代码随想录打卡—day6—【哈希表】— 哈希基础
1 哈希的基础知识
选择哈希:一般哈希表都是用来快速判断一个元素是否出现集合里。
哈希存储:【1】数组【2】set【3】map。
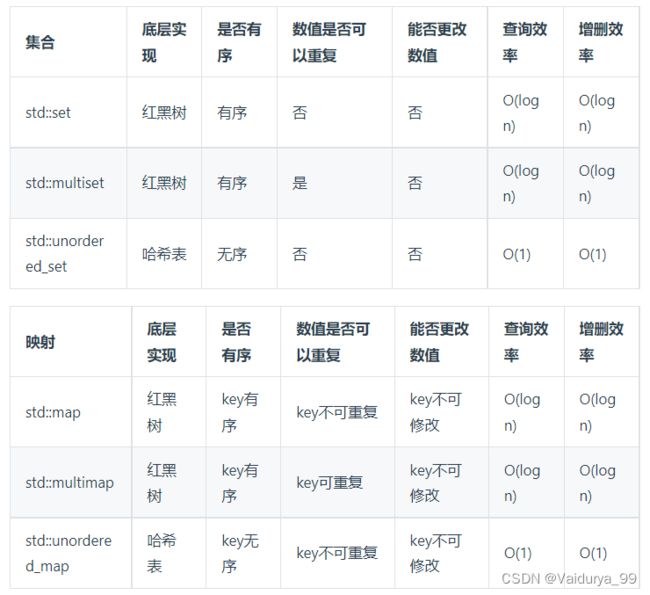
关于set——当我们要使用set来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set(set最主要的作用是自动去重并按升序排序),如果要求不仅有序还要有重复数据的话,那么就用multiset。
写的不错的博客:
1. 复习set
2. 复习map
2 哈希题(1)
242. 有效的字母异位词
class Solution {
public:
bool isAnagram(string s, string t)
{
int s_num[26];
int t_num[26];
for(int i = 0; i < 26; i++) //初始化一下
{
s_num[i] = 0;
t_num[i] = 0;
}
for(int i = 0; i < s.size();i++)
s_num[s[i] - 'a']++;
for(int i = 0; i < t.size();i++)
t_num[t[i] - 'a']++;
for(int i = 0; i < 26; i++)
if(s_num[i] != t_num[i])return 0;
return 1;
}
};3 哈希题(2)
349. 两个数组的交集
我的第一版AC 用set的版本,注意一个set find不到指定元素时候 返回的是set.end()迭代器。
class Solution {
public:
vector intersection(vector& nums1, vector& nums2)
{
// 本题可以用数组 现在尝试用一下set
set set1;
set set2;
for(int i = 0; i < nums1.size();i++)
set1.insert(nums1[i]);
for(int i = 0; i < nums2.size();i++)
set2.insert(nums2[i]);
vector a;
for(auto x = set1.begin(); x != set1.end();x++)
{
int tmp = *x;
if(set2.find(tmp) != set2.end()) // find没找到的话 会返回set2.end()
a.push_back(tmp);
}
return a;
}
}; 其实这样做不是最优的,应该用unordered_set !因为本题不用有序且unordered_set效率最高,所以本题unordered_set比set好。
4 哈希题(3)
202. 快乐数
本题的关键是看到题目中,判断非快乐数的条件是无限"循环"——即这个sum会重复出现!这时候判断sum是否在之前出现过,自然想到哈希表。
class Solution {
public:
bool isHappy(int n)
{
// 关键:不是快乐数的这个数会无限循环 就是会最少出现2次
unordered_set out;
bool flag = 1; // 非快乐数的结束flag
while(n != 1)
{
vector tmp;
tmp.clear();
// 获得n的每一位数
while(n)
{
tmp.push_back(n % 10);
n /= 10;
}
int sum = 0;
for(int i = 0; i < tmp.size();i++)
sum += tmp[i]*tmp[i];
if(out.find(sum) != out.end())// 找到重复了
return 0;
out.insert(sum);
n = sum;
}
return 1;
}
};
5 哈希题(4)
1. 两数之和
自己的原始想法unordered_set ,做着做着发现要加个map,就AC了。
class Solution {
public:
vector twoSum(vector& nums, int target)
{
// 第一反应还是用unordered_set的做法 做着做着发现需要map
unordered_set x;
map y;
vector out;
for(int i = 0; i < nums.size();i++)
{
x.insert(nums[i]);
y[nums[i]] = i;
}
for(int i = 0; i < nums.size();i++)
{
int rest = target - nums[i];
if(x.find(rest) != x.end()) // 有目标rest
{
if(y[rest] == i)continue; // 不能自己和自己相加
out.push_back(i);
out.push_back(y[rest]);
break;
}
}
return out;
}
}; 看了题解发现,【1】这里的unordered_set 没必要用,map可以替代这个功能,且map还能存键值对。【2】应该用unordered_map 不用map ,因为这里不要求有序,前者底层是哈希表,更快一些。
直接放carl的代码:
class Solution {
public:
vector twoSum(vector& nums, int target) {
std::unordered_map map;
for(int i = 0; i < nums.size(); i++) {
// 遍历当前元素,并在map中寻找是否有匹配的key
auto iter = map.find(target - nums[i]);
if(iter != map.end()) {
return {iter->second, i};
}
// 如果没找到匹配对,就把访问过的元素和下标加入到map中
map.insert(pair(nums[i], i));
}
return {};
}
}; 总结哈希的选择【重点】
选择哈希:
需要在一堆数里面,O(1)查找某数在不在这堆数里面。
选择数组:
【1】要查找的数据有范围 ,比如,小写字母表0-25 、题目告知的1-1000等等。
【2】数据在数组中分布比较密集。 如果是3个数:1,5,100000 的话,开100000就很浪费空间。
选择set:
【1】首选 unordered_set (去重,无序)
【2】需要 去重,有序 就用set
【3】需要 不去重,有序 就multiset
选择map:
【1】在set基础上,对于每个元素不能只存一个数,需要存键值对。选择unordered_map ,map,multimap 判断标准和set类似。
感受:
这样的题目复习一下STL 感觉效果最显著的!赞。总共用时:近3h。
todo:

