Flink + Iceberg 的数仓增量生产 ETL 以及在美团的落地实践
一、美团数仓架构图

如上图,是美团最新的数仓架构图。
整个架构图分为三层,从下往上看,最下面一层是数据安全,包括受限域认证系统、加工层权限系统,应用层权限系统,安全审计系统,来保证最上层数据集成与处理的安全;
中间一层是统一的元数据中心和全链路血缘,覆盖了全链路的加工过程;
最上层根据数据的流向,分成数据集成,数据处理,数据消费,数据应用,四个阶段;
在数据集成阶段,对于不同的数据来源(包括用户行为数据,日志数据,DB 数据,文件数据),都有相对应的数据集成系统,把数据收集到统一的存储之中,包括 Kafka 和 Hive 等。
在数据处理阶段,有一个面向用户的数据开发平台(万象平台),可以使用两条数据处理链路来加工数据,一个是流式处理链路,一个是离线处理链路。
数据加工好了之后,使用内部自研的 DeltaLink 同步数据到其他的应用中,例如即席分析,即席查询,报表等应用。
上图中标红的地方,Kafka -> HDFS,Flink,DeltaLink 是本次重点分享的内容。
二、美团当前 Flink 应用场景和规模
美团 Flink 应用场景包括:
- 实时数仓、经营分析、运营分析、实时营销
- 推荐、搜索
- 风控、系统监控
- 安全审计
Flink 集群规模如下(高峰流量是每天最高峰的流量):

三、基于 Flink 的流式数据集成
数据集成经历了多个版本的迭代
1. 数据集成 V1.0
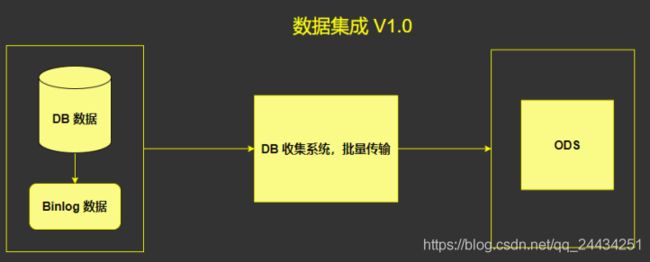
V1.0 版本很简单,是完全批量同步的架构。
在数据量比较少的情况下,这样的批同步的架构,优势很明显,架构简单,非常简单易于维护。
但是缺点也很明显,光是数据传输就 1 - 2 个小时。
2. 数据集成 V2.0
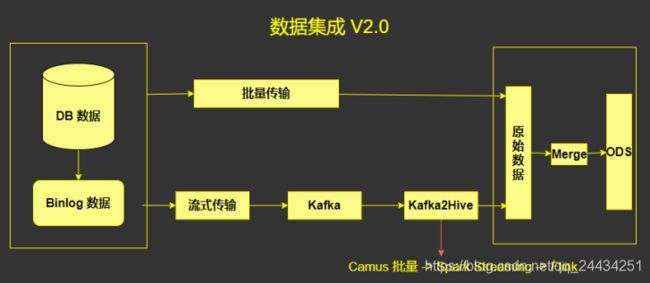
在 V2.0 中,增加了流式传输的链路(下面的链路),把数据实时传输到 ODS 中(批量传输的链路仍然是必须的,作为第一次全量的导入)。
流式传输系统,使用 canal (阿里开源) 采集 Mysql 的 binlog 日志到 kafka。后边有一个 Kafka2Hive 系统,这个系统经过了多个版本的迭代。
Kafka2Hive 模块,最开始是使用 Camus ,每一个小时拉一次数据,跑在 Spark 上。后面改成使用 SparkStreaming ,但是 Spark Streaming 在资源的利用方面有一些问题的,所以最终弄全部迁移到了 Flink 框架上来。
这样的架构,优势是非常明显的:把数据传输放在了 T+0 的时间去做,T + 1 的时间只需要经过一次 Merge 即可,花费的时间可能就从 2 - 3 个小时减少到 1 个小时了,提升是非常明显的。
3. 数据集成 V3.0
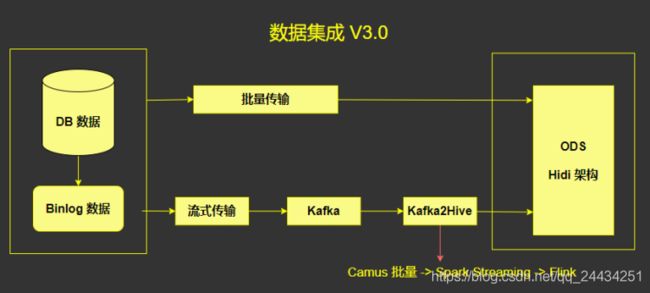
数据集成 V3.0 的架构,前面的部分和 V2.0 一样,关键的是后面这一部分。
在 V2.0 架构中,凌晨需要对数据做一次 Merge,这个操作对于 Hdfs 的压力非常大,要把几十 T 的数据读过来,清洗一遍,再把几十 T 的数据写入到 Hdfs。
所以,在 V3.0 架构中,引用了 Hidi 架构(Hidi 是美团内部基于 Hdfs 开发的类似 Hudi 或者 Iceberg 的文件格式)。
4. 美团自研的 Hidi
要做到增量生产,最关键的特性在于
- 支持增量读取,也就是读取当前时间到前一段时间的数据, 才能做到增量;
- 支持基于主键的 Upsert/Delete。
Hidi 是美团在 2,3 年前,在内部自研的架构,此架构的特性在于:
- 支持 Flink 引擎读写;
- 通过 MOR 模式支持基于主键的 upsert/Delete;
- 小文件管理 Compaction;
- Table Schema
可以对比 Hidi、Hudi、Iceberg,如下:
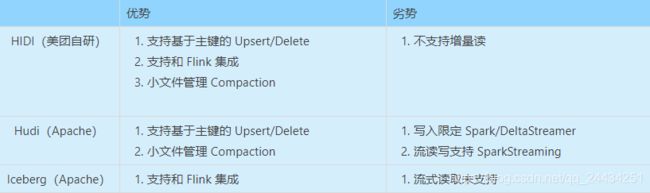
Hudi 最亮眼的特性是支持基于主键的 Upsert/Delete,但劣势是深度和 Spark 绑定,但在国内 Flink 框架这么火热的情况下,难免会有点美中不足。
Iceberg 不依赖于执行引擎,可以深度和 Flink 集成。
美团自研的 Hidi 则根据自己的需求实现了诸多的特性,目前仍然在完善中。
四、基于 Flink 的增量生产
1、传统离线数仓特性分析
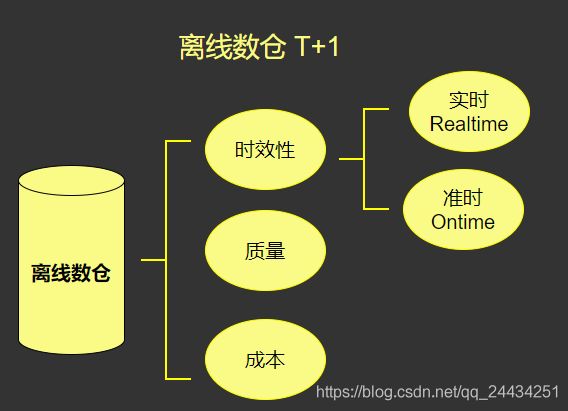
一般我们说数仓,都是指离线数仓。离线数仓有三个重要的指标,一是时效性,二是质量,三是成本。
首先是时效性,有两个更深层次的含义,一个是实时,一个是准时。
实时就是实时流式处理,来一条处理一条,实时处理消耗的资源很多。
准时,就是按时处理。比如广告需求,可能只需要在每个整点,统计过去一小时或者在每个整点统计当天的数据即可,没有必要做到实时,只需要到点能产出数据就行。
所以,总结下来,离线数仓和实时数仓各有利弊,离线数仓在质量和成本上会有优势,但是时效性不足;实时数仓,在时效性上很有优势,但是质量和成本都略逊色。
2. 增量生产
如下图,是离线数仓、实时数仓和增量计算的对比
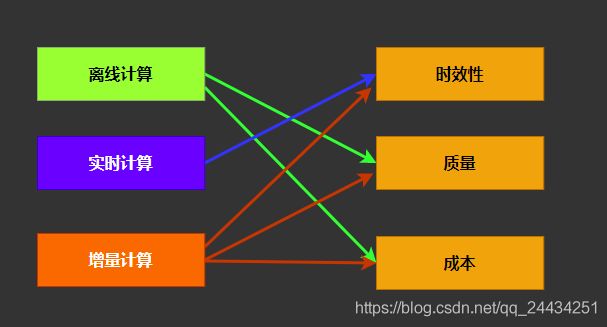
所谓增量计算,就是企业在时效性、质量、成本上做一个权衡,时效性需要高一点,但是不用做到 RealTime,OnTime 也可以接受( 8 点看报表,提前到 3 点计算好也没有很大的意义),但是质量要高,成本也需要尽量少。
3. 增量计算的优点
增量计算最大的优点,就是可以尽快的发现问题。
一般我们会在第二天花 8 个小时到 12 个小时,把前一天的数据生产出来。但是如果第二天发现数据错了,可能要花一天的时间去修复数据,这个时候,准时性和质量都被打破了。
如下图,横坐标是时间(T 表示当天,T+1 表示第二天),黑色线表示离线生产,大概利用 T + 1 一半资源去生产。红色线是实时生产,在当天就生产数据,占用的资源比离线计算高。
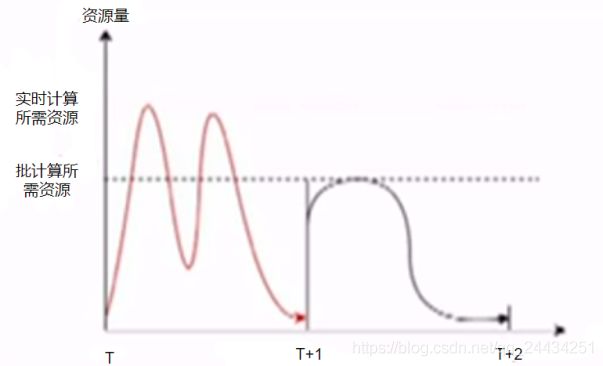
下图是增量生产的示意图。
绿色线是增量计算,在当天就计算好。
黑色线是离线计算,在第二天的前半天计算。

增量计算,是在当天计算,在当天就能提前发现问题,避免 T + 1 修复数据。并且还可以充分利用资源,提前产出数据的时间,并且占用资源更少。
4. 增量生产架构图
下图是美团增量生产的架构图(目前的架构正在逐步完善中,还没有完全实现)
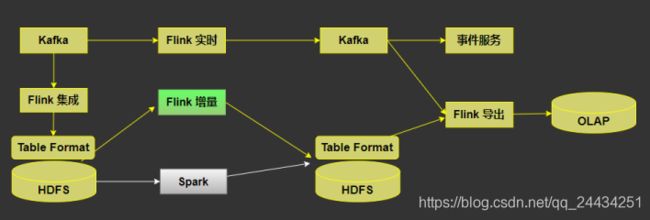
如图,最上面是实时处理的链路,Flink 消费 Kafka 数据 到 下游的 kafka,输出结果给下游使用或者供 OLAP 分析。
下面的链路是批处理,首先 kafka 数据经过 Flink 集成到 HDFS,再通过 Spark 做离线的生产,最终经过 Flink 导出到 OLAP 应用里面去。
上文提到的增量生产,就是图中标绿色的部分,希望可以用增量生产来替换掉 Spark 离线计算,做到计算引擎的统一。
要能支持增量生产,需要具备几个核心的能力:
- Flink SQL 能力能够对齐 Spark SQL;
- Hidi 支持 Upsert/Delete 特性(Hidi 已支持);
- Hidi 支持全量和增量的读取,全量读取用于查询和修复数据,增量读取用来增量生产;
五、实时数仓模型与架构
如下图是实时数仓的模型,基本上都见过
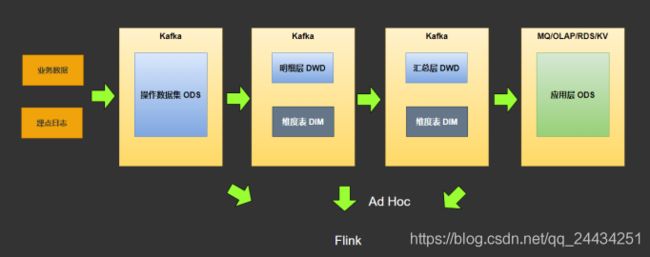
下图是实时数仓平台的架构图
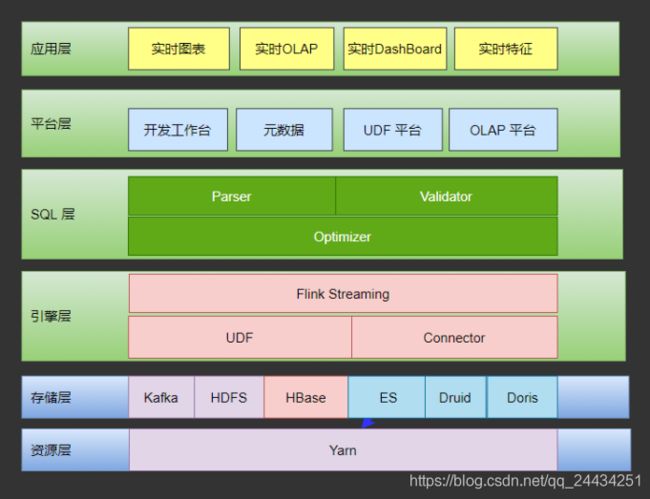
整个架构,分为资源层、存储层、引擎层、SQL 层、平台层和应用层。
六、流式导出与 OLAP 应用
1. 异构数据源的同步
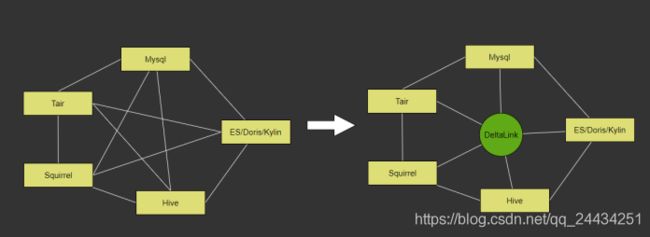
如上图,是异构数据源的同步。数据会在不同的存储系统中交换,所以我们做了一个 Deltalink 的平台,把数据 N 对 N 的交换过程,抽象成 N 对 1 的交换过程。
我们也迭代改进了很多版本。
2. 第一版实现
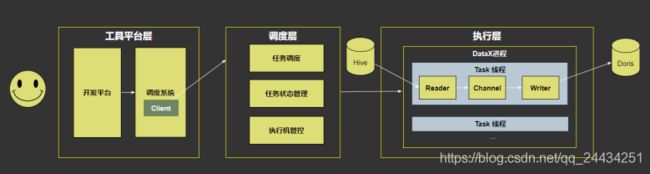
第一版是基于 DataX (阿里开源)来做同步,包含工具平台层,调度层,执行层。
- 工具平台层,对接用户,用来配置同步任务,配置调度,运维任务;
- 调度层,负责任务的调度,管理任务状态管理,以及执行机的管理,这其中有非常多的额外工作都需要自己做;
- 执行层,通过 DataX 进程,以及 Task 线程从源存储同步到目标存储。
但劣势也很明显,开源版的 DataX 是一个单机多线程的模型,当数据量非常大的时候,单机多线程是成为了瓶颈,限制了可扩展性;
然后在调度层,需要管理机器,管理同步的任务和状态,非常繁琐;
当调度执行机发生故障的时候,整个灾备都需要单独去做。
3. 第二版实现

在第二版中,改成了基于 Flink 同步的架构,看起来就清爽了很多。
工具平台层没有变,调度层的任务调度和执行机管理都交给 Yarn 去做。
调度层的任务状态管理,可以迁移到 Client 中去做。
基于 Flink 的 DeltaLink 的架构,解决了可扩展性问题,而且架构非常简单。
当把同步的任务拆细之后,可以分布式的分布到不同的 TaskManager 里去执行。
并且离线和实时的同步,都可以统一到 Flink 框架中去,这样离线和实时同步的 Source 和 Sink 组件都可以共用一套。
4. 基于 Flink 的同步架构关键设计
- 避免跨 TaskManager 的 Shuffle,避免不必要的序列化成本;
Source 和 Sink 尽量在同一个 TaskManager; - 务必设计脏数据收集旁路和失败反馈机制;
数据同步遇到脏数据的时候,比如失败了 1% 的时候,直接停下来; - 利用 Flink 的 Accumulators 对批任务设计优雅退出机制;
数据传输完之后,通知下游数据同步完了; - 利用 S3 统一管理 Reader/Writer 插件,分布式热加载,提升部署效率;
很多传输任务都是小任务,而作业部署时间又非常长,所以需要要提前部署插件;
5. 基于 Flink 的 OLAP 生产平台
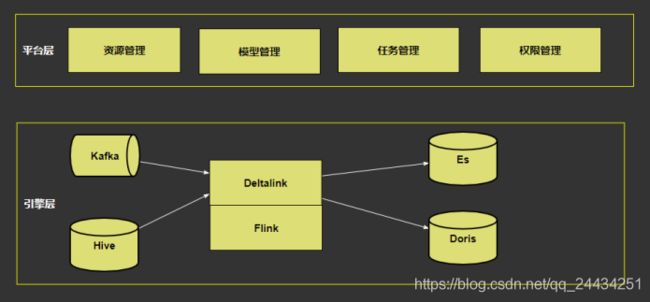
基于 Flink 做了 Deltalink ,数据导出的平台;
基于数据导出的平台,做了 OLAP 平台,对于资源,模型,任务和权限都做了管理。
七、 未来规划
经过多次迭代,把 Flink 用到了数据集成、数据处理、离线数据导出、OLAP 等场景,但事情还没有结束。
未来的目标,是要做到流批一体,把离线作业都迁移到 Flink 上来;
同时数据也要做到批流一体,这个很重要。如果数据仍然是两份,是两套 Schema 定义,那么不管如何处理,都需要去对数据,就不是真正的流批统一。
所以不管是计算还是存储,都使用 Flink,达到真正的流批一体。
本文整理自2020年 Flink Forward Asia 大会,分享者:鞠大升
关注公众号:KK架构师,获取更多数据湖最新实战
