数据爬取概念以及Java和Python语言实现
数据爬取
1. 爬虫概念
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
广义上的爬虫:搜索引擎,针对于广域网上所有的网站的数据的获取
狭义上的爬虫:12306抢票,针对于某一个或某一类网站的数据的获取
爬虫的三个关键步骤:
1. 网站源代码的获取
2. 对源代码解析
3. 数据的持久化
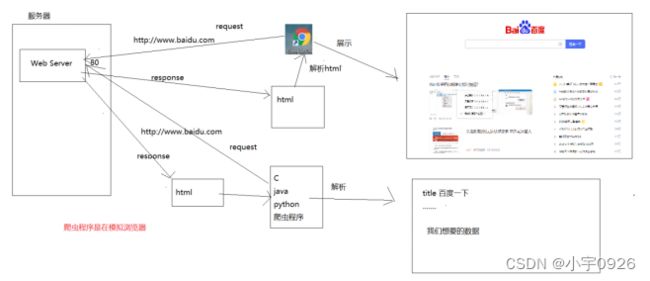
2. HTTP协议



3. 常用的爬虫技术
- Java
| URLConnection | java.net包下提供的 |
|---|---|
| HttpClient | Apache提供的 |
| Jsoup | Java 的XML解析器 |
| Webmagic | 分布式爬虫框架(基于Scrapy实现的) |
| Selenium | Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。 |
- Python
| urllib | 基础爬虫工具 |
|---|---|
| requests+bs4 | 爬取+解析 |
| Scrapy | 分布式爬虫,网站级爬取 |
| PySpider | 分布式爬虫,带有WebUI界面(CN) |
4. 第一个爬虫程序
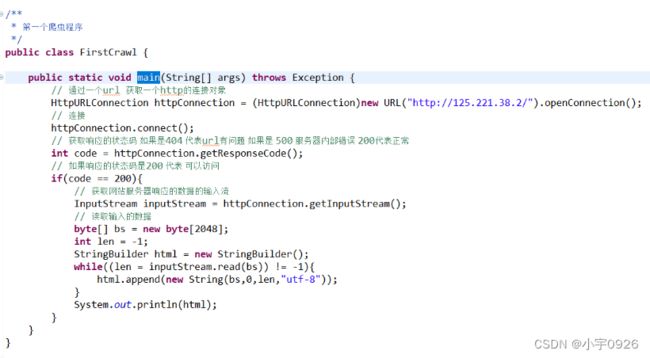
以上是使用JDK提供的URLConnection来获取网站的源代码
5. 数据提取技术
| RE | 正则表达式 |
|---|---|
| CSS | CSS选择器 |
| XPATH | 解析XML文档 |
6. Jsoup的基本使用
6.1 根据URL获取网页源代码

6.2 CSS选择器的基本使用
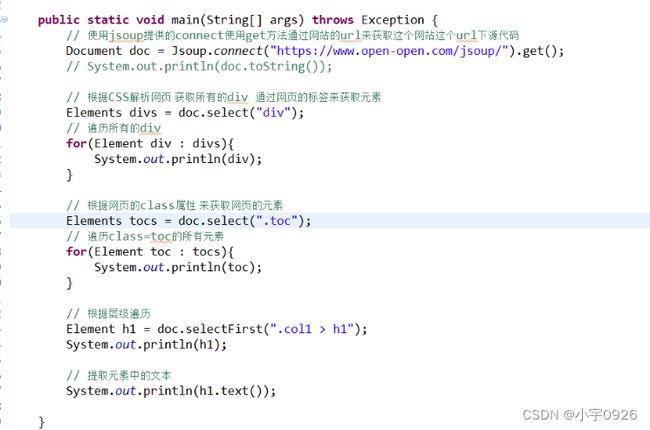
CSS选择器的具体的用法可以参考中文网站
https://www.open-open.com/jsoup/selector-syntax.html
7. 爬取Discuz论坛数据
爬取discuz论坛中的某一个板块中的所有帖子,Discuz网站如下图所示。
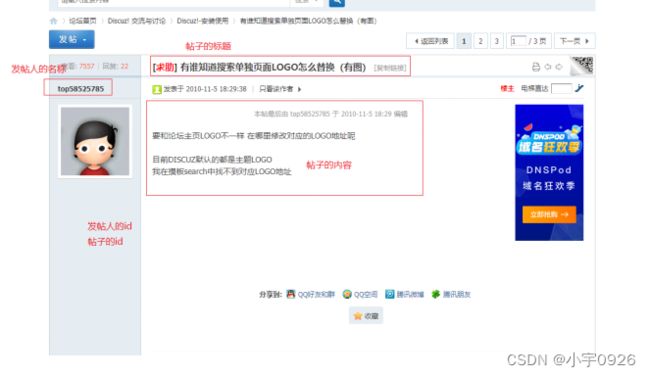
需要爬取的内容为帖子的id|发帖人的名称| 发帖人的id| 帖子的标题 |帖子的内容
7.1 分析具体的帖子的网页源代码
- 帖子的id
![]()
-
发帖人的名称和发帖人的id

-
帖子的标题 位于

-
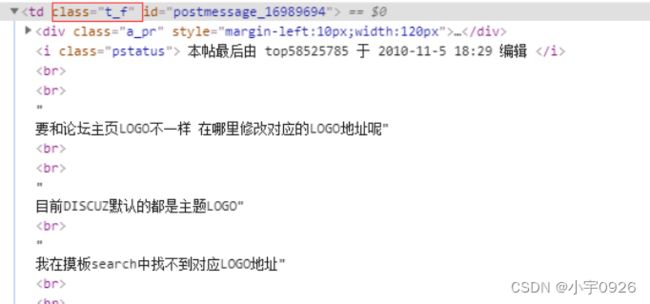
帖子的内容
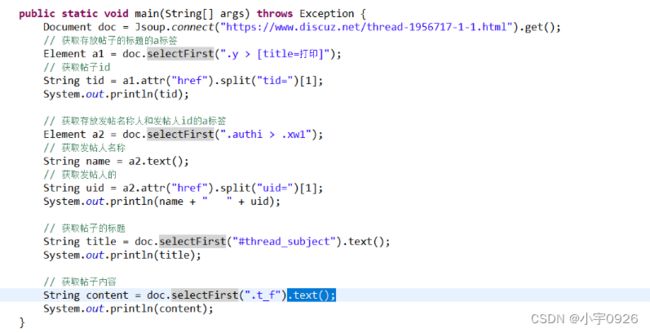
7.2 编写代码爬取单个帖子网页内容
7.3 获取列表页中所有的帖子的URL
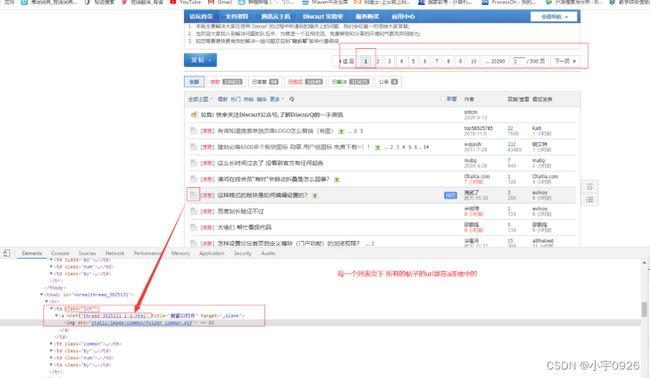
爬取思路:获取当前列表页的所有的url,就需要获取到所有class=icn的td下的a标签
7.4 编写爬取列表页所有帖子的url的代码
7.5 Java代码
- CrawlDiscuz.java
package cn.crawl.demo;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class CrawlDiscuz implements Runnable {
// 开始页面
private int startPage;
// 结束页面
private int endPage;
public CrawlDiscuz(int startPage, int endPage) {
this.startPage = startPage;
this.endPage = endPage;
}
/**
* 根据传入的页面范围 爬取范围内所有列表页的帖子
*
* @param startPage
* @param endPage
* @throws Exception
*/
public void getPage(int startPage, int endPage) throws Exception {
// 创建文件写入对象
FileWriter fw = new FileWriter("d:/discuz.txt", true);
// 创建带有缓冲区的文件输出流
BufferedWriter bw = new BufferedWriter(fw);
// 创建 打印流
PrintWriter pw = new PrintWriter(bw);
for (int i = startPage; i <= endPage; i++) {
Document doc = Jsoup.connect(
"https://www.discuz.net/forum-2-" + i + ".html").get();
// 获取当前列表页下的所有子链接
Elements aList = doc.select(".icn > a");
System.out.println("total: " + aList.size());
// 提取连接
for (Element e : aList) {
String url = "https://www.discuz.net/" + e.attr("href");
System.out.println("get ----> " + url);
// 调用爬取帖子内容的方法
String content = getContent(url);
// 将爬取数据写入文件
pw.print(content);
// 写入换行符
pw.println();
}
// 刷新流
pw.flush();
}
// 关闭流
pw.close();
}
/**
* 根据传入的帖子的url 爬取帖子的内容
* @param url
* @return
* @throws IOException
*/
public static String getContent(String url) throws IOException {
Document doc = Jsoup.connect(url).get();
Element a1 = doc.selectFirst(".authi > a");
// 如果获取的到 就爬取
if (a1 != null) {
// 获取帖子的作者 和 用户id
String author = a1.text();
// uid
String uid = a1.attr("href").split("uid=")[1];
// 获取存放帖子id的a标签
Element a2 = doc.selectFirst("[title=打印]");
// 获取帖子id
String tid = a2.attr("href").split("tid=")[1];
// 获取帖子的标题
String title = doc.selectFirst(".ts").text();
// 获取帖子的内容
String content = doc.selectFirst(".t_f").text();
// 组装数据
StringBuilder sb = new StringBuilder().append(author).append("\t")
.append(uid).append("\t").append(tid).append("\t")
.append(title).append("\t").append(content).append("\t");
return sb.toString();
} else {
// 如果获取不到 就爬取了 因为有的帖子需要登录
return "";
}
}
// 线程的run方法
@Override
public void run() {
try {
// 调用爬取列表页帖子的方法
getPage(startPage, endPage);
} catch (Exception e) {
e.printStackTrace();
}
}
}
- Test.java
package cn.crawl.demo;
public class Test {
public static void main(String[] args) throws Exception {
// 创建爬取数据的线程
for(int i = 1;i <= 500;i ++){
if(i % 10 == 0){
new Thread(new CrawlDiscuz(i - 9, i)).start();
}
}
}
}
7.6 Python代码
# -*- coding: utf-8
import time
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool as ThreadPool
# 根据url获取网页内容
def getHtml(url):
text = ""
try:
r = requests.get(url);
r.encoding = r.apparent_encoding;
text = r.text;
print("get url ---->%s"%(url))
except:
print("爬不动了");
return text;
# 获取url的方法
def getUrl(page):
urls = []
for i in range(1,page):
url = "https://www.discuz.net/forum-2-%s.html"%(i);
print("get page ----> %s"%(url))
soup = BeautifulSoup(getHtml(url),"lxml")
#提取网页连接
aList = soup.select(".icn > a")
for a in aList:
urls.append("https://www.discuz.net/%s"%(a['href']))
return urls
# 获取数据的方法
def getContent(url):
# 根据网页的源代码生成soup对象 解析网页 使用解析器为lxml
soup = BeautifulSoup(getHtml(url),"lxml")
# 获取用户名 和 用户id所在的a标签
a = soup.select_one(".authi > a")
if a != None:
# 获取标题
title = soup.select_one("#thread_subject").text
uid = a['href'].split("uid=")[1]
uname = a.text
# 获取帖子id
tid = url.split("-")[1].split("-")[0]
write_content("%s,%s,%s,%s"%(tid,title,uid,uname))
# 将数据写入文件的方法
def write_content(text):
f = open("D:\\res.txt","a",encoding='utf-8')
f.write(text)
f.write("\n")
f.close()
if __name__ == '__main__':
# 开始时间
start = time.time()
urls = getUrl(500)
# 创建线程池
pool = ThreadPool(20)
pool.map(getContent,urls)
pool.close()
# 结束时间
end = time.time()
print("程序用时: %s"%(end - start))
8. Python爬虫
8.1 Python的第一个爬虫程序
主要使用Python的Requests库进行爬虫,Requests 官方文档链接如下。
https://requests.readthedocs.io/zh_CN/latest/user/quickstart.html
import requests
# 使用get方法获取网站的源代码 返回一个response
r = requests.get("http://www.baidu.com")
print(r.text)
8.2 BeautifulSoup的使用
解析网页源代码主要使用bs4库的BeautifulSoup模块,官方文档如下。
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
import requests
from bs4 import BeautifulSoup
# 使用get方法获取网站的源代码 返回一个response
r = requests.get("http://125.221.38.2/")
html = r.text
print(html)
# 创建一个soup对象 用于解析html文档
soup = BeautifulSoup(html,"html.parser")
# 获取html中的title 标签
title = soup.title
print(title.text)
# 获取html中的body标签
body = soup.body
print(body)
- CSS选择器的使用
import requests
from bs4 import BeautifulSoup
# 使用get方法获取网站的源代码 返回一个response
r = requests.get("http://125.221.38.2/")
html = r.text
# 根据html的源代码 创建一个soup对象
soup = BeautifulSoup(html,"html.parser")
# 根据元素的class获取对应的元素 select_one只会选择到第一个匹配的元素
div = soup.select_one(".message")
# 获取当前div下的所有的p标签的元素 select就会返回所有匹配的元素
pList = div.select("p")
# 遍历p标签
for i in range(0,len(pList)-1):
print(pList[i].text)
9.总结
本文简单介绍了爬虫的基本原理,Java和Python两种语言实现网页爬虫的方式。随着现在互联网环境越来越规范,爬虫也成为了高危操作,对数据爬取者本身来说,如果对爬取的目标网站造成危害,就可能要承担相应的法律责任,对于被爬取网站来说,会造成服务器的负载过大,影响自身业务系统。