Python requests包get响应内容中文乱码解决方案
Requests源码包解析原理
分析requests的源代码发现,text返回的是处理过的Unicode型的数据,而使用content返回的是bytes型的原始数据。也就是说,r.content相对于r.text来说节省了计算资源,content是把内容bytes返回. 而text是decode成Unicode. 如果headers没有charset字符集的化,text()会调用chardet来计算字符集,这又是消耗cpu的事情。
若reqponse header只指定了type,但是没有指定编码(一般现在页面编码都直接在html页面中),查找原网页可以看到
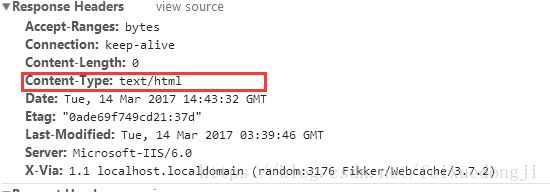
再找一个标准点的网页查看,比如博客园的网页博客园
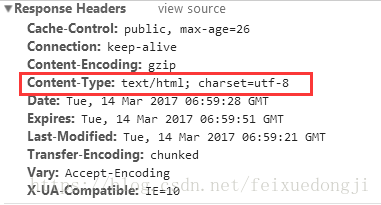
response herders的Content-Type指定了编码类型。
《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。这处理英文页面当然没有问题,但是中文页面,就会有乱码了!
python中的编码
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表示将gb2312编码的字符串str1转换成unicode编码,encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312’),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码。
requests中的编码
先上结论:之所以request的响应内容乱码,是因为模块中并没有正确识别出encoding的编码,而s.txt的结果是依靠encoding的编码“ISO-8859-1”解码出的结果,所以导致乱码。
所以正确的逻辑应该这样:
如:
s = requests.get('http://www.vuln.cn')
一般可以先判断出编码,比如编码为gb2312,
str = s.content
可以直接用正确的编码来解码。
str.decode('gb2312')
那么知道这个逻辑,接下来就是需要正确判断网页编码就行了,获取响应html中的charset参数:
但实际上我们并不需要轮子。
因为requests模块中自带该属性,但默认并没有用上,我们看下源码:
def get_encodings_from_content(content):
"""
Returns encodings from given content string.
:param content: bytestring to extract encodings from.
"""
charset_re = re.compile(r'
pragma_re = re.compile(r'
xml_re = re.compile(r'^<\?xml.*?encoding=["\']*(.+?)["\'>]')
return (charset_re.findall(content) + pragma_re.findall(content) + xml_re.findall(content))
还提供了使用chardet的编码检测,见models.py:
def apparent_encoding(self):
"""The apparent encoding, provided by the lovely Charade library."""
return chardet.detect(self.content)['encoding']
所以我们可以直接执行encoding为正确编码,让response.text正确解码即可:
response=requests.get('www.test.com')
response.encoding = response.apparent_encoding
————————————————
版权声明:本文为CSDN博主「老野_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/feixuedongji/article/details/82984583