山东大学项目实训四——Face_Recognition 使用Opencv和Dlib实现基于视频的人脸识别
Face_Recognition
使用Opencv和Dlib实现基于视频的人脸识别
文件夹介绍
1、Resources\pictures
此文件夹下存放人脸保存结果
2、Resources\video
此文件夹下存放带标注视频保存结果
3、Resources\faceS
此文件夹下存放各个人物的图片,用于人脸库的建立
4、Resources\featureDB
此文件下为各个人物的128D描述符的数据存储文件
5、Resources\featureMean\feature_all.csv
此文件为人脸特征库文件
6、Resources\shape_predictor_68_face_landmarks.dat
人脸关键点标记模型文件
7、Resources\dlib_face_recognition_resnet_model_v1.dat
面部识别模型文件
8、face_recognition.mp4
待检测的视频
9、face_recognition.py
人脸识别代码文件
10、detection.py
人脸检测代码文件
11、face_recognition.py
建立本地人脸库代码文件
介绍
思路介绍
无论是基于视频或者调用摄像头来完成人脸识别,其实是一样,通过使用opencv,来捕获视频或者摄像头传来的图像,每隔若干帧取一帧做人脸识别,调用Dlib中的人脸检测器来检测人脸,并通过Dlib的人脸关键点预测器来获得人脸的关键点,接下来使用Dlib的面部识别模型将获得的68个关键点转换成128D面部描述符,我们通过计算人脸的128D面部描述符与本地人脸库(需要自己建立人脸库)中的人脸128D面部描述符的欧氏距离,来判断是否为同一人,当距离小于特定阈值时,认定识别成功,打上标签。

运行环境介绍
操作系统版本:Windows10
运行环境:python3.6+opencv4.1.2+dlib19.8.1
软件:PyCharm
(注:这里下载dlib包最好下载.whl文件,不需要安装cmake以及boost这些麻烦的东西。因为dilib包的没有python3.7版的whl文件,所以建议使用python3.6)
附上opencv和dlib包链接:https://pan.baidu.com/s/1Z33r7SoD5Z0faH96wr7Ecw
提取码:a8gl
模型介绍
这里的人脸识别使用了Dlib已训练成功的两个模型–人脸关键点预测器和面部识别模型。使用时需要加载模型,文件分别为shape_predictor_68_face_landmarks.dat和dlib_face_recognition_resnet_model_v1.dat
模型文件下载地址 http://dlib.net/files/
人脸关键点预测器
Dlib中标记68个特征点采用的是ERT算法,是一种基于回归树的人脸对齐算法,这种方法通过建立一个级联的残差回归树来使人脸形状从当前形状一步一步回归到真实形状。每一个GBDT的每一个叶子节点上都存储着一个残差回归量,当输入落到一个节点上时,就将残差加到改输入上,起到回归的目的,最终将所有残差叠加在一起,就完成了人脸对齐的目的。
用法:
predictor_path = resources_path + "shape_predictor_68_face_landmarks.dat"
#加载人脸关键点预测器
predictor= dlib.shape_predictor(predictor_path)
#获取面部关键点,gary为灰度化的图片
shape = predictor(gray,value)
人脸识别模型
Dlib中使用的人脸识别模型是基于深度残差网络,深度残差网络通过残差块来构建,它有效的解决了梯度消失以及梯度爆炸问题。当网络深度很大时,普通网络的误差会增加,而深度残差网络却有较小的误差。这里的人脸识别通过训练深度残差网络将人脸的68个特征关键点转换成128D面部描述符,用于人脸的识别。
model_path = resources_path + "dlib_face_recognition_resnet_model_v1.dat"
#生成面部识别器
facerec = dlib.face_recognition_model_v1(model_path)
# 提取特征-图像中的68个关键点转换为128D面部描述符,其中同一人的图片被映射到彼此附近,并且不同人的图片被远离地映射。
face_descriptor = facerec.compute_face_descriptor(frame, shape)
效果展示
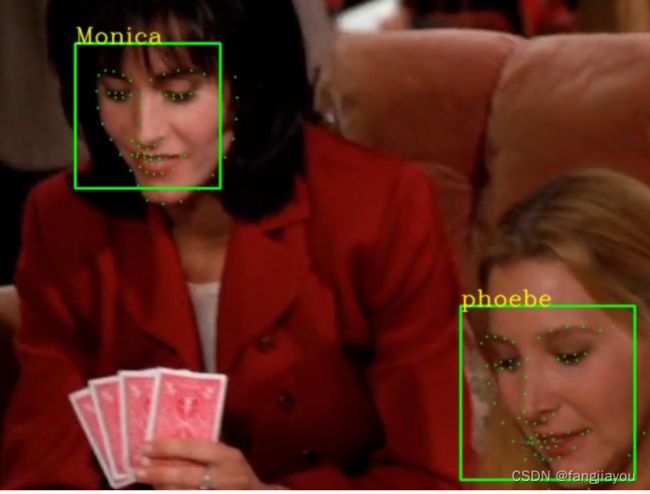
识别过程
1、本地人脸库建立

通过opencv提供的VideoCapture()函数对视频进行加载,并计算视频的fps,以方便人脸标记之后的视频的输出。
3、加载模型
将已经训练好的模型加载进来,将人脸关键点标记模型和面部识别模型加载进来,以便后续使用。
4、人脸检测
对视频进行读取,每隔6帧,取一帧进行人脸检测,先将取得的照片进行灰度处理,然后进行人脸检测,并绘画人脸标记框进行展示,然后通过加载的人脸关键点标记模型识别图像中的人脸关键点,并且标记。
5、人脸识别
将获取的人脸关键点转换成128D人脸描述符,将其与人脸库中的128D面部描述符进行欧氏距离计算,当距离值小于某个阈值时,认为人物匹配,识别成功,打上标签。当无一小于该阈值,打上Unknown标签
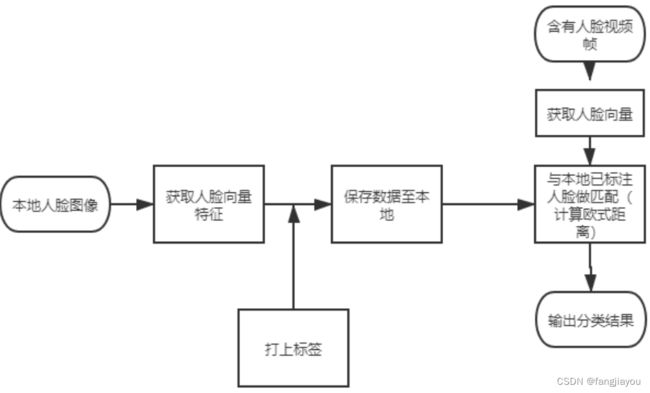
6、 保存人脸标记视频
将整个处理过程进行输出,将人脸标记过程保存下来。

代码
建立本地人脸库
(特别说明,这里是分别对同一个人的多张图片进行人脸检测,通过ERT人脸对齐算法获得其面部关键点,再将关键点转换成128D面部描述符(特征),将多个128D特征向量进行取平均值,来降低误差,最后将所有人的平均128D特征向量存到一个文件中,作为人脸特征库文件,用于人脸识别)
getFaceDB
# 从人脸图像文件中提取人脸特征存入 CSV
# Features extraction from images and save into features_all.csv
# return_128d_features() 获取某张图像的128D特征
# compute_the_mean() 计算128D特征均值
import cv2
import os
import dlib
from skimage import io
import csv
import numpy as np
import pandas as pd
# @author 方新悦
# @function 建立本地人脸库
# @detail 收集每个人物的多张图片,通过模型计算出人脸的128D面部描述符,计算每个人的特征平均值,存入人脸特征总文件
# @time 2022-2-13
# 要读取人脸图像文件的路径
path_images_from_camera= "Resources/faceS/"
path_featureDB= "Resources/featureDB/"
path_featureMean="Resources/featureMean/"
resources_path = os.path.abspath(".")+"\Resources\\"
predictor_path = resources_path + "shape_predictor_68_face_landmarks.dat"
model_path = resources_path + "dlib_face_recognition_resnet_model_v1.dat"
print(model_path)
# Dlib 正向人脸检测器
detector = dlib.get_frontal_face_detector()
# Dlib 人脸预测器
predictor = dlib.shape_predictor(predictor_path)
# Dlib 人脸识别模型
# Face recognition model, the object maps human faces into 128D vectors
face_rec = dlib.face_recognition_model_v1(model_path)
# 返回单张图像的 128D 特征
def return_128d_features(path_img):
img_rd = io.imread(path_img)
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_BGR2RGB)
faces = detector(img_gray, 1)
print("%-40s %-20s" % ("检测到人脸的图像 / image with faces detected:", path_img), '\n')
# 因为有可能截下来的人脸再去检测,检测不出来人脸了
# 所以要确保是 检测到人脸的人脸图像 拿去算特征
if len(faces) != 0:
shape = predictor(img_gray, faces[0])
face_descriptor = face_rec.compute_face_descriptor(img_gray, shape)
else:
face_descriptor = 0
print("there is no face")
return face_descriptor
# 将文件夹中照片特征提取出来, 写入 CSV
def write_into_csv(path_faces_personX, path_csv):
dir_pics = os.listdir(path_faces_personX)
with open(path_csv, "w", newline="") as csvfile:
writer = csv.writer(csvfile)
for i in range(len(dir_pics)):
# 调用return_128d_features()得到128d特征
print("正在读的人脸图像:", path_faces_personX + "/" + dir_pics[i])
features_128d = return_128d_features(path_faces_personX + "/" + dir_pics[i])
# print(features_128d)
# 遇到没有检测出人脸的图片跳过
if features_128d == 0:
i += 1
else:
writer.writerow(features_128d)
#对不同的人的特征数据进行取均值并将结果存储到all_feature。csv文件中
def computeMean(feature_path):
head=[]
for i in range(128):
fe="feature_"+str(i+1)
head.append(fe)
#需设置表头,当表头缺省时,会将第一行数据当作表头
rdata = pd.read_csv(feature_path,names=head)
# meanValue=[]
# for fea in range(128):
# fe = "feature_" + str(fea + 1)
# feature=rdata[fe].mean();
# meanValue.append(feature)
meanValue=rdata.mean()
print(len(meanValue))
print(type(meanValue))
print(meanValue)
return meanValue
#读取所有的人脸图像的数据,将不同人的数据存在不同的csv文件中,以便取均值进行误差降低
faces = os.listdir(path_images_from_camera)
i=0;
for person in faces:
i+=1
print(path_featureDB+ person + ".csv")
write_into_csv(path_images_from_camera+person, path_featureDB+ person+".csv")
print(i);
#计算各个特征文件中的均值,并将值存在feature_all文件中
features=os.listdir(path_featureDB)
i=0;
with open(path_featureMean + "feature_all.csv", "w", newline="") as csvfile:
writer = csv.writer(csvfile)
for fea in features:
i+=1;
meanValue=computeMean(path_featureDB+fea)
writer.writerow(meanValue)
print(i)
人脸识别
(注意人脸匹配的阈值的选取,阈值的选取影响识别的效果)
face-recognition
import dlib,os,glob,time
import cv2
import numpy as np
import csv
import pandas as pd
# @author 方新悦
# @function 利用opencv和dlib实现人脸识别
# @time 2022-3-26
# 声明各个资源路径
resources_path = os.path.abspath(".")+"\Resources\\"
predictor_path = resources_path + "shape_predictor_68_face_landmarks.dat"
model_path = resources_path + "dlib_face_recognition_resnet_model_v1.dat"
video_path =resources_path + "face_recognition.mp4"
resources_vResult=resources_path+"video\\"
faceDB_path="Resources/featureMean/"
# 加载视频,加载失败则退出
video = cv2.VideoCapture(video_path)
# 获得视频的fps
fps = video.get(cv2.CAP_PROP_FPS)
if not video.isOpened():
print("video is not opened successfully!")
exit(0)
# # 加载模型
#人脸特征提取器
detector = dlib.get_frontal_face_detector()
#人脸关键点标记
predictor= dlib.shape_predictor(predictor_path)
#生成面部识别器
facerec = dlib.face_recognition_model_v1(model_path)
#定义视频创建器,用于输出视频
video_writer = cv2.VideoWriter(resources_vResult+"result1.avi",
cv2.VideoWriter_fourcc(*'XVID'), int(fps),
(int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))))
#读取本地人脸库
head = []
for i in range(128):
fe = "feature_" + str(i + 1)
head.append(fe)
face_path=faceDB_path+"feature_all.csv"
face_feature=pd.read_csv(face_path,names=head)
print(face_feature.shape)
face_feature_array=np.array(face_feature)
print(face_feature_array.shape)
face_list=["Chandler","Joey","Monica","Phoebe","Rachel","Ross"]
# 创建窗口
cv2.namedWindow("Face Recognition", cv2.WINDOW_KEEPRATIO)
cv2.resizeWindow("Face Recognition", 720,576)
#计算128D描述符的欧式距离
def compute_dst(feature_1,feature_2):
feature_1 = np.array(feature_1)
feature_2 = np.array(feature_2)
dist = np.linalg.norm(feature_1 - feature_2)
return dist
descriptors = []
faces = []
# 处理视频,按帧处理
ret,frame = video.read()
flag = True # 标记是否是第一次迭代
i = 0 # 记录当前迭代到的帧位置
while ret:
if i % 6== 0: # 每6帧截取一帧
# 转为灰度图像处理
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1) # 检测帧图像中的人脸
# for i in range(len(dets)):
# landmarks = np.matrix([[p.x, p.y] for p in predictor(gray,dets[i]).parts()])
# 处理检测到的每一张人脸
if len(dets)>0:
for index,value in enumerate(dets):
#获取面部关键点
shape = predictor(gray,value)
#pos = (value[0, 0], value[0, 1])
#标记人脸
cv2.rectangle(frame, (value.left(), value.top()), (value.right(), value.bottom()), (0, 255, 0), 2)
#进行人脸识别并打上姓名标签
# 提取特征-图像中的68个关键点转换为128D面部描述符,其中同一人的图片被映射到彼此附近,并且不同人的图片被远离地映射。
face_descriptor = facerec.compute_face_descriptor(frame, shape)
v = np.array(face_descriptor)
print(v.shape)
l = len(descriptors)
Flen=len(face_list)
flag=0
for j in range(Flen):
# 人脸匹配,距离小于阈值,表示识别成功,打上标签
if(compute_dst(v,face_feature_array[j])<0.56):
flag=1
cv2.putText(frame,face_list[j],(value.left(), value.top()),cv2.FONT_HERSHEY_COMPLEX,0.8, (0, 255, 255), 1, cv2.LINE_AA)
break
if(flag==0):
cv2.putText(frame,"Unknown", (value.left(), value.top()), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 255, 255), 1,
cv2.LINE_AA)
#标记关键点
for pti,pt in enumerate(shape.parts()):
pos=(pt.x,pt.y)
cv2.circle(frame, pos, 1, color=(0, 255, 0))
#faces.append(frame)
# 将第一张人脸照片直接保存
if flag:
descriptors.append(v)
faces.append(frame)
flag = False
else:
sign = True # 用来标记当前人脸是否为新的
for i in range(l):
distance = compute_dst(descriptors[i] , v) # 计算两张脸的欧式距离,判断是否是一张脸
# 取阈值0.5,距离小于0.5则认为人脸已出现过
if distance < 0.4:
# print(faces[i].shape)
face_gray = cv2.cvtColor(faces[i], cv2.COLOR_BGR2GRAY)
# 比较两张人脸的清晰度,保存更清晰的人脸
if cv2.Laplacian(gray, cv2.CV_64F).var() > cv2.Laplacian(face_gray, cv2.CV_64F).var():
faces[i] = frame
sign = False
break
# 如果是新的人脸则保存
if sign:
descriptors.append(v)
faces.append(frame)
cv2.imshow("Face Recognition", frame) # 在窗口中显示
exitKey= cv2.waitKey(1)
if exitKey == 27:
video.release()
video_writer.release()
cv2.destroyWindow("Face Recognition")
break
video_writer.write(frame)
ret,frame = video.read()
i += 1
print("不同的人脸数")
print(len(descriptors)) # 输出不同的人脸数
print("输出的照片数")
print(len(faces)) #输出的照片数
# 将不同的比较清晰的人脸照片输出到本地
j = 1
for fc in faces:
cv2.imwrite(resources_path + "\pictures\\" + str(j) +".jpg", fc)
j += 1
face-detection
import dlib,os,glob,time
import cv2
import numpy as np
import csv
import pandas as pd
# @author 方新悦
# @function 利用opencv和dlib实现人脸识别
# @time 2022-3-26
# 声明各个资源路径
resources_path = os.path.abspath(".")+"\Resources\\"
predictor_path = resources_path + "shape_predictor_68_face_landmarks.dat"
model_path = resources_path + "dlib_face_recognition_resnet_model_v1.dat"
video_path =resources_path + "face_recognition.mp4"
resources_vResult=resources_path+"video\\"
faceDB_path="Resources/featureMean/"
# 加载视频,加载失败则退出
video = cv2.VideoCapture(video_path)
# 获得视频的fps
fps = video.get(cv2.CAP_PROP_FPS)
if not video.isOpened():
print("video is not opened successfully!")
exit(0)
# # 加载模型
#人脸特征提取器
detector = dlib.get_frontal_face_detector()
#人脸关键点标记
predictor= dlib.shape_predictor(predictor_path)
#生成面部识别器
facerec = dlib.face_recognition_model_v1(model_path)
#定义视频创建器,用于输出视频
video_writer = cv2.VideoWriter(resources_vResult+"result1.avi",
cv2.VideoWriter_fourcc(*'XVID'), int(fps),
(int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))))
#读取本地人脸库
head = []
for i in range(128):
fe = "feature_" + str(i + 1)
head.append(fe)
face_path=faceDB_path+"feature_all.csv"
face_feature=pd.read_csv(face_path,names=head)
print(face_feature.shape)
face_feature_array=np.array(face_feature)
print(face_feature_array.shape)
face_list=["Chandler","Joey","Monica","Phoebe","Rachel","Ross"]
# 创建窗口
cv2.namedWindow("Face Recognition", cv2.WINDOW_KEEPRATIO)
cv2.resizeWindow("Face Recognition", 720,576)
#计算128D描述符的欧式距离
def compute_dst(feature_1,feature_2):
feature_1 = np.array(feature_1)
feature_2 = np.array(feature_2)
dist = np.linalg.norm(feature_1 - feature_2)
return dist
descriptors = []
faces = []
# 处理视频,按帧处理
ret,frame = video.read()
flag = True # 标记是否是第一次迭代
i = 0 # 记录当前迭代到的帧位置
while ret:
if i % 6== 0: # 每6帧截取一帧
# 转为灰度图像处理
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1) # 检测帧图像中的人脸
# for i in range(len(dets)):
# landmarks = np.matrix([[p.x, p.y] for p in predictor(gray,dets[i]).parts()])
# 处理检测到的每一张人脸
if len(dets)>0:
for index,value in enumerate(dets):
#获取面部关键点
shape = predictor(gray,value)
#pos = (value[0, 0], value[0, 1])
#标记人脸
cv2.rectangle(frame, (value.left(), value.top()), (value.right(), value.bottom()), (0, 255, 0), 2)
#进行人脸识别并打上姓名标签
# 提取特征-图像中的68个关键点转换为128D面部描述符,其中同一人的图片被映射到彼此附近,并且不同人的图片被远离地映射。
face_descriptor = facerec.compute_face_descriptor(frame, shape)
v = np.array(face_descriptor)
print(v.shape)
l = len(descriptors)
Flen=len(face_list)
flag=0
for j in range(Flen):
# 人脸匹配,距离小于阈值,表示识别成功,打上标签
if(compute_dst(v,face_feature_array[j])<0.56):
flag=1
cv2.putText(frame,face_list[j],(value.left(), value.top()),cv2.FONT_HERSHEY_COMPLEX,0.8, (0, 255, 255), 1, cv2.LINE_AA)
break
if(flag==0):
cv2.putText(frame,"Unknown", (value.left(), value.top()), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 255, 255), 1,
cv2.LINE_AA)
#标记关键点
for pti,pt in enumerate(shape.parts()):
pos=(pt.x,pt.y)
cv2.circle(frame, pos, 1, color=(0, 255, 0))
#faces.append(frame)
# 将第一张人脸照片直接保存
if flag:
descriptors.append(v)
faces.append(frame)
flag = False
else:
sign = True # 用来标记当前人脸是否为新的
for i in range(l):
distance = compute_dst(descriptors[i] , v) # 计算两张脸的欧式距离,判断是否是一张脸
# 取阈值0.5,距离小于0.5则认为人脸已出现过
if distance < 0.4:
# print(faces[i].shape)
face_gray = cv2.cvtColor(faces[i], cv2.COLOR_BGR2GRAY)
# 比较两张人脸的清晰度,保存更清晰的人脸
if cv2.Laplacian(gray, cv2.CV_64F).var() > cv2.Laplacian(face_gray, cv2.CV_64F).var():
faces[i] = frame
sign = False
break
# 如果是新的人脸则保存
if sign:
descriptors.append(v)
faces.append(frame)
cv2.imshow("Face Recognition", frame) # 在窗口中显示
exitKey= cv2.waitKey(1)
if exitKey == 27:
video.release()
video_writer.release()
cv2.destroyWindow("Face Recognition")
break
video_writer.write(frame)
ret,frame = video.read()
i += 1
print("不同的人脸数")
print(len(descriptors)) # 输出不同的人脸数
print("输出的照片数")
print(len(faces)) #输出的照片数
# 将不同的比较清晰的人脸照片输出到本地
j = 1
for fc in faces:
cv2.imwrite(resources_path + "\pictures\\" + str(j) +".jpg", fc)
j += 1