gcd(a,m)=1,b≤φ(m)gcd(a,m)=1,b>φ(m)
这个 ∞ a ^\infty a ∞a 一定在模意义下对应一个唯一确定的整数。下文中讨论 ∞ a ^\infty a ∞a 的值,一定是针对于某个特定的模数而言。
由扩展欧拉定理可得,要想求 ∞ a m o d m ^\infty a \bmod m ∞amodm,考虑使用扩展欧拉定理。显然 ∞ a ^\infty a ∞a 充分大,因而有:
∞ a ≡ a ∞ a m o d φ ( m ) + φ ( m ) ( m o d m ) ^\infty a \equiv a^{^\infty a \bmod \varphi(m)+\varphi(m)} \pmod m ∞a≡a∞amodφ(m)+φ(m)(modm)
而对于任意一个数字 m m m,不断对它求 φ ( m ) \varphi(m) φ(m),不超过 O ( 2 log m ) \mathcal O(2 \log m) O(2logm) 次操作就可以使 m = 1 m=1 m=1,这时 ∞ a ≡ 0 ( m o d 1 ) ^\infty a \equiv 0 \pmod 1 ∞a≡0(mod1),因而更高次指数不再有意义,因而可以通过下面的递归函数求出 ∞ a m o d m ^\infty a \bmod m ∞amodm 的值。本题即P4139 上帝与集合的正确用法。
long long dfs(long long base, long long p)
{
if (p == 1)
return 0;
long long phip = phi(p);
long long y = power(base, dfs(base, phip) + phip, p);
return y;
}
下面开始对本题的正式解法描述。
法一:首先考虑 a u ≡ u ( m o d m ) a^u \equiv u \pmod m au≡u(modm) 的形式。如果假设 u u u 有 a k a^k ak 形式,则带入可得 a a k ≡ a k ( m o d m ) a^{a^k} \equiv a^k \pmod m aak≡ak(modm)。如果这个 u u u 充分大(即大于 φ ( m ) \varphi(m) φ(m)),则根据扩展欧拉定理的指数条件有 a k ≡ k ( m o d φ ( m ) ) a^k \equiv k \pmod{\varphi(m)} ak≡k(modφ(m)),而这个式子与原式形式完全相同且模数减小,因而可以考虑一路递归下去,如此进行到 m = 1 m=1 m=1。这时考虑边界条件,不妨设此时的 u u u 仍然具有 a k a^k ak 形式,而这显然成立(模 1 1 1 意义下什么值都是 0 0 0)。因而,我们可以假定 u u u 就是 ∞ a ^\infty a ∞a。
由于 ∞ a ^\infty a ∞a 对于不同的模数就有不同的值,回到原式考虑这个 u u u 需要满足什么条件。显然由最基本的条件, a ∞ a = ∞ a ≡ u ( m o d m ) a^{^\infty a}=\ ^\infty a \equiv u \pmod m a∞a= ∞a≡u(modm)。此外,由于它在指数上,因而由 a u ≡ ∞ a = a ∞ a ( m o d m ) a^u \equiv\ ^\infty a=a^{^\infty a} \pmod m au≡ ∞a=a∞a(modm) 可得 u ≡ ∞ a ( m o d φ ( m ) ) u \equiv\ ^\infty a \pmod {\varphi(m)} u≡ ∞a(modφ(m))。注意这里的 u u u 要充分大。因而可以得到如下的同余方程:
{ u ≡ ∞ a ( m o d m ) u ≡ ∞ a ( m o d φ ( m ) ) \begin{cases} u \equiv \ ^\infty a\pmod m\\ u \equiv \ ^\infty a \pmod{\varphi(m)} \end{cases} {u≡ ∞a(modm)u≡ ∞a(modφ(m))
因而有 u ≡ ∞ a ( m o d l c m ( m , φ ( m ) ) ) u \equiv \ ^\infty a\pmod{{\rm lcm}(m, \varphi(m))} u≡ ∞a(modlcm(m,φ(m)))。考虑直接用上述方程组解 exCRT(扩展中国剩余定理)即可。因为 ∞ a ( m o d l c m ( φ ( m ) , m ) ) ^\infty a \pmod{{\rm lcm}(\varphi(m), m)} ∞a(modlcm(φ(m),m)) 一定存在,因而上述同余方程组一定有解。复杂度 O ( T V ) \mathcal O\left(T \sqrt{V}\right) O(TV)。
#include 法二:首先不难注意到当 gcd ( a , m ) = 1 \gcd(a,m)=1 gcd(a,m)=1 时, a φ ( m ) ≡ 1 ( m o d m ) a^{\varphi(m)} \equiv 1 \pmod m aφ(m)≡1(modm)。如果 φ ( m ) ∣ u \varphi(m)|u φ(m)∣u 且 u ≡ 1 ( m o d m ) u \equiv 1 \pmod m u≡1(modm) 有解的时候这样的 u u u 就是合法的。可惜这个同余方程组不一定有解。考虑让上述方程有解,即考虑一个一般情况,即 u u u 仍然是充分大(大于 φ ( m ) \varphi(m) φ(m))时,有 a u ≡ a c ( m o d m ) a^u \equiv a^c \pmod m au≡ac(modm),其中 c c c 为一常数且 c ∈ [ φ ( m ) , 2 φ ( m ) ) c \in [\varphi(m),2\varphi(m)) c∈[φ(m),2φ(m))。则考虑指数和底数条件有:
u ≡ a c ( m o d m ) u ≡ c ( m o d φ ( m ) ) \begin{aligned} u &\equiv a^c \pmod m\\ u &\equiv c \pmod{\varphi(m)} \end{aligned} uu≡ac(modm)≡c(modφ(m))
消去 u u u 将同余方程组转化为丢番图方程,观察对 c c c 的约束,有:
a c + k 1 m = c + k 2 φ ( m ) a^c+k_1m=c+k_2\varphi(m) ac+k1m=c+k2φ(m)
即 a c − c = k 1 m + k 2 φ ( m ) a^c -c =k_1m+k_2\varphi(m) ac−c=k1m+k2φ(m),右侧必为 g = gcd ( m , φ ( m ) ) g=\gcd(m,\varphi(m)) g=gcd(m,φ(m)) 的倍数。由于 k 1 , k 2 k_1,k_2 k1,k2 的任意性,右侧可以组合出一切 g g g 的倍数,因而有 a c ≡ c ( m o d g ) a^c \equiv c \pmod {g} ac≡c(modg),就可以开始递归计算上述方程 c c c 的解。对于每一轮递归,可以考虑暴力回代解出相应的 u u u。
D Non-Puzzle: Error Permutation
题意:给定长度为 n n n 的排列 { P } i = 1 n \{P\}_{i=1}^n {P}i=1n,问有多少个连续子区间 [ l , r ] [l,r] [l,r],在区间中从左往右数的第 i i i 个数字都不是该区间的第 i i i 小。$ 1\le n \le 5\times 10^3$。
解法:反过来思考出现什么情况会让一个区间不合法。对于一个确定的数字 P i P_i Pi,考虑对于区间 [ l , r ] [l,r] [l,r],如果这个 P i P_i Pi 导致了区间不合法,那一定是它是这个区间的第 i i i 小。考虑 P i P_i Pi 左侧比 P i P_i Pi 大的个数,和 P i P_i Pi 右侧比 P i P_i Pi 小的数字个数,显然这两个要相等:即把 P i P_i Pi 左侧比 P i P_i Pi 大的数字都用 i i i 右侧比 P i P_i Pi 小的数字替换就可以实现 P i P_i Pi 左侧都比 P i P_i Pi 小,右侧都比 P i P_i Pi 大。即,左大等于右小。
这时考虑枚举 i i i,依次去维护当 l l l 从 i i i 向左侧移动时,比 P i P_i Pi 大的数字个数变化情况——它一定是一段区间 [ l 0 , r 0 ] [l_0,r_0] [l0,r0] 上都是 0 0 0 个数字比 P i P_i Pi 大, l ∈ [ l 1 , r 1 ] l \in [l_1,r_1] l∈[l1,r1] 上都是只有 1 1 1 个数字比 P i P_i Pi 大,依次类推;右侧当 r r r 从 i i i 开始向右移动时也是同理: [ l 0 ′ , r 0 ′ ] [l_0',r_0'] [l0′,r0′] 都是 0 0 0 个数字比 P i P_i Pi 小, [ l 1 ′ , r 1 ′ ] [l_1',r_1'] [l1′,r1′] 都是 1 1 1 个数字比 P i P_i Pi 小,等等。那么对于固定的 i i i,它将会导致整个二维矩阵区间 [ l j , r j ] : [ l j ′ , r j ′ ] [l_j,r_j]:[l_j',r_j'] [lj,rj]:[lj′,rj′] 都变成不合法的。
初始化矩阵为全 0 0 0 矩阵,每次出现不合法就直接对这个不合法矩阵区域整体加一,最后统计右上角矩阵中 0 0 0 个数即为答案。而对于这种矩阵整体更新,就可以直接使用二维差分快速维护对于每个 i i i 的 O ( n ) \mathcal O(n) O(n) 次更新,最后前缀和即可。整体复杂度 O ( n 2 ) \mathcal O(n^2) O(n2)。
#include E Puzzle: Square Jam
题意:给定 n × m n\times m n×m 的矩形,将其划分成为若干个正方形,并且要求任何一个正方形的顶角不能和三个其他的正方形顶角重合(即划分出来的线不存在十字交叉)。输出一个构造方案。多测, 1 ≤ T ≤ 1 0 5 1 \le T \le 10^5 1≤T≤105, 1 ≤ ∑ n × m ≤ 2 × 1 0 5 1 \le \sum n\times m \le 2\times 10^5 1≤∑n×m≤2×105。
解法:本题和第四场 G 题非常相似——使用辗转相减法进行构造,每次裁剪最大的一个正方形即可。
#include G Non-Puzzle: Game
题意:给定长度为 n n n 的序列 { a } i = 1 n \{a\}_{i=1}^n {a}i=1n,先后手轮流依次从序列中选择两个数字 a i , a j a_i,a_j ai,aj(可选相同数字)然后将 a i ⊕ a j a_i \oplus a_j ai⊕aj 加入序列中。给定 k k k,谁先凑出 k k k 谁获胜。问谁胜。 1 ≤ n ≤ 1 0 6 1 \le n \le 10^6 1≤n≤106, 0 ≤ a i , k < 2 30 0 \le a_i,k <2^{30} 0≤ai,k<230。
解法:考虑最后如果得到 k k k,那一定是由给出序列 { a } i = 1 n \{a\}_{i=1}^n {a}i=1n 中的某几个元素异或起来得到的。因而我们只关心所得序列的数字种类而不关心每个数字具体有多少个。因而可以首先考虑对 { a } \{a\} {a} 序列去重。下文中讨论的 { a } \{a\} {a} 序列均无重复元素,设此时集合大小仍为 n n n。
首先最朴素的情况:如果当前先手一步操作就可以得到 k k k 则先手必胜;从第二步操作开始,每个人都可以消极参赛——重复上一个人的操作,这样整个序列的数字种类数就不会发生变化,因而局面完全相同。因而不难得到,如果当前局面对于先手是必败的,则他一定会重复上一步操作让这个必败局面留给对手,进而达成平局。所以先手想要输,必须满足的条件是:
- 先手没有上一步操作可以重复——即他在走第一步。
- 先手走任意的操作,都会让后手一波操作获胜。否则先手可以考虑执行一步操作让后手没办法一步凑出 k k k。
因而不难发现如果游戏不能在两轮之内结束,双方就都会消极参赛。而后手必胜条件是先手无论操作什么,都能让他选出当前新的两个数字凑出 k k k(注意一定不可能是给定序列中的两个数字,因为这样会导致先手一波操作结束)。
因而后手必胜的充要条件是, ∀ i , j ∈ [ 1 , n ] \forall i,j \in [1,n] ∀i,j∈[1,n], a i ⊕ a j ≠ k a_i \oplus a_j \ne k ai⊕aj=k,且 ∃ l ∈ [ 1 , n ] \exists l\in [1,n] ∃l∈[1,n], a i ⊕ a j ⊕ a l = k a_i \oplus a_j \oplus a_l=k ai⊕aj⊕al=k。第一个条件可以通过哈希表枚举 a i a_i ai 去查询 k ⊕ a j k\oplus a_j k⊕aj 快速判断。对于第二个,利用异或性质可得 ( a i ⊕ k ) ⊕ ( a j ⊕ k ) = a l ⊕ k (a_i \oplus k) \oplus (a_j \oplus k)=a_l \oplus k (ai⊕k)⊕(aj⊕k)=al⊕k。考虑 a i ′ = a i ⊕ k a_i'=a_i \oplus k ai′=ai⊕k,定义集合 A = { x ∣ x = a i ⊕ k } A=\{x|x=a_i \oplus k\} A={x∣x=ai⊕k},则 a i ′ ⊕ a j ′ = a l ′ a_i' \oplus a_j'=a_l' ai′⊕aj′=al′ 对于任意的 i , j i,j i,j 成立。因而 a i ′ a_i' ai′ 集合在异或运算上封闭——即任取集合中的两个元素进行运算,其运算结果仍然在这个集合中。进而再推一步——从这个集合中选出任意多个元素进行异或运算,其运算结果仍然在这个集合 A A A 中——每次进行一次两个集合内元素的异或运算,得到的结果仍然在集合中,就可以再次进行这样的异或运算。
因而只需要使用线性基判断出该集合对应的向量空间一定等于集合 A A A 即可。而显然,集合 A A A 一定在张成的向量空间中,因而只需要判断出该向量空间大小是否等于 ∣ A ∣ |A| ∣A∣。而考虑由 n n n 维的 01 01 01 向量所张成空间的大小一定等于 2 r 2^r 2r,其中 r r r 为该矩阵的秩(主元个数)。而在向线性基插入元素的时候主元才会增加 1 1 1,因而统计这样的元素个数即可。
#includeI Non-Puzzle: Segment Pair
题意:给定 n n n 组区间,每组区间由两个区间构成。问从每组区间中选一个区间出来,这些区间能够同时覆盖同一个点的方案数。 1 ≤ n ≤ 5 × 1 0 5 1 \le n \le 5\times 10^5 1≤n≤5×105,区间数字范围 [ 1 , 5 × 1 0 5 ] [1,5\times 10^5] [1,5×105]。
解法:注意到区间覆盖的总长度只有 5 × 1 0 5 5\times 10^5 5×105,因而可以考虑枚举最终的这个全部覆盖点的位置,然后根据枚举区间从左到右依次插入或删除当前一对区间,观察和统计贡献。
但是根据覆盖点判断这样做可能有重复:如一对区间 [ 1 , 3 ] , [ 2 , 5 ] [1,3],[2,5] [1,3],[2,5], 2 , 3 2,3 2,3 都是被这一对区间包含,枚举 2 , 3 2,3 2,3 的答案都是这一对区间中任意二选一,而实际上在 2 2 2 或 3 3 3 处进行二选一对应的方案是本质一样的。即当选择的最终点的位置不同时,每组区间的选法如果完全相同,此时应当视为同一种方案。为避免这一问题,可以考虑仅在每个区间开头处统计答案,即只在 1 , 3 1,3 1,3 处统计答案。此时统计的答案因为新区间的开启必然会导致不同选法的出现。
考虑维护一个 b b b 数组,随着全部覆盖点和区间的变化而实时更新。第 i i i( i ∈ [ 0 , 2 ] i \in [0,2] i∈[0,2])项表示当前这个点被多少组区间覆盖 i i i 次。例如区间 [ 1 , 3 ] , [ 2 , 5 ] [1,3],[2,5] [1,3],[2,5] 就让点 2 , 3 2,3 2,3 被覆盖了两次,在覆盖点为 2 , 3 2,3 2,3 时 b 2 b_2 b2 就因为这一组区间增大一,覆盖点为 4 , 5 4,5 4,5 时则是 b 1 b_1 b1 被这组区间影响。那么随着覆盖点变化时,当 b 0 = 0 b_0=0 b0=0 即不存在一组区间在这个点上没有一次覆盖且满足是新区间开启条件时可以统计答案,答案即为 2 b 2 2^{b_2} 2b2,因为这 b 2 b_2 b2 组区间在当前点上都是两次覆盖,可以任选。
考虑如何维护这个 b b b 数组——可以记录每组中每个区间开始和结束的位置,并用 { a } i = 1 n \{a\}_{i=1}^n {a}i=1n 数组维护第 i i i 组区间在当前点上已经覆盖了多少次。则对于第 i i i 组中某个区间开始或结束,只需要更新 b a i b_{a_{i}} bai 加一或减一即可。总时间复杂度 O ( n log n ) \mathcal O(n \log n) O(nlogn),因为涉及对区间操作(开始或结束)位置的排序。
#include J Puzzle: Star Battle
题意:给定 4 n × 4 n 4n\times 4n 4n×4n 的正方形,该正方形划分为 4 n 4n 4n 个可能不连通的区域。要求每个区域内选出 n n n 个点,使得这 4 n 2 4n^2 4n2 个点在每行、每列上都有恰好 n n n 个,且这些点互不八邻接。构造一个方案,或输出无解。 1 ≤ n ≤ 300 1 \le n \le 300 1≤n≤300。
解法:首先考虑题目中要求边长都是 4 4 4 的倍数的特殊用意。考虑下图中 4 × 4 4\times 4 4×4 的构造方法,符合条件的仅有两种:
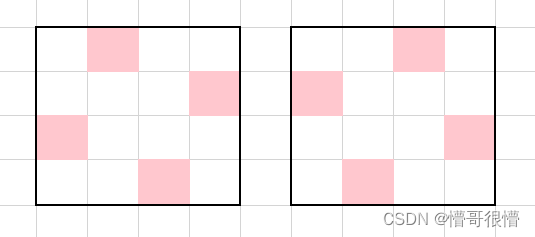
由于边长一定是 4 4 4 的倍数,考虑按照 4 × 4 4\times 4 4×4 的基本型组合出大的形状。仅以左图为例:

每次向外扩展 2 + 2 2+2 2+2 格,就是把内层的格子复制一次。这样整个图形根据两种内核,就只有两种构造方式。因而直接判断这两种核是不是合法的即可。
#include