干货 | 携程度假基于 RPC 和 TypeScript 的 BFF 设计与实践
作者简介
工业聚,携程高级前端开发专家,react-lite, react-imvc, farrow, remesh 等开源项目作者,专注 GUI 开发、框架设计、工程化建设等领域。
一、前言
随着多终端的发展,前后端的数据交互的复杂性和多样性都在急剧增加。不同的终端,其屏幕尺寸和页面 UI 设计不一,对接口的数据需求也不尽相同。构建一套接口满足所有场景的传统方式,面对新的复杂性日益捉襟见肘。
在这个背景下,BFF 作为一种模式被提出。其全称是 Backend for frontend,即为前端服务的后端。它的特点是考虑了不同端的数据访问需求,并给予各端针对性的优化。
在这篇文章中,我们将介绍一种基于 RPC 和 TypeScript 的 BFF 设计与实践。我们称之为 RPC-BFF,它利用前后端都采用同一语言(TypeScript)的优势,实现了其它 BFF 技术方案所不具备的多项功能,可以显著提升前后端数据交互的性能、效率以及类型安全。
二、为什么会需要 BFF?
用发展的视角来看,业界存在的两大趋势催生了 BFF 模式:
硬件行业的多终端发展趋势
软件行业的微服务发展趋势
其中,微服务化以及中台化的趋势,改变了后端团队构建服务的方式。整个系统将按照领域模型分隔出多个微服务,这增强了各个服务的内聚性和可复用性的同时,也给下游的接口调用者增加了数据聚合的成本。
多终端的发展,又让数据聚合的需求进一步多样化。使得处于微服务和多终端之间的团队,不管是前端团队还是后端团队,他们面对的问题日趋复杂化。
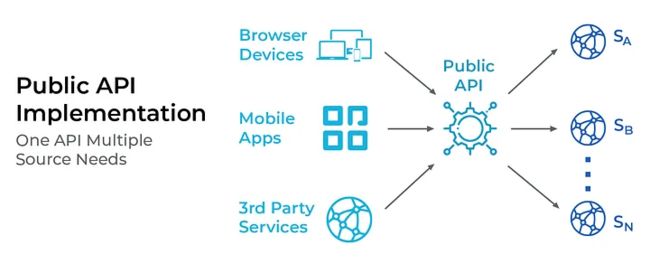
系统复杂度的增加,将体现在代码复杂度和团队协作复杂度上。这意味着,没有采用有效手段应对复杂度的团队,自身将成为产研流程中的瓶颈。他们既要面对上游多个微服务的联调需求,又要应对下游多个端的数据消费需求;有更多的会议要参加,更多的需求文档要读,更多的代码、单元测试和技术文档要写,然而敏捷开发模式的交付周期却不随之增加。
此时一般有两个应对策略。一种是去掉数据聚合层,让各个下游前端应用自行对接微服务接口,将聚合数据的业务逻辑转移到前端,增加它们的代码体积,拖慢其加载速度,同时显著增加客户端向服务端发起的请求数,达到拉低页面渲染性能,破坏用户体验的效果。
另一种做法则是采用 BFF 模式,降低前后端数据交互的复杂度。微服务强调按领域模型分隔服务,BFF 则强调按终端类型分隔服务。将原本单个团队处理“多对多”的复杂关系,转变成多个团队处理的“一对多”关系。因此,本质上,BFF 模式的优化方式是通过调整开发团队在人力组织关系层面的职能分工而实现的。
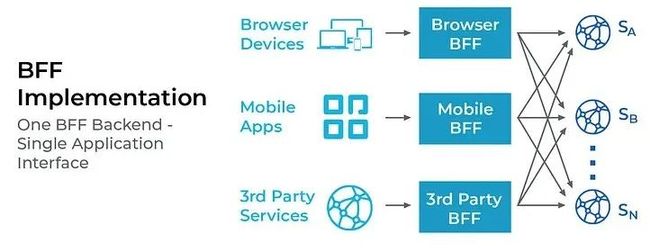
也就是说,BFF 不是作为新技术用以提升生产力,而是通过改变生产关系去解放生产力。从单一团队成为产研流程中的单点瓶颈,转变成多个 BFF 研发团队各自应对某一端的数据聚合需求。
这种转变所争取到的是增加人手以提升效率的空间。一个工作任务相耦合的研发团队不能无限加人提效,但若能拆成多个研发团队,则可以扩大每个子团队的提效空间。当然,代价是团队之间可能存在重复工作,只是相比效率瓶颈而言,这些问题可能不属于现阶段主要矛盾,值得取舍。
尽管 BFF 不是新技术,也不要求新技术,但不意味着不能引入新技术,或者引入新技术无法提效。我们仍可以用新技术去实现 BFF,解决因团队拆分而产生的问题,收获研发效率(生产力)和产研流程(生产关系)两方面的提升。
接下来,我们先看一下实现 BFF 的几种不同方式,然后介绍作为新技术出现的 RPC-BFF。
三、BFF 的实现方式
如前所述,BFF 是作为模式(Pattern)被提出,而非一种新技术。在技术层面上,任何支持服务端开发的语言和运行时,不管是 Java、Python、Go 还是 Node.js,都可以开发 BFF 服务。只要它们所实现的这个服务,是面向前端需求的。
BFF 的实现方式多种多样,不仅跟技术选型有关,跟研发团队的分工方式、职能边界、协作流程等因素也息息相关。
3.1 朴素模式
所谓的朴素模式,是指 BFF 的实现方式不改变前后端的分工方式、职能边界和协作流程。前端不介入 BFF 层的实现,BFF 层的需求由后端团队自行消化。
也就是说,BFF 在这里仅仅是后端团队的内部分工:
开发微服务应用(后端团队)
开发 BFF 服务(后端团队)
消费 BFF 接口(前端团队)
前端的工作方式跟之前一样,后端负责开发 BFF 为前端团队提供面向前端的数据聚合接口。开发 BFF 的编程语言由后端决定。
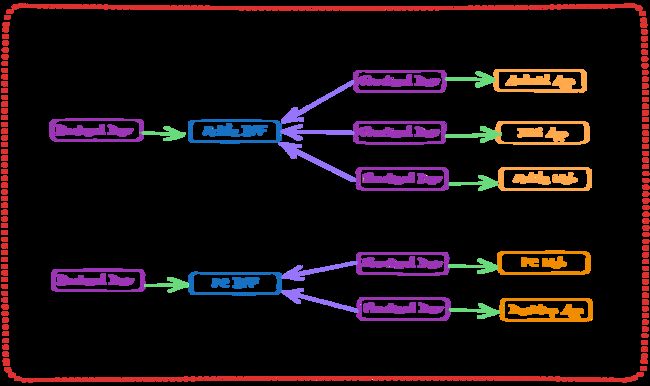
如上图所示,紫框为研发团队(前端或后端),蓝框为 BFF 服务,黄框为前端应用,绿色箭头表示“开发”,紫色箭头表示“调用”。
在图示中,BFF 按照终端尺寸分为 Mobile BFF 和 PC BFF 两类,它背后的假设是:相近终端尺寸的前端应用拥有相近的数据访问需求。移动端应用调用 Mobile BFF,PC 端应用调用PC BFF。
3.2 解耦模式
解耦模式,相比朴素模式而言,它改变了分工方式、职能边界和协作流程。后端不介入 BFF 层的实现,BFF 层的需求由前端团队自行消化。
也就是说,BFF 是前后端团队共同完成的一种新的分工:
开发微服务应用(后端团队)
开发 BFF 服务(前端团队)
消费 BFF 服务(前端团队)
前端的工作方式跟之前有所不同,前端团队自己开发 BFF 服务以供自己的前端应用消费聚合好的数据。开发 BFF 的编程语言由前端决定。
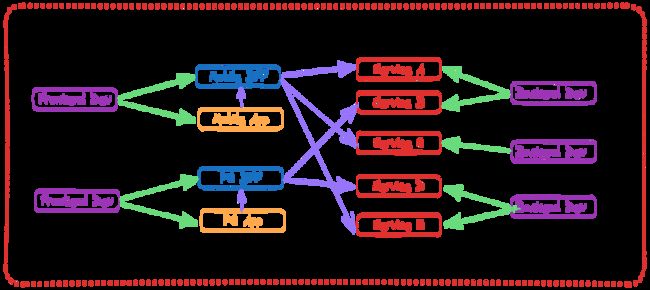
如上图所示,前端团队同时开发了 App 及配套的 BFF 服务。前端开发的 BFF 服务背后调用了后端团队提供的各个微服务接口,将它们聚合起来,转换为前端应用可直接消费的数据形态。
3.3 朴素模式 VS 解耦模式
两种模式都有其适用场景,具体要看不同研发团队的人力资源、应用类型和技术文化风格等多个因素。
从技术发展的角度,解耦模式更能代表“彻底的前后端分离”的趋势和目标。
前后端分离可以大体分为两个阶段:
渲染服务回归前端团队(SSR)
数据服务回归前端团队(BFF)
部分开发者可能认为完成了第一阶段,就达到了前后端分离的目标。此时前端团队可以自行构建SSR 服务器,更早介入渲染流程,不必等到浏览器加载页面的 JavaScript 脚本后才开始发挥作用。不必再跟后端频繁沟通,交代他们在 html 文件里添加指定的 id 或class 名;前端团队可以全权处理,后端团队只需要提供数据接口即可。
然而,“前后端分离”不只是把前端代码(如 html 文件)从后端代码仓库转移到前端代码仓库里,这只是形式和手段。前后端分离是指职能的分离,是为了让前端研发人员不必低效率地遥控后端研发人员,让他们去机械地调整面向前端需求的代码。前端团队可以自主负责、自主修改、快速迭代,专业的人做专业的事儿。
面向前端需求的代码,不仅仅是 html 文件,也包括了面向渲染优化的数据聚合代码。前端的职能是为用户开发出体验更好的 GUI 应用,有助于这个目标的所有合理的技术手段都在其职能范围之内。
让 SSR 服务从后端团队转到前端团队,是为了得到面向前端需求的界面渲染优化空间。让更加理解渲染优化原理的前端团队,可以在 SSR 服务上应用新的渲染优化措施,包括但不限于 Streaming SSR、Suspense、Selective Hydration、Server Component 等技术可以得以应用。它们可以显著提升页面的各项性能指标,令用户更早看到内容,更早看到有意义的内容,更早跟界面自由交互。
让 BFF 服务从后端团队转到前端团队,则是为了获得面向前端需求的数据聚合优化空间,可以提高代码的跨端复用率、减少前端应用的代码体积、减少前端应用的加载时间,提升用户体验。
当研发团队完成了 SSR 和 BFF 两个阶段的前后端分离后,前端团队同时掌握了 SSR 和 BFF 两重优化空间。他们既不需要让后端团队帮忙添加 id 和 class 到 html 文件中,也不需要让他们帮忙把某个文案添加到某个接口里。面向前端的渲染优化需求和数据优化需求,都能在前端团队职责范围内自主解决,显著减少前后端的沟通频次和成本,分离彼此的关注度,提升双方的专业聚焦水平。
更重要的是,SSR 和 BFF 在渲染优化上有着不可分割的关系。视图的渲染不是凭空的,它依赖数据的准备,有意义的内容才得以呈现;当视图需要流式渲染,数据请求也需要做相应配合。假设我们页面的首屏所依赖的数据,都被聚合到一个单一接口里,其后果便是 Streaming SSR 无法发挥充分价值;所有组件都在等待单一聚合接口的响应数据,才开始进行渲染。
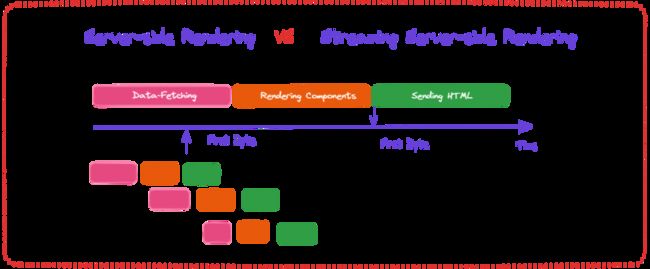
如上图所示,紫色箭头表示“时间”,粉色框为数据获取,橙色框为组件渲染,绿色框为发送 HTML 到浏览器。我们可以看到,朴素的 SSR 是一个串行过程,组件渲染阶段需要等待数据获取全部结束。而充分的 Streaming SSR 则有多次数据获取的并发任务(调用了多次后端接口),组件渲染并不需要等待所有数据获取任务结束,只需相关数据就位即可进入组件渲染及后续发送 HTML 的流程。用户可以更早看到内容。
在前端团队缺乏 BFF 掌控能力的情况下,他们无法自主控制 SSR 的数据获取过程,只能被动接受后端提供的接口。即便视图层框架(如 React)支持 Streaming rendering,也仅仅是把一大块 html 分多次发送给浏览器,它仍受制于 data-fetching 的阻塞时间,无法做到充分的 Streaming SSR。
因此,技术层面更合理的做法是,每个组件描述它自身所需的数据依赖,页面渲染时遇到没有数据依赖的静态组件,立即发送给用户,遇到有数据依赖的组件则发起请求(Render-As-You-Fetch),不同组件可以独立发起不同请求,每个组件数据请求完毕后即刻开始自身渲染,最终得到页面流式渲染,用户渐进式地看到一块块成形的界面渲染的效果。
我们可以看到,在这个渲染优化需求下,传统意义上的数据聚合思路(尽可能少的接口)反而是不利的;微服务式的多个接口,反而是有利的。当然,这不意味着前端直接对接微服务接口,不需要 BFF;这其实意味着我们需要 Streaming BFF 去解放 Streaming SSR 的潜力。
总的而言,彻底的前后端分离是指前端掌握了面向渲染优化的充分条件,包括 SSR 和 BFF 两个彼此紧密关联的优化空间,缺少任意一个,都难以获得充分的渲染优化能力。从这个角度来看,前端团队开发 BFF 是一个未来的技术方向。研发团队的分工模式随着技术发展,将从朴素模式逐渐转向解耦模式。
四、解耦模式的 BFF 技术选型
解耦模式的 BFF 服务由前端团队开发,所用的编程语言也由前端团队决定。大部分情况下前端团队会采用相同的编程语言(JavaScript/TypeScript),基于 Node.js 运行时开发相应的 BFF 服务。基于这个前提,我们讨论几种技术选型。
4.1 RESTful API
处于模仿阶段的前端团队,往往会采用 RESTful API 方式实现 BFF 服务。技术目标是把后端之前做但现在不做的功能,用同样的方式和思路让前端团队用Node.js 实现一遍。
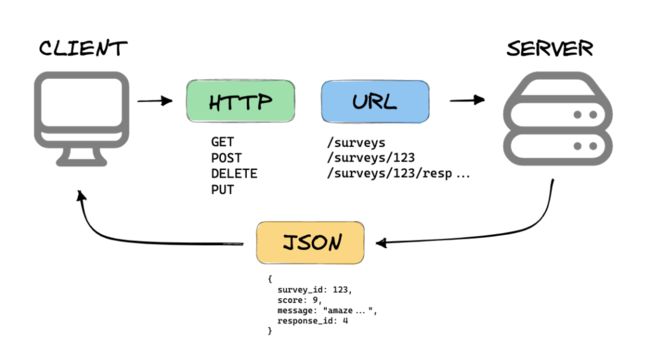 实现 BFF 服务的前端开发人员,其心智模型跟普通后端无异,涉及 URL,HttpRequest, HttpResponse, RequestHeader, Query, Body, Cookie, Authorization, CORS,Service, Controller 等等。
实现 BFF 服务的前端开发人员,其心智模型跟普通后端无异,涉及 URL,HttpRequest, HttpResponse, RequestHeader, Query, Body, Cookie, Authorization, CORS,Service, Controller 等等。
然而,即便是现在,掌握成熟后端接口开发能力的前端开发人员,依旧是稀缺的。所以,往往这种方式开发的 BFF 服务的质量,劣于专业后端开发的,并且几乎不考虑面向前端的极致优化,能满足需求已经达到了目标。
此外,从语义角度看,RESTful API 是面向资源的,跟面向前端需求的 BFF 场景并不契合。很多时候,前端需要的数据并不是后端资源的直接映射,而是经过聚合、转换、过滤、排序等处理后的结果。
因此,一开始基于 RESTful API 开发的 BFF 服务,最终将有意或无意、主动或被动地演变成只有一半功能的 RPC 服务。它的 url 参数设计是函数语义,而非资源语义,但调用这些远程函数时仍然要考虑 server-client 之间底层通讯细节。既没有被封装,也缺少优化。
4.2 GraphQL
GraphQL是一个面向前端数据访问优化的数据抽象层,它相当适合作为 BFF 技术选型,并且也是我们之前包括现在仍在使用的 BFF 方案。
它的技术特点是,在数据访问层实现了一定的控制反转(Inversion of control,IOC)的能力。
GraphQL 服务的开发者负责构建一个数据网络结构(Graph),支持其消费者根据自身需求编写 GraphQL Query 语句查询所需 JSON 数据(Tree)。这种灵活的查询能力,实际上是将前后端数据交互相关的代码分成了两部分,一部分是关于通用性的,放在数据提供方(GraphQL 服务)里,一部分是关于特殊性的,放在数据消费方(前端应用的查询语句)里。
如此,GraphQL BFF 可以将按终端尺寸分类的多个 BFF 整合成一个 BFF。从之前Mobile BFF 和 PC BFF,变成统一的GraphQL BFF。减少了两个 BFF 之间重复的部分。
Mobile BFF = GraphQL BFF + Mobile GraphQL Query
PC BFF = GraphQL BFF + PC GraphQL Query
通过统一的 GraphQL-BFF 配合差异的 *-GraphQL-Query 实现了之前多个 BFF服务提供的数据访问能力。
前端团队开发 GraphQL BFF 应用时,其心智模型不再是纯粹的后端概念,而是 GraphQL 相关的概念,如 Schema, Query, Mutation, Resolver,DataLoader, Directive, SelectionSet 等等,它们更加利于前后端数据访问的优化。更多详情可以阅读另一篇文章《GraphQL-BFF:微服务背景下的前后端数据交互方案》。
4.3 RPC
RPC 是指 Remote Procedure Call,即远程过程调用。这个模式也适用于 BFF 服务的实现。
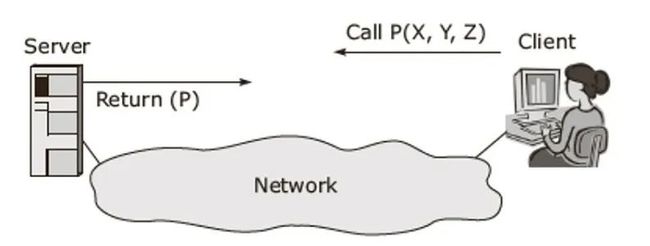
它的技术特征是,将实现端和调用端之间的通讯过程封装,作为技术细节隐藏起来,并不暴露给调用者。对于调用者而言,仿佛像调用本地函数。
正因如此,它不要求调用一次 RPC 函数即发起一次独立的通讯过程。它可以将多次 RPC 函数批量化(Batching)并流式响应(Streaming),进一步减少反复重建通讯过程的开销。
前端团队基于 RPC 模式开发 BFF时,其心智模型跟开发传统后端服务不同。所谓的接口设计,被转化为函数参数设计和返回值设计,沿袭了前端开发者熟悉的标准编程语言特性。相比 RESTful API 和 GraphQL 而言,RPC 引入更少概念和领域知识要求。
4.4 GraphQL VS RPC
我们团队从四年前开始使用 GraphQL-BFF,并成功落地到多个项目,取得了不错的效果。我们看到了它带来的好处和价值,同时也发现了它当前的一些局限性。为了突破桎梏,争取到更广阔的优化空间,我们开始探索 RPC-BFF 方案,并试图克服 GraphQL-BFF 方案未能解决的问题。
值得提醒的是,本文提到的 GraphQL-BFF 面临的难题,是在精益求精的层面上的探讨,并非否定和质疑 GraphQL 作为 BFF 方案的合理性。
GraphQL-BFF 的第一个难题是类型问题。GraphQL 是一个跨编程语言的数据抽象层,它自带了一套 Type System。使用具体某个带类型的编程语言(如 TypeScript)开发 GraphQL 服务时,就存在两个类型系统,因此难免有一些语言特性无法对齐以及类型重复定义的地方。
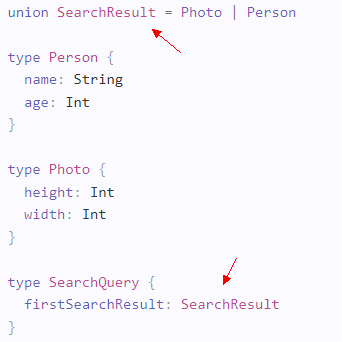
比如,GraphQL 的类型系统支持代数数据类型(Algebraic data type),可以用 union 定义 A 或 B 的类型关系。这在 Rust和 TypeScript 中有不错的支持,在 Java 或 Go 中还没有直接的支持。然而即便是 TypeScript,很多类型声明也得在 GraphQL 和 TypeScript 中分别定义一份。
此外,GraphQL 的 Client-side 类型问题也是一个挑战。由于 GraphQL 服务的返回值取决于发送过来的查询语句,因此其响应的数据类型不是固定的,而是随着查询语句代码的修改而变化的。
尽管 GraphQL 由于提供了内省机制(Introspection),可以构建出专门根据 GraphQL Schema + GraphQL Query 生成 TypeScript 类型定义的 Code Generator 工具。但其中包含很多手动处理或复杂的工程化配置环节。
开发者有可能需要手动从 TypeScript 代码里复制出 GraphQL Query 语句,在 GraphQL Code Generator 工具里生成 TypeScript 类型后,复制该类型定义到项目中,然后传入 GraphQL Client 调用函数标记其返回值类型。
或者像 Facebook/Meta 公司推出的 Relay 框架那样,实现一个 Compiler 去扫描代码里的 GraphQL Query 语句,自动生成类型到指定目录,让开发者可以直接使用。这块对研发团队的技术能力和工程化水平有较高要求。
GraphQL-BFF 的第二个难题是,缺乏 Streaming 优化支持。当前的 GraphQL 数据响应,是由查询语句中最慢的节点决定的,尚未支持已 resolved 的节点提前返回给调用端消费的能力。
虽然 GraphQL 有 @stream/@defer 相关的 RFC,但目前并未进入 GraphQL 规范中,也未在相关 GraphQL 库中得到实现或推广。
GraphQL-BFF 的第三个难题是缺少 Client-side Data-Loader 优化支持。
在 Server-side 的GraphQL 有相关 Data-Loader,支持在一次查询请求处理过程中,相同资源的访问可以被去重。但是在调用端,一次 GraphQL Query 就对应着一次 Http 请求与响应。多次 GraphQL Query 很难被自动 merge 和 batching,遑论 streaming 优化。
如前所述,为了渲染上的进一步优化,前端组件实践的流行趋势是,每个组件可以将自己的数据需求定义在自己的组件代码中,而非托管给父级组件。如此,可以方便组件自身做 streaming 优化;当它自身的数据已经获取完毕,它可以先行渲染,不必等待。
相关 GraphQL Client(如Relay)的处理办法是,让视图组件用 GraphQL Fragment 而非 GraphQL Query 去表达数据需求。通过编译器处理后,它们将可以提取到父级组件或者根组件里合并为 GraphQL Query。实现编写时在组件内,运行时托管在父级组件中获取数据。
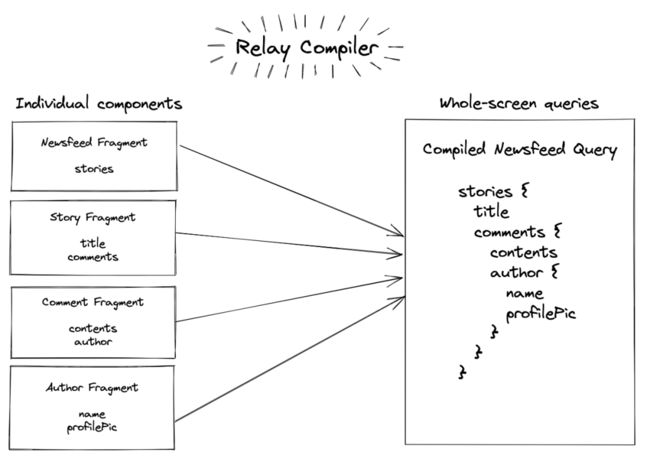
这种策略在实践上是可行的,然而既有较高的工程化门槛,难以普遍推广,又不是 GraphQL 规范所定义的标准行为,甚至需要额外自定义很多指令以达到目标(如 Relay 框架的 @argument, @argumentDefinitions 等),这进一步损害了它的易用性。
我们需要的一种 BFF 技术方案是:
支持使用标准的语言特性解决问题
BFF 实现端类型定义不必编写两份
BFF 调用端可无缝复用 BFF 实现端的定义,不必重复定义
支持 Client-side Data-Loader 机制,可以将客户端的多个数据访问调用自动
merging
batching
streaming
RPC-BFF 技术方案,可以满足上述目标。
五、RPC-BFF 的技术选型
基于 RPC 实现 BFF 的思路和方案,也有很多种选择。
5.1 gRPC
gRPC 是一个非常优秀的 RPC 技术方案,但它跟 GraphQL 一样是跨编程语言的,需要额外使用一种 DSL 定义类型(Interface Definition Language,IDL),因此有类似的重复定义类型的问题,也未对前端常用语言(如TypeScript)做充分的针对性优化,并且它主要服务于分布式系统这类 server-to-server 的调用,对 client/ui-to-server 的 BFF 场景没有特殊处理。
在很多基于 gRPC 的 BFF 实践中,BFF 跟背后的领域服务之间是 RPC 模式,BFF 跟前端之间则回到 RESTful API 模式。而我们所谓的 RPC-BFF,其实是指前端和 BFF 之间是 RPC 模式的调用关系。
5.2 tRPC
tRPC 的设计目的则跟我们的目标更加贴合,它是基于 TypeScript 实现的端到端类型安全方案(End-to-end type-safe APIs)。
然而,tRPC 的技术实现方式,跟我们的需求场景却不契合。
tRPC 跟前文的 Relay 框架某种意义上是两个极端。Relay 框架完全依赖它的 Relay Compiler 去扫描代码,充分分析和收集代码里的 GraphQL 配置,有很多编译、构建和代码生成的环节。而 tRPC 则相反,它目前没有构建、编译和代码生成的步骤,正如其官方文档里所言:
tRPC has no build or compile steps, meaning no code generation, runtime bloat or build step.
tRPC 假设了开发者的项目是全栈项目(full-stack application),或者前后端代码都在一个仓库。
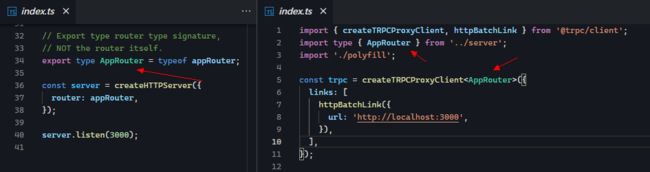
因此,前端项目可以直接 import 后端项目里的 TypeScript 类型。
如果我们构建的 BFF 项目,不只为了一个前端项目服务,而是多个前端项目共用的,涉及跨端、跨语言、跨团队等复杂组合。使用 tRPC 时,可能就得采取 Monorepo 模式,把 BFF 项目及其所有调用方的代码项目,放到一个 Git 仓库中管理。这将显著地增加多个团队之间的 Git 工作流、CI/CD、研发和部署流程等多方面的协调问题,要求处理新的工程化复杂度(Monorepo),能满足这个条件的团队不多。
我们的场景所期望的技术方案是,允许 BFF 项目及各个下游前端项目在不同仓库中管理,它们无法直接 import BFF 项目的类型,不满足 tRPC 的项目假设。
5.3 DeepKit
DeepKit 是一个富有野心的项目,它在 TypeScript 基础上增加了很多特性,力图打造一个更加完备的 TypeScript 后端基础设施。

它也有 RPC 模块的部分,但出于以下几个原因,最后未被我们选择。
第一个原因是,DeepKit 的 RPC 实践方式跟 tRPC 有类似的项目结构假设。
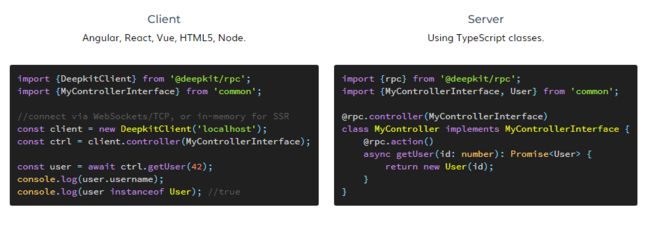
如上所示,rpc server 和 rpc client 之间需要有个共享的接口,一个负责实现该接口,一个负责消费该接口。这也要求前后端需要放到一个仓库中。或者采用 npm 包这类更低效的代码共享途径,对库和框架这种变动比较不频繁的场景来说是合适的,对业务迭代这种更新频率则难以接受。
另一个原因则是,选择 DeepKit 并不是选择一个库或者框架这种小决策,它从编程语言开始侵入,然后到运行时以及库和框架等方方面面。有较强的 Vendor lock-in 风险,一个项目要从 DeepKit 中迁移到另一个技术相当困难。
团队需要下很大的决心才敢押注 DeepKit 选型,以 DeepKit 目前的完成度和流行度,还无法支撑我们做出这个决定。
5.4 自研 RPC-BFF
如前所述,我们深入分析了 RPC BFF 的优势,以及考察了多个不同的技术选型。有的过于庞大、过分复杂,有的则过于简单、过于局限。
但这些项目也启发了我们的自研方向,帮助我们从简单到复杂的光谱中,根据自身实际需求找到一个平衡点,可以用尽可能低的研发成本、尽可能小的侵入性、尽可能少的项目结构要求,实现 RPC-BFF 模式。
也就是说,我们既不要像 DeepKit 和 Relay 那样,从完整的编译器乃至编程语言层面切入到代码生成和运行时,它们或许有更大的目标和野心,配得上如此高昂的技术成本和实现难度,但对纯粹的 BFF 场景而言可能过犹不及。同时也不要像 tRPC 那样完全没有代码生成,而是选择一个最小化代码生成的路线,满足 RPC-BFF 这一聚焦场景的需求。
六、自研 RPC-BFF 的设计与实现
6.1 RPC-BFF 的设计思路
RPC-BFF 可以看作朴素 BFF 的拓展增强版。在朴素 BFF 中,后端在最简陋的情况下只为前端提供了数据。
而 RPC-BFF 则需要做更多:提供数据、提供类型以及提供代码。

如上图所示,RPC-BFF 既是数据提供者(Data Provider),也是类型提供者(Type Provider),还是代码提供者(Code Provider)。前端不必重复定义 BFF 响应的数据类型,也不必亲自构造 Http 请求处理通讯问题。
要做到这些功能,同时又不能损害易用性,需要极致地挖掘 TypeScript 的类型表达能力。

上图为 RPC-BFF 架构图示意,其中存在四种颜色,分别的含义如下:
服务端运行时(server-runtime)为粉色,服务器代码在此运行
类型编译时(compile-time)为蓝色,类型检查在此进行
CLI 运行时(cli-runtime)为黄色,本地开发阶段使用的命令行工具
客户端运行时(client-runtime)为紫色,前端代码在此运行
该 RPC-BFF 架构设计的核心在于Schema 部分,它是一切的基础。我们可以看到,Schema 有两条箭头,一条为 type infer,一条为 to JSON。也就是说,Schema 既作用于类型(type)所在的编译时(compile-time),也作用于值(value)所在的运行时(runtime)。
当 BFF 端的代码经过编译,类型信息被编译器抹除后,我们仍可以在运行时访问到 JSON 数据结构表示的 Schema。
通过这种机制,我们的 RPC-BFF 像 GraphQL 那样支持内省特性(introspection)。在开发阶段,前端可以通过本地 CLI 工具向 RPC-BFF 发起内省请求(Introspection Request)拿到 JSON 形式的 Schema 结构,然后通过 Code Generator 生成前端所需的 Client 类型和 Client 代码。
如此,我们既不需要用编译器去扫描和分析服务端代码以提取类型,也不需要用编译器去扫描和分析前端代码去生成类型。对于 RPC-BFF 来说,不需要掌握到图灵完备的编程语言的所有信息才能工作,只需要掌握RPC 函数列表及其输入和输入类型结构即可。
6.2 RPC-BFF Schema 设计与实现
Schema 是一段特殊的代码,它介于 Type 和 Program 之间,面向特定领域保留其所需的元数据性质的配置结构。Schema 往往比类型复杂,但比一般意义上的程序简单。
不管是 tRPC 还是 GraphQL 都包含 Schema 性质的要素。然而,对于 RPC-BFF 的场景来说,它们分别都有能力的缺失。
tRPC 中的 Schema 是只起到了 Validator 和 Type-infer 的作用,而没有 Introspection 机制。

如上所示,tRPC 自身没有实现 schema 部分,但可以从开源社区的多个 schema-based validator 库中选择一个它目前支持的(如 zod),从而得到在 server runtime 对客户端传递进来的参数验证,以及在开发阶段提供 type-infer 功能。
而 GraphQL 的情况则复杂一些,它分为 Schema-first 和 Code-first 两类实践方式。
Schema-first GraphQL 实践如上图所示,GraphQL Schema 以字符串的形式出现在 TypeScript/JavaScript 代码中,它是 DSL 形态,要复用 host language(如 TypeScript)的类型系统相当困难。

Code-first/Code-only GraphQL 则如上图所示,它是 eDSL 形态,即嵌入式领域特定语言(Embedded domain specific language),它可以基于 host language 的API 以程序的方式而非字符串的方式,创建出 GraphQL Schema。因此,这种模式下 GraphQL 相当于嵌入到 TypeScript 中,它有机会利用 TypeScript 的类型推导(type infer)能力,反推出 TypeScript 类型;也能够在运行时 stringify 为 DSL 形态的 GraphQL Schema。
可以说,这种实践方式的 GraphQL 跟 host language 的整合度更高,某种程度上是更灵活的,尽管牺牲了 DSL 那种直观性。
然而,目前几乎所有 Code-first/Code-only 的 GraphQL 库的 TypeScript 类型支持程度都有很大的不足。特别是对 GraphQL 这种类型之间递归结构特别频繁的技术来说,其类型推导的技术挑战远大于zod 等朴素 schema-based validator 库。
即便是 zod 这类更简单的场景,对递归类型也没有充分支持。
You can define a recursive schema in Zod, but because of a limitation of TypeScript, their type can't be statically inferred. Instead you'll need to define the type definition manually, and provide it to Zod as a "type hint".
如 zod 官方文档所述,当我们的 schema 中存在递归,type-infer 就受到了限制,需要更繁琐的方式去自行拼装出递归类型。
const baseCategorySchema = z.object({
name: z.string(),
});
type Category = z.infer & {
subcategories: Category[];
};
const categorySchema: z.ZodType = baseCategorySchema.extend({
subcategories: z.lazy(() =>categorySchema.array()),
}) 如上所示,它需要先用 schema 方式定义递归类型(Category)中非递归的部分,然后用 type-infer 在 type-level 定义递归部分的类型,最后回到 schema-level 中显式类型标注,定义递归 schema。
它在 schema-level 和 type-level 中来回穿梭。每一个递归字段都要求拆成上述 3 个部分,其工程上的易用性缺乏保障,其代码也缺乏可读性。有多少读者能轻易看出上面的复杂 schema 是为了定义下面这几行代码?
type Category = {
name: string
subcategories: Category[]
}回到 GraphQL,我们现在能够看到,它在 Validator 和 Introspection 特性上有良好的支持,可以在 server runtime 验证参数结构和返回值,也可以通过内省请求曝露出schema 结构,但在 type-infer 上仍有一些难以攻克的挑战存在。
RPC-BFF 的 Schema 需要同时满足 Validator,Type-infer 和 Introspection 三个能力,现有方案并不满足,因此我们通过自研 Schema方案实现了它们。
下面是一段定义 User 类型的TypeScript 代码:
type UserType = {
id: string;
name: string;
age: number;
}
const user: UserType = {
id: 'user_id_01',
name: 'Jade',
age: 18
}经过编译后,在运行时执行的 JavaScript 代码如下:
"use strict";
const user = {
id: 'user_id_01',
name: 'Jade',
age: 18
};类型信息被抹去,在运行时无法获取。通过 RPC-BFF Schema 重新定义 User 结构如下:
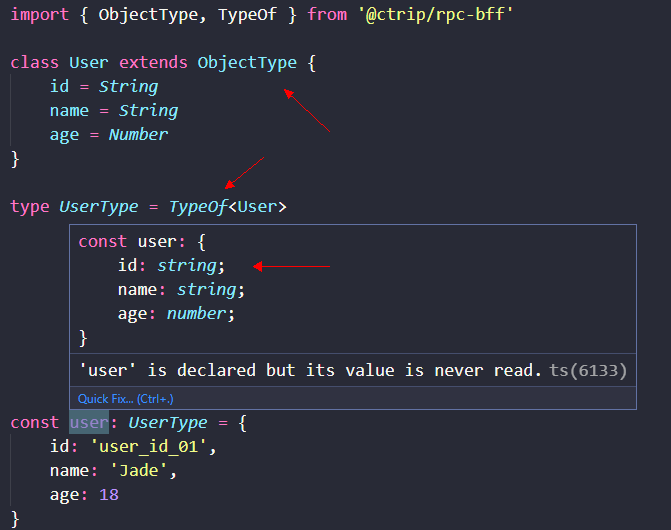
我们用 ObjectType 定义了User Schema,用 TypeOf 推导出UserType,经过 TypeScript 编译后,JavaScript 代码如下所示:
import { ObjectType } from '@ctrip/rpc-bff';
class User extends ObjectType {
constructor() {
super(...arguments);
this.id = String;
this.name = String;
this.age = Number;
}
}
const user = {
id: 'user_id_01',
name: 'Jade',
age: 18
};我们可以看到,由 ObjectType 定义的 User Schema 在运行时也得到了保留,因此我们可以基于这些信息,实现在运行时的 Validation 和 Introspection 功能。
此外,我们的 RPC-BFF Schema 技术还克服了 zod 等库未能解决的递归类型定义问题:

我们无需为了支持递归而人为拆分类型,可以直观地定义出上述的 Category 结构,并支持静态类型推导。其秘诀在于利用 TypeScript 中 class 声明具备的独特性质—— value & type 二象性。
当我们用 class 声明一个结构时,它同时也定义了:
Constructor 函数值
Instance Type 实例类型

如上图所示,左边箭头的 Test 是一个实例类型(Instance Type),右边箭头的则是类的构造器函数(Constructor)。
目前就我们所知,只在 class 声明场景下 TypeScript 对递归 Schema 有良好的类型推导支持。因此,如果 zod 或者 Code-first GraphQL 库想要支持递归 Schema 结构,它们的 Schema API 可能需要大改,变成我们上面演示的 RPC-BFF Schema 的 API 风格。
尽管我们掌握了在 Validator, Type-infer 和 Introspection 能力上更完备的 Schema 技术,满足了 Code-first GraphQL 的技术要求,但也仅限于 server 端的情况,在 client 端的类型,仍需要引入复杂的编译技术扫描前端代码库里的 GraphQL Query 片段以生成类型。这不是我们期望的。
因此,我们目前先将这种技术应用于更简单的 RPC-BFF 场景,未来也不排除支持 GraphQL。
6.3 定义 RPC-BFF 函数
有了 RPC-BFF Schema 之后,我们就可以用它来定义 RPC-BFF 函数了。
在纯 TypeScript 的代码里,定义函数的 input 和 output 是这样的:
// 定义 input
type HelloInput = {
name: string
}
// 定义 output
type HelloOutput = {
message: string
}
type HelloFunction = (input: HelloInput) => HelloOutput然后实现满足该函数类型的代码:
const hello: HelloFunction = ({ name })=> {
return {
message: `Hello ${name}!`,
}
}在 RPC-BFF 里,我们只是换了一种方式去定义 input 和 output。
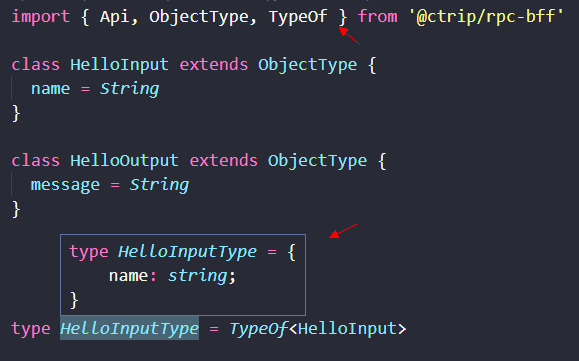
去掉注释,并且引入 ObjectType,前面的 hello 函数就变成了这样:
import { Api, ObjectType } from '@ctrip/rpc-bff'
class HelloInput extends ObjectType {
name = String
}
class HelloOutput extends ObjectType {
message = String
}
export const hello = Api(
{
input: HelloInput,
output: HelloOutput,
},
async ({ name }) => {
return {
message: `Hello ${name}!`,
}
},
)可以看到,它跟我们纯 TypeScript 的结构几乎是一样的。
6.4 RPC 函数和普通函数的区别
RPC 函数和普通函数的区别在于,RPC函数的 input 和 output 都是 value,而普通函数的 input 和 output 都是 type。
type 会在编译时被擦除,而value 会在运行时被保留。所以,RPC 函数的 input和 output 需要是 value,它们在运行时是可以被访问到的。这样可以为 RPC-BFF client 生成类型代码和调用代码。
尽管我们使用 value 的方式去定义RPC 函数的输入和输出,但通过 TypeScript 提供的type infer 能力,我们不必为 RPC 函数的实现重新写一次类型定义,而是可以使用 TypeScript 的类型推导能力,让 TypeScript 自动推导出 RPC 函数的输入和输出类型。
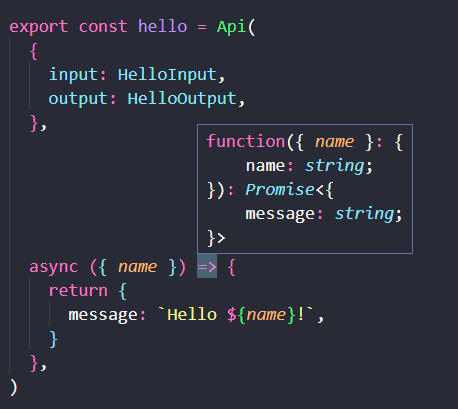
可以看到,我们的 hello 函数实现是有类型的。不仅如此,我们还可以通过 TypeOf 获取到 Schema API 定义出来的结构。
通过这种方式,我们实现了 RPC 函数的输入和输出结构,具备以下能力:
可以在运行时保留,用以生成代码或者生成文档
可以在编译时被隐式地推导出来,用以做类型检查
可以通过 TypeOf 工具类型显式地获取到,用以做类型标记
现在,让我们把 RPC-BFF 函数放到 RPC-BFF App 中:
import { createApp } from '@ctrip/rpc-bff'
import { hello } from './api/hello'
export const app = createApp({
entries: {
hello,
}
})createApp 将创建一个 RPC-BFF App,其中 options.entries 字段就是我们想要曝露给前端调用的 RPC-BFF 函数列表。
启动后,一个 RPC-BFF Server 就运行起来了。
6.5 RPC-BFF 的 Client
在前端项目的开发阶段,它将会新增 rpc.config.js 配置脚本。
rpc.config.js
const { createRpcBffConfig } = require('@ctrip/rpc-bff-cli')
module.exports = createRpcBffConfig({
client: {
rootDir: './__generated__/',
list: [
{
src: 'http://localhost:3001/rpc_bff',
dist: 'my-bff-client.ts',
}
]
}
})如上所示,当该脚本被 rpc-bff-cli 运行时,它会向 src 发起 introspection request 并生成代码到指定目录下的指定文件(如 my-bff-client.ts)。
就我们前面所演示的 hello 函数来说,其生成的代码大概如下所示:
./__generated__/my-bff-client.ts
/**
* This file is auto generated by rpc-bff-client
* Please do not modify this file manually
*/
import { createRpcBffLoader } from '@ctrip/rpc-bff-client'
export type JsonType =
| number
| string
| boolean
| null
| undefined
| JsonType[]
| { toJSON(): string }
| { [key: string]: JsonType }
/**
* @label HelloInput
*/
export type HelloInput = {
name: string
}
/**
* @label HelloOutput
*/
export type HelloOutput = {
message: string
}
export type ApiClientLoaderInput = {
path: string[]
input: JsonType
}
declare global {
interface ApiClientLoaderOptions {}
}
export type ApiClientOptions = {
loader: (input: ApiClientLoaderInput,
options?: ApiClientLoaderOptions) => Promise
}
export const createApiClient = (options: ApiClientOptions) => {
return {
hello: (input: HelloInput,
loaderOptions?: ApiClientLoaderOptions) => {
return options.loader(
{
path: ['hello'],
input: input as JsonType,
},
loaderOptions
) as Promise
}
}
}
export const loader = createRpcBffLoader("http://localhost:3001/rpc_bff")
export default createApiClient({ loader }) 我们可以看到,RPC-BFF 的代码生成结果主要包含三个部分:
RPC-BFF Server 里的 Schema 变成了前端里的 Type,将在编译后被擦除,不会增加前端代码体积
RPC-BFF Server 里的 entries 变成了 createApiClient 函数,包含了跟 BFF 端对齐的函数调用列表及其类型信息
RPC-BFF Client 被引入和实例化,它将在前端的运行时接管 RPC 函数的前后端通讯过程,对前端调用者无感
通过 Introspection + Code-generator 途径,一个 RPC-BFF 服务不必跟它的下游前端项目绑定,而是每个前端项目通过 rpc.config.js 各自同步它们所需的 RPC-BFF 服务。如此解耦了前后端的项目依赖,同时这个模式在 Monorepo 项目中也能很好地工作,是一种更加灵活的方式。
七、RPC-BFF 特性概览
至此,我们了解到了 RPC-BFF 的后端和前端分别的开发方式,可以看到对于 RPC-BFF 服务的开发者来说,并没有引入复杂的 API 或者概念,仅仅是在编写朴素函数的心智模型的基础上,将定义函数输入和输出结构的方式,从朴素的 Type 换成了 RPC-BFF Schema。
对于 RPC-BFF 服务的调用方而言,只是增加了 rpc.config.js 配置脚本,在开发阶段就能得到 RPC-BFF 的类型及其 Client 封装,用极小的成本获得极大便利。
但这仍不是 RPC-BFF 的优势的全部,接下来,我们来了解一下 RPC-BFF 的几大特性。
7.1 端到端类型安全的函数调用
端到端类型安全(End to end type-safety)的函数调用是 RPC-BFF 的基本功能,前端通过生成的 RPC-BFF Client 模块访问 RPC-BFF Server 时,像调用本地异步函数一样。

如上所示,BFF 后端和前端的类型对齐。前端不必关心底层 HTTP 通讯细节,可以聚焦 RPC 函数的 input 和 output 结构。
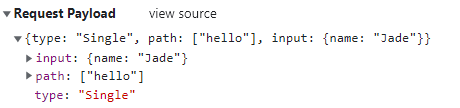
当 RPC 函数执行时,它将发起 HTTP 请求,将所调用的 RPC 函数的路径(path)和输入(input)等信息打包发送给 RPC-BFF Server。

RPC-BFF Server 接受到 RPC 函数调用请求后,将匹配出指定函数并以 input 参数调用它得到其 output 结果后发送给前端,前端收到响应结果后,RPC-BFF Client 将其转换为前端 RPC 调用函数的返回值。整个 RPC 过程的前后端流程就完成了。
7.2 直观的错误处理
前面介绍的 RPC 调用只涉及请求正确处理和返回的情况,如果服务端报错了,前端如何处理呢?
对于这个问题,RPC-BFF 也有其优势。不同于朴素的接口请求错误处理,需要去判断 HTTP Status Code 检查请求状态码是否正确,甚至还得判断 result.code 检查业务状态码是否正确等等。
RPC-BFF 的错误处理支持最直观和自然的 throw 和 try-catch 特性。在 RPC-BFF Client 中可以 catch 到 RPC-BFF Server 里 throw 的错误。
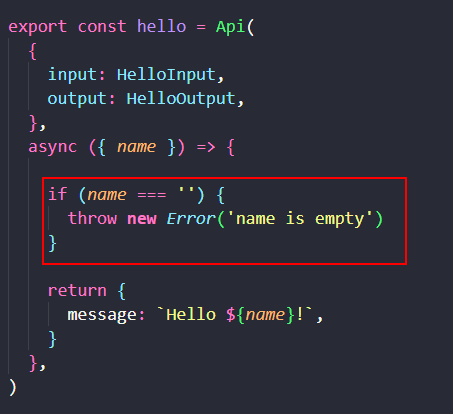
如上,改造我们的 hello 函数,当它遇到空的 name 参数时 throw 指定错误。

前端则构造一个空的 name 参数,并 try-catch 此次 RPC 调用,它将能捕获服务端抛出的错误。
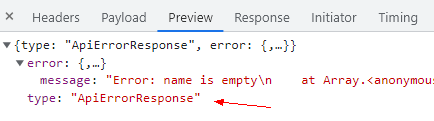
再次执行后,从 Chrome Devtools 的 Network 面板中,我们看到了标记为错误的 RPC 响应结果。

在 Console 面板中,我们则看到了前端 catch 到的 RPC 调用错误日志输出。
7.3 代码即文档
RPC-BFF 从 GraphQL-BFF 中学习到了很多优秀之处。在 GraphQL 中,可以基于其 Schema 的 Introspection 能力,构建 GraphQL Playground 平台,可以在其中查看接口的参数类型、字段描述等信息,还能发起查询,相当方便。
RPC-BFF 的 Schema 也拥有 Introspection 能力,因此我们可以为前端提供更多内容。
export class Todo extends ObjectType {
id = {
description: `Todo id`,
[Type]: Int,
}
content = {
description: 'Todo content',
[Type]: String,
}
completed = {
description: 'Todo status',
[Type]: Boolean,
}
}
export class AddTodoInput extends ObjectType {
content = {
description: 'a content of todo for creating',
[Type]: String,
}
}
export class AddTodoOutput extends ObjectType {
todos = {
description: 'Todo list',
[Type]: TodoList,
}
}
export const addTodo = Api(
{
description: 'add todo',
input: AddTodoInput,
output: AddTodoOutput,
},
(input) => {
state.todos.push({
id: state.uid++,
content: input.content,
completed: false,
})
return {
todos: state.todos,
}
},
)如上所示,我们在定义 addTodo 接口的 input schema 和 output schema 时,不仅仅提供了对应的类型,还添加了相关的 description 描述。
经过前端的代码生成后,将得到如下代码:
/**
* @label Todo
*/
export type Todo = {
/**
* @remarks Todo id
*/
id: number,
/**
* @remarks Todo content
*/
content: string,
/**
* @remarks Todo status
*/
completed: boolean
}
/**
* @label AddTodoInput
*/
export type AddTodoInput = {
/**
* @remarks a content of todo for creating
*/
content: string
}
/**
* @label AddTodoOutput
*/
export type AddTodoOutput = {
/**
* @remarks Todo list
*/
todos: (Todo)[]
}
export const createApiClient = (options: ApiClientOptions) => {
return {
/**
* @remarks add todo
*/
addTodo: (input: AddTodoInput, loaderOptions?: ApiClientLoaderOptions) => {
return options.loader(
{
path: ['addTodo'],
input: input as JsonType,
},
loaderOptions
) as Promise
},
}
} 相比文本形式的接口契约文档,RPC-BFF 通过注释的方式将接口描述信息呈现出来。
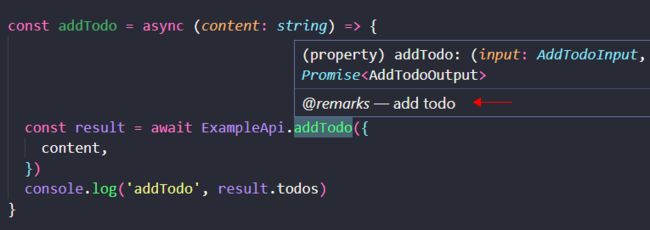
如上所示,生成到注释的方式,比朴素的接口契约更贴近开发者,可以在代码编辑器里直观地看到接口描述和类型描述,并且基于开发阶段的同步机制,它总是实时反映当前 RPC-BFF 的最新状态,避免了接口文档过时的问题。
当我们想要废弃一个 RPC 函数时,这项机制尤为重要。
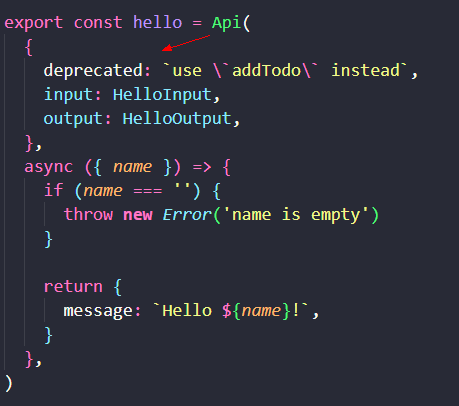
如上,我们通过添加 RPC 函数的 deprecated 描述,宣布废弃。

前端经过代码生成同步到 RPC-BFF 最新状态时,将能在代码编辑器里直观地看到废弃的提示信息。如此可以实现流畅的前后端接口废弃过程。
7.4 自由的函数组合
在 RPC-BFF 中,RPC 函数跟普通函数本质上是一样的,只是它通过 Schema 定义额外携带了描述自身的元数据信息。我们可以像组合普通函数一样,组合 RPC 函数。
假设我们有 updateTodo 和 removeTodo 两个 RPC 函数,然后我们希望添加一个功能:当 updateTodo 收到的 todo.content 为空时,则 remove 该 todo。
那么,我们不必把 removeTodo 功能分别在 updateTodo 和 removeTodo 中各自实现一遍,而是在 updateTodo 中根据条件调用 removeTodo。

如上所示,在 updateTodo 中调用 removeTodo 并没有特殊的要求,就像调用别的异步函数一样简单,并且对于前端发起的 updateTodo RPC 调用也没有额外开销,仍是一次对 updateTodo 的远程函数调用。
7.5 可靠的接口兼容性识别与版本跟踪
由于 RPC-BFF 的调用方在自己的前端项目中,通过 rpc.config.js 同步了 RPC-BFF 当前的接口的类型,因此它还解决了前后端之间常常遇到的接口兼容性争议。
在以往朴素的实践中,接口兼容往往只是后端对前端的口头承诺,缺乏自动化的、系统化的方式去发现和识别接口兼容性,甚至往往将问题暴露在生产环境。然后前后端开始争执判空职责的前后端边界划分问题。
而现在,RPC-BFF 提供了自动发现接口兼容性机制,并且是以系统性的、无争议的方式实现的。
export class AddTodoOutput extends ObjectType {
todos = {
description: 'Todo list',
[Type]: Nullable(TodoList),
}
}如上,当后端的 addTodo 接口改变了返回值类型,从非空的 todos 变成可空的 todos,这是一种不兼容的变更。
前端同步 RPC-BFF 的接口契约后,在代码编辑器里立即可以看到类型系统的 type-check 结果。

在不解决这个类型问题的情况下,前端项目难以通过编译,从而避免将问题泄露到生产环境。

此外,RPC-BFF 生成的代码也进入了前端项目的版本管理中,可以从 git diff 中,清晰地看到每一次迭代的接口契约变更记录。更完整无误地追溯和跟踪前后端的接口契约历史。
7.6 自动 merge & batch & stream 优化
如前文所描述的,RPC-BFF 需要支持自动的 merge & batch & stream 功能,以便达到更少的 HTTP 请求、更快的数据响应以及更优的 SSR 支持。
我们先来讲解一下它们分别的含义。
首先讲 batch,它是一种常见的优化技术,可以把一组数据请求合并为一次,往往用在相同资源的批量化请求上。这需要服务端接口提供支持,比如 getUser 接口是获取单个用户信息的,而 getUsers 则是获取多个的,后者可以被视为 batch 接口。
而 merge 在这里则偏向前端概念,接口支持 batch 只是说我们可以调用一个 batch 接口获取更多数据,但不意味着前端代码里多个地方调用 getUser 接口,会自动 merge 到一起去调用 getUsers 接口。
merge & batch 结合起来,就可以让前端里分散的各个调用自动合并到一次 batch 接口的请求中。
现在我们来看 stream,它跟 batch 一样需要服务端的支持。一次 batch 接口请求的响应时间,往往取决于最慢的数据,因为服务端需要准备好所有数据后才能返回 JSON 结果;所谓的 stream 支持,则是服务端能够提前将已获得的数据一份份发送给前端。
某种意义上,stream 也需要前端的支持。假设接口支持 stream 可以一批批返回数据,前端却一个 await 等待所有数据就位后才开始下一步,那么等于没有发挥出接口流式响应的优势。
因此,merge & batch & stream 三者的结合才能发挥出更充分的优化效果。
通过 merge,前端代码里各个地方的接口调用被 batch 起来
通过 batch & stream 接口,一份份数据从服务端发送给前端
通过 RPC-BFF Client 内部数据分发,指定的数据被一份份地发送到各个前端调用点
每个前端调用点收到数据响应后都将第一时间进入后续的渲染流程,不会受到其它调用点的阻塞影响。
我们来看一个例子:
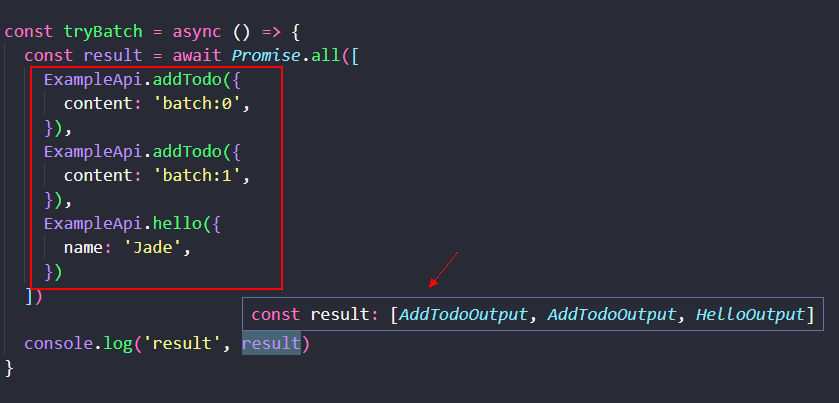
如上,为了演示方便,我用 Promise.all 将 3 次 RPC 函数调用的结果打包到一起返回,但我们仍需知道,它们其实是三个独立的 RPC 调用,被写到一起还是分散在其它地方调用,不影响结果。Promise.all 只是在前端汇总 promises 结果,不包含接口相关的 merge & batch & stream 等作用。
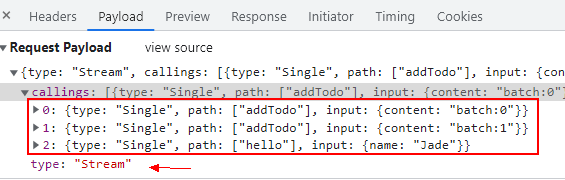
从 Network Request 面板中,我们看到了一个被标记为 Stream 的请求,它里面包含了上面 3 个 RPC 调用的所有信息。

在 Network Response 面板中,我们则看到了一个 Newline delimited JSON 响应,即用换行符分隔的streaming JSON 格式。每一个被 batch & stream 起来的 RPC 函数调用返回数据后,都将立即产生一条 JSON 结果发送给前端,每一行对应一次 RPC 调用。
7.7 自动缓存和去重
除了 merge & batch & stream 以外,自动的缓存和去重(cache & dedup)对于渲染优化也很重要。
在前端界面中,两个组件依赖同一份接口数据的情况很常见。传统方式是,手动去重,即两个组件都不包含接口调用,而是 lift up 到公共的祖先级组件统一处理后通过 props/context 等方式将同一份数据传送给这两个组件。
这种方式的缺点是:
两个组件都无法被独立使用和复用,因为它们的数据请求逻辑都被挪出去了,内聚性被打破
组件优化不足。只有枝叶组件各自发起请求时,Streaming 渲染得到了更优条件。越是顶层的组件里悬停,子组件渲染越是受到阻塞
这就是为什么 React 目前致力于接管 data-fetching 层,让开发者手动去管理缺少将系统性优化。
对于 RPC-BFF 而言,支持 cache & dedup 变得重要。
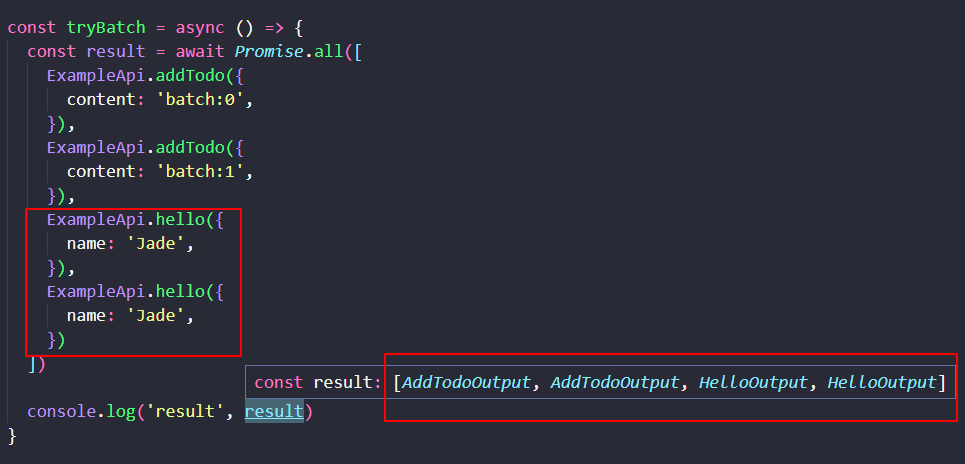
改造前面的 tryBatch 代码,使其包含 4 次 RPC 调用,有 4 个返回值,但有 2 次的参数和函数名是重复的。
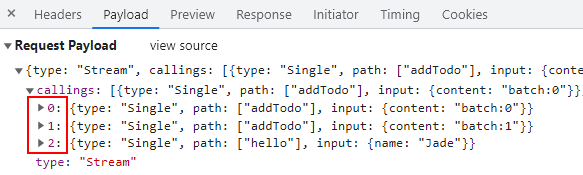
但我们的请求却只包含了 3 次 RPC调用及其响应,其中 2 次的重复调用被合并为一次。
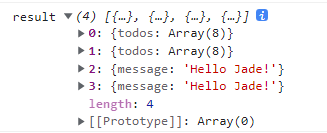
但并不影响每个 RPC 调用拿到它对应的 4 个调用结果。
通过这种 cache & dedup 机制,每个组件的数据请求都可以内聚于组件代码内部,而不必被迫 lift up 到父级组件做请求托管了。
值得提醒的是,不是所有相同参数的 RPC 调用都能被缓存和去重。特别是对于 mutation 性质的请求来说,连续调用两次相同参数的 createTodo,应当是创建两条而非一条。
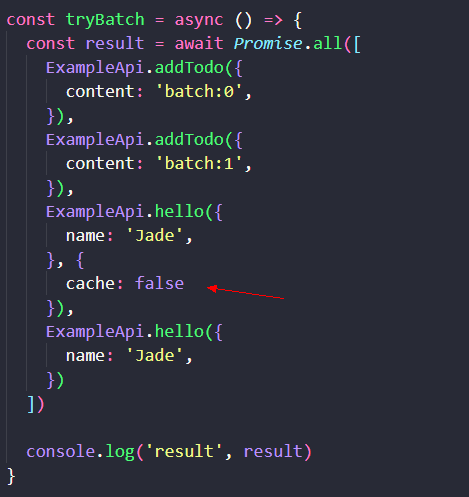
因此,RPC-BFF 支持在前端传递第二个 options 参数给 RPC 函数,可以关闭 cache 特性。
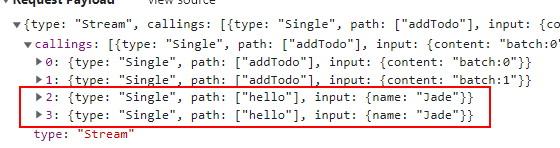
如上图所示,关闭 cache 后,即便是相同的 RPC 调用,也不会被缓存和去重。
options 选项,不仅可以关闭 cache,还可以关闭 batch, stream 等特性。
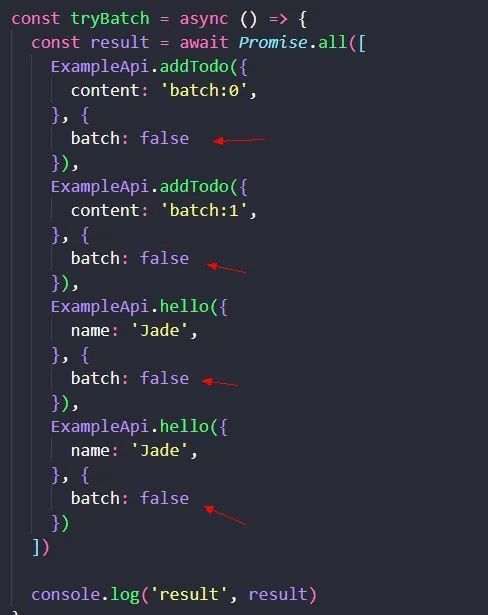
如上所示,options.batch 是 cache 和 stream 的前提,我们将所有 RPC 调用的 batch 选项都关闭。
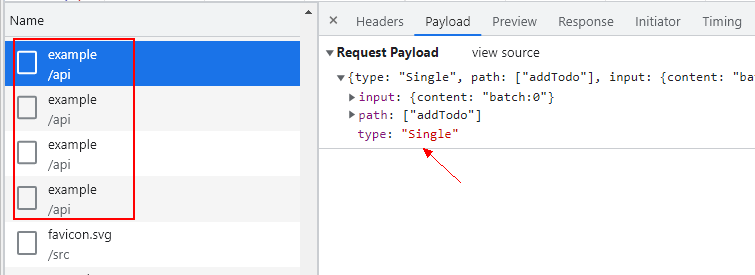
其结果是所有 RPC 函数调用退化为朴素形态,每一个 RPC 调用对应独立的一次 HTTP 请求。
通过灵活的选项配置,我们可以按需决定 RPC-BFF 里的函数调用的优化策略。
八、总结
在这篇文章中,我们介绍了 BFF 的起源、模式和技术选型,并根据界面渲染优化需求,了解到 Streaming BFF 的重要性,同时也给出了我们当前探索的技术方向——RPC-BFF。
我们对比了开源社区的一些流行方案,并根据我们自身的场景做了分析,尽管最终采用了自研的方式,但在调研和实验开源技术的过程中,也让我们学习到了很多知识,使得 RPC-BFF 的设计和实现能够吸收开源社区的技术成果。
我们最终达到了预期的技术目标,实现了:
Validation: BFF 端可以在运行时验证参数结构和返回值结构的合法性
Type-infer: 支持从 Schema 中静态类型推导出 TypeScript 类型,避免重复定义
Introspection: RPC-BFF 服务可以通过内省请求曝露出其函数列表的契约结构
Code-generation: 支持为调用方生成类型代码和调用代码,解耦项目依赖
Merge: 前端多次 RPC 调用可以自动合并为一次 HTTP 请求
Batch: 一次 HTTP 请求支持包含多个 RPC 调用
Stream: 多个 RPC 调用可以流式响应,一份份发给前端,避免阻塞
Dedup: 重复的 RPC 调用可以被去重合并
Cache: 重复的 RPC 调用可复用缓存结果
Type-safe: 前端可复用和对齐 BFF 端的类型
Code as documentation: 代码即文档,RPC 接口的文档描述通过代码生成,以代码注释的形态直接作用于前端项目中
目前我们的 RPC-BFF 技术方案已经在内部试点项目中落地并上线平稳运行,接下来将会推广和迭代,并持续挖掘 RPC-BFF 技术方向上的优化潜力。
以上,希望能给大家带来帮助。
【推荐阅读】
携程Web组件在跨端场景的实践
携程商旅大前端 React Streaming 的探索之路
携程火车票7个优化动画性能的方法
携程小程序内嵌webview实践指南

“携程技术”公众号
分享,交流,成长