【无监督】5、DINO | 使用自蒸馏和 transformer 来释放自监督学习的超能力(ICCV2021)

文章目录
-
- 一、背景
- 二、相关工作
- 三、方法
- 四、效果
论文:Emerging Properties in Self-Supervised Vision Transformers
代码:https://github.com/facebookresearch/dino
出处:ICCV2021 | FAIR
DINO: self-DIstillation with NO labels
本文的标题中总共有 6 个单词,有 2 个重点,一个是自监督,一个是 Vision Transformer,为什么这里作者在文章标题中强调了 transformer ,只因为之前的自监督学习基本上都是基于 CNN 的(也是因为之前 Transformer 没有在视觉中有很成功的应用),所以本文 DINO 的方法也算是首次将 Transformer 成功的用于自监督学习的方法,也证明了基于 Transformer 的自监督网络能够在视觉上获得很好的特征提取能力(甚至比 CNN 更好)。
这里我们首先要明白为什么要研究自监督任务,意义在哪里?
-
自监督学习能干什么:强有力的特征提取器
-
自监督学习的意义:不需要大量的人工标注数据,模型能学习图像内部的关系,从而可以利用大量无标注的数据,也能扩展模型的泛化能力
-
自监督的一个很大的设定就是不需要标签,那么没有标签的图像能学习什么呢,能学习的就是有意义的前景特征,正是因为自监督学习不需要标签,所以不需要费时费力的人工标注。
-
没有标签提示的情况下模型学习什么样的内容呢,就是基于图像内部的自相关性,具有相同语义信息的像素一定都是有相关性的,直观理解也就是说在一副图像中,前景和前景之间或前景目标内部的自相关性肯定比前景和背景的相关性更大一些,背景像素之间的相关性肯定比背景和前景的相关性大一些,所以自监督学习就是模型在图像内部不断提取由浅到深的特征,整合出有意义的特征
这个图一展示了,在没有任何监督信号(就是没有类别、框等 label 信息,只有一张图)的情况下,vision transformer 网络提取到的图像内部的自注意力特征图,图中像素颜色越亮就说明响应特征越强烈,这里展示的是 [CLS] token 的特征图,这几张图已经是强有力的证据证明自监督在图像特征提取上的效果,甚至帆船上的绳子都有很好的响应。作者在这里强调使用自监督得到的 ViT 的特征更关注场景信息尤其是目标边界信息。
DINO 的贡献:
- 证明了使用 small ViT 获得的无监督特征在只搭配 KNN 且无任何 fine-tuning 的情况下就能在 ImageNet 上获得 78.3% top-1 acc
- 证明了 momentum encoder、multi-crop training、small patch with ViT 的效果,并且基于此构建了一个自监督方法 DINO,证明了结合 DINO 和 ViT 可以达到 80.1% top-1 acc
一、背景
Transformer 的出现打破了视觉任务 CNN 一家独大的场面,Transformer 在 NLP 的成功证明了使用大量数据进行预训练,然后在对应任务上微调的方式是可行的。但 Transformer 一直被诟病于需要更大的计算量和训练数据,而且在视觉上也没有取得比 CNN 优异很多的成绩。
既然 Transformer 在 NLP 上取得的成功很大程度上源于无监督的训练方式,因为在 NLP 中 transformer 的输入都是源于一句相同的话。
如 BERT 中会 mask 掉的单词也是这个句子中的单词,GPT 的 language modeling 方式也是盖住后面的单词,使用前面的单词来预测后面的单词,所以不需要额外的标注,而这种句子自己监督自己的方式也就是自监督的方式。
BERT 中通过 mask 掉句子中的单词,然后让模型预测对应的单词,这样的操作能够让模型更关注全局特征,更关注整个句子内部单词之间的关系,在掌握了整个句子的全局语义后能更好的预测出被 mask 掉的单词,且效果也比对一个句子提供一个全局的监督监督信号更好。
所以 DINO 的出发点就是:自监督学习能否在视觉上展示出 ViT 不同于 CNN 的全新属性呢?
等同于 NLP 中的思路,作者认为给一个图片提供一个全局的监督信号(如 cat 或 dog)的方式会丢失图片中很多细节信息,也会丢失掉没有没 label 提及到的目标的信息。
基于此,作者证明使用自监督的 ViT 得到的图像特征包含了非常丰富的语义分割信息,这在有监督的 ViT 或 CNN 中都是没有的
作者发现了哪些有意思的事情:
- 第一:很多无监督的方法都展现了对 segmentation mask 的很好的提取特性
- 第二:只有在结合 momentum encoder 和 multi-crop augmentation 的情况下,DINO 和 KNN 的简单结合才能或者很好的效果
- 第三:在 ViT 中使用更小的 patch 能提高特征的质量(但这也会带来计算量的提升啊!)
二、相关工作
self-supervised learning:
很多自监督学习方法的做法是在一张图片上使用数据增强获得两个不同的图像,将得到的这两张图片当做一对正样本,也就是这两个图片是一个类别(有多少个图片样本就会有多少个类别),然后自监督学习的目的是让模型能学习到哪两个图像属于一类(就是源于同一张图片)
这种方法就相当于一个分类任务,也就是要学习一个分类器来区分不同的类别(同一图片经过不同数据增强方式获得的两张图片就相当于同一个类别),但是当数据样本增多的时候,这种方法表现的就不是很好的
[73] 提出了使用 noise contrastive estimator(NCE)的方法来对比不同的实例,而不是分类,但这个需要大量的对比数据,也就是需要大的 batch 或 memory bank 才能学习到不同类别数据的内在差别。
基于此,BYOL 方法就提出了不需要学习不同图像之间的差别特征的方法,BYOL 训练的目标是使用 momentum encoder 来将同一类的图片匹配上。
本文的方法也是手 BYOL 启发,但是和 BYOL 的 similarity matching loss 不同
Self-training and knowledge distillation:
Self-training 是最简单的半监督方法之一,其主要思想是找到一种方法,用未标记的数据集来扩充已标记的数据集。算法流程如下:
- 利用已标记的数据来训练一个好的模型,然后使用这个模型对未标记的数据进行伪标签的生成
- 模型对未标记数据的所有预测都不可能都是好的,因此对于经典的 Self-training,通常是使用分数阈值(confidence score)过滤部分预测,以选择出未标记数据的预测标签的一个子集。
- 将生成的伪标签与原始的标记数据相结合,并在合并后数据上进行联合训练。
- 整个过程可以重复 n 次,直到达到收敛。
- Self-training 最大的问题在就在于伪标签非常的 noisy,会使得模型朝着错误的方向发展。以下文章大多数都是为了解决这个问题。
Distillation 一般是使用一个大的训练好的模型的输出来指导小模型的训练,将大模型的知识迁移到小模型上,一般 teacher 模型比较大,学习能力比较强,student 模型比较小
Self-training 和 Distillation 如何结合起来呢,之前有的方法使用大模型生成 soft label(pseudo-label),然后小模型学习这些 soft label,以 self-training 的模式来训练模型
本文的方法也是建立在自训练和知识蒸馏上,特殊的地方在于:
- self-training 过程是完全没有标签的,所以不存在上面说的使用小部分带标签数据训练然后生成伪标签的过程
- teacher 模型的参数是随机初始化的,使用 EMA 的方式从 student 模型上来更新参数,不存在预训练好的 teacher model
- teacher 模型和 student 模型结构完全一样,student 模型使用梯度回传来更新,teacher 模型使用 EMA 方式来更新
三、方法
模型在总体框架如图 2 所示,该蒸馏网络学习的目标是让 student 的输出分布和 teacher 的输出分布尽可能的相同,衡量两个分布的差距的方式使用的是交叉熵,让交叉熵最小化。
给定一张图 x,会使用不同的 crop 方式来得到多种不同的子图:
- 两个 global views,分辨率为 224x224,包含的内容大于原图的 50%
- 多个 local views,分辨率为 96x96,包含的内容小于原图的 50%
得到不同的子图后怎么经过不同的模型:
- teacher 模型:每次只会接收一个 global 子图
- student 模型:每次接收一个随机子图,global 和 local 的都可以
训练的目标是最小化如下 loss:
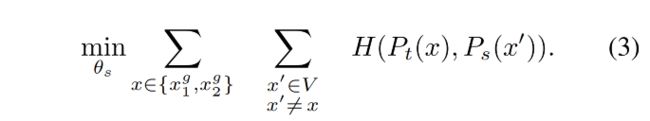
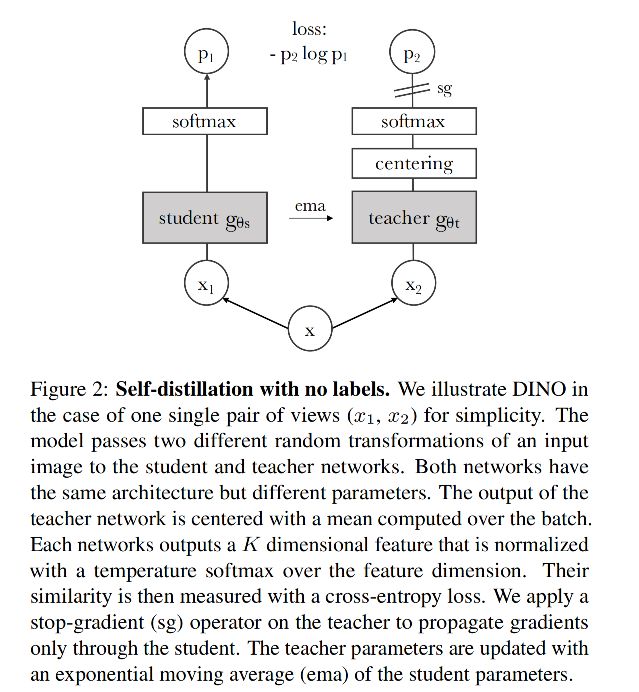
整个框架是自蒸馏的框(自己学习自己):输入的是一张不带标签的图片,使用代理学习(数据增强)来获得两个不同视角的图片,teacher 模型和 student 模型的结构完全一致
-
左边是 student 网络:使用梯度更新参数
- student 网络学习的目标是 teacher 网络的输出,输入的是 crop 大于 50% 的大子图,或小于 50% 的小子图
- 权重的更新方式是使用梯度回传的方式更新,经过 student 模型会输出特征
- 经过 softmax 后得到 p1 和 teacher 的输出特征 p2 求交叉熵损失
-
右边是 teacher 网络:使用 EMA 更新参数,且 teacher 的参数也是随机初始化的,没有使用预训练好的模型
- teacher 网络的输出用于指导 student 网络的学习
- 输入的是 crop 大于原图 50% 内容的大子图
- 权重不使用梯度回传的方式更新,而是使用 EMA 的方式即动量的方式来更新权重
- 在经过 teacher 网络得到的输出上,会进行 centering 的操作,这个操作就是把整个 batch 的样本算一个均值,减掉均值就是 centering(BYOL 中对 batch norm 的讨论),防止模型坍塌
- θ t ← λ θ t + ( 1 − λ ) θ s \theta_t \gets \lambda \theta_t + (1-\lambda)\theta_s θt←λθt+(1−λ)θs,且 λ \lambda λ 在训练的时候设置为 0.996~1 之间,也就是每次 teacher 网络的更新特别小
-
在之前的对比学习方法中(如 MOCO)使用了 queue 中存储的样本作为负样本来进行对比学习,但 DINO 是没有对比学习 loss 的,更像是自监督学习中的 mean teacher。
图 6 展示了使用不同方式更新 teacher 模型参数所带来的效果:
- student copy:每次 student 更新后直接把参数复制到 teacher
- previous iter:就是直接使用上一个 iter 的参数来更新 teacher
- previous epoch:就是直接使用上一个 epoch 的参数来更新 teacher,能够取得和 MOCOv2 或 BYOL 类似 效果
- Momentum:能够得到最好的效果
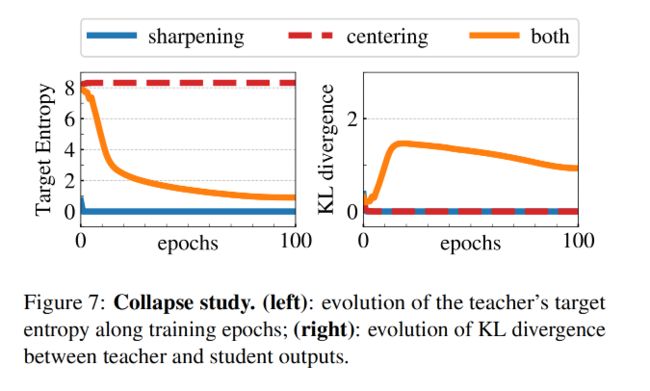
Centering 的效果:防止模型坍塌
伪代码:和 MOCOv3 非常像

四、效果

图 3 展示了不同 attention head 能够注意到不同的语义区域,哪怕当两个不同语义的目标叠加、遮挡非常严重的时候,也能区分开开

图 4 展示了有监督的训练和 DINO 的效果,有监督的模型在图片上的注意力不集中而且很散乱

图 8 和图 10 展示了更多自注意力的可视化效果,图片源自 COCO val
图 8 上的点对应的特征图框表示和该点的相关性

图 11 展示了 DINO 提取到的 ImageNet val 特征的 t-SNE 可视化,每个类别是使用所有图片的 embedding 的平均后得到的,可以看出类间相关性更高的类会被聚合到一起。
