Aurora 8B/10B
目录
- 1. Overview
- 2. Feature List
- 2. Block Diagram
- 3. PDU Transmission Procedure
-
- 3.1. User Interface
-
- Framing Interface
- Streaming Interface
- 3.2. Clock Compensation
- 3.3. Aurora 8B/10B Frame Gen
- 3.4. 8B/10B Transmission Code
- 4. PDU Reception Procedure
- 5. Flow Control
-
- 5.1. User Flow Control(UFC)
- 5.2. Native Flow Control(NFC)
- 6. Status and Control Ports
- 7. Transceiver Interface
- 8. Clock and Reset Ports
本篇blog将介绍由xilinx开发的Aurora 8B/10B链路层协议,并介绍aurora ip使用。
pg046 - Aurora 8B/10B v11.1 LogiCORE IP Product Guide
sp002 - Aurora 8B/10B protocol spec
ug476 - 7 Series FPGAs GTX GTH TransceiversUser Guide
FPGA高速接口设计指南 - 知乎
Xilinx平台Aurora IP介绍(汇总篇)- CSDN
一天上手Aurora 8B/10B IP核----汇总篇
Aurora 8B/10B IP核(一)——Aurora概述及数据接口 - 电子发烧友
Xilinx FPGA平台GTX简易使用教程(汇总篇)- CSDN
AURORA 8B/10B IP 核详解- CSDN
1. Overview
Aurora 8B/10B协议是一个用于在点对点串行链路间移动数据的可扩展轻量级链路层协议(由Xilinx开发提供)。
该协议能够方便对接GT等高速收发器,在AURORA的基础上可以运行诸如Ethernet和TCP/IP等常用逻辑层协议,或其他自定协议,可扩展性高。
Aurora 8B/10B常用于FPGA之间通信,可应用在多个GT收发器之间传输数据,最多可实现16个GT(包括GTX、GTP、GTH等)。可配置成单工or全双工模式。吞吐量可从480Mbit/s扩展到84.48Gbit/s,取决于GT的数量及线速率。
下图是典型的基于Aurora 8B/10B协议的全双工串行通信流程图。两个aurora channel cores通过多组lanes连接,实现相互通信。每组lane表示一根串行发送数据线和一个串行接收数据线,常说的GTH4X或GTH8X指的就是4组lanes或8组lanes。
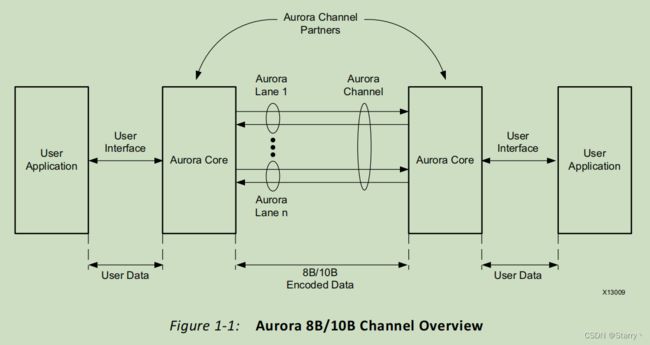
Xilinx的Aurora 8B/10B IP核可以在连接到另一个aurora之后自动初始化链路,并将数据以frame或stream的形式收发。传输的用户数据(Protocol Data Units,PDU)可以是任意大小,aurora会对其进行打包,并通过8B/10B规则进行重编码,以检测错误。如果用户不传输数据,aurora也会发送IDLE数据以保持通信、防止电子干扰。同时可通过流量控制(Flow control)对数据传输速率进行控制。
8B/10B编码是将8bit数编码成10bit数进行传输,以尽量平衡0和1的个数以实现DC平衡,同理还有64B/66B编码。
如果aurora建链失败,或是数据检验错误,将会进行复位并重新建链
2. Feature List
● Aurora 8B/10B协议定义了以下内容:
物理层接口:电气特性、时钟编码、符号编码(symbol coding)
初始化与错误处理:定义了通讯双方通讯前的初始化操作,同样定义了通讯双方在出现错误时的操作(复位和重建链)
数据分段(data striping):定义了通讯数据如何映射到多个通道
链路层(link layer):链路层定义了用户数据的封装方式(帧头、帧尾、pad等)
流控(flow control):流控机制解决通信双方速率不一致所带来的缓存不足的问题
● Aurora 8B/10B协议未定义的内容:
错误指示和恢复:Aurora 8B/10B协议没有定义检测用户pdu错误的机制,也没有定义在8B/10B编码之外从错误中恢复的机制
数据交换:Aurora 8B/10B协议没有定义寻址方案,因此不能支持链路层复用或交换
2. Block Diagram
Aurora 8B/10B IP核如下图所示

其中
● GT Transceiver:Aurora 8B/10B 协议的物理层实现。千兆比特高速收发器(Gigabit Transceiver, GT),用于大容量高速率数据收发,其线速率从500Mb/s到13.1Gb/s不等。
Aurora 8B/10B核例化时自动调用所需的GT接口,每个GT对应1组lane,其内部的物理编码子层(Physical Coding Sublayer,PCS)可实现Aurora协议所需的IDLE序列产生、8B/10B编解码、lane状态监视等功能。而物理媒体连接子层(Physical Medium Attachment, PMA)可将10bit数据串行差分发送出去,或是将收到的串行数据解串对齐形成10bit数据。
● Lane Logic: 每条Lane都包含一个GT,每个Lane驱动1个GT,可实现处理编解码及错误检测等。
● Global Logic: 执行通道初始化的绑定和验证阶段。 可生成Aurora协议所需的随机空闲字符,并监控所有lane逻辑模块的错误。
● RX User Interface: 接收端用户接口,使用AXI4-Stream格式将数据从channel传到用户端,并可进行接收流控。
● TX User Interface: 发送端用户接口,使用AXI4-Stream格式将数据从用户端传到channel,并进行发送流控功能。核中具有标准时钟补偿(Clock Compensation)模块,可实现时钟补偿字符的周期性传输。
3. PDU Transmission Procedure
用户层接口是基于AMBA AXI4-Stream格式进行交互的,也可添加流控功能。
启用以下接口需要在IP核中设置
高级可拓展接口 4.0 - 流传输(Advanced eXtensible Interface 4 - Stream, AXI4-Stream)
3.1. User Interface
Framing Interface
可以选择帧格式对用户数据封装,接口如下
| Group | Signal | Direction | Width(bits) | Clock Domain | Description |
|---|---|---|---|---|---|
| USER_DATA_S_AXI_TX | s_axi_tx_tdata | input | 8n | user_clk | 发送数据。此处n表示待发送数据的字节数,且8n=Lanes个数×Lane位宽 |
| s_axi_tx_tready | output | 1 | user_clk | ||
| s_axi_tx_tlast | input | 1 | user_clk | ||
| s_axi_tx_tkeep | input | n | user_clk | 指示数据中哪个字节是有效的,仅在last拉高时该数据有效 | |
| s_axi_tx_tvalid | input | 1 | user_clk | ||
| USER_DATA_M_AXI_RX | m_axi_rx_tdata | output | 8n | user_clk | |
| m_axi_rx_tlast | output | 1 | user_clk | ||
| m_axi_rx_tkeep | output | n | user_clk | 指示数据中哪个字节是有效的,仅在last拉高时该数据有效 | |
| m_axi_rx_tvalid | output | 1 | user_clk |
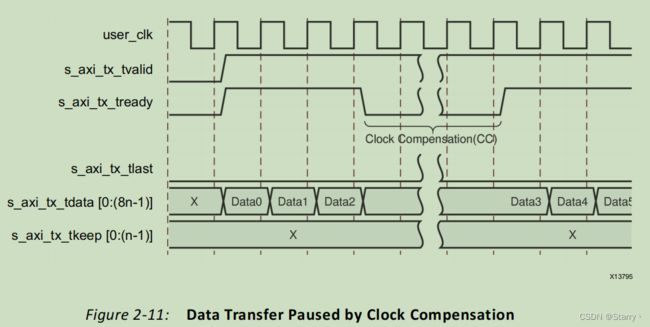
对于用户待发送的数据PDU,核通过AXI4-Stream协议获取PDU,获取过程中s_axi_tx_tvalid为高表示数据有效,用户可将其拉低暂停交互,但Aurora IP会自动插入IDLE字符,如下图所示。

Streaming Interface
流式接口去掉了last和keep信号,该接口下Aurora 核将进行流水传输,始终可用于写入。当s_axi_tx_tvalid拉低则Aurora IP会自动插入IDLE字符,
| Group | Signal | Direction | Width(bits) | Clock Domain | Description |
|---|---|---|---|---|---|
| USER_DATA_S_AXI_TX | s_axi_tx_tdata | input | 8n | user_clk | 发送数据。此处n表示待发送数据的字节数,且8n=Lanes个数×Lane位宽 |
| s_axi_tx_tready | output | 1 | user_clk | ||
| s_axi_tx_tvalid | input | 1 | user_clk | ||
| USER_DATA_M_AXI_RX | m_axi_rx_tdata | output | 8n | user_clk | |
| m_axi_rx_tvalid | output | 1 | user_clk |
3.2. Clock Compensation
同时,Aurora核也可能会在获取PDU过程中将s_axi_tx_tready拉低,以插入时钟补偿(Clock Compensation),每个lane每发送10000bytes就要发送12byte的时钟补偿符号。
也就是说,如果lane位宽是2bytes,则获取PDU达到5000个user_clk,就要插入6个user_clk进行时钟补偿。如果lane位宽是4bytes,则获取PDU达到2500个user_clk,就要插入3个user_clk进行时钟补偿,
3.3. Aurora 8B/10B Frame Gen
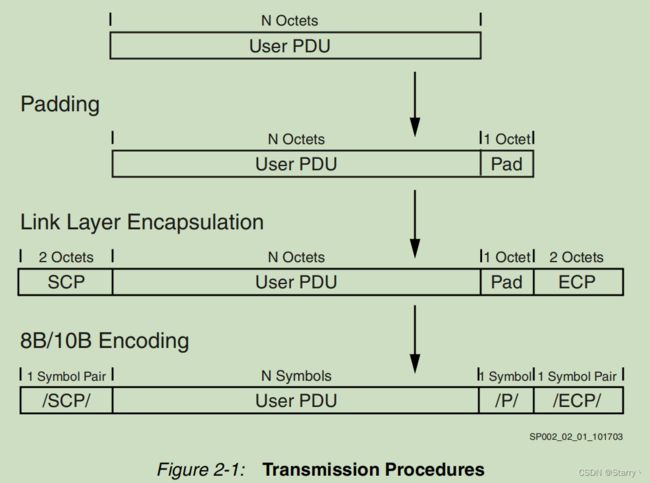
当Aurora核采样到s_axi_tx_tlast就知道PDU发送完毕,根据s_axi_tx_tkeep的值对PDU修正,之后将PDU转化成Aurora 8B/10B数据帧。过程如下:
-
Padding:如果形成的帧是奇数个bytes,则在PDU末尾加入1byte的pad数据,数值为0x9C
-
Link Layer Encapsulation:在帧头(Start Of Frame, SOF)处填入2bytes的起始通道协议码组(Start of Channel Protocol code group, SCP),再在帧尾(End Of Frame, EOF)处填入2bytes的终止通道协议码组(End of Channel Protocol code group, ECP),对于中途
s_axi_tx_tvalid拉低的情形,则插入2bytes空闲码组(IDLE code group)。这一步形成的叫 链路层数据(Link Layer Payload) -
8B/10B Encoding:之后将数据送入GT高速接口进行8B/10B编码,并将每个byte数据按照一个表格重编码成10bit的数据。8B/10B编码尽量实现0、1平衡,并使数据有足够多的跳变以回复时钟。
-
Serialization and Clock Encoding:再将Aurora 8B/10 数据帧进行串行化和时钟编码,差分发送
3.4. 8B/10B Transmission Code
4. PDU Reception Procedure
5. Flow Control
双方在通信的时候,如果发送方的发送速率太快,会导致接收方处理不过来,如果接收方缓存FIFO满了发送方还在疯狂发送数据,就会导致数据丢失。因此流控的意义就在于控制发送方的发送速率,让接收方与发送方处于一种动态平衡。
目前支持的流控机制有两种:Native Flow Control(本地流控);User Flow Control(用户流控)。
5.1. User Flow Control(UFC)
5.2. Native Flow Control(NFC)
本地流控机制是,用户通过NFC接口可以控制接收方Aurora 核通过TX向发送方发送NFC数据,以控制发送方发送IDLE多少拍,以防止接收方的RX FIFO溢出。
所以用户端需要编写监控模块,输入是RX FIFO状态,输出是NFC控制数据,连接到Aurora 核的NFC接口。注意该模块需要考虑检测RX FIFO状态,到发送方响应NFC这个过程的延迟有多久。
接口如下
| Group | Signal | Direction | Width(bits) | Clock Domain | Description |
|---|---|---|---|---|---|
| NFC_S_AXI_TX | s_axi_nfc_tx_tdata | input | 4 | user_clk | 指定发送方要发送的IDLE时钟周期个数 |
| s_axi_nfc_tx_tready | output | 1 | user_clk | ||
| s_axi_nfc_tx_tvalid | input | 1 | user_clk | ||
| NFC_M_AXI_RX | m_axi_nfc_rx_tdata | output | 8n | user_clk | 获取发送方要发送的IDLE时钟周期个数 |
| m_axi_nfc_rx_tvalid | output | 1 | user_clk |
其中s_axi_nfc_tx_tdata数值和IDLE周期个数关系如下表

需要说明的是,当接收方收到用户的NFC请求,但又有PDU需要发送给发送方时,NFC优先发送,即优先级:NFC > PDU。如下图所示
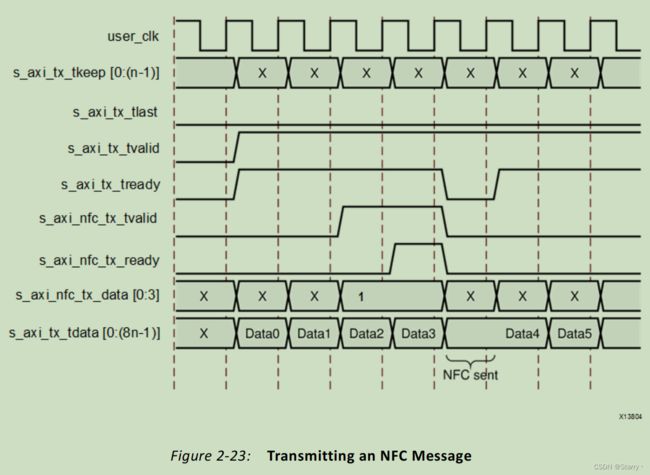
当发送方收到接收方发来的NFC请求时,会解析NFC Codes使s_axi_tx_tready拉低。如下图所示需要插入2拍IDLE,故拉低2拍。
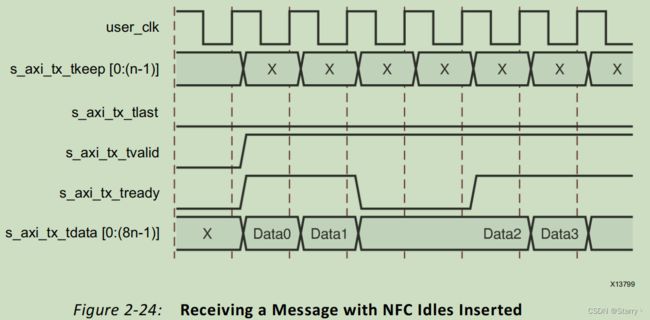
如果是immediate NFC mode就如同上图那样,发送端一旦解析完毕NFC请求后,立刻拉低s_axi_tx_tready。如果是completion mode,发送端就会在解析完毕NFC请求后,待当前PDU发送完毕后,再发IDLE。