python语音识别
语音识别技术,也被称为自动语音识别,目标是以电脑自动将人类的语音内容转换为相应的文字。应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。
一、功能概述
实现将语音转换为文字,调取第3方接口。比如百度ai,图灵机器人,得到想要的结果。
二、软件环境
操作系统:win10
语言:Python 版本:3.5.4
Python库:baidu-aip
三、原理概述
利用windows自带的录音机,基于百度API进行wav格式的音频转文本。根据文本,调取图灵机器人接口,得到结果。
四、部署工作
1 登录百度ai,链接为:
https://ai.baidu.com/
登录账户(如果你有百度,可以直接登录,否则需要注册)
点击右边的控制台->直接进入
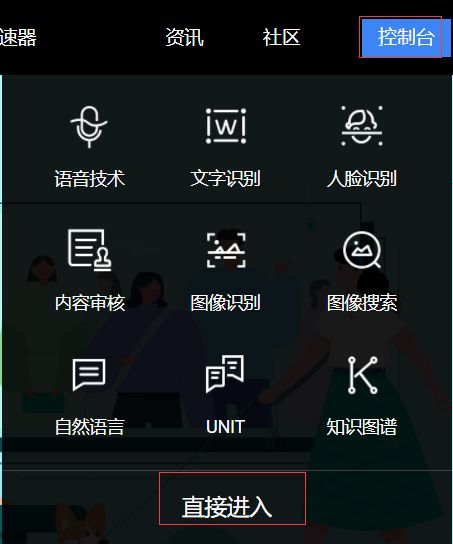
进入之后,拖动进度条到中间。找到已开通服务,点击百度语言。
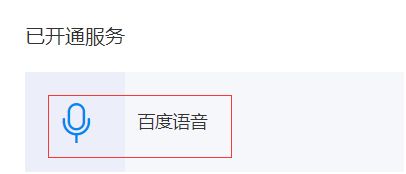
点击创建应用

应用名字,可以自定义。我写的是语音识别,默认就已经开通了语音识别和语音合成。
这就够了,所以接口选择,不用再选了。
语音包名,选择不需要。因为接下来要展示的是用Python代码实现的,不是android和ios
应用描述,这里一定要好好写啊。不然不通过的!
点击立即创建,瞬间就创建成功了。我估摸着,我写的描述太吊了。百度不得不同意哈!
点击返回列表,在Secret Key的下面,点击显示。
复制AppID,API Key,Secret Key 这3个信息到一个文件里面。接下来的Python代码会用到!

点击左侧的技术文档
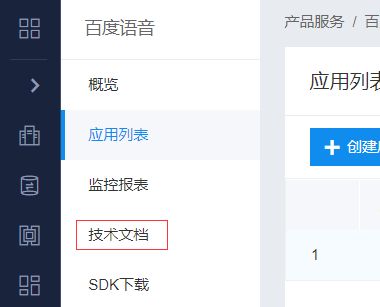
点击左边的语言合成->SDK文档->Python SDK

文本不能太长

目录结构

支持2x和3x
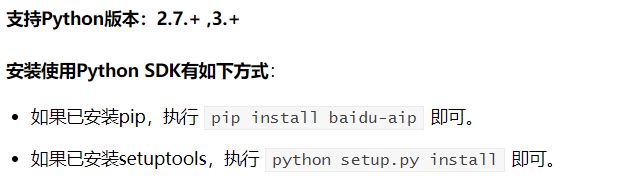
打开windows的cmd窗口,输入命令 pip3 install baidu-aip
我已经安装好了,效果如下:

打开Pycharm,新建一个目录ai
创建文件audio_text.py
代码如下:
import time
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '11212345'
API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
将前面提到的AppID,API Key,Secret Key,复制到对应位置。
上面的id和KEY,后5位我改了,复制我的也没有用!
继续看文档,下面的代码可以把文件变成语言

代码如下:
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '11212345'
API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis('你好百度', 'zh', 1, {
'vol': 5,
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('auido.mp3', 'wb') as f:
f.write(result)
执行代码,会看到当前目录出现了一个auido.mp3文件,打开播放器,听一下声音。
我用QQ影音,打开正常
![]()
看参数

看上面的代码,可以发现
‘你好百度’ 对于参数text
‘zh’ 表示中文
1 表示客户度类型
result = client.synthesis('你好百度', 'zh', 1, {
'vol': 5,
})
再来加几个参数
result = client.synthesis('你好百度', 'zh', 1, {
'spd':5, # 语速-中等
'vol': 5, # 音量-中等
'pit':5, # 音调-中等
'per':0 # 发音人-女声
})
per的参数,如果是0,表示女声。我比较喜欢听女声,不要问我为什么!
语速,音量,音调,大家可以自行调节,声音会有相应的变化。
假设一段文件,有1000个子,可以使用split()方法切割,就可以得到多段语言。
接下来,需要进行语音识别,看文档
点击左边的百度语言->语音识别->Python SDK
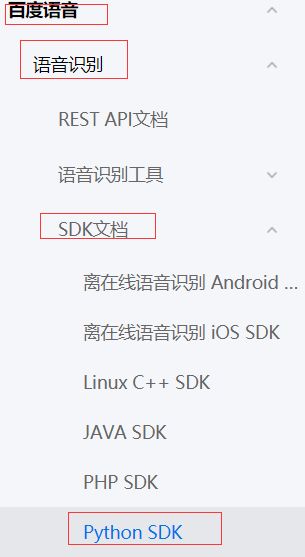
支持的语言格式有3种。分别是pcm,wav,amr
建议使用pcm,因为它比较好实现。而另外2种语言格式,有非常高的要求,只有专业级别的设备才能录制。它才能达到百度的要求。

使用windows录音工具,保存的是wav格式,那么就需要将wav转换为pcm格式。
下面介绍一个工具ffmpeg,百度搜索就能找到。
打开网址:
http://ffmpeg.org/download.html
点击windows图标,点击Builds
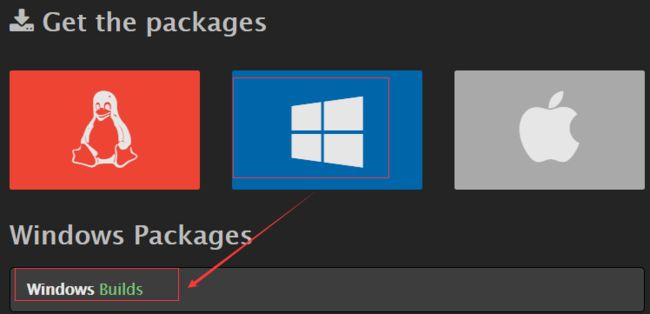
我的电脑是64位系统,选择64位,一定要选择Shared,最后点击下载。
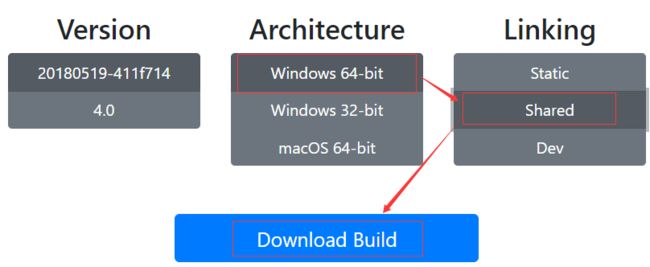
下载完成后,将包解压到你常用的安装目录,我的安装目录是D:\Program Files (x86)
进入目录
D:\Program Files (x86)\ffmpeg-20180518-16b4f97-win64-shared\bin
里面有一个ffmpeg.exe,后面的Python代码会调用它。
添加环境变量
打开我的电脑->高级系统设置->环境变量->编辑

点击右边的新建,输入路径D:\Program Files (x86)\ffmpeg-20180518-16b4f97-win64-shared\bin
之后,一路确定…
关闭cmd窗口,再次打开cmd窗口,输入命令 ffmpeg
出现下面橘黄色提示,就表示环境变量添加成功了。
这个时候,一定要关闭Pycharm,否则Pycharm识别不到。
再次开启Pycharm
Pycharm用法如下:
ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm
第一个%s 表示原始文件
第二个%s 也是原始文件,它加了后缀.pcm
继续看文档,语言时长,不要超过60s

请求时,要指定一个pcm格式的文件

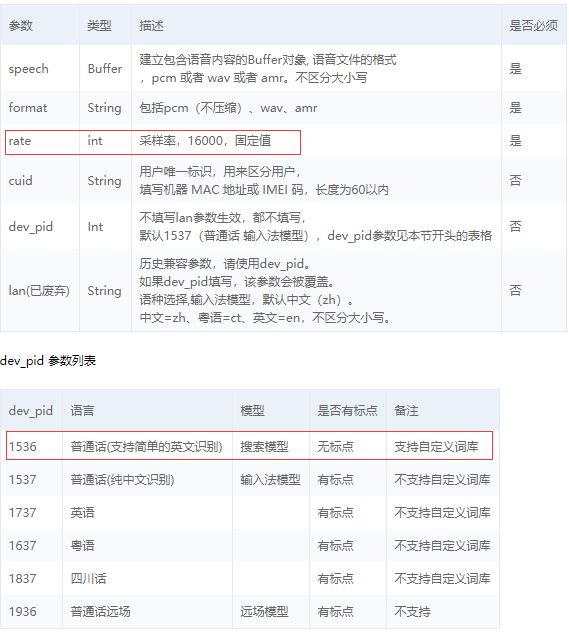
看参数,主要用到的是rate和1536
上图的16000表示采样率
1536表示能识别中文和英文,它的容错率比较高
1537必须是标准的普通话,带点地方口音是不行的。
所以建议使用1536
打开win10自带的录音机,录制一段声音,比如:你叫什么呀
一定要带一个呀字,下面的代码执行会输出10个结果,否则只有一个!
注意:笔记本的麦克风在摄像头的2边,所以录制的时候,一定要对着摄像头!
默认为m4a格式的,重命名为whatyouname.m4a,将文件放入ai目录
新增文件a_t.py,内容如下:
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '11212345'
API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
a = client.asr(get_file_content('whatyouname.m4a'), 'pcm', 16000, {
'dev_pid': 1536,
})
print(a)
注意上面的id和key。文件名为whatyouname.wav
执行文件,输出:
{‘sn’: ‘7436726851526824321’, ‘err_no’: 3301, ‘err_msg’: ‘speech quality error.’}
返回错误’err_no’: 3301
看文档

找下面对应的3301,表示声音不清晰!

再仔细用播放器,播放一下刚才的声音,挺清晰的呀!
这里报3301不是因为声音不清晰,而是格式不支持。
使用os模块调用ffmpeg实现转码
代码如下:
import os
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '11212345'
API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath)
os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可
with open(filePath + ".pcm", 'rb') as fp:
return fp.read()
# 识别本地文件
a = client.asr(get_file_content('whatyouname.m4a'), 'pcm', 16000, {
'dev_pid': 1536,
})
print(a)
执行输出,效果如下:

上面红色文件,不是报错,而是转码过程
主要看err_msg是什么,这里显示success,表示成功。
在ai目录下,会多出一个文件whatyouname.m4a.pcm。这个文件才是刚才真正发给百度的语言文件
返回的结果是一个字典,第一个结果,一般是最正确的。取第一个,就可以了!
接下来,就需要从字典取值。字典取值,不要用以下这种方法:
print(a['result'])
为什么呢?如果key不存在,会直接报错!毕竟报错,是要崩溃的…
所以建议使用get方法,将最后一行的print(a),修改为以下内容:
完整代码,我就不贴了。
if a.get('result'):
print(a.get('result')[0])
执行输出:

从结果上来看就只有一个了。
jieba分词,完全开源,有集成的python库,简单易用。
jieba分词是基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG),动态规划查找最大概率路径, 找出基于词频的最大切分组合
安装jieba
在安装有python3 和 pip 的机子上,安装jieba库很简单,使用pip即可:pip3 install jieba
由于包很大,默认使用国外更新源比较慢,下面使用国内更新源安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
下图表示已经安装好了

新建一个文件jieba_test.py,代码如下:
import jieba
a = jieba.cut('你叫什么名字')
print(a)
执行输出:
![]()
它是一个生成器对象,转换为列表
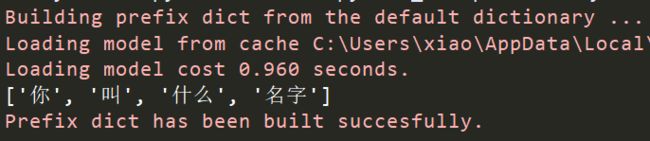
import jieba
a = list(jieba.cut('你叫什么名字'))
print(a)
执行输出:
换一句话
import jieba
a = list(jieba.cut('我想听周杰伦的夜曲'))
print(a)
执行输出:

发现,断句不对。应该是下面的结果
['我想听', '周杰伦', '的', '夜曲']
新建一个words.py文件,用来存放关键字,内容如下:
KEY_WORDS = ["我想听",
"我要听",
"播放",
"名字是什么",
"名字叫什么",
"你叫什么名字"
]
导入words模块,也就是上面写的文件
import jieba
import words
for i in words.KEY_WORDS: # 遍历关键字
jieba.add_word(i) # 在程序中动态修改词典
a = list(jieba.cut('我想听周杰伦的夜曲'))
print(a)
执行输出:

除了使用jieba.cut以外,还有一个方法jieba.cut_for_search
该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
图灵机器人是以语义技术为核心驱动力的人工智能公司,致力于“让机器理解世界”,产品服务包括机器人开放平台、机器人OS和场景方案。
官方地址为:
http://www.tuling123.com/
首先得注册一个账号,或者使用第3方登录,都可以。
登录之后,点击创建机器人
机器人名称,可以是自己定义的名字
选择网站->教育学习->其他 输入简介
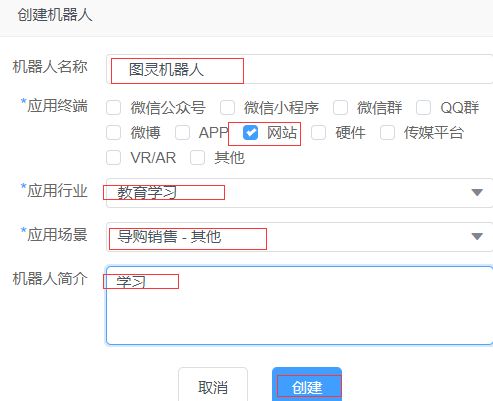
创建成功之后,点击终端设置,拉到最后。
可以看到api接入,下面有一个apikey,待会会用到

右侧有一个窗口,可以和机器人聊天
点击api使用文档,初学者,先看Web API V1.0的
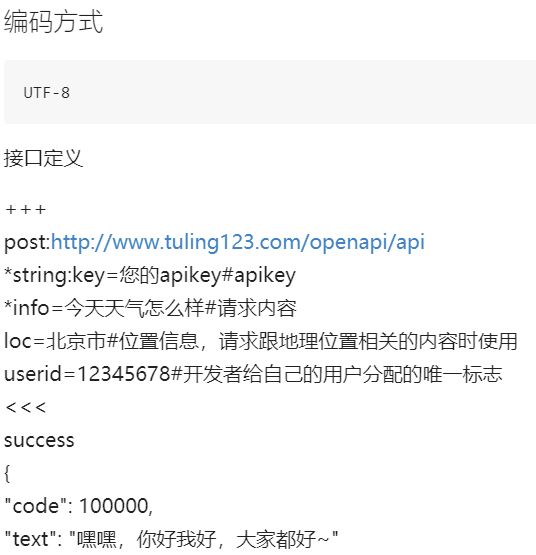
新建一个文件tuling.py,内容如下:
import json
import requests
urls = 'http://www.tuling123.com/openapi/api' # 请求地址
data_str = {
"key":"6a944508fd5c4d499b9991862ea12345", # 你的apikey
"info":'今天天气怎么样', # 请求内容
"userid":123, # 开发者给自己的用户分配的唯一标志
}
a = requests.post(urls,data_str) # 必须使用post请求
content = (a._content).decode('utf-8') # 获取返回结果_content属性,并解码
s = json.loads(content) # 反序列化
print(s)
key是你创建机器人的apikey,上面的代码,后5位我改了,复制没用的!
执行代码输出:
{‘text’: ‘请问你想查询哪个城市’, ‘code’: 100000}
修改info为 北京
再次执行,输出:
{‘code’: 100000, ‘text’: ‘北京:周日 05月27日,多云 西南风3-4级,最低气温17度,最高气温32度’}
参数解释:
userid 表示上下文标记,用来区分用户。举个例子,如果我更改了userid,那么我问"今天天气怎么样"
它会返回给我"你想查询哪个城市"。而我不改userid,它会直接返回天气结果。
上下文,好像只能保留上一次,我回复的内容。
a的返回结果是一个requests对象,_content才是我们真正需要的结果。
它是一个bytes类型,需要解码。解码之后一个json数据类型,反序列之后,就可以得到字符串了。
得到字符串之后,就可以调用百度接口,生成语音文件
创建一个audio_test.py文件,用来将字符串生成语音文件,内容如下:
import time
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '11212345'
API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def text_to_audio(text):
file_name = time.time() # 保证文件名不重复
result = client.synthesis(text, 'zh', 1, {
'spd':5,
'vol': 5,
'pit':5,
'per':0
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('%s.mp3'%(file_name), 'wb') as f:
f.write(result)
return '%s.mp3'%(file_name)
打开tuling.py,导入模块audio_test
import json
import requests
import audio_text
urls = 'http://www.tuling123.com/openapi/api' # 请求地址
data_str = {
"key":"6a944508fd5c4d499b9991862ea12345", # 你的apikey
"info":'今天天气怎么样', # 请求内容
"userid":123, # 开发者给自己的用户分配的唯一标志
}
a = requests.post(urls,data_str) # 必须使用post请求
content = (a._content).decode('utf-8') # 获取返回结果_content属性,并解码
s = json.loads(content) # 反序列化
print(audio_text.text_to_audio(s.get['text']))
执行输出: 1527421766.491485.mp3
在当前目录会生成一个音频文件,打开播放一下
有一个女生的声音,说:“请问你想查询哪个城市”
非常Nice
修改a_t.py,封装成函数,完整代码如下:
import os
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '11212345'
API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def get_file_content(filePath):
print(filePath)
cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath)
print(cmd_str)
os.system(cmd_str)
with open(filePath+".pcm", 'rb') as fp:
return fp.read()
# 识别本地文件
def audio_text(file_path):
a = client.asr(get_file_content(file_path), 'pcm', 16000, {
'dev_pid': 1536,
})
# print(a["result"])
if a.get("result") :
return a.get("result")[0]
修改jieba_test.py,导入模块,完整代码如下:
import jieba
import words
import tuling
for i in words.KEY_WORDS:
jieba.add_word(i)
def fenci(text):
a = list(jieba.cut(text))
# print(a)
user_key_name={
"你叫",
"你叫什么",
"你的名字",
"名字叫什么",
"你叫什么名字",
"名字是什么"
}
if user_key_name.intersection(a):
a = tuling.to_tuling('我叫肖',1)
#print('我叫肖')
print(a)
return a
a = tuling.to_tuling(text,'ai01')
return a
修改tuling.py,完整内容如下:
import json
import requests
import audio_text
urls = 'http://www.tuling123.com/openapi/api'
def to_tuling(text,uid):
data_str = {
"key":"6a944508fd5c4d499b9991862ea12345",
"info":text,
"userid":uid,
}
a = requests.post(urls,data_str)
content = (a._content).decode('utf-8')
s = json.loads(content)
print(s)
return audio_text.text_to_audio(s.get('text'))
新建文件wen_da.py,内容如下:
import a_t
import jieba_test
a = a_t.audio_text('How_is_the_weather.wav')
b = jieba_test.fenci(a)
How_is_the_weather.wav是我提前录制好的文件,内容是,北京天气如何?
执行wen_da.py,输出:
北京天气如何
{‘code’: 100000, ‘text’: ‘北京:周日 05月27日,多云 西南风3-4级,最低气温17度,最高气温32度’}
1527423163.572486.mp3
打开文件1527423163.572486.mp3,听声音,内容应该是
北京:周日 05月27日,多云 西南风3-4级,最低气温17度,最高气温32度
本地版的语言识别到这里就结束了!
这种方式很繁琐,很LOW!
来,看一个高大上的效果:
基于flask框架的语言识别系统
点击按钮,开始说话

说完之后,就直接语言播放天气

还能成语接龙

说不知道,就自动退出成语接龙模式

还可以听歌,比如说:“我想听世上只有妈妈好”
就会直接播放音乐
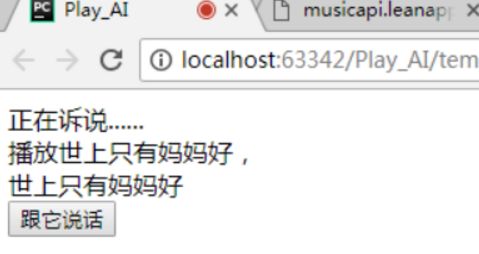
播放音乐功能,是调用了一个第3方接口musicapi