电商交易数据分析
一.数据集介绍
数据来源于自kaggle的某电商真实交易数据,经过后期处理,不会造成任何隐私的泄露。该公司主要销售礼品,大部分出售对象是面向个人。
二.数据集字段介绍
数据包含104557条数据,10个字段,字段内容为:
orderId:订单编号,订单编号均为数字。
userId:客户编号,每个客户编号由数字组成。
productId:产品编号,由整数组成。
cityId:客户所在城市编号。
price:商品价格。
payMoney:客户最终支付金额。
channelId:购买渠道编号。
deviceType:客户下单的设备类型。
createTime:订单下单时间。
payTime:客户支付时间。
三.分析内容
分析数据可以从两方面开始考虑,一个是维度,一个是指标,维度可以看做x轴,指标可以看成是y轴,同一个维度可以分析多个指标,同一个维度也可以做降维升维。
比如:分析商品维度可以通过价格、销售额以及销量这几个指标进行分析,而城市维度也可以通过销售额和销量这两个指标进行分析、渠道维度可以通过订单数、成交量等指标进行分析。
四. 数据处理分析过程
1.数据清洗
利用Python语言进行数据分析,开发工具有Jupyter Notebook。
导入加载数据分析需要使用的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
加载数据,加载之前先用文本编辑器看下数据的格式,首行是什么,分隔符是什么等,加载完查看前五条数据
df = pd.read_csv('./order_info_2016.csv', index_col='id')
df.head()

加载好数据之后,第一步先分别使用describe和info方法看下数据的大概分布,这两个方法放到两个cell中
df.describe()
df.info()
查看完数据集的基本信息后,接下来就可以进行数据的清洗
(1)orderId
首先对orderId进行处理,因为orderId在一个系统里是唯一值,所以这里需要先看下有没有重复值
df.orderId.unique().size
df.orderId.size
执行完以上代码得到结果为104530和104557,可以看出orderId列存在27个重复值,但如果有重复值,我们一般最后处理,因为其他的列可能会影响到删除哪一条重复的记录,因此先处理其他的列
(2)userId
userId我们只要从上面的describe和info看下值是不是在正常范围就行了,对于订单数据,一个用户有可能有多个订单,重复值是合理的
(3)productId
productId最小值是0,先来看下值为0的记录数量
df.productId[(df.productId == 0)].size
得到结果为177条记录,数量不多,可能是因为商品的上架下架引起的,处理完其他值的时候我们把这些删掉
(4)cityId
cityId类似于userId,值都在正常范围,不需要处理
df.cityId.unique().size
(5)price
price没有空值,且都大于0,注意单位是分,我们把它变成元
df.price = df.price / 100
(6)payMoney
展示负值的记录
df[df.payMoney < 0]
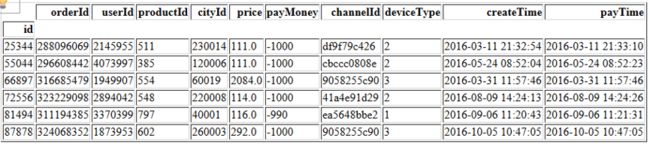
payMoney有负值,我们下单不可能是负值,所以这里对于负值的记录要删除掉
df.drop(index=df[df.payMoney < 0].index, inplace=True)
将分转换成元
df.payMoney = df.payMoney / 100
(7)channelId
channelId根据info的结果,有些null的数据,可能是端的bug等原因,在下单的时候没有传channelId字段,数据量大的时候,删掉少量的null记录不会影响统计结果,这里我们直接删除,展示null记录
df[df.channelId.isnull()]

将null记录删除
df.drop(index=df[df.channelId.isnull()].index, inplace=True)
(8)deviceType
deviceType的取值分别是1:PC,2:Android,3:iPhone,4:Wap,5:other,没有问题,不需要处理
(9)createTime和payTime
和上述方法一样,可以发现createTime和payTime都没有null,不过我们是要统计2016年的数据,所以把非2016年的删掉,payTime类似,这里只按创建订单的时间算,就不处理了,先把createTime和payTime转换成datetime格式
df.createTime = pd.to_datetime(df.createTime)
df.payTime = pd.to_datetime(df.payTime)
import datetime
startTime = datetime.datetime(2016, 1, 1)
endTime = datetime.datetime(2016, 12, 31, 23, 59, 59)
# 有16年之前的数据,需要删掉
df[df.createTime < startTime]
df.drop(index=df[df.createTime < startTime].index, inplace=True)
df[df.createTime < startTime]
# payTime早于createTime的也需要删掉
df.drop(index=df[df.createTime > df.payTime].index, inplace=True)
回过头来我们把orderId重复的记录删掉
df.orderId.unique().size
df.orderId.size
df.drop(index=df[df.orderId.duplicated()].index, inplace=True)
df.orderId.unique().size
把productId为0的也删除掉
df.drop(index=df[df.productId==0].index, inplace=True)
数据清洗完毕,可以开始分析了
2.数据分析
一般都是先看下数据的总体情况总体情况,总订单数,总下单用户,总销售额,有流水的商品数
print(df.orderId.count())
print(df.userId.unique().size)
print(df.payMoney.sum()/100)
print(df.productId.unique().size)

分析数据可以从两方面开始考虑,一个是维度,一个是指标,维度可以看做x轴,指标可以看成是y轴,同一个维度可以分析多个指标,同一个维度也可以做降维升维。
(1)销量分析
按照商品的productId,先看下商品销量的前十和后十个
productId_orderCount = df.groupby('productId').count()['orderId'].sort_values(ascending=False)
print(productId_orderCount.head(10))
print(productId_orderCount.tail(10))

(2)销售额分析
看下销售额前十和倒数前十的商品
productId_turnover = df.groupby('productId').sum()['payMoney'].sort_values(ascending=False)
print(productId_turnover.head(10))
print(productId_turnover.tail(10))

根据以上商品的排名,可以决定,对销售额排名前十的商品可以增加库存,增加推广成本等,而对于销售额排名倒数前十的商品,则需要进行调研分析,确定商品销售额低下的原因,采取一定措施进行商品销售额的提升,更可以适当减少这些商品的库存,以减少损失。
看下销量和销售额最后100个的交集,如果销量和销售额都不达标,这些商品需要看看是不是要优化或者下架
problem_productIds = productId_turnover.tail(100).index.intersection(productId_orderCount.tail(100).index)
problem_productIds

得出以上商品均是销量和销售额都不达标的商品,这些商品则需要尽快采取优化或者下架处理,以免造成亏损,还需要根据实际情况调整此类商品的库存情况
(3)城市分析
城市的分析可以和商品维度类似,对每个城市的订单数量以及销售额进行分析
cityId_payMoney = df.groupby('cityId').sum()['payMoney'].sort_values(ascending=False)
cityId_payMoney
cityId_orderCount = df.groupby('cityId').count()['orderId'].sort_values(ascending=False)
cityId_orderCount
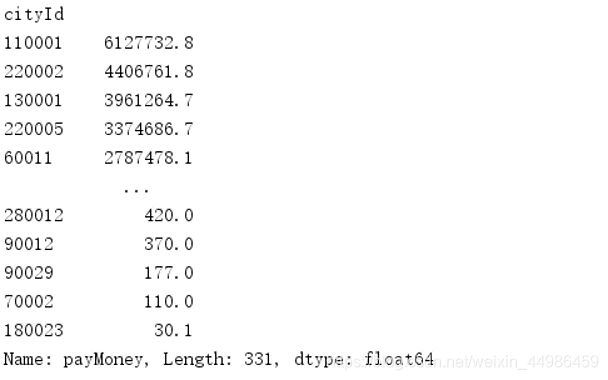

通过以上结果,可以知道编号为11001的城市购买力最高,因此可以得出该城市人均收入最高,因此,我们应该针对该城市开展更多的优惠活动或者线下活动,以留住该城市的顾客作为主要发展城市
(4)价格分析
对于价格,可以看下所有商品价格的分布,这样可以知道什么价格的商品卖的最好,根据商品最小值和最大值确定价格区间,然后按照100的区间取分桶,价格是分,这里为了好看把他转成元
bins = np.arange(0, 7500, 100)
pd.cut(df.price, bins).value_counts()

根据以上商品价格的分布可以描绘商品价格分布直方图
plt.figure(figsize=(16, 16))
plt.hist(df['price'], bins)

从直方图可以观察到,大部分商品价格都处于0-1000的范围
price_cut_count = pd.cut(df.price, bins).value_counts()
zero_cut_result = (price_cut_count == 0)
zero_cut_result[zero_cut_result.values].index
![]()
从上图可以看出,很多价格区间没有商品,如果有竞争对手的数据,可以看看是否需要补商品填充对应的价格区间
(5)渠道的分析
渠道的分析类似于productId,可以给出成交量最多的渠道,订单数最多的渠道等,渠道很多时候是需要花钱买流量的,所以还需要根据渠道的盈利情况和渠道成本进行综合比较,同时也可以渠道和商品等多个维度综合分析,看看不同的卖的最好的商品是否相同
t1 = df.groupby('deviceType').sum()['orderId'].sort_values(ascending=False)

可以看出成交量最多的,订单数最多的渠道是安卓手机
(6)下单时间分析
a.按小时分析
df['orderHour'] = df.createTime.dt.hour
df.groupby('orderHour').count()['orderId'].plot()
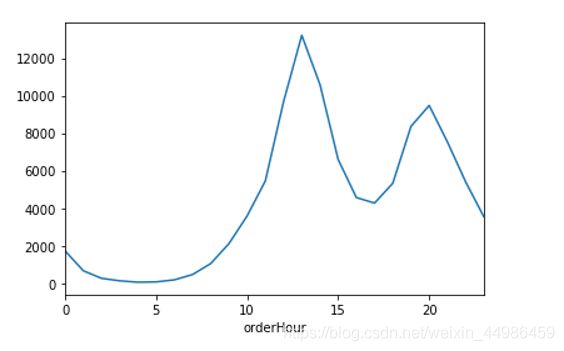
从上图按小时的下单量分布可以得出,中午12、 13、14点下单比较多,应该是午休的时候,然后是晚上20点左右,晚上20点左右几乎是所有互联网产品的一个高峰,下单高峰要注意网站的稳定性、可用性,也可以按时间做推广
b.按星期分析
按照星期来看,周六下单最多,其次是周四周五
df['orderWeek'] = df.createTime.dt.dayofweek
df.groupby('orderWeek').count()['orderId']

c.下单后多久支付
def get_seconds(x):
return x.total_seconds()
df['payDelta'] = (df['payTime'] - df['createTime']).apply(get_seconds)
bins = [0, 50, 100, 1000, 10000, 100000]
pd.cut(df.payDelta, bins).value_counts()
pd.cut(df.payDelta, bins).value_counts().plot(kind='pie', autopct='%d%%', shadow=True, figsize=(10, 10))
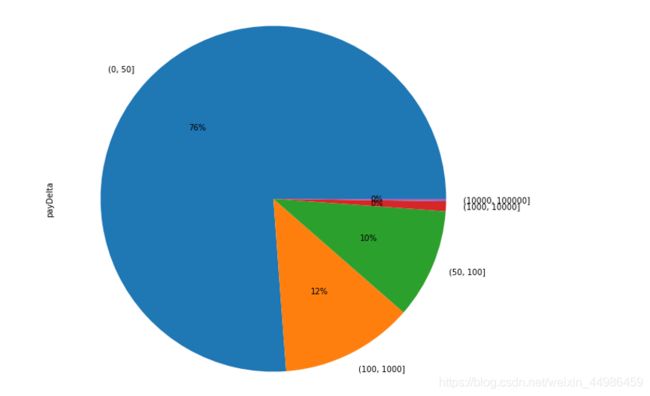
从饼图中可以看出,绝大部分都在十几分钟之内支付完成,说明用户基本很少犹豫,购买的目的性很强
五、总结
本案例主要对电商交易数据进行了一些常见的分析,包括了商品ID、商品价格、设备类型、下单时间等多个维度。因为不是多年的数据,因此无法做同比分析,而且数据不是企业内部的全部数据,所以原数据并没有出现像加购转化漏斗、网站流量等电商数据分析中常见的指标。不过,从仅有的数据来看,分析的结果基本符合我们的生活习惯,例如手机购物占多数、午休和晚饭后的休闲时间达到购物高峰期等等。