Rail-5k:一个用于轨道表面缺陷检测的真实数据集
Rail-5k:一个用于轨道表面缺陷检测的真实数据集
文章目录
- Rail-5k:一个用于轨道表面缺陷检测的真实数据集
-
- 摘要
- 1 介绍
- 2 相关工作
-
- 2.1自然图像数据集
- 2.2合成缺陷数据集
- 2.3铁路缺陷数据集
- 3 轨道5k数据集
-
- 3.1轨道图像采集
- 3.2 细粒度的类定义和实例级注释
- 3.3 数据集分割
- 4标注统计
-
- 4.1类分布
- 4.2分边框的尺寸及纵横比
- 4.3对象位置
- 5.铁路5k数据集的试点研究
-
- 5.1检测基准
- 5.2裂缝基准
- 5.3 半监督学习的基准测试
- 6 结论


文章地址: https://arxiv.org/abs/2106.14366
视频地址: https://www.bilibili.com/video/BV18V411p7AT
摘要
本文提出了Rail-5k数据集,用于对现实应用场景中视觉算法性能的基准测试,即轨道表面缺陷检测任务。我们从中国各地的铁路中收集了超过5000张高质量的图像,并在铁路专家的帮助下注释了1100张图像,以识别最常见的13种铁路缺陷类型。该数据集可以用于两种设置,两者都有独特的挑战,第一个是使用1k+标记图像进行训练的全监督设置,细粒度性质和缺陷类的长尾分布使得视觉算法难以处理。第二种是由4k个未标记图像促进的半监督学习设置,这4k个图像不包含可能的图像损坏和域位移,这是以前的半监督学习方法不容易解决的。我们相信我们的数据集可以是评估视觉算法的鲁棒性和可靠性的一个有价值的基准。
1 介绍
ImageNet[3]等大规模注释数据集的引入大大加快了基于深度学习的视觉算法[10]的发展。在ImageNet[3]上预训练的深度学习算法也被证明可以有效地在领域和任务之间进行转移,如目标检测[21]、农业[23,2]或医学图像分析[13]。
铁路作为人类生活的重要基础设施,其维护和现状分析具有现实世界的经济和以安全为中心的价值。然而,目前铁路领域的数据集局限于数据集的大小[7],图像质量[5,6,7],以及标注类型[6,7]。目前可用数据集的大小和质量还没有完全地好,以支持深度学习方法的训练。
我们的数据集有足够从真实世界的铁路中捕获的高质量图像,使深度训练模型成为可能。除了带有1.1k个图像的标记集外,我们还提供了一个未标记的4k个图像集来实现半监督设置。我们的数据集的几个独特的特征也对视觉算法提出了新的挑战。第一个挑战是在外部数据集中呈现的类的长尾分布,最大多数类与最少数类的不平衡比高达40.98,结果表明,长尾分布将极大地损害学习模型[18,9]的性能。除了长尾类分布在标记数据集,未标记的图像集也构成了一个困难的场景半监督缺陷检测,半监督对象检测是一个相对较新的任务,很少最近的工作[8,22],以前的方法通常假设未标记集也策划。然而,在我们的案例中,未标记的集是未被多个未知的图像损坏和看不见的标记集中的对象所管理的。鉴于这些独特的特性,我们认为我们提出的数据集不仅有助于轨道表面缺陷检测算法的开发,而且还可以开发一个更健壮的视觉模型,以处理未标记集中的长尾分布和可能的损坏。
2 相关工作
传统的检查方法,如主观人工观察、抽样检查,都是定性或补偿的方法,不能为整个线路的智能维护提供数字和自动的决策依据。我们的数据集主要关注缺陷检测的任务,我们在本节总结了相关文献。
2.1自然图像数据集
表面缺陷检测任务与视觉算法中的目标检测任务最为相关。视觉物体检测的常见基准是使用自然图像构建的,如PascalVOC[4]和MS-COCO[17]。这些数据集在类分布方面大多是平衡的。LVIS[9]数据集提出了一个更大的具有长尾类分布的图像集合。我们提出的数据集对于类也有一个长尾分布。与一般的自然图像数据集不同,由于铁路图像的性质,我们的数据集也提供了细粒度的类定义。
2.2合成缺陷数据集
还有许多数据集集中专注于测试深度学习模型在域位移和图像损坏下的鲁棒性,如ImageNet-C[11]、CityScapes-C[19]和COCO-C[19]。然而,这些数据集中的损坏是合成的,是使用图像处理技术生成的。此外,它们主要被用作测试鲁棒性的测试集,而不是训练集。在我们的数据集中,标记的数据集有很好的管理,但未标记的数据集包含各种现实世界的缺陷,从而对半监督学习方法提出了新的挑战。
2.3铁路缺陷数据集
在铁路工程领域,有一些关注铁路缺陷[24]的分类和检测的数据集。至于铁路工程,图像大多以地图集的形式供手工参考。有铁路场景的分类和检测[24]数据集,以及超声波检测数据集[12]。但仍然缺乏关于铁路表面缺陷的真实数据集。法吉赫-鲁希等人[5]收集并标记6个缺陷类别中的100x50分辨率的图像。RSDDs数据集[7]包含两种分割掩码铁路中的195张灰度图像。冯等人[6]收集数千张图像,并注释带区域的波纹、腐蚀和剥离。以上数据集均是由低分辨率和粗粒度注释的高速线性扫描相机收集的。因此,它们都不能驱动现实世界中鲁棒深度学习算法的训练。
3 轨道5k数据集
3.1轨道图像采集
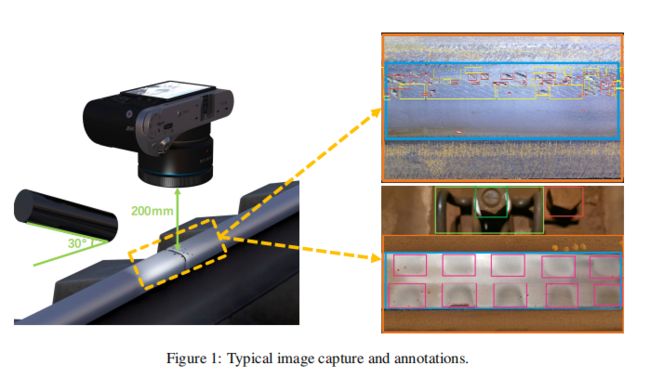
铁路表面缺陷主要是由铁路系统高速段车轮恒定载荷下的金属摩擦造成的。Rail-5k数据集中的轨道图像是由安装在铁路沿线的检查车上的专门摄像机拍摄的,使镜头垂直距轨道表面200毫米,垂直向下聚焦。我们排除了在铁路表面有阴影或过度暴露的图像,供铁路专家贴上标签。我们收集了1100张RGB图像的注释,分辨率为3648×2736像素,包括隧道、高架桥、直线、曲线线、内外轨道、磨削或磨削等场景。图1显示了我们收集图像的典型铁路路段的地图,每个点代表一个图像。我们还从轨道表面的未经整理的图像中收集了3k张图像。这些图像包含标记集中未知的损坏和不可见的对象。图3显示了未标记集中的一些典型图像。
综上所述,我们的数据集包含两部分数据,第一部分是有1k标记图像的标记子集,第二部分是有3k图像的未标记子集。因此,我们的数据集可以同时支持有监督和半监督的学习设置。


3.2 细粒度的类定义和实例级注释
我们的数据集中的注释由10位铁路专家标记,每个标记的图像至少由3位专家检查。基于专家知识和铁路标准,我们使用细粒度的类定义和实例级注释范式进行铁路缺陷检测。标签原理列于表3中。

注意,裂纹区域是尖锐而薄的物体,没有清晰的边缘边界,我们用分割掩模进行注释。
3.3 数据集分割
我们将1100张标记图像中的20%随机分割到测试集,其余的图像用作监督设置中的训练集。对于半监督设置,我们使用相同的测试集来评估性能以进行比较。
4标注统计
在本节中,我们将展示数据集的统计数据。统计数据分为三个方面,即类间的图像和边界框分布、边界框尺寸和长宽比,以及标注边界框的中心点。
4.1类分布
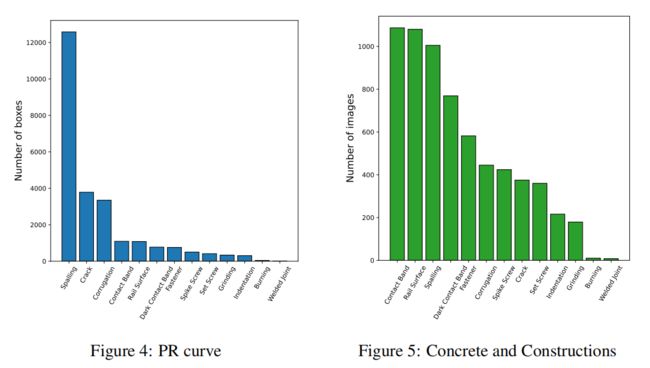
图4 显示了包含每个类的图像和注释的数量。燃烧和焊接接头在我们的实验和基准测试中被忽略了,因为它们的外观很少。与最多数类与最少数类之间的边界框数之间的不平衡比为40.98,与图像数之间的不平衡比为6.07。
4.2分边框的尺寸及纵横比
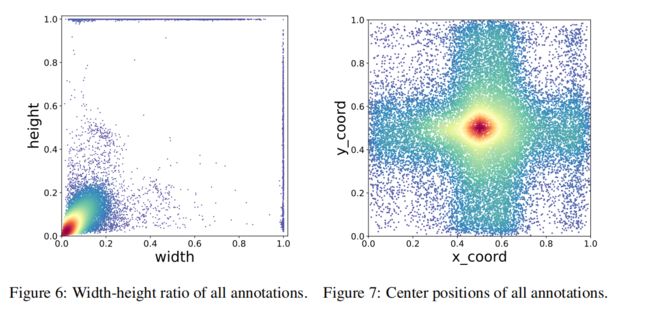
(boundingbox大小比图)我们的数据集中的边界框注释在大小和长宽比上差异很大。有高窄物体,还有短宽物体,如轨道表面和接触带、普通方形物体(紧固件和螺钉)。此外,如图所示。有大量密集分布的小物体,比如脱落。
4.3对象位置
图7 显示了在我们的数据集中对象的中心位置的分布。由于特殊的拍摄范式,轨道表面通常水平或垂直地位于图像中。因此,缺陷通常在图像中的跨区域扩散。
5.铁路5k数据集的试点研究
在本节中,我们进行了几个方面的全面实验,以调查铁路-5k数据集的挑战和潜力。我们在Rail-5k上训练了一个对象检测模型和一个语义分割模型作为基线,并展示了我们的数据集具有挑战性的属性。此外,我们提出了一个半监督的目标检测基准。

5.1检测基准
在一般的对象检测数据集上有许多流行的检测器[20,21,16]。最近,许多新的方法被提出,并在MS-COCO基准[17]中取得了最先进的结果。例如,YOLOv5[14]是一个轻型模型,具有镶嵌增强和Union(GIOU)损失上的广义相交。在我们的实验中,我们通过MS-COCO预训练在我们的数据集中确定了Yolov5-s作为基线。详细的培训设置是根据data/hyp.finetune.yaml2进行的。
可以注意到,该探测器对裂纹的性能极低。这是因为裂纹更像是一个纹理,而不是一个没有明确定义分离实例的对象。因此,我们选择从另一种方法来解决这个问题,这将在第5.2节中进一步讨论。


5.2裂缝基准
对于开裂区域,它更像是一个纹理和图案,而不是一个物体。因此,我们使用分割来识别这类,因为检测不能很好地识别它。我们使用Deeplabv3[1]架构与ResNet50[10]骨干作为分割模型。该模型被训练为9000次迭代,批处理大小大小为16次。我们使用具有动量的SGD作为优化器。动量和重量衰减分别设置为0.01、1e-4。为了评估我们的基准,我们选择了最常见的分割基准,即交叉点而不是Union(IoU)。该模型的背景信息值为98.9%,裂纹值为67.8%,远优于检测性能。DeepLabv3可以学习主要的和明显的裂纹,但会忽略微小的裂纹。

图11:第一行图像为分割预测结果,第二行图像为标签。
5.3 半监督学习的基准测试
利用附加的3k个未标记图像,我们提出了一个半监督的目标检测基准。我们得到的结果见表5。
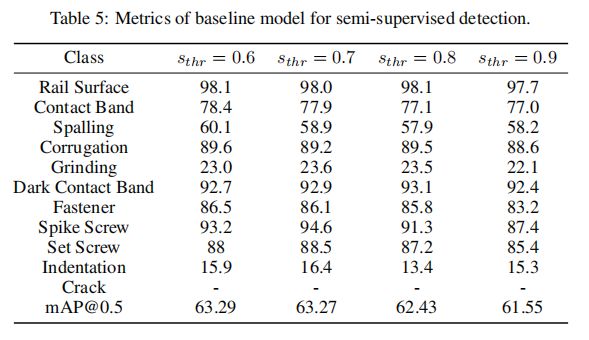
这些结果是用简单的伪标签技术生成的。我们按照第5.1节中描述的策略,使用yolov5s对未标记的图像进行推断。然后,我们对所有的预测应用一个置信分数阈值,并使用剩余的预测作为伪标签。最后,我们联合对标记图像和未标记图像进行了一次伪标签处理,基础学习率为4e-4。其他的培训设置是第5.1节中的培训设置。
如表5所示,在半监督下被发现后,探测器通常表现更差。这可能是由于未标记图像中的损坏和噪声造成的。
6 结论
我们介绍了Rail-5k,一个用于轨道表面缺陷检测的真实数据集。我们捕获中国各地的铁路图像,并提供细粒度的实例级注释。该数据集在铁路维护和计算机视觉方面都提出了新的挑战。作为一个基线,我们使用现成的检测模型提供了一个关于Rail-5k的试点研究。在以后的版本中,Rail-5k将包括更多的图像和模式,以及更多的缺陷类别和图像模式,如3d扫描或涡流数据。这将使Rail-5k成为一个更标准化和更包容的真实世界数据集。我们希望这个数据集将鼓励更多的工作来改进轨道维护的视觉识别方法,特别是在现实世界、细粒度、小和密集缺陷的对象检测和语义分割方面。
References
[1] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. CVPR, 2017.
[2] Mang Tik Chiu, Xingqian Xu, Kai Wang, Jennifer Hobbs, Naira Hovakimyan, Thomas SHuang, and Honghui Shi. The 1st agriculture-vision challenge: Methods and results. In CVPR Workshop, 2020.
[3] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
[4] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman.The pascal visual object classes (voc) challenge. IJCV, 2010.
[5] Shahrzad Faghih-Roohi, Siamak Hajizadeh, Alfredo Núñez, Robert Babuska, and Bart De Schutter. Deep convolutional neural networks for detection of rail surface defects. In IJCNN, 2016.
[6] Jiang Hua Feng, Hao Yuan, Yun Qing Hu, Jun Lin, Shi Wang Liu, and Xiao Luo. Research on deep learning method for rail surface defect detection. IET Electrical Systems in Transportation,2020.
[7] Jinrui Gan, Qingyong Li, Jianzhu Wang, and Haomin Yu. A hierarchical extractor-based visual rail surface inspection system. IEEE Sensors Journal, 2017.
[8] Mingfei Gao, Zizhao Zhang, Guo Yu, Sercan Ömer Arik, Larry S. Davis, and Tomas Pfister.Consistency-based semi-supervised active learning: Towards minimizing labeling cost. In NeurIPS, 2019.
[9] Agrim Gupta, Piotr Dollár, and Ross B. Girshick. LVIS: A dataset for large vocabulary instance segmentation. In CVPR, 2019.
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
[11] Dan Hendrycks and Thomas G. Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. ICLR, 2019.
[12] SNCF Exploitation-Maintenance IEM-RM. B-scan ultrasonic image analysis for internal rail defect detection. 2003.
[13] Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute,Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In AAAI, 2019.
[14] Glenn Jocher, Alex Stoken, Jirka Borovec, NanoCode012, ChristopherSTAN, Liu Changyu,Laughing, tkianai, yxNONG, Adam Hogan, lorenzomammana, AlexWang1900, Ayush Chaurasia, Laurentiu Diaconu, Marc, wanghaoyang0106, ml5ah, Doug, Durgesh, Francisco Ingham,
Frederik, Guilhen, Adrien Colmagro, Hu Ye, Jacobsolawetz, Jake Poznanski, Jiacong Fang,Junghoon Kim, Khiem Doan, and Lijun Yu. ultralytics/yolov5: v4.0 - nn.SiLU() activations,Weights & Biases logging, PyTorch Hub integration, 2021.
[15] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset,Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4. IJCV, 2020.
[16] Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In ICCV, 2017.
[17] Tsung-Yi Lin, Michael Maire, Serge J. Belongie, Lubomir D. Bourdev, Ross B. Girshick, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. In ECCV, 2014.
[18] Ziwei Liu, Zhongqi Miao, Xiaohang Zhan, Jiayun Wang, Boqing Gong, and Stella X. Yu.Large-scale long-tailed recognition in an open world. In CVPR, 2019.
[19] Claudio Michaelis, Benjamin Mitzkus, Robert Geirhos, Evgenia Rusak, Oliver Bringmann,Alexander S. Ecker, Matthias Bethge, and Wieland Brendel. Benchmarking robustness in object detection: Autonomous driving when winter is coming. NeuriIPS Workshop, 2019.
[20] Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016.
[21] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NeurIPS, 2015.
[22] Kihyuk Sohn, Zizhao Zhang, Chun-Liang Li, Han Zhang, Chen-Yu Lee, and Tomas Pfister. A simple semi-supervised learning framework for object detection. arXiv:2005.04757, 2020.
[23] Siwei Yang, Shaozuo Yu, Bingchen Zhao, and Yin Wang. Reducing the feature divergence of rgb and near-infrared images using switchable normalization. In CVPR Workshop, 2020.
[24] Oliver Zendel, Markus Murschitz, Marcel Zeilinger, Daniel Steininger, Sara Abbasi, and Csaba Beleznai. Railsem19: A dataset for semantic rail scene understanding. In CVPR Workshop,2019。