电商系统架构设计系列(八):订单数据越来越多,数据库越来越慢该怎么办?
上篇文章中,我给你留了一个思考题:订单数据越来越多,数据库越来越慢该怎么办?
今天这篇文章,我们来聊一下如何应对数据的持续增长,特别是像订单数据这种会随着时间一直累积的数据。
引言
为什么数据量越大数据库就越慢?你得理解这里面的根本原因。
我们知道,无论是“增删改查”哪个操作,其实都是查找问题,因为你都得先找到数据才能对数据做操作。那存储系统性能问题,其实就是查找快慢的问题。
无论是什么样的存储系统,一次查询所耗费的时间,都取决于两个因素:
- 查找的时间复杂度
- 数据总量
这也是为什么大厂面试时总喜欢问“时间复杂度”相关问题的原因。
查找的时间复杂度又取决于两个因素:
- 查找算法
- 存储数据的数据结构
你看,这两个知识点也是面试问题中的常客吧?所以人家面试官并不是非要问你一些用不上的问题来为难你,这些知识点真的不是用不上,而是你不知道怎么用。
对于我们大多数做业务的系统,用的都是现成的数据库,数据的存储结构和查找算法都是由数据库来实现的,业务系统基本没法去改变它。比如说,MySQL 的 InnoDB 存储引擎,它的存储结构是 B+ 树,查找算法大多就是树的查找,查找的时间复杂度就是 O(log n),这些都是固定的。那我们唯一能改变的,就是数据总量了。
所以,解决海量数据导致存储系统慢的问题,思想非常简单,就是一个“拆”字,把一大坨数据拆分成 N 个小坨,学名叫“分片(Shard)”。拆开之后,每个分片里的数据就没那么多了,然后让查找尽量落在某一个分片上,这样来提升查找性能。
所有分布式存储系统解决海量数据查找问题都是遵循的这个思想,但是光有思想还不够,还需要落地,下面我们就来说下如何拆分数据的问题。
存档历史订单数据提升查询性能
我们在开发业务系统的时候,很多数据都是具备时间属性的,并且随着系统运行,累计增长越来越多,数据量达到一定程度就会越来越慢,比如说电商中的订单数据,就是这种情况。按照我们刚刚说的思想,这个时候就需要拆分数据了。
我们的订单数据一般都是保存在 MySQL 中的订单表里面,说到拆分 MySQL 的表,可能大多数人的第一反应都是“分库分表”,别着急,咱现在的数据量还没到非得分库分表那一步呢。如果归档能解决问题,就不要分库分表。(下一篇文章我们会聊聊分库分表,也可阅读我的另一篇文章:分库分表方案汇总)。
当单表的订单数据太多,多到影响性能的时候,首选的方案是,归档历史订单。
所谓归档,其实也是一种拆分数据的策略。简单地说,就是把大量的历史订单移到另外一张历史订单表中。为什么这么做呢?因为像订单这类具有时间属性的数据,都存在热尾效应。大多数情况下访问的都是最近的数据,但订单表里面大量的数据都是不怎么常用的老数据。
因为新数据只占数据总量中很少的一部分,所以把新老数据分开之后,新数据的数据量就会少很多,查询速度也就会快很多。老数据虽然和之前比起来没少多少,查询速度提升不明显,但是,因为老数据很少会被访问到,所以慢一点儿也问题不大。
这样拆分的另外一个好处是,拆分订单时,需要改动的代码非常少。大部分对订单表的操作都是在订单完成之前,这些业务逻辑都是完全不用修改的。即使像退货退款这类订单完成后的操作,也是有时限的,那这些业务逻辑也不需要修改,原来该怎么操作订单表还怎么操作。
基本上只有查询统计类的功能,会查到历史订单,这些需要稍微做一些调整,按照时间,选择去订单表还是历史订单表查询就可以了。很多电商大厂在它逐步发展壮大的过程中,都用这种订单拆分的方案撑了好多年。你可能还有印象,几年前你在京东、淘宝查自己的订单时,都有一个查“三个月前订单”的选项,其实就是查订单历史表。
归档历史订单,大致的流程是这样的:
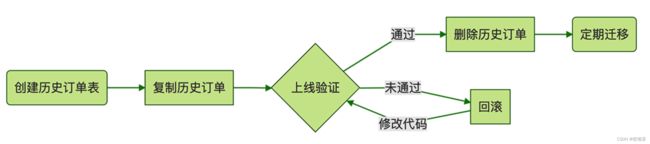
- 首先我们需要创建一个和订单表结构一模一样的历史订单表;
- 然后,把订单表中的历史订单数据分批查出来,插入到历史订单表中去。这个过程你怎么实现都可以,用存储过程、写个脚本或者写个导数据的小程序都行,用你最熟悉的方法就行。如果你的数据库已经做了主从分离,那最好是去从库查询订单,再写到主库的历史订单表中去,这样对主库的压力会小一点儿。
- 现在,订单表和历史订单表都有历史订单数据,先不要着急去删除订单表中的数据,你应该测试和上线支持历史订单表的新版本代码。因为两个表都有历史订单,所以现在这个数据库可以支持新旧两个版本的代码,如果新版本的代码有 Bug,你还可以立刻回滚到旧版本,不至于影响线上业务。
- 等新版本代码上线并验证无误之后,就可以删除订单表中的历史订单数据了。
- 最后,还需要上线一个迁移数据的程序或者脚本,定期把过期的订单从订单表搬到历史订单表中去。
类似于订单商品表这类订单的相关的子表,也是需要按照同样的方式归档到各自的历史表中,由于它们都是用订单 ID 作为外键来关联到订单主表的,随着订单主表中的订单一起归档就可以了。
这个过程中,我们要注意的问题是,要做到对线上业务的影响尽量的小。迁移这么大量的数据,或多或少都会影响数据库的性能,你应该尽量放在闲时去迁移,迁移之前一定做好备份,这样如果不小心误操作了,也能用备份来恢复。
如何批量删除大量数据?
这里面还有一个很重要的细节问题:如何从订单表中删除已经迁走的历史订单数据?我们直接执行一个删除历史订单的 SQL 行不行?像这样删除三个月前的订单:
delete from orders
where timestamp < SUBDATE(CURDATE(),INTERVAL 3 month);大概率你会遇到错误,提示删除失败,因为需要删除的数据量太大了,所以需要分批删除。比如说我们每批删除 1000 条记录,那分批删除的 SQL 可以这样写:
delete from orders
where timestamp < SUBDATE(CURDATE(),INTERVAL 3 month)
order by id limit 1000;执行删除语句的时候,最好在每次删除之间停顿一会儿,避免给数据库造成太大的压力。上面这个删除语句已经可以用了,反复执行这个 SQL,直到全部历史订单都被删除,是可以完成删除任务的。
但是这个 SQL 还有优化空间,它每执行一次,都要先去 timestamp 对应的索引上找出符合条件的记录,然后再把这些记录按照订单 ID 排序,之后删除前 1000 条记录。
其实没有必要每次都按照 timestamp 比较订单,所以我们可以先通过一次查询,找到符合条件的历史订单中最大的那个订单 ID,然后在删除语句中把删除的条件转换成按主键删除。
select max(id) from orders
where timestamp < SUBDATE(CURDATE(),INTERVAL 3 month);
delete from orders
where id <= ?
order by id limit 1000;这样每次删除的时候,由于条件变成了主键比较,在 MySQL 的 InnoDB 存储引擎中,表数据结构就是按照主键组织的一颗 B+ 树,而 B+ 树本身就是有序的,所以不仅查找非常快,也不需要再进行额外的排序操作了。当然这样做的前提条件是订单 ID 必须和订单时间正相关才行,大多数订单 ID 的生成规则都可以满足这个条件,所以问题不大。
然后我们再说一下,为什么在删除语句中非得加一个排序呢?因为按 ID 排序后,我们每批删除的记录,基本都是 ID 连续的一批记录,由于 B+ 树的有序性,这些 ID 相近的记录,在磁盘的物理文件上,大致也是放在一起的,这样删除效率会比较高,也便于 MySQL 回收页。
大量的历史订单数据删除完成之后,如果你检查一下 MySQL 占用的磁盘空间,你会发现它占用的磁盘空间并没有变小,这是什么原因呢?这也是和 InnoDB 的物理存储结构有关系。
虽然逻辑上每个表是一颗 B+ 树,但是物理上,每条记录都是存放在磁盘文件中的,这些记录通过一些位置指针来组织成一颗 B+ 树。当 MySQL 删除一条记录的时候,只能是找到记录所在的文件中位置,然后把文件的这块区域标记为空闲,然后再修改 B+ 树中相关的一些指针,完成删除。其实那条被删除的记录还是躺在那个文件的那个位置,所以并不会释放磁盘空间。
这么做也是没有办法的办法,因为文件就是一段连续的二进制字节,类似于数组,它不支持从文件中间删除一部分数据。如果非要这么删除,只能是把这个位置之后的所有数据往前挪,这样等于是要移动大量数据,非常非常慢。所以,删除的时候,只能是标记一下,并不真正删除,后续写入新数据的时候再重用这块儿空间。
理解了这个原理,你就很容易知道,不仅是 MySQL,很多其他的数据库都会有类似的问题。这个问题也没什么特别好的办法解决,磁盘空间足够的话,就这样吧,至少数据删了,查询速度也快了,基本上是达到了目的。
如果说我们数据库的磁盘空间很紧张,非要把这部分磁盘空间释放出来,可以执行一次 OPTIMIZE TABLE 释放存储空间。对于 InnoDB 来说,执行 OPTIMIZE TABLE 实际上就是把这个表重建一遍,执行过程中会一直锁表,也就是说这个时候下单都会被卡住,这个是需要注意的。另外,这么优化有个前提条件,MySQL 的配置必须是每个表独立一个表空间(innodb_file_per_table = ON),如果所有表都是放在一起的,执行 OPTIMIZE TABLE 也不会释放磁盘空间。
重建表的过程中,索引也会重建,这样表数据和索引数据都会更紧凑,不仅占用磁盘空间更小,查询效率也会有提升。那对于频繁插入删除大量数据的这种表,如果能接受锁表,定期执行 OPTIMIZE TABLE 是非常有必要的。
如果说,我们的系统可以接受暂时停服,最快的方法是这样的:直接新建一个临时订单表,然后把当前订单复制到临时订单表中,再把旧的订单表改名,最后把临时订单表的表名改成正式订单表。这样,相当于我们手工把订单表重建了一次,但是,不需要漫长的删除历史订单的过程了。我把执行过程的 SQL 放在下面供你参考:
-- 新建一个临时订单表
create table orders_temp like orders;
-- 把当前订单复制到临时订单表中
insert into orders_temp
select * from orders
where timestamp >= SUBDATE(CURDATE(),INTERVAL 3 month);
-- 修改替换表名
rename table orders to orders_to_be_droppd, orders_temp to orders;
-- 删除旧表
drop table orders_to_be_dropp总结
对于订单这类具有时间属性的数据,会随时间累积,数据量越来越多,为了提升查询性能需要对数据进行拆分,首选的拆分方法是把旧数据归档到历史表中去。这种拆分方法能起到很好的效果,更重要的是对系统的改动小,升级成本低。
在迁移历史数据过程中,如果可以停服,最快的方式是重建一张新的订单表,然后把三个月内的订单数据复制到新订单表中,再通过修改表名让新的订单表生效。如果只能在线迁移,那需要分批迭代删除历史订单数据,删除的时候注意控制删除节奏,避免给线上数据库造成太大压力。
最后,再提醒一下:线上数据操作非常危险,在操作之前一定要做好数据备份。
感谢阅读,如果你觉得这篇文章对你有一些启发,也欢迎把它分享给你的朋友。
思考题
确实需要分库分表,该如何设计?要考虑哪些问题?
期待、欢迎你留言或在线联系,与我一起讨论交流,“一起学习,一起成长”。
上一篇文章
电商系统架构设计系列(七):如何构建一个电商的商品搜索系统?
推荐阅读
- 技术破局,业绩狂飙十倍:亿级电商平台重构大揭秘
- 当我们聊高并发时,到底是在聊什么?如何真正地掌握高并发设计能力?
- 微服务架构实战 - 我的经验分享总结2019(系统架构师)架构演进过程-从信息流架构到电商中台架构
系列分享
- Elasticsearch教程
- 微服务架构实战
- 架构思维成长系列
- 电商系统架构设计系列
------------------------------------------------------
------------------------------------------------------
我的CSDN主页
关于我(个人域名,更多我的信息)
我的开源项目集Github
期望和大家 一起学习,一起成长,共勉,O(∩_∩)O谢谢
如果你有任何建议,或想学习的知识,可与我一起讨论交流
欢迎交流问题,可加个人QQ 469580884,
或者,加我的群号 751925591,一起探讨交流问题
不讲虚的,只做实干家
Talk is cheap,show me the code