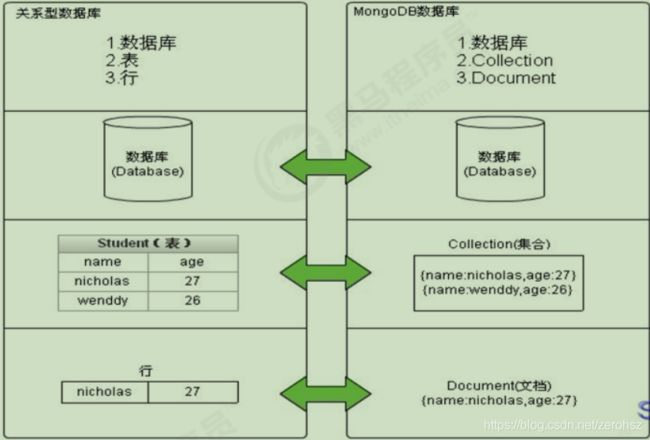
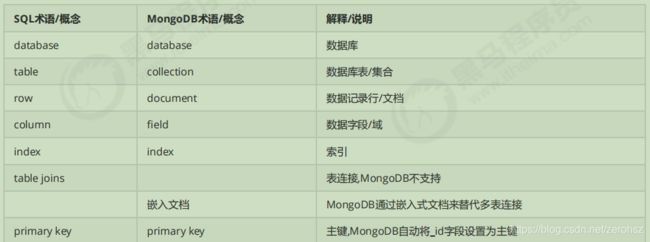
MongoDB 是一个开源、高性能、无模式的文档型数据库,当初的设计就是用于简化开发和方便扩展,是 NoSQL 数据库产品中的一种。是最
像关系型数据库( MySQL )的非关系型数据库。
它支持的数据结构非常松散,是一种类似于 JSON 的 格式叫 BSON ,所以它既可以存储比较复杂的数据类型,又相当的灵活。
MongoDB 中的记录是一个文档,它是一个由字段和值对( fifield:value )组成的数据结构。 MongoDB 文档类似于 JSON 对象,即一个文档认
为就是一个对象。字段的数据类型是字符型,它的值除了使用基本的一些类型外,还可以包括其他文档、普通数组和文档数组。
1.3 体系结构
MySQL 和 MongoDB 对比
1.4 数据模型
MongoDB 的最小存储单位就是文档 (document) 对象。文档 (document) 对象对应于关系型数据库的行。数据在 MongoDB 中以
BSON ( Binary-JSON )文档的格式存储在磁盘上。
BSON ( Binary Serialized Document Format )是一种类 json 的一种二进制形式的存储格式,简称 Binary JSON 。 BSON 和 JSON 一样,支持
内嵌的文档对象和数组对象,但是 BSON 有 JSON 没有的一些数据类型,如 Date 和 BinData 类型。
BSON 采用了类似于 C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的三个特点,可
以有效描述非结构化数据和结构化数据。这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想。
Bson 中,除了基本的 JSON 类型: string,integer,boolean,double,null,array 和 object , mongo 还使用了特殊的数据类型。这些类型包括
date,object id,binary data,regular expression 和 code 。每一个驱动都以特定语言的方式实现了这些类型,查看你的驱动的文档来获取详
细信息。
BSON 数据类型参考列表:
1.5 MongoDB的特点
MongoDB 主要有如下特点:
( 1 ) 高性能 :
MongoDB 提供高性能的数据持久性。特别是 ,
对嵌入式数据模型的支持减少了数据库系统上的 I/O 活动。
索引支持更快的查询,并且可以包含来自嵌入式文档和数组的键。(文本索引解决搜索的需求、 TTL 索引解决历史数据自动过期的需求、地
理位置索引可用于构建各种 O2O 应用)
mmapv1 、 wiredtiger 、 mongorocks ( rocksdb )、 in-memory 等多引擎支持满足各种场景需求。
Gridfs 解决文件存储的需求。
( 2 ) 高可用性:
MongoDB 的复制工具称为副本集( replica set ),它可提供自动故障转移和数据冗余。
( 3 ) 高扩展性:
MongoDB 提供了水平可扩展性作为其核心功能的一部分。
分片将数据分布在一组集群的机器上。(海量数据存储,服务能力水平扩展)
从 3.4 开始, MongoDB 支持基于片键创建数据区域。在一个平衡的集群中, MongoDB 将一个区域所覆盖的读写只定向到该区域内的那些
片。
( 4 ) 丰富的查询支持:
MongoDB 支持丰富的查询语言,支持读和写操作 (CRUD) ,比如数据聚合、文本搜索和地理空间查询等。
( 5 )其他特点:如无模式(动态模式)、灵活的文档模型、
2 单机部署
2.1 Windows系统中的安装启动
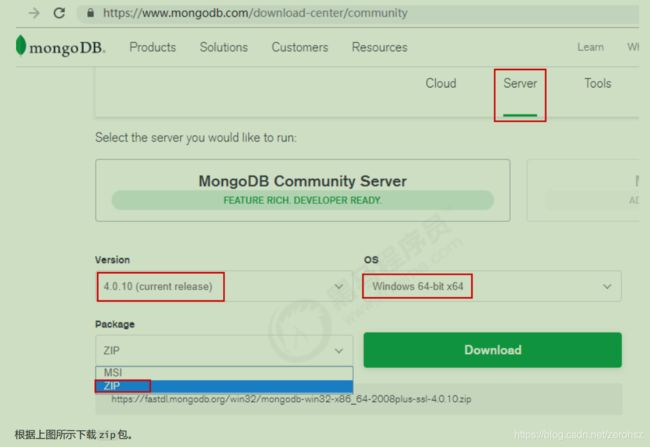
第一步:下载安装包
MongoDB 提供了可用于 32 位和 64 位系统的预编译二进制包,你可以从 MongoDB 官网下载安装, MongoDB 预编译二进制包下载地址:
https://www.mongodb.com/download-center#community
根据上图所示下载 zip 包。
提示:版本的选择:
MongoDB 的版本命名规范如: x.y.z ;
y 为奇数时表示当前版本为开发版,如: 1.5.2 、 4.1.13 ;
y 为偶数时表示当前版本为稳定版,如: 1.6.3 、 4.0.10 ;
z 是修正版本号,数字越大越好。
详情: http://docs.mongodb.org/manual/release-notes/#release-version-numbers
第二步:解压安装启动
将压缩包解压到一个目录中。
在解压目录中,手动建立一个目录用于存放数据文件,如 data/db
方式 1 :命令行参数方式启动服务
在 bin 目录中打开命令行提示符,输入如下命令:
mongod --dbpath = ..\data\db
我们在启动信息中可以看到, mongoDB 的默认端口是 27017 ,如果我们想改变默认的启动端口,可以通过 --port 来指定端口。
为了方便我们每次启动,可以将安装目录的 bin 目录设置到环境变量的 path 中, bin 目录下是一些常用命令,比如 mongod 启动服务用的,
mongo 客户端连接服务用的。
方式 2 :配置文件方式启动服务
在解压目录中新建 config 文件夹,该文件夹中新建配置文件 mongod.conf ,内如参考如下:
storage :
#The directory where the mongod instance stores its data.Default Value is "\data\db" on Windows.
dbPath : D : \02_Server\DBServer\mongodb-win32-x86_64-2008plus-ssl-4.0.1\data
详细配置项内容可以参考官方文档: https://docs.mongodb.com/manual/reference/confifiguration-options/
启动方式:
mongod -f ../config/mongod.conf
或
mongod --config ../config/mongod.conf
2.3 Compass-ffl形化界面客户端
到MongoDB官网下载MongoDB Compass ,
地址:httus:〃www.monodb.com/download-center/v2/comuass?initial=true
如果是下载安装版,则按照步骤安装;如果是下载加压缩版,匐瓣压,执行里面的MongoDBCompasscommunity .exe文件即可。
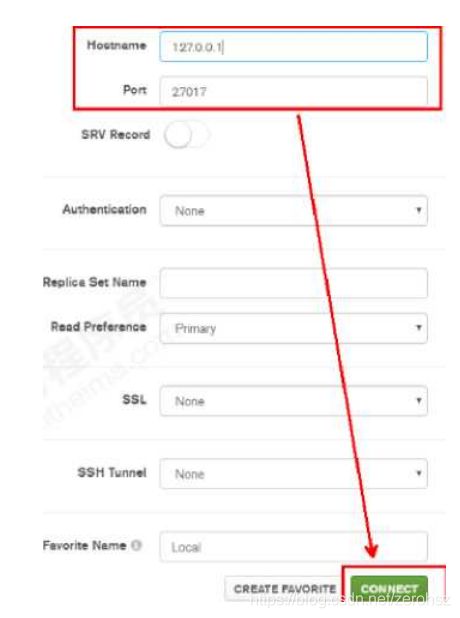
在打开的界面中,输入主机地址、端口等相关信息,点击连接:
2.4 Linux系统中的安装启动和连接
目标:在Linux中部 ~ 单机的MongoDB ,作为生产环境下使用。
提示:和Windows下操作差不多。
步骤如下:
(1 )先到官网下载压缩包 mongod-li nux-x86_64-4.0.10 .tgz。
(2 )上传压缩包到Linux中,解压到当前目录:
tar -xvf mongodb-1i nux-x86_64-4.0.10.tgz
- 移动解压后的文件夹到指定的目录中:
mv mongodb-1i nux-x86_64-4.0.10 /usr/1ocal/mongodb
- 新建几个目录,分别用来存储数据和日志:
#数据存储目录
mkdi r -p /mongodb/si ngle/data/db
#日志存储目录
mkdi r -p /mongodb/si ngle/log
- 新建并修改配置文件
vi /mongodb/single/mongod.conf
配置文件的内容如下:
systemLog:
#MongoDB发送所有日志输出的目标指定为文件 #
#The path of the log file to which mongod or mongos should send all diagnostic logging information
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: "/mongodb/single/log/mongod.log"
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。
logAppend: true
storage:
#mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。
##The directory where the mongod instance stores its data.Default Value is "/data/db".
dbPath: "/mongodb/single/data/db"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式。
fork: true
net:
#服务实例绑定的IP,默认是localhost
bindIp: localhost,192.168.1.13
#bindIp #绑定的端口,默认是27017
port: 27017
(6 )启动MongoDB服务
[root@bobohost single]# /usr/1ocal/mongodb/bin/mongod -f /mongodb/single/mongod.conf
about to fork child process, waiting until server is ready for connections.
forked process: 90384
chi Id process started successful1y, parent exiting
注意:
如果启动后不是successfully,则是启动失败了。原因基本上就是配置文件有问题。
通过进程来査看服务是否启动了:
[root@bobohost single]# ps -ef Igrep mongod
root 90384 1 0 8月26 ? 00:02:13 /usr/local/mongdb/bin/mongod -f /mongodb/single/mongod.conf
(7 )分别使用mongo命令和com pass工具来连接测试。
提示:如果远程连接不上,需要配置防火墙放行,或直接关闭linux防火墙
#查看防火墙状态
systemctl status fi rewalId
#临时关闭防火墙
systemctl stop fi rewalId
#开机禁止启动防火墙
systemctl disable fi rewalId
(8)停止关闭服务
停止1艮务的方式有两种:快速关闭和标准关闭,下面依次说明:
(-)快速关闭方法(快速,简单,数据可能会出错)
目标:通过系统的kill命令直接杀死进程:
杀完要检査一下,避免有的没有杀掉。
#通过进程编号关闭节点
kill -2 54410
【补充】
如果一旦是因为数据损坏,则需要进行如下操作(了解):
1 )删除lock文件:
rm -f /mongodb/single/data/db/*.lock
2)修复数据:
/usr/local/mongdb/bi n/mongod --repai r --dbpath=/mongodb/single/data/db
(二)标准的关闭方法(数据不容易出错,但麻烦):
目标:通过mongo客户端中的shutdownserver命令来关闭服务
主要的操作步骤参考如下:
〃客户端登录服务,注意,这里通过local host登录,如果需要远程登录,必须先登录认证才行。
mongo --port 27017
//#切换到admi n库
use admi n
//关闭服务
db.shutdownserver()
3.2数据库操作
3.2.1选择和创建数据库
选择和创建数据库的语法格式:
use数据库名称
如果数据库不存在则自动创建,例如,以下语句创建spitdb熟居库:
use articledb
查看有权限查看的所有的数据库命令
show dbs
或
show databases
注意:在MongoDB中,集合只有在内容插入后才会创建!就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
查看当前正在使用的数据库命令
db
MongoDB中默认的数据库为test,如果你没有选择数据库,集合将存放在test数据库中。
另外:
数据库名可以是满足以下条件的任意UTF-8字符串。
•不能是空字符串("")o
•不得含有'’(空格)、.、$、/、\和\0 (空字符)。
•应全部小写。
•最多64字节。
有一些娄対居库名是保留的,可以直接访问这些有樹^乍用的数据库。
- admin :从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特 定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local:这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config:当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
3.2.2数据库的删除
MongoDB删除数据库的语法格式如下:
db.dropDatabase()
提示:主要用趣除已经持久化的瓣库
3.3集合操作
集合,类似关系型蜘居库中的表。
可以显示的创建,也可以隐式的创建。
3.3.1集合的显式创建(了解)
基本语法格式:
db.createcollection(name)
参数说明:
• name:要创建的集合名称
例如:创建一 名为mycollection的普通集合。
db.createcollection("mycol lection")
查看当前库中的表:show tablesqp令
show collections
或
show tables
集合的命名规范:
•集合名不能是空字符串"。
•集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
•集合名不能以"system."开头,这是为系统集合保留的前缀。
•用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除 非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
33.2集合的隐式创建
当向f 集合中插入f文档的时候,如果集合不存在,则会自动创建集合。
详见 文档的插入章节。
提示:通常我们使用隐式创建文档即可。
3.3.3集合的删除
集合删除语法格式如下:
db. col lection .drop。
或
db.集合.drop()
返回值
如果成功删除选定集合,则drop()方法返回true ,否则返回false。
例如:要删除mycollection集合
db.mycol1ection.drop()
3.4文档基本CRUD
文档(document)的数据结构和JSON基本一样。
所有存储在集合中的数据都是BSON格式。
3.4.1文档的插入
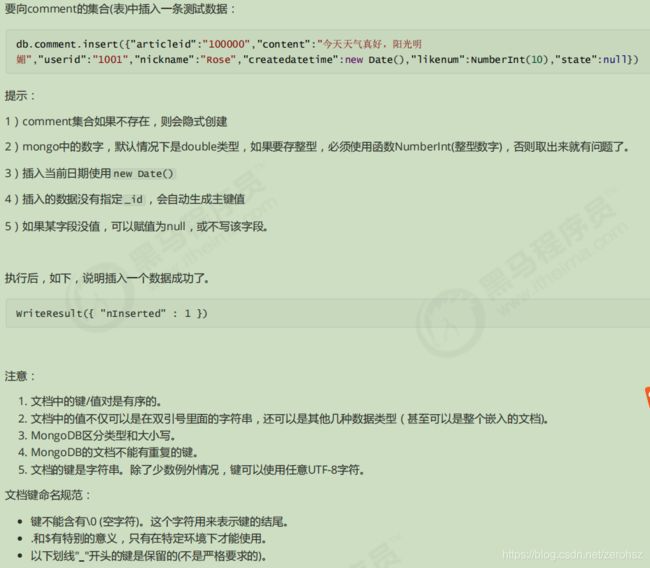
(1)单个文档插入
使用insert()或save。方法向集合中插入文档,语法如下:
db.col lection.insert( , {
writeconcern: , ordered:
}
)
1)单个插入
批量插入
db . collection . insertMany (
[ < document 1 > , < document 2 > , ... ],
{
writeConcern : < document > ,
ordered : < boolean >
}
)
示例:
try {
db . comment . insertMany ([
{ "_id" : "1" , "articleid" : "100001" , "content" : " 我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我
他。 " , "userid" : "1002" , "nickname" : " 相忘于江湖 " , "createdatetime" : new Date ( "2019-08-
05T22:08:15.522Z" ), "likenum" : NumberInt ( 1000 ), "state" : "1" },
{ "_id" : "2" , "articleid" : "100001" , "content" : " 我夏天空腹喝凉开水,冬天喝温开水 " , "userid" : "1005" , "nickname" : " 伊人憔
悴 " , "createdatetime" : new Date ( "2019-08-05T23:58:51.485Z" ), "likenum" : NumberInt ( 888 ), "state" : "1" },
{ "_id" : "3" , "articleid" : "100001" , "content" : " 我一直喝凉开水,冬天夏天都喝。 " , "userid" : "1004" , "nickname" : " 杰克船
长 " , "createdatetime" : new Date ( "2019-08-06T01:05:06.321Z" ), "likenum" : NumberInt ( 666 ), "state" : "1" },
{ "_id" : "4" , "articleid" : "100001" , "content" : " 专家说不能空腹吃饭,影响健康。 " , "userid" : "1003" , "nickname" : " 凯
撒 " , "createdatetime" : new Date ( "2019-08-06T08:18:35.288Z" ), "likenum" : NumberInt ( 2000 ), "state" : "1" },
{ "_id" : "5" , "articleid" : "100001" , "content" : " 研究表明,刚烧开的水千万不能喝,因为烫
嘴。 " , "userid" : "1003" , "nickname" : " 凯撒 " , "createdatetime" : new Date ( "2019-08-
06T11:01:02.521Z" ), "likenum" : NumberInt ( 3000 ), "state" : "1" }
]);
} catch ( e ) {
print ( e );
}
插入时指定了 _id ,则主键就是该值。
如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。
因为批量插入由于数据较多容易出现失败,因此,可以使用 try catch 进行异常捕捉处理,测试的时候可以不处理
3.4.2 文档的基本查询
1 查询所有
db . comment . find ({})
db.comment.find({userid:'1003'})
2 投影查询
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)。
如:查询结果只显示 _id 、 userid 、 nickname :
>db.comment.find({userid:"1003"},{userid:1,nickname:1})
{ "_id" : "4", "userid" : "1003", "nickname" : " 凯撒 " }
{ "_id" : "5", "userid" : "1003", "nickname" : " 凯撒 " }
>db.comment.find({},{userid:1,nickname:1})
不显示_id
>db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0})
{ "userid" : "1003", "nickname" : " 凯撒 " }
{ "userid" : "1003", "nickname" : " 凯撒 " }
3.4.3 文档的更新
( 1 )覆盖的修改
如果我们想修改 _id 为 1 的记录,点赞量为 1001 ,输入以下语句:
db.comment.update({_id:"1"},{likenum:NumberInt(1001)})
执行后,我们会发现,这条文档除了 likenum 字段其它字段都不见了,
( 2 )局部修改
为了解决这个问题,我们需要使用修改器 $set 来实现,命令如下:
我们想修改 _id 为 2 的记录,浏览量为 889 ,输入以下语句:
db . comment . update ({ _id : "2" },{ $set :{ likenum : NumberInt ( 889 )}})
( 3 )批量的修改
更新所有用户为 1003 的用户的昵称为 凯撒大帝 。
// 默认只修改第一条数据
db . comment . update ({ userid : "1003" },{ $set :{ nickname : " 凯撒 2" }})
// 修改所有符合条件的数据
db . comment . update ({ userid : "1003" },{ $set :{ nickname : " 凯撒大帝 " }},{ multi : true })
( 3 )列值增长的修改
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 $inc 运算符来实现。
需求:对 3 号数据的点赞数,每次递增 1
db . comment . update ({ _id : "3" },{ $inc :{ likenum : NumberInt ( 1 )}})
3.4.4 删除文档
删除文档的语法结构:
db. 集合名称 .remove( 条件 )
删除全部
db.comment.remove({})
删除_id=1的
db.comment.remove({_id:"1"})
统计查询
db.comment.count()
db.comment.count({userid:"1003"})
如果你想返回指定条数的记录,可以在 fifind 方法后调用 limit 来返回结果 (TopN) ,默认值 20 ,例如
db.comment.find().limit(3)
skip 方法同样接受一个数字参数作为跳过的记录条数。(前 N 个不要) , 默认值是 0
db.comment.find().skip(3)
sort() 方法对数据进行排序, sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用
于降序排列。
db.comment.find().sort({userid:-1,likenum:1})
skip(), limilt(), sort() 三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip() ,最后是显示的 limit() ,和命令编写顺序无关。
db. 集合名称 .find({ "field" : { $gt: value }}) // 大于 : field > value
db. 集合名称 .find({ "field" : { $lt: value }}) // 小于 : field < value
db. 集合名称 .find({ "field" : { $gte: value }}) // 大于等于 : field >= value
db. 集合名称 .find({ "field" : { $lte: value }}) // 小于等于 : field <= value
db. 集合名称 .find({ "field" : { $ne: value }}) // 不等于 : field != value
示例
db.comment.find({likenum:{$gt:NumberInt(700)}})
包含与不包含
db.comment.find({userid:{$in:["1003","1004"]}})
db.comment.find({userid:{$nin:["1003","1004"]}})
示例:查询评论集合中 likenum 大于等于 700 并且小于 2000 的文档:
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})
示例:查询评论集合中 userid 为 1003 ,或者点赞数小于 1000 的文档记录
db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})
常用命令:
选择切换数据库: use articledb
插入数据: db.comment.insert({bson 数据 })
查询所有数据: db.comment.find();
条件查询数据: db.comment.find({ 条件 })
查询符合条件的第一条记录: db.comment.findOne({ 条件 })
查询符合条件的前几条记录: db.comment.find({ 条件 }).limit( 条数 )
查询符合条件的跳过的记录: db.comment.find({ 条件 }).skip( 条数 )
修改数据: db.comment.update({ 条件 },{ 修改后的数据 }) 或 db.comment.update({ 条件 },{$set:{ 要修改部分的字段 : 数据 })
修改数据并自增某字段值: db.comment.update({ 条件 },{$inc:{ 自增的字段 : 步进值 }})
删除数据: db.comment.remove({ 条件 })
统计查询: db.comment.count({ 条件 })
模糊查询: db.comment.find({ 字段名 :/ 正则表达式 /})
条件比较运算: db.comment.find({ 字段名 :{$gt: 值 }})
包含查询: db.comment.find({ 字段名 :{$in:[ 值 1 ,值 2]}}) 或 db.comment.find({ 字段名 :{$nin:[ 值 1 ,值 2]}})
条件连接查询: db.comment.find({$and:[{ 条件 1},{ 条件 2}]}) 或 db.comment.find({$or:[{ 条件 1},{ 条件 2}]})