
在前面一篇「Python 爬虫第一篇(urllib+regex)」 我们使用正则表达式来实现了网页输入的提取,但是网页内容的提取使用正则是比较麻烦的,今天介绍一种更简便的方法,那就是使用 BeautifulSoup 网页解析库来实现同样的功能。BeautifulSoup 的安装和用法可以参考「Python 爬虫之网页解析库 BeautifulSoup」这篇文章。
在上一篇中我们获取并解析了立创商城上的原件采购数量对应的价格,我们将整个解析过程分成了三个部分。第一步,解析出所有的采购数量所对应的价格;第二步,解析出一行中采购的数量;第三步,解析出一行中数量对应的价格信息。今天将使用正则表达式实现的解析代码更换成 BeautifulSoup。
- 解析出所有的数量对应的价格组
使用正则表达式的实现如下:
res_tr = r'(.*?) '
m_tr = re.findall(res_tr, html_text, re.S)
更换为 BeautifulSoup 后实现如下:
soup.find_all('tr', class_='sample_list_tr')
- 解析出一行中的采购数量
使用正则表达式的实现如下:
res = r'(.*?) '
find_str = re.findall(res, str, re.S)[0]
# 去除单位
res_2 = '[1-9]{1}[\\d ~\\s]*\\d'
find_str = re.findall(res_2, find_str, re.S)[0]
# 去除字符串中的空格
strinfo = re.compile('[\\s]')
return re.sub(strinfo, '', find_str)
更换为 BeautifulSoup 后实现如下:
number_tag = tag.find('td', align='right')
if number_tag is None:
return 'None'
else:
price = re.search('[1-9]{1}[\\d ~\\s]*\\d',
next(number_tag.stripped_strings),
re.S).group()
strinfo = re.compile('[\\s]')
return re.sub(strinfo, '', price)
- 解析出一行中的价格信息
使用正则表达式的实现如下:
res = r"(.*?)
"
find_str = re.findall(res, str, re.S)
# 若无对应的价格是显示 None
if len(find_str):
# 去除价格中的单位
res_2 = '[1-9]{1}[\\d\\.]*'
find_str = re.findall(res_2, find_str[0], re.S)
return find_str[0]
else:
return 'None'
更换为 BeautifulSoup 后实现如下:
price_tag = tag.find('p', class_='goldenrod')
if price_tag is None:
return 'None'
else:
price = [price for price in price_tag.stripped_strings]
return re.search('[1-9]{1}[\\d\\.]*', price[0], re.S).group()
从以上三个步骤中的实现来看,使用 BeautifulSoup 的代码意图更加清晰,同时我们也无需去费心编写正则表达式『其实吧,我觉得正则表达式写起来还是比较费神的』,只需要找到所需内容所在的 html 标签,设置好过滤内容就可以了,而这些在网页源码中可以非常方便的获取到,以下既是要解析的内容所对应的源码,看完以后你就会觉得这非常简单。
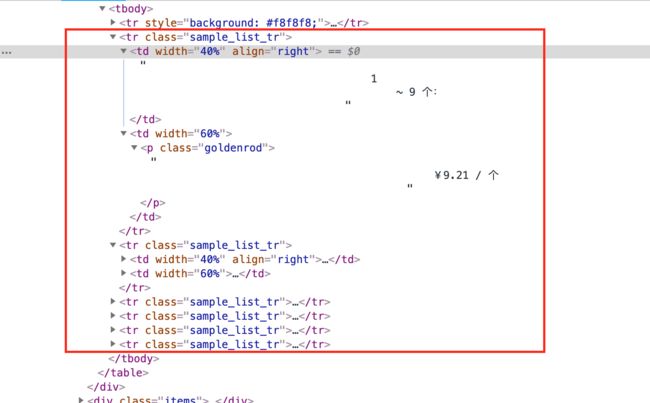
源码已经上传到了最大的同性交友网站「github」,https://github.com/keinYe/pycrawler 有兴趣的话可自行查看。