【APT检测——论文精读】DEPCOMM:用于攻击调查的系统审计日志的溯源图
DEPCOMM: Graph Summarization on System Audit Logs for Attack Investigation
文章目录
- DEPCOMM: Graph Summarization on System Audit Logs for Attack Investigation
-
- 摘要
- Introduction
- 2 BACKGROUND AND MOTIVATION
-
- A. 系统事件和因果分析
- B. 举例
-
- ==生成社区==。
- 3 OVERVIEW AND THREA T MODEL
- 4 DESIGN OF DEPCOMM
-
- A.依赖图的生成
- B.依赖关系图预处理
- C.社区检测
-
- 分层随机游走算法
- 进程节点表示
- 进程节点聚类
- D.社区压缩
-
- 基于进程的模式
- 基于资源的模式
- E. 社区摘要
摘要
因果分析从系统审计日志生成依赖图(dependency graph),这已成为攻击调查的重要解决方案。在依赖关系图中,节点表示系统实体(例如,进程和文件),边缘表示实体之间的依赖关系(例如,写入文件的进程)。但因果关系分析通常会产生一个大的图(>10000条边),而安全分析人员检查这样一个大图进行攻击调查是一项艰巨的任务。为了解决攻击调查中的挑战,我们提出了DEPCOMM,这是一种图形摘要(graph summarization)方法,通过将大型依赖图划分为以进程为中心的团体然后为每个团体生成摘要,从依赖图生成摘要图。具体而言,团体由一系列亲密进程和进程访问的资源(如文件)构成,这些进程相互协作以完成某些系统活动(例如,文件压缩)。在社区中, DEPCOMM进一步识别由不太重要和重复的系统活动导致的冗余边缘,并对这些边缘执行压缩。 最后,DEPCOMM使用表示跨团体的信息流InfoPaths为每个团体生成摘要。这些InfoPaths更有可能捕获一组与攻击相关的进程,这些进程协同工作以实现某些恶意目标。我们对真实攻击(约1.5亿事件)的评估表明,DEPCOMM平均生成18.4个依赖图社区,比原始图小约70倍。我们的压缩进一步将每个社区的边缘平均减少到32.1。与9种最先进的团体检测算法相比,平均而言,DEPCOMM在检测社区方面的F1得分比这些算法高2.29倍。通过与自动技术HOLMES的合作,DEPCOMM可以通过96.2%的召回率识别被攻击的社区。我们对真实攻击的案例研究也证明了DEPCOMM在促进攻击调查方面的有效性。
Introduction
最近的网络攻击已经渗透到许多受到良好保护的企业,造成了重大的经济损失。为了应对这些攻击,基于无处不在的系统监控的因果关系分析已成为执行攻击调查的重要方法。系统监控观察系统调用并生成内核级审计事件作为系统审计日志。这些日志可以进行因果分析,以确定入侵的入口点(后向跟踪)和攻击的后果(前向跟踪),已被证明在协助攻击调查和及时系统恢复方面的有效性。
虽然因果关系分析的早期结果很有希望,但现有方法需要人工检查,这阻碍了其广泛采用。因果分析方法将同一系统调用事件(例如,读取文件的进程)中涉及的系统实体(例如,文件、进程和网络连接)视为具有因果相关性。基于这些依赖关系,这些方法使用系统依赖关系图表示系统调用事件,其中节点表示系统实体,边缘表示从系统事件派生的依赖关系。使用依赖图,安全分析师可以通过重建导致POI事件(Point-Of-Interest)(例如,入侵检测系统报告的警报事件)的事件链来调查攻击的上下文信息。此类上下文信息可有效地揭示攻击相关事件,如识别勒索软件中ZIP的良性使用。然而,由于依赖性爆炸问题,安全分析师很难从一个巨大的图(通常包含>100K条边)中有效地提取所需的上下文信息。
认识到在攻击调查中使用依赖图的挑战,最近提出了自动过滤无关事件并揭示攻击相关事件的技术。尽管这些技术取得了令人满意的结果,但由于三个主要原因,人工攻击调查仍然不可或缺。首先,尽管很少,但系统中始终存在残余风险,这些风险无法通过这些自动化技术准确揭示,尤其是对于严重依赖系统配置文件的技术。第二,威胁不断演变,以规避防御技术,例如新出现的攻击战术和对手最近开发的技术。第三,现有技术主要依赖启发式规则(启发式规则检测方法通过专业的分析人员对现有的恶意代码进行规则提取,并依照提取出的规则对代码样本进行检测),这些规则会导致信息丢失和侵入性系统更改,如二进制插入,阻碍了它们的实际应用。
动机:为了有效地协助攻击调查,在本文中,我们的目标是 开发一种图摘要方法,该方法保留依赖图中系统活动的语义,同时通过隐藏不太重要的细节来缩小其大小。 更具体地说,我们的目标是通过将依赖关系图划分为多个社区(即子图)并为每个社区提供简洁的摘要来生成一个摘要图。每个社区只包含密切相关的进程,它们一起工作以完成某些系统任务(例如,文件压缩)。然后,我们使用这些进程及其访问的资源来计算摘要,这些资源可以表示共同勾勒原始依赖关系图骨架的高级系统活动。此外,我们的图形摘要可以与现有的自动调查技术结合[12–15,28],以突出与攻击相关的社区。
挑战:图形摘要技术通过生成一个简洁的图像表示(eg.摘要图)已被证明在管理大规模图形方面是有效的。然而,对攻击调查摘要图的安全含义研究甚少。特别是,依赖关系图的独特特性对DEPCOMM生成依赖关系图摘要图提出了三大挑战。
- 依赖图是一种异构图,其中节点表示不同类型的系统实体(即进程、文件和网络连接),并在攻击步骤中扮演不同的角色。对每个节点一视同仁的通用摘要技术不能有效地检测表示主要系统活动的社区。此外,非安全域的特定域的技术,即使它是为异构图设计的,也很可能导致攻击信息的丢失。
- 因果关系分析依赖于事件时间来识别因果依赖关系(例如,一个进程在另一个进程写入文件之后读取文件),并且依赖关系图包含许多不太重要的依赖关系,这些依赖关系表示不相关的系统活动,例如记录系统维护任务和不相关的web浏览。这些依赖关系成为依赖关系图的主要部分,压缩和隐藏不太重要的依赖关系是一项具有挑战性的任务。
- 图形摘要技术主要处理存储在数据库中的数据,其模式和约束在生成的摘要图形中起着重要作用。但在依赖关系图中,表示系统活动的一系列边应该是生成的攻击调查摘要图的核心。如何总结这些边成为DEPCOMM面临的另一个挑战。
贡献:为了解决依赖图的图摘要中的上述挑战,我们提出了DEPCOMM,这是一种图摘要方法,它检测以进程为中心的社区,压缩每个社区中不太重要的边缘,并使用表示社区之间信息流的排名靠前的路径来总结每个社区。DEPCOMM是一种通用方法,它在大规模依赖图上执行图形摘要,并可以与各种自动调查技术合作,以突出显示和可视化攻击相关社区。DEPCOMM的设计由以下关键见解驱动。
首先,在系统审计日志中,系统活动(例如,下载恶意脚本并执行脚本)通常被表示为一组进程节点,这些进程节点要么彼此具有强相关性,要么通过一些资源节点具有数据依赖性。例如,一个进程tar产生一个子进程bzip2,它们一起工作来压缩文件。通过仔细检查进程的协作,我们观察到这些进程要么具有父子关系(生成一组子节点的进程),要么共享相同的父进程(兄弟进程),并通过某些资源(例如,文件)具有数据依赖性,我们将这类密切相关的进程称为亲密进程。因此,为了应对这一挑战,DEPCOMM将依赖关系图划分为以进程为中心的社区,其中每个社区包括一组亲密进程和这些进程访问的系统资源。
- 亲密进程的定义:具有父子关系(生成一组子节点的进程),要么共享相同的父进程(兄弟进程),并通过某些资源(例如,文件)具有数据依赖性。
- DEPCOMM将依赖关系图划分为以进程为中心的社区,其中每个社区包括一组亲密进程和这些进程访问的系统资源。
其次,如最近的研究[26,27,33]所示,由于不太重要和重复的系统活动(如历史记录任务和备份文件更新),存在许多冗余边缘。因此,为了应对这一挑战,DEPCOMM确定了基于进程和基于资源的模式,并根据每个社区的这些模式压缩边缘。与现有工作[27,33]不同,我们的社区检测允许在社区内的多个进程之间进行积极压缩。
第三,通过仔细检查各种攻击的依赖关系图[12,13,15,18],主要系统活动(例如,压缩文件)和攻击行为(例如,泄漏数据)通常表示为附加进程之间的信息流,例如压缩敏感数据和泄漏压缩文件。这种信息流通常表示为社区中从输入节点到输出节点的路径,称为InfoPaths。例如,恶意脚本通过打包、加密和上载来泄漏敏感文件,相应的InfoPath为:../secret.doc→tar→../upload.tar→bzip2→../upload.tar .bz2→gpg→../upload.gpg→curl→xxx->xxx.。此外,在一个社区中,从输入到输出可能有许多InfoPath,并且并非所有InfoPath都与主要系统活动相关。因此,为了应对这一挑战,DEPCOMM对每个社区内的InfoPaths进行了优先级排序,并对最有可能代表攻击步骤和主要系统活动的InfoPath进行了排名。
方法:基于这些见解,DEPCOMM提供了新的技术来检测以进程为中心的社区,在检测到的社区内执行压缩,并为每个社区生成代表性摘要。
为了检测以进程为中心的社区(第IV-C节),DEPCOMM学习依赖关系图的进程节点的行为表示,并将具有类似表示的进程节点聚类到社区中。具体而言,DEPCOMM在每个进程节点上执行随机行走[34]以获得行走路线,并通过矢量化这些行走路线来计算每个进程节点的行为表示。特别是,按照现有的随机游动算法[34–38]那样平等的处理每个节点,它们在为亲密进程生成相似的行为表示方面不太有效。因此,我们设计了一系列新颖的分层行走方案,它们利用进程的本地邻居和全局进程谱系树(lineage trees)的信息[39]来选择更可能找到亲密进程的行走路线。利用每个进程节点的已经学习的表示,DEPCOMM将这些进程节点聚类为社区,并进一步将这些进程访问的资源节点分类到检测到的社区中,从而产生以进程为中心的社区。
为了执行社区压缩(第IV-D节),DEPCOMM首先为每个社区计算进程谱系树,并将每个进程节点与访问资源节点的事件相关联。通过搜索该树,DEPCOMM可以识别基于进程的模式(例如,一个bash进程产生多个vim进程)和基于资源的模式(如,多个vim进程编辑源文件)。通过识别基于进程和基于资源的模式,DEPCOMM合并所有重复的边缘和节点以压缩社区。
压缩社区后,DEPCOMM为每个社区生成InfoPaths,对InfoPaths进行优先级排序,并将排名靠前的InfoPaths作为社区的摘要(第IV-E节)。为此,DEPCOMM首先根据社区之间的信息流识别每个社区的输入节点和输出节点,然后通过查找每对输入和输出节点的路径来生成InfoPaths。接下来,DEPCOMM根据表示社区中主要系统活动(例如,POI事件——入侵检测系统报告的警报事件)的可能性为每个InfoPath分配优先级分数。最后,DEPCOMM根据优先级对这些InfoPaths进行排名,并将排名靠前的InfoPaths显示为社区的摘要。虽然前2个InfoPaths可以揭示大多数社区的攻击行为(第V-E节),但安全分析师可以根据他们的需求决定社区摘要中显示的前InfoPaths的数量。
- 根据信息流找到输入节点和输出节点;
- 根据输入节点和输出节点之间的路径生成InfoPaths;
- 根据发生安全事件的可能性为每个InfoPath分配优先级分数;
- 使用排名靠前的InfoPaths显示为社区的摘要
实验评估部分。我们对在实验室环境中执行的6次真实攻击和DARPA TC数据集中的8次攻击进行了DEPCOMM评估[40]。总共有约1.5亿个系统审计事件,生成的依赖关系图平均由1302.1个节点和7553.4条边组成。在我们的评估中,DEPCOMM为依赖图平均生成18.4个社区,比原始图小约70倍。这些社区平均包含43.1个节点和248.5条边。与9种最先进的社区检测算法[36,38,41–47]相比,DEPCOMM获得的F1分数(94.1%)平均比算法获得的分数高2.29倍。接下来,DEPCOMM基于检测到的基于进程和基于资源的模式对社区进行压缩,平均压缩率为44.7%。被压缩后的社区平均有15.7个节点和32.1个边缘,分别减少了63.6%和87.1%。此外,通过使用排名前2的InfoPaths可以有效地调查所有攻击,即平均15.7条InfoPaths中的2条(12.7%)。这些结果表明这些摘要图需要更少的人工进行攻击调查。此外,与HOLMES合作的评估[32]表明,除两个攻击社区外,所有攻击社区都映射到Kill Chain[48]中的步骤(实现96.2%的召回率),通过考虑相邻的攻击社区,可以容易地识别这两个未披露的社区。我们的DEPCOMM实施和评估数据集可在我们的项目网站上获得[49]。
代码和数据集:https://github.com/ieeesp2021sub/depcomm
2 BACKGROUND AND MOTIVATION
A. 系统事件和因果分析
系统审计事件:监控和分析内核级审计事件对于攻击调查和检测至关重要。系统审计事件描述了两个系统实体之间的交互,它们表示为3元组 < s u b j e c t , o p e r a t i o n , o b j e c t >
因果分析:因果分析已广泛应用于攻击调查和检测[8-15]。它推断系统审计事件之间的因果依赖关系,并将它们组织为依赖关系图。依赖关系图是一个有向图,其中节点表示系统实体(即进程、文件和网络连接),边表示系统审计事件。在依赖图 G ( E , V ) G(E,V) G(E,V)中,系统审计事件表示为有向边 e ( u , v ) e(u,v) e(u,v),其中 u ∈ V , v ∈ V 、 e ∈ E u∈V,v∈V、e∈E u∈V,v∈V、e∈E,边的方向表示数据流的方向(即从 u u u流向 v v v)。此外,边缘记录事件的开始时间 ( e . s t ) (e.st) (e.st)和结束时间 ( e . e t ) (e.et) (e.et)。给定两个节点 n 1 n_1 n1和 n 2 n_2 n2,如果存在两个边缘 e 1 ( n 1 , v 1 ) e_1(n_1,v_1) e1(n1,v1)和 e 2 ( v 2 , n 2 ) e_2(v_2,n_2) e2(v2,n2),使得 v 1 = v 2 v_1=v_2 v1=v2且 e 1. s t ≤ e 2. e t e1.st≤e2.et e1.st≤e2.et,则 n 2 n_2 n2对 n 1 n_1 n1具有因果依赖性。
n 1 → v 1 ( v 2 ) → n 2 n_1\to v_1(v_2)\to n_2 n1→v1(v2)→n2,且 e 1. s t ≤ e 2. e t e1.st≤e2.et e1.st≤e2.et,则 n 2 n_2 n2对 n 1 n_1 n1具有因果依赖性
(??感觉是不是写反了,应该是 e 1. e t ≤ e 2. s t e1.et≤e2.st e1.et≤e2.st)
B. 举例
我们以数据泄露攻击为例来解释DEPCOMM。在该攻击中,攻击者通过Apache Sever在目标系统中下载并执行一个后门程序bdoor,并利用打开的9999端口后门打开终端(即bash)。然后,攻击者下载一个可执行脚本leak.sh,并利用root访问权限运行该脚本来收集敏感文件,这些文件被发送到可疑的远程主机。进程和操作系统资源之间的所有这些活动都被捕获在系统审计日志中(捕获/采集数据)。我们通过从将文件发送到远程IP的可疑事件(即POI事件)应用因果关系分析来构建依赖关系图。下图显示了依赖关系图的一部分。完整的依赖关系图有1038个节点和4039条边,包括攻击相关和良性事件。

数据泄露攻击的部分依赖关系图。完整的依存关系图有1038个节点和4039条边。DEPCOMM将依赖关系图划分为10个以进程为中心的社区,其中红色虚线框是具有攻击相关事件的社区(粗体红色边缘),蓝色虚线框是仅具有正常事件的社区。对于表示社区输入和输出的节点,我们创建这些节点的副本(蓝色节点),并将每个副本分配给社区。这些副本通过有向边(蓝色虚线箭头)连接,其中方向指示跨社区的信息流的方向。
在本文中,我们设计了DEPCOMM,将一个大型依赖关系图概括为一个紧凑的图,以便于攻击调查。DEPCOMM包括三个关键部分:(1)生成社区(2)压缩社区(3)生成社区摘要。

生成社区。
DEPCOMM首先将依赖关系图划分为10个以进程为中心的社区(C1–C10),如上图所示,每个社区由一组亲密的进程节点及其访问的资源节点组成。例如,在C3中,leak进程产生tar、bzip2、gpg和curl,因此leak进程与这些子进程节点具有父子关系。此外,资源节点../upload.tar,../upload.tar.bz2,../upload和xxx->xxx由这些进程点访问,因此被分类为C3社区。
此外,社区之间的依赖关系是:(1)社区之间基于边的依赖关系(例如,C1和C2之间的bdoor→bash)或(2)基于节点的依赖关系(图1中的蓝色椭圆),表示社区之间的输入/输出关系(例如,C2和C3中的leak)。

压缩社区。为了进一步减小每个社区的大小,同时保留其语义,DEPCOMM压缩社区中不太重要和冗余的依赖关系,例如,在C9中,bash重复生成python(12次)和vim(13次)进行读写../adjust.py和/dev/null,这可以概括为基于进程的模式(即bash创建许多python和vim节点)和基于资源的模式(例如,许多python和vim节点访问的../adjust.py)。压缩后,C9的边缘数从108个减少到33个(压缩率69.4%)。类似地,C5从58个边缘压缩成2个边缘(96.5%的压缩率)。
生成社区摘要。如图2所示,对于每个社区,DEPCOMM生成一个摘要,它由三个部分组成:
- 起始节点作为社区行为源的主进程节点(例如,C3中的
leak); - 社区中最早事件的开始时间和最新事件的结束时间之间的时间跨度;
- 排名靠前的InfoPaths,以显示社区的主要信息流。
排名靠前的InfoPath是leak to xxx->xxx: leak→tar→../ upload.tar→bzip2→../upload.tar .bz2→gpg→../upload→curl→xxx->xxx它具有最高优先级,因为它包含POI事件curl→xxx->xxx。
攻击检测。接下来,我们将展示如何使用图2中的摘要图来研究C3中的POI事件curl→xxx->xxx去检测攻击。首先,通过检查其他社区(C2、C4、C6、C7、C8)到C3的所有边缘,我们发现来自C2的边缘与C3的主进程节点leak和C3的前1 InfoPath比来自其他社区的边更相关。因此,C2被认为具有导致POI事件的攻击相关事件。接下来,对于C2和其他社区之间的边缘,我们确定C1的bdoor→bash 的边比来自C5的边更相关。因此,C1可能代表攻击的初始步骤。总之,我们只检查了53个节点和8个InfoPaths,就识别了35个与攻击相关的事件,这大大减少了人工工作。
3 OVERVIEW AND THREA T MODEL

图3显示了DEPCOMM的体系结构。DEPCOMM由五个组件组成:(1)依赖图生成,(2)依赖图预处理,(3)社区检测,(4)社区压缩,(5)社区摘要。
- 依赖图生成组件:利用因果关系分析从系统审计事件计算依赖图(第IV-a节)。
- 依赖关系图预处理组件:通过合并两个节点之间相同类型的边并过滤出只读文件节点来处理图(第IV-D节)。
- 社区检测组件将依赖图:划分为多个以进程为中心的社区并将资源节点与社区相关联(第IV-C节)。
- 社区压缩组件:基于所识别的基于进程的模式和基于资源的模式来压缩每个社区中的节点和边缘(第IV-D节)。
- 社区摘要组件:提取每个社区的InfoPaths,并对这些InfoPaths进行优先级排序。最后,DEPCOMM生成一个具有排名靠前的InfoPaths的摘要图(第IV-E节)。
威胁模型:我们遵循与之前的安全调查工作相同的威胁模型[8,9,25,50,51]。OS级事件是从系统内核收集的。我们假设系统内核是可信的,不会被对手篡改[52,53]。任何故意危害安全审计系统的内核级攻击都超出了本工作的范围,现有的软件和内核强化技术[50,54–56]可用于更好地保护日志存储。我们也不考虑使用侧信道或程序间通信(IPC)执行的攻击,这些攻击无法被底层源跟踪器捕获。可以使用更细粒度的审计工具来捕获内存跟踪或侧通道分析技术来解决这些攻击,但它们不是本工作的重点。
DEPCOMM将系统行为聚类到社区中,并对表示跨社区信息流的InfoPaths进行优先级排序。因此,完全了解DEPCOMM摘要方法的攻击者可能会故意将其攻击限制在少数进程和文件内,从而最大限度地减少社区内和社区间的痕迹。这种攻击通常通过操纵进程的存储器来危害进程(例如,代码重用攻击[57]),可以应用诸如存储器随机化[58,59]的专门技术来加强存储器保护。攻击者还可以通过执行生成大量日志的活动(例如创建大量临时文件)来淹没系统审计日志。为了防御此类攻击,可以使用现有的日志压缩技术[26,27,33,60]来压缩系统审计日志,并且DEPCOMM可以在压缩日志上无缝工作,因为这些压缩日志保留了相关性。此外,可以部署异常检测技术[14,61],以针对日志收集中的此类意外峰值发出警报。
4 DESIGN OF DEPCOMM
A.依赖图的生成

DEPCOMM使用在主流操作系统(如Windows、Linux、Mac OS和Android)上运行的系统监控工具来收集系统审计事件,包括进程事件、文件事件和网络事件。对于每个收集的实体和事件,DEPCOMM记录安全分析所必需的属性(例如,实体的PID、文件名和IP;事件的开始时间、结束时间和操作),如表I和表II所示。给定POI事件(例如,关于文件下载的警报),DEPCOMM通过执行反向因果分析来构建依赖关系图,以跟踪依赖关系。从POI事件开始,因果分析迭代地找到与POI事件具有相关性并且在POI事件之前发生的事件。这些发现的事件(即依赖图中的边)形成POI事件的依赖图。
B.依赖关系图预处理
边合并:依赖关系图通常在进程节点和文件/网络节点之间有许多平行的边缘,表示在短时间内重复的读/写操作。这是因为OS通常通过将数据按比例分配给多个系统调用来执行读/写任务。如最近的研究[26]所示,这些平行边缘没有为攻击调查提供额外有用的信息,因此DEPCOMM直接将相同操作类型的平行边缘合并为一个边缘。
过滤只读文件节点:如最近的研究[33,51]所示,依赖关系图有许多只读文件,这些文件通常是用于进程初始化的库、配置文件和资源(例如/lib64/libdl.so.2),不包含有用的攻击相关信息[33]。因此,DEPCOMM过滤掉只读文件并保留进程以保留主要系统活动的语义。
C.社区检测
DEPCOMM将一组亲密进程定义为以进程为中心的社区。以进程为中心的社区是一个图,它包含(1)一个主进程节点,(2)一组表示主进程派生子进程子集,这些子进程彼此之间具有数据依赖性,以及(3)一组由主进程和这些子进程访问的资源节点。

例如,leak是 C3 的主进程节点,派生出 tar, bzip, gpg,curl 这些 子进程节点。这些子进程至少与另一个子进程有数据依赖关系,这可以从依赖关系图中的以下路径中反映出来:tar→…/upload.tar→bzip2 →…/upload.tar .bz2→gpg→…/upload→curl→xxx->xxx。此外,有些进程或资源节点可以属于多个社区,称为重叠节点。例如,在图1中,leak首先与curl联系,在C2中完成脚本leak.sh的执行,然后生成子进程tar、bzip2、gpg和curl,在C3中压缩并上传文件。在这种情况下,leak是在C2和C3重叠的节点。我们将重叠节点分为三种类型,如图4所示:
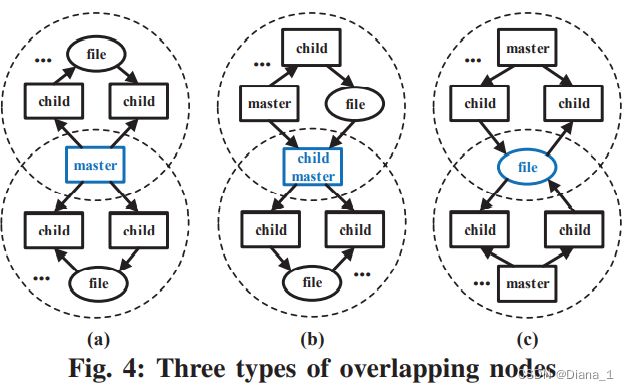
a) 主进程节点,和一系列不同的子进程节点合作完成不同的系统活动;
b) 子进程节点,和它的兄弟节点协作完成一个系统活动,同时产生一系列子进程完成不同的系统活动;
c) 资源节点,由来自不同社区的进程节点访问的资源节点。
接下来,我们将描述DEPCOMM社区检测组件的两个阶段:以进程为中心的社区检测和资源节点关联。
以进程为中心的社区检测。DEPCOMM基于我们提出的[分层行走方案在每个进程节点上执行随机行走以生成行走路线,然后应用word2vec模型[62]来学习基于每个进程节点的行走路线的行为表示。基于行为表示,DEPCOMM将具有相似表示的进程节点集群到相同的社区中。接下来我们将详细描述每个步骤。
分层随机游走算法
以节点 v 1 v_1 v1为根节点的随机行走生成特定长度 W = { v 1 , ⋅ ⋅ , v l } W=\{v_1,··,v_l\} W={v1,⋅⋅,vl}的行走路线,其中 v i ∈ W v_i∈W vi∈W根据转移概率随机选择[34]。从 v i v_i vi到其邻居节点 n n n的转移概率为 P r ( v i , n ) = w ( v i , n ) / W N ( v i ) Pr(v_i,n)=w(v_i,n)/W_{N(v_i)} Pr(vi,n)=w(vi,n)/WN(vi),其中 w ( v i , n ) w(v_i,n) w(vi,n)表示从 v i v_i vi到 n n n的行走权重, W N ( v i ) W_{N(v_i)} WN(vi)代表 v i v_i vi的所有邻居之间的行走权重之和。与现有的以相等概率对待邻居节点的随机行走算法不同[34],DEPCOMM为 v i v_i vi的邻居提供了更高的概率,这些邻居更可能是其亲密过程。
行走者同时考虑 进程的邻居 和 全局进程谱系树(global process lineage trees)来保证联系亲密进程更可能被采样到同一条游走路径中,因此,在嵌入表示之后,这么紧密联系的进程也会很相似。对于每个进程节点 p p p,DEPCOMM检查p的单跳邻居节点(one-hop),并将p关联到:① 父进程节点 ② 子进程节点 ③ 访问的资源节点。特别地,我们观察到,对于一个进程 p r p_r pr 和它的子进程 p c p_c pc ,如果 p c p_c pc开始生成它自己的子进程(通常是多个子进程), p c p_c pc很可能启动一个新的系统任务,而生成的子进程不与 p r p_r pr 合作。因此, p c p_c pc的子进程应该与pr的在不同的社区。为了识别这种子进程的创建,DEPCOMM搜索全局进程谱系树,并将每个进程节点与 ④ 离它最近且有多个子进程的祖先关联起来。
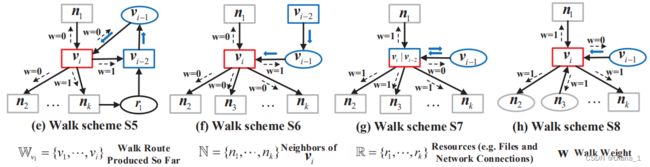
使用从进程的邻居和全局进程谱系树收集的信息(①②③④),DEPCOMM采用8种分层游走方案生成游走序列。具体来说,当walker从进程节点 v 1 v_1 v1开始时,它给每个邻居分配相同的权重(初始化),并随机移动到其中一个。经过这个初始步骤后,行走者根据8种分层行走方案选择下一个节点,如图5所示。在具有通用性的前提下,我们假设步行者目前在节点 v i v_i vi上,目前产生的游走序列为 W v 1 = v 1 , ⋅ ⋅ ⋅ , v i W_{v_1} = {v_1,···,v_i} Wv1=v1,⋅⋅⋅,vi, v i v_i vi的邻居是节点 N = n 1 , ⋅ ⋅ ⋅ , n k N = {n_1,···,n_k} N=n1,⋅⋅⋅,nk的集合, R ( v ) R(v) R(v)表示进程节点 v v v访问的资源节点, L ( v ) L(v) L(v)找到进程节点 v v v的最近祖先,它有多个子进程。下面详细叙述这8种 分层随机游走策略(Hierarchical Random Walk )。

-
策略 S1: v i − 1 v_{i-1} vi−1表示 v i v_i vi的父进程。如果 N N N包含除 v i − 1 v_{i−1} vi−1之外的其他邻居节点,则步行者将随机步行到这些邻居之一,即 ∀ n j ∈ N , n j ≠ v i − 1 , w ( v i , n j ) = 1 , w ( v i , v i − 1 ) = 0 \forall n_j \in \mathbb{N}, n_j \neq v_{i-1}, w\left(v_i, n_j\right)=1, w\left(v_i, v_{i-1}\right)=0 ∀nj∈N,nj=vi−1,w(vi,nj)=1,w(vi,vi−1)=0。如果 v i v_i vi只有一个邻居(即 v i − 1 v_{i-1} vi−1),为了避免步行的提前终止,步行者将返回 v i − 1 v_{i-1} vi−1,即 w ( v i , v i − 1 ) = 1 w\left(v_i, v_{i-1}\right)=1 w(vi,vi−1)=1。
-
策略 S2: v i − 1 v_{i-1} vi−1表示 v i v_i vi的子进程,在该情况下 v i v_i vi的其他子节点不会和 v i − 1 v_{i-1} vi−1属于同一个社区,除非它们和 v i − 1 v_{i-1} vi−1由数据依赖关系。因此,如果有其他子进程访问与 v i − 1 v_{i-1} vi−1相同的资源,则walker将以很高的概率步行到子进程节点,例如: ∀ n j ∈ N , n j ≠ v i − 1 , R ( n j ) ∩ R ( v i − 1 ) ≠ ∅ , w ( v i , n j ) = \forall n_j \in \mathbb{N}, n_j \neq v_{i-1}, \mathbb{R}\left(n_j\right) \cap \mathbb{R}\left(v_{i-1}\right) \neq \emptyset, w\left(v_i, n_j\right)= ∀nj∈N,nj=vi−1,R(nj)∩R(vi−1)=∅,w(vi,nj)= 1 , w ( v i , v i − 1 ) = 0 1, w\left(v_i, v_{i-1}\right)=0 1,w(vi,vi−1)=0,否则,walker将返回 v i − 1 v_{i-1} vi−1, w ( v i , v i − 1 ) = 1 , w ( v i , n j ) = 0 w\left(v_i, v_{i-1}\right)=1, w\left(v_i, n_j\right)=0 w(vi,vi−1)=1,w(vi,nj)=0。
-
策略 S3:考虑 v i − 1 v_{i-1} vi−1代表 v i v_i vi的子进程, v i − 1 v_{i-1} vi−1是 v i v_i vi的唯一子进程。这表明 v i v_i vi和 v i − 1 v_{i-1} vi−1合作处理一些数据,因此它们属于同一个社区。因此,如果除了 v i − 1 v_{i-1} vi−1之外还有其他邻居,则walker将继续探索而不返回,即, ∀ n j ∈ N , n j ≠ v i − 1 , w ( v i , n j ) = \forall n_j \in \mathbb{N}, n_j \neq v_{i-1}, w\left(v_i, n_j\right)= ∀nj∈N,nj=vi−1,w(vi,nj)= 1 , w ( v i , v i − 1 ) = 0 1, w\left(v_i, v_{i-1}\right)=0 1,w(vi,vi−1)=0。否则,为了避免步行提前终止,步行者将返回 v i − 1 v_{i-1} vi−1,即 w ( v i , v i − 1 ) = 1 w\left(v_i, v_{i-1}\right)=1 w(vi,vi−1)=1。
-
策略 S4:考虑 v i − 1 v_{i-1} vi−1是流程节点, v i v_i vi是资源节点。如果 v i − 1 v_{i-1} vi−1和访问 v i v_i vi的进程具有共同的父进程,则访问 v i v_i vi的进程可能属于 v i − 1 v_{i-1} vi−1的社区。因此,我们让walker有很大概率步行到与 v i − 1 v_{i-1} vi−1共享相同父进程的邻居,即, ∀ n j ∈ N , n j ≠ v i − 1 , L ( n j ) = \forall n_j \in \mathbb{N}, n_j \neq v_{i-1}, \mathbb{L}\left(n_j\right)= ∀nj∈N,nj=vi−1,L(nj)= L ( v i − 1 ) , w ( v i , n j ) = 1 , w ( v i , v i − 1 ) = 0 \mathbb{L}\left(v_{i-1}\right), w\left(v_i, n_j\right)=1, w\left(v_i, v_{i-1}\right)=0 L(vi−1),w(vi,nj)=1,w(vi,vi−1)=0。否则,walker将返回 v i − 1 v_{i-1} vi−1,即 w ( v i , v i − 1 ) = 1 , w ( v i , n j ) = 0 w\left(v_i, v_{i-1}\right)=1, w\left(v_i, n_j\right)=0 w(vi,vi−1)=1,w(vi,nj)=0。
-
策略 S5:考虑 v i − 1 v_{i-1} vi−1是一个资源节点, v i v_i vi是一个具有多个子进程的进程节点, v i − 2 v_{i-2} vi−2是 v i v_i vi的子进程。在这种情况下, v i v_i vi的其他子进程可能不像 v i − 2 那样属于社区,除非它们与 v_{i-2}那样属于社区,除非它们与 vi−2那样属于社区,除非它们与v_{i-2}有数据依赖关系。因此,walker将步行到 v i − 2 和访问与 v_{i-2}和访问与 vi−2和访问与v_{i-2}相同资源的子进程节点,即 ∀ n j ∈ N , n j ≠ v i − 1 , n j ≠ v i − 2 , R ( n j ) ∩ R ( v i − 2 ) ≠ ∅ , w ( v i , n j ) = 1 , w ( v i , v i − 2 ) = 1 \forall n_j \in \mathbb{N}, n_j \neq v_{i-1}, n_j \neq v_{i-2}, \mathbb{R}\left(n_j\right) \cap \mathbb{R}\left(v_{i-2}\right) \neq \emptyset, w\left(v_i, n_j\right)=1, w\left(v_i, v_{i-2}\right)=1 ∀nj∈N,nj=vi−1,nj=vi−2,R(nj)∩R(vi−2)=∅,w(vi,nj)=1,w(vi,vi−2)=1,并且其他邻居的权重设置为0。
-
策略 S6:考虑 v i − 1 v_{i-1} vi−1是一个资源节点, v i v_i vi是一个具有多个子进程的进程节点, v i − 2 v_{i-2} vi−2不是 v i v_i vi的子进程。在这种情况下,我们将 v i v_i vi视为社区的主进程,而 v i v_i vi的子进程和 v i − 2 v_{i-2} vi−2不属于同一社区。因此,walker将返回 v i − 1 v_{i-1} vi−1, ∀ n j ∈ N , n j ≠ \forall n_j \in \mathbb{N}, n_j \neq ∀nj∈N,nj= v i − 1 , w ( v i , n j ) = 0 , w ( v i , v i − 1 ) = 1 v_{i-1}, w\left(v_i, n_j\right)=0, w\left(v_i, v_{i-1}\right)=1 vi−1,w(vi,nj)=0,w(vi,vi−1)=1
-
策略 S7:考虑 v i − 1 v_{i-1} vi−1是一个资源节点, v i v_i vi是一个具有多个子进程的进程节点, v i − 2 = v i v_{i-2}=v_i vi−2=vi。这表明 v i − 1 v_{i-1} vi−1表示信息流的结束。为了提高亲密进程的采样效率,步行者将不返回地行走,即, ∀ n j ∈ N , n j ≠ v i − 1 , w ( v i , n j ) = 1 , w ( v i , v i − 1 ) = 0 \forall n_j \in \mathbb{N}, n_j \neq v_{i-1}, w\left(v_i, n_j\right)=1, w\left(v_i, v_{i-1}\right)=0 ∀nj∈N,nj=vi−1,w(vi,nj)=1,w(vi,vi−1)=0。
-
策略 S8:考虑 v i − 1 v_{i-1} vi−1是资源节点, v i v_i vi是最多有一个子进程的进程节点。在这种情况下,如果vi具有除 v i − 1 v_{i-1} vi−1之外的其他邻居节点,则步行者将不返回地步行到邻居节点,即, ∀ n j ∈ \forall n_j \in ∀nj∈ N , n j ≠ v i − 1 , w ( v i , n j ) = 1 , w ( v i , v i − 1 ) = 0 \mathbb{N}, n_j \neq v_{i-1}, w\left(v_i, n_j\right)=1, w\left(v_i, v_{i-1}\right)=0 N,nj=vi−1,w(vi,nj)=1,w(vi,vi−1)=0。如果 v i − 1 v_{i-1} vi−1是 v i v_i vi的唯一邻居,为了避免步行过早终止,步行者将返回 v i − 1 v_{i-1} vi−1,即 w ( v i , v i − 1 ) = 1 w\left(v_i, v_{i-1}\right)=1 w(vi,vi−1)=1。
进程节点表示
(使用word2vec中的skip-gram模型对节点矢量化)我们将依赖关系图中的节点视为单词,将行走路线视为单词的有序序列来进行类比。DEPCOMM使用SkipGram[62](一种广泛使用的单词表示学习算法)来学习行走路线中进程节点的行为表示。更具体地说,给定进程节点 p p p和上下文窗口大小 t t t,Skip-Gram从包含 p p p的每条步行路线中提取子序列 W p = { v i − t , ⋯ , v i , ⋯ , v i + t } \mathbb{W}_p=\left\{v_{i-t}, \cdots, v_i, \cdots, v_{i+t}\right\} Wp={vi−t,⋯,vi,⋯,vi+t},该子序列由 v i = p v_i=p vi=p及其上下文节点 v i + k ( k ∈ ( − t , t ) ) v_{i+k}(k \in(-t, t)) vi+k(k∈(−t,t))组成。然后,通过最大化子序列中出现的节点概率对数来学习的d维向量 Φ ( v i ) \Phi\left(v_i\right) Φ(vi),即 log Pr ( { v i − t , ⋯ , v i − 1 , v i + 1 , ⋯ , v i + t } ∣ Φ ( v i ) ) \log \operatorname{Pr}\left(\left\{v_{i-t}, \cdots, v_{i-1}, v_{i+1}, \cdots, v_{i+t}\right\} \mid \Phi\left(v_i\right)\right) logPr({vi−t,⋯,vi−1,vi+1,⋯,vi+t}∣Φ(vi))。优化过程旨在学习具有相似上下文节点的亲密进程节点的相似行为表示。然而,优化问题是NP-hard。为了使优化问题易于处理,我们假设选择每个节点的概率是条件独立的,并且目标函数被转换为: log ∏ − t ≤ k ≤ t , k ≠ 0 Pr ( v i + k ∣ Φ ( v i ) \log \prod_{-t \leq k \leq t, k \neq 0} \operatorname{Pr}\left(v_{i+k} \mid \Phi\left(v_i\right)\right. log∏−t≤k≤t,k=0Pr(vi+k∣Φ(vi)。此外,使用softmax函数对目标函数进行建模: log ∏ − t < k ≤ t , k ≠ 0 exp ( Φ ( v i + k ) ⋅ Φ ( v i ) ) ∑ v ∈ V exp ( Φ ( v ) ⋅ Φ ( v i ) ) [ 37 ] \log \prod_{-t
进程节点聚类
基于进程节点的行为表示来计算其重叠聚类,DEPCOMM采用了软聚类方法FCM
(Fuzzy C-Means) [64]。与仅将一个进程节点分类为一个集群的硬聚类方法(即K-means硬聚类算法一个对象可以属于两个集合)不同,FCM通过最小化反对函数输出每个集群中每个进程节点的隶属度: J = ∑ i = 1 ∣ V p ∣ ∑ j = 1 ∣ C ∣ u i j 2 ∥ v i − c j ∥ 2 J=\sum_{i=1}^{\left|V_p\right|} \sum_{j=1}^{|C|} u_{i j}^2\left\|v_i-c_j\right\|^2 J=∑i=1∣Vp∣∑j=1∣C∣uij2∥vi−cj∥2,其中 u i j u_{ij} uij表示属于社区 c j c_j cj的过程节点 v i v_i vi的程度。 v i v_i vi被分类为 c j c_j cj,如果 u i j u_{ij} uij高于给定阈值。根据最近的工作[65],我们设置了阈值 λ = 0.8 ⋅ m a x j { u i j } λ=0.8·max_j\{u_{ij}\} λ=0.8⋅maxj{uij}。如果流程节点标记为多个社区(即重叠),我们创建节点的多个副本,并为每个社区分配一个副本。此外,DEPCOMM根据模糊划分系数(FPC) F ( ∣ C ∣ ) = 1 / ∣ V p ∣ ∑ j = 1 ∣ C ∣ ∑ i = 1 ∣ V p ∣ u i j 2 F(|C|)=1 /\left|V_p\right| \sum_{j=1}^{|C|} \sum_{i=1}^{\left|V_p\right|} u_{i j}^2 F(∣C∣)=1/∣Vp∣∑j=1∣C∣∑i=1∣Vp∣uij2[66]确定社区数量 ∣ C ∣ |C| ∣C∣。模糊划分系数(FPC)其用于测量不同数量的cluster的有效性。由于FPC的值越高表示数据分布的描述越好,DEPCOMM选择具有最大FPC的cluster的数量|C|,即 ∣ C ∣ = a r g m a x ( F ( ∣ C ∣ )) |C|=argmax(F(|C|)) ∣C∣=argmax(F(∣C∣))。
资源节点关联。给定一个资源节点 r r r和一个流程节点 p p p,如果它们通过一条边连接,那么 v v v与 p p p所属的社区相关联。如果一个资源结点与来自不同社区的多个流程结点连接,那么这个资源结点是一个重叠结点,我们创建资源结点的副本,并为每个社区分配一个副本。
D.社区压缩
基于进程的模式
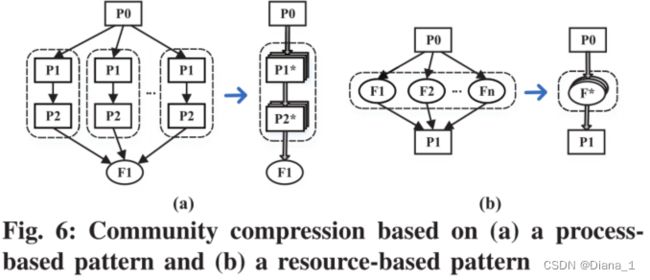
基于进程的模式描述了产生同一组进程以处理某些资源的重复活动。图6(a)显示了一个示例:进程P0重复生成名为P1和P2的子进程以写入文件F1。但保持重复的活动并不能为安全分析师提供额外的价值。因此,DEPCOMM旨在识别这种模式并合并重复的节点和边缘。该进程包括以下四个步骤:
- 步骤1:构建进程谱系树。给定一个以进程为中心的社区,DEPCOMM通过遍历社区内的进程节点,从社区的主进程节点构建一棵进程索引树。该树可以表明进程节点的派生子进程节点的行为。
- 步骤2:与访问的资源关联。捕获进程谱系树中每个进程的资源使用情况,DEPCOMM检查社区内的事件,以确定这些进程访问的资源。具体而言,每个进程都与所访问资源的代表性属性(即,文件的文件名和网络连接的IP)以及这些资源上的操作类型相关联。
- 步骤3:基于进程的模式挖掘。进程谱系树中基于进程的模式是重复的自下而上的子树[67],其中自底向上的子树包括节点及其所有后代。特别地,DEPCOMM使用进程谱系树为每个进程节点生成子树。然后,DEPCOMM通过在子树中附加进程节点的相关资源属性,将子树编码为字符串,并标识相同的字符串(即重复子树)。
- 步骤4:基于模式的压缩。所识别的重复子树可以具有不同的父节点。为了确保子树与其父节点之间的依赖关系不被破坏,DEPCOMM仅选择具有相同父节点的重复子树,并将所选子树合并为一个子树。合并子树中每个节点和边的属性是原始节点和边属性的并集。
基于资源的模式
资源模式标识由同一组进程重复访问的资源。为了识别这种模式,DEPCOMM首先将进程与其访问的资源相关联,然后搜索每个资源以识别重复访问。基于找到的模式,将资源节点合并为一个节点,合并节点的属性是原始资源节点的属性的并集。
E. 社区摘要
对于每个社区,DEPCOMM生成一个由三部分组成的摘要:主进程、时间跨度和排名靠前的InfoPaths,如图2所示。主进程表示社区中系统活动的根进程。使用社区中所有事件中的最早开始时间和最晚结束时间(即, = min e i ∈ c { e i . s t } =\min _{e_i \in c}\left\{e_i . s t\right\} =minei∈c{ei.st} and c.et = = = max e i ∈ c { e i . e t } ) \left.\max _{e_i \in c}\left\{e_i . e t\right\}\right) maxei∈c{ei.et}))来计算时间跨度,这为跟踪某些活动提供了时间信息。InfoPaths表示社区中从输入到输出的信息流,表示社区中的主要活动。
信息路径提取。给定一个以流程为中心的社区,DEPCOMM首先确定其输入和输出节点。输入节点表示社区的传入信息流,社区间边缘的目标节点(例如,图1中C3的leak和…/analysis.txt)和具有传出边缘的网络节点(例如图1中C1的xxx->xxx,表示社区从中接收文件的外部IP)。对于没有输入边的社区,我们选择主进程作为输入节点。一个输出节点代表一个社区的传出信息流,它是一个连接两个社区边的源节点(如图1中C2的 leak),有入边的节点(如图1中C3的xxx-> xxx,表示社区向其发送文件的外部IP),以及POI节点(因为一条路径的终点也是为了抵达POI节点)。然后,对于每一对输入和输出节点(从输入到输出会有多个节点,采用DFS来搜索),DEPCOMM使用深度优先搜索(DFS)算法寻找没有重复节点的最长路径作为InfoPath。这样的路径通常比较短的路径包含更多的活动信息。
信息路径优先级。一个社区通常包含多个输入和输出,因此具有多个InfoPath。DEPCOMM根据InfoPaths代表主要活动(例如攻击行为)的可能性对其进行优先级排序。InfoPath的优先级分数 P k : v 0 → v 1 → ⋯ → v ∣ P k ∣ − 1 P_k: v_0 \rightarrow v_1 \rightarrow \cdots \rightarrow v_{\left|P_k\right|-1} Pk:v0→v1→⋯→v∣Pk∣−1,基于以下四个关键特征计算:
-
POI 事件( f p o i fpoi fpoi). 包含POI事件的InfoPath与攻击直接相关。因此,如果InfoPath包含POI事件, f p o i fpoi fpoi为1,否则为0.
-
输入/输出类型( f i o t f_{iot} fiot)。由于进程驱动攻击执行,安全分析人员更有可能通过进程节点找到另一个攻击阶段。例如,在图1中,可以通过输入进程节点 leak 来跟踪从C3到C2的攻击,但不能通过输入文件节点…/analysis.txt。因此,fiot 赋予输入或输出节点为进程的InfoPath更高的优先级:
f i o t = 1 2 ( δ ( v 0 ) + δ ( v ∣ P k ∣ − 1 ) ) f_{i o t}=\frac{1}{2}\left(\delta\left(v_0\right)+\delta\left(v_{\left|P_k\right|-1}\right)\right) fiot=21(δ(v0)+δ(v∣Pk∣−1))
如果 v i v_i vi 是进程,则 δ ( v i ) \delta\left(v_i\right) δ(vi) 是1 ,否则为0. -
事件唯一性( f u n i f_{uni} funi)。出现在较少社区中的文件事件更有可能代表社区中的主要活动,例如事件vim write/analysis.txt只出现在C4中,而在不同社区中频繁观察到的文件事件通常表示后台运行的无关历史记录任务。基于这一观察,我们设计了 f u n i f_{uni} funi特征来衡量文件事件的唯一性:
f u n i = 1 ∣ Evt ( P k ) ∣ ∑ e i ∈ P k , e i ∈ E v t f 1 ∣ Comm ( e i ) ∣ f_{u n i}=\frac{1}{\left|\operatorname{Evt}\left(P_k\right)\right|} \sum_{e_i \in P_k, e_i \in E v t_f} \frac{1}{\left|\operatorname{Comm}\left(e_i\right)\right|} funi=∣Evt(Pk)∣1ei∈Pk,ei∈Evtf∑∣Comm(ei)∣1
其中 ∣ Evt ( P k ) ∣ \left|\operatorname{Evt}\left(P_k\right)\right| ∣Evt(Pk)∣表示 P k P_k Pk中文件事件的数量, e i ∈ E v t f e_i \in E v t_f ei∈Evtf 表示文件事件,而 ∣ Comm ( e i ) ∣ \left|\operatorname{Comm}\left(e_i\right)\right| ∣Comm(ei)∣ 表示 e i e_i ei 发生的社区的数量。当 ∣ Comm ( e i ) ∣ \left|\operatorname{Comm}\left(e_i\right)\right| ∣Comm(ei)∣较小时, f uni f_{\text {uni }} funi 的值较大。 -
时间跨度( f s p a n f_{span} fspan)。直观地说,时间跨度与社区时间跨度相似的InfoPath更有可能代表社区中的主要活动。我们设计功能fspan来模拟这种直觉:
f span = e ( v ∣ P k ∣ − 2 , v ∣ P k ∣ − 1 ) . e t − e ( v 0 , v 1 ) . s t c.et − c.st f_{\text {span }}=\frac{e\left(v_{\left|P_k\right|-2}, v_{\left|P_k\right|-1}\right) . e t-e\left(v_0, v_1\right) . s t}{\text { c.et }-\text { c.st }} fspan = c.et − c.st e(v∣Pk∣−2,v∣Pk∣−1).et−e(v0,v1).st
其中分子表示InfoPath的时间跨度,分母表示社区的时间跨度。
基于这些特征,我们通过给每个特征赋予相等的权重来计算Pk的优先级分数。根据分配的优先级分数,我们对InfoPaths进行排序,并选择前n个路径作为摘要,其中安全分析师可以灵活选择n的值