03夯实基础之java核心类库
文章目录
- 夯实基础之java核心类库
-
- 一、Java核心类
-
- 1.1 泛型
-
- 1.1.1 定义
- 1.1.2 泛型类
- 1.1.3 泛型接口
- 1.1.4 泛型方法
- 1.1.5 泛型限制类型
- 1.1.6泛型中通配符 ?的使用
- 1.1.7 泛型的作用
- 1.1.8 注意
- 1.2 JDK 中所有类的基类—— Object 类
-
- 1.2.1 Java.lang 包下的类不需要手动导入
- 1.2.2 类构造器
- 1.2.3 equals 方法
- 1.2.4 getClass 方法
- 1.2.5 hashCode 方法
-
- 1.2.5.1 什么是 hashCode()
- 1.2.5.2 hashCode 的要求
- 1.2.5.3 hashCode 的编写建议
- 1.2.5.4 hashCode() 和 equals() 使用的注意事项
- 1.3 Java 的深拷贝和浅拷贝
-
- 1.3.1 创建对象的 5 种方式
- 1.3.2 浅拷贝
- 二、Java字符串、日期处理
- 三、包装类、集合、数据结构
- 四、异常处理
-
- 4.1 什么是异常
-
- 4.1.1 异常定义
- 4.1.2 异常示例
- 4.2 异常处理(try+catch+finally)
- 4.3 异常体系结构
- 4.4 throws 关键字
- 4.5 throw 关键字
- 4.6 RuntimeExcepion 与 Exception 的区别
- 4.7 自定义异常
- 4.8 异常处理常见的面试题
- 五、IO
-
- 5.1 File类
-
- 5.1.1 File类常用的构造方法
- 5.1.2 File类常用的方法
- 5.1.3 绝对路径和相对路径
- 5.2 FileFilter ( 文件过滤器 )
- 5.3 IO流
-
- 5.3.1 IO流的概念
- 5.3.2 Java中流的分类
- 5.3.3 OutputStream 字符输出流
- 5.3.4 FileOutputStream 文件字节输出流
- 5.3.5 InputStream 输入流
- 5.3.6 FileInputStream 文件输入流
- 5.3.7 Writer 字符输出流
- 5.3.8 FileWriter/FileReader 文件字符输出/输入流
- 5.3.9 BufferedReader 逐行读取字符流
- 5.3.10 PrintStream | PrintWriter 打印流
- 5.3.11 转换流
- 5.3.12 OutputStreamWriter 字节转字符输出流
- 5.3.13 InputStreamReader 字节转字符输入流
- 5.4 对象序列化
-
- 5.4.1 Serializable 序列化接口
- 5.4.2 什么情况下属性不会被序列化
- 六、异常处理和IO之间的配合使用--异常日志
- 七、多线程编程
-
- 7.1 相关内容
- 7.2 一些注意点
- 八、网络编程
- 九、XML与JSON
-
- 9.1 XML简介
- 9.2 xml文件
- 9.3 xml语法格式
- 9.4 java中xml的解析方式
- 9.5 DOM4J解析xml
- 9.6 java生成xml
- 9.7 JSON
- 十、枚举、注解、反射
-
- 10.1 枚举
- 10.2 注解
- 10.3 反射
夯实基础之java核心类库
一、Java核心类
1.1 泛型
1.1.1 定义
泛型即参数化类型,即将类型由原来的的具体类型参数化。类似于方法中的变量参数,此时类型定义成参数形式,在使用的时候传入具体的类型。
1.1.2 泛型类
定义一个泛型类:
public class ClassName<T> {
private T data;
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}
1.1.3 泛型接口
public interface InterfaceName<T> {
T getData();
}
// 实现时指定泛型具体类型
public class InterfaceImpl01 implements InterfaceName<String> {
private String info;
@Override
public String getData() {
return info;
}
}
// 实现时不指定泛型具体类型
public class InterfaceImpl02<T> implements InterfaceName<T> {
private T data;
@Override
public T getData() {
return data;
}
}
1.1.4 泛型方法
private static
1.1.5 泛型限制类型
在使用泛型的时候,可以指定泛型的限定区域,如:
1.1.6泛型中通配符 ?的使用
类型通配符是使用 ?来替代具体的类型实参,如: 指定泛型类型的上界 指定泛型类型的下界 指定没有限制的泛型类型
1.1.7 泛型的作用
提高代码的复用率。泛型中类型在使用时指定,不需要强转。
1.1.8 注意
Java 的泛型只在编译阶段有效,因为编译之后程序会去泛型化。在编译阶段检查结果是正确之后,会将泛型的相关信息进行擦除,并且会在对象进入和离开方法的边界处添加类型检查和类型转换的方法。
1.2 JDK 中所有类的基类—— Object 类
Object 类是 Java 中所有类的父类,所有类默认继承 Object。Object 类中所有的公有方法将被任何类继承,如果把所有的 Java 类看成一棵树,那么 Object 类则是这棵树的树根。
1.2.1 Java.lang 包下的类不需要手动导入
Java 中两种导包的形式:
1)单类型导入(single-tpye-import),如:import java.util.Date
2)按需导入类型(type-import-on-demand),如:import java.util.*
其中按需导入并不是导入 java.util 包下的所有类,java 会根据名字知道是按照需求导入,并不是导入整个包下所有的类。java 编译器会从启动目录(bootstrap)、扩展目录(extension)、和用户类路径去定位按照需要导入的类。单类型导入可以导入包名和类名,所以编译器可以一次定位到所要用到的类文件;按需导入类型比较复杂,编译器会把包名和文件名进行排列组合,然后对所有可能性进行类文件查找。如:如果文件中使用到了 File 类,编译器在找到了 java.io.File 之后不会停止下一步寻找,而是会把所有的可能性都查找完以确定是否有冲突。如果查找完之后,编译器发现了两个同名的类就会报错。按需类型导入不会降低 java 代码的执行效率的,但是会影响到 java 代码的编译速度。所以在编码的时候,最好使用单类型导入。
1.2.2 类构造器
在 Object 类中是看不到构造器的,系统会自动添加一个无参构造器。可以通过下面的方式创建一个对象:Object obj = new Object();
1.2.3 equals 方法
== 运算符用于比较基本类型的值是否相同,或者比较两个对象的引用是否相等,而 equals 方法用于比较两个对象是否相等。在 Object 类中,== 运算符和 equals 方法是等价的,都是比较两个对象的引用是否相等。如果对于一个自定义的对象,如果不重写 equals 方法的话,在比较的时候就会调用 Object 类的比较方法,也就是用 == 进行比较。
比较完美的 equals 方法:
1)显式参数命名为 otherObject,稍后将它转换成另一个称为 other 的变量。
2)判断比较的两个对象引用是否相等,如果引用相等则表示是同一个对象。
3)如果 otherObject 为 null,直接返回 false。比较 this 和 otherObject 是否是同一个类,如果 equals 的语义在每个子类中有所改变,就用 getClass 检测,如果所有的子类都有统一的定义,那么就用 instanceof 检测。
4)将 otherObject 转换成对应的类型变量。
5)最后对对象的属性进行比较。用 == 比较基本类型,用 equals 比较对象。无论何时重写 equals 方法,通常都必须重写 hashCode 方法,以遵循 hashCode 方法的一般约定。
1.2.4 getClass 方法
getClass 的作用是返回对象的运行时类。
public final native Class getClass();
用 native 修饰的方法是由操作系统帮忙实现的,该方法的作用是返回一个对象的运行时类,通过这个类对象可以获取该运行时类的相关属性和方法。也就是 java 的反射,各种通用的框架都是利用反射来实现的。java 中还有一种方法,通过 类名.class 获取这个类的类对象。class 是一个类的属性,能够获取该类编译时的类对象,而 getClass 是一个类的方法,它获取到的是该类运行时的类对象。
1.2.5 hashCode 方法
1.2.5.1 什么是 hashCode()
hashCode() 和 equals() 方法的作用其实一样,在 java 中都用来比较两个对象是否相等。hashCode() 的方法定义:public native int hashCode();作用是返回对象的哈希码,为 int 类型。hash 算法也称散列算法,是将数据通过特定算法产生的结果直接指定到一个地址上。
1.2.5.2 hashCode 的要求
1)在程序的运行时期间,只要对象的变化不影响 equals 方法的决策结果,则不管调用多少次 hashCode,都应该返回同一个 hash 值。
2)通过 equals 调用返回 true 的两个对象的 hashCode 一定相同。
3)通过 equals 返回 false 的两个对象的 hash 值不需要相同。
总结起来就是:如果对象相等,hashCode 一定相同;对象不相等,hashCode 有可能相同;hashCode 相同,对象不一定相等;hashCode 不相同,对象一定不相等。对于元素不多的情况下,直接通过 hashCode 产生的唯一索引值,不仅能找到该元素,也能判定元素是否相等。
1.2.5.3 hashCode 的编写建议
1)不同的对象 hash 值应该尽量不同,避免 hash 冲突。
2)hash 值是一个 int 类型的,在 java 中占 4 个字节,也就是 232,要避免溢出的情况。
3)对于 Map 集合,如果不是基本类型或者 String 这样的引用类型作为 key,也就是自定义对象作为 key,一定要重写 equals 和 hashCode 方法,否则会报错。
1.2.5.4 hashCode() 和 equals() 使用的注意事项
1)对于需要大量并且快速的对比,如果都用 equals 去实现效率显然太低。当我们需要对比的时候,首先用 hashCode 去对比,如果 hashCode 结果不一样,则表示这两个对象肯定不相等,如果 hashCode 相同,再用 equals 去比较,如果此时 equals 也相同,表示这两个对象真正相同。
2)大量并且快速的对象对比一般采用 hash 容器,如 HashMap、HashSet、HashTable 等。
1.3 Java 的深拷贝和浅拷贝
1.3.1 创建对象的 5 种方式
1)通过 new 关键字通过new关键字调用类的有参或者无参构造函数来创建对象。
Object obj = new Object();
2)通过 Class 的 newInstance() 方法默认调用类的无参构造方法。
Person p = (Person) Class.forname("com.soda.pojo.Person").newInstance();
3)通过 Constructor 类的 newInstance方法与第二种方法类似,使用的是反射机制实现的。第二种方法内部调用的还是 Constructor 的 newInstance 方法。
Person p = (Person) Person.class.getConstructors()[0].newInstance();
4)利用 clone 方法clone方法是Object的方法,调用 A.clone() 方法会创建一个内容和对象 A一模一样的对象B。clone方法是用 native 关键字修饰的,用该关键字修饰的方法就是告诉操作系统去实现。
Person p1 = (Person) p.clone();
5)反序列化序列化:把堆内存中的java对象数据通过某种方式把对象存储到磁盘文件中或者传递给其他网络节点。反序列化:把磁盘文件中的对象数据或者把网络节点上的数据对象恢复成java对象模型。
1.3.2 浅拷贝
在需要进行拷贝的类中,实现 Cloneable 接口,然后重写 clone 方法时调用 super.clone() 方法。在需要拷贝的地方,直接使用上面的第四种方法。
浅拷贝:创建一个新对象,然后将当前对象的非静态字段复制到该新对象,如果字段是值类型的,那么对该字段执行复制;如果该字段是引用类型的,则复制引用但不复制引用的对象。因此,原始对象及其副本引用同一对象。
二、Java字符串、日期处理
更多常用类库的使用,见我的另一篇博客:Java常用类库
三、包装类、集合、数据结构
包装类及集合的使用见博客Java常用类库,常用数据结构的使用见:Java核心类库之集合及常见数据结构
四、异常处理
4.1 什么是异常
4.1.1 异常定义
程序运行时,发生的不被期望的事件,它阻止了程序按照程序员预期的结果正常执行。(做软件开发,不可能写的代码没有 bug,哈哈哈,所以出了问题,需要一套问题的处理机制。)
4.1.2 异常示例
public class ExceptionDemo { public static void main(String[] args) { int i = 10; int j = 0; System.out.println("============= 计算开始 ============="); int temp = i / j; System.out.println("temp = " + temp); System.out.println("============= 计算结束 ============="); } }异常:
产生了异常之后,异常之后的代码便不再被执行,程序自行退出。

4.2 异常处理(try+catch+finally)
异常处理机制能让程序在异常发生时,按照我们的预先设定的异常处理逻辑,有针对性地进行处理,让程序尽最大可能恢复正常并继续执行,且保持代码的清晰。
如果要想对异常进行处理,则必须采用标准的处理格式,处理格式语法如下:
try{
// 有可能发生异常的代码段
} catch (异常类型1 对象名1) {
// 异常的处理操作
} catch (异常类型2 对象名2) {
// 异常的处理操作
} ...
finally {
// 异常的统一出口
}
一旦产生异常以后,JVM 根据异常的情况,自动实例化一个异常对象。如果在try语句中出现的异常,能够匹配上 catch 中的异常类型,则异常会被传递到对应的 catch 块中。如果在程序中对异常进行了处理,产生了预先要处理的异常时,程序不会异常终止。jvm 只能是尝试去捕获 catch 中声明的语句,如果没有捕获到,程序依旧会异常退出。
一个 catch 也可以捕获多个异常,采用如下格式:
try{
// 有可能发生异常的代码段
} catch (异常类型1 对象名1 | 异常类型2 对象名2) {
// 异常的处理操作
}
也可以通过里氏替换原则,选择一个父类(更粗粒度的异常类型,或者放大到顶级父类Exception)来捕获多个异常。(在公司开发规范中没有要求的情况下可以采用)
注意:捕获更粗的异常不能放在捕获更细的异常之前。
在进行异常的处理机制中,如果在异常的处理格式中还有一个finally语句,那么此语句将作为异常的统一出口,不管是否产生了异常,最终都要执行此段代码。特殊情况下,finally就不会执行,比如jvm完蛋了,还执行啥了,哈哈哈。
由于finally在异常处理机制中是必然执行的代码块,所以finally通常用来释放占用的资源。
4.3 异常体系结构
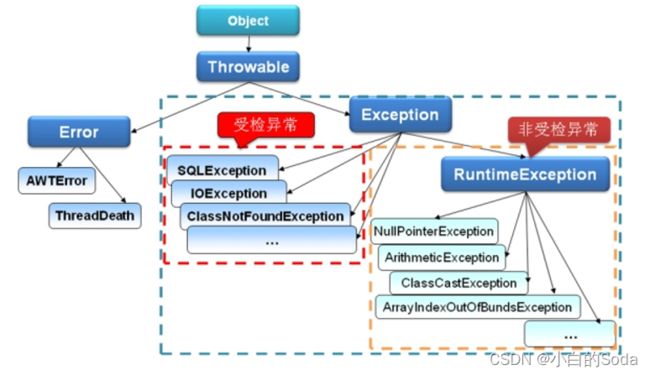
Java标准库内包含了一些通用的异常类,这些类以 Throwable 为顶层父类。
Throwable 又有 Error 类和 Exception 类两个子类。
1. Error:只能尽量避免,无法通过代码处理的错误,比如:内存溢出,JVM 运行错误。
2. Exception:可以被处理的程序中错误,所以一般在程序中通过try…catch进行处理。
4.4 throws 关键字
throws 关键字主要在方法的声明上使用,表示方法中不处理异常,而交给调用方处理。
格式:
返回值类型 方法名称() throws Exception{
}
当某些时候,在 java 的异常处理机制下,我们的工具没有问题,而是使用工具的地方会出问题,我们不希望对工具进行修理,但是对调用的地方使用 try-catch 进行处理时又不符合规范,这个时候可以让工具 throws 异常,转而交由调用方进行处理。
4.5 throw 关键字
throw 关键字表示在程序中人为的抛出一个异常。从异常处理机制来看,所有的异常一旦产生之后,实际上抛出的就是一个异常类的实例化对象,那么此对象也可以由 throw 直接抛出。如果你写的方法 throw 了一个异常,并且调用方又没有去处理,那么程序就会崩溃,也就是说,throw 出来的异常和 jvm 抛出异常的效果是一样的。
示例: throw new Exception(“就是玩儿。”) ;
4.6 RuntimeExcepion 与 Exception 的区别
RuntimeExcepion 是运行时异常,是非受检异常,Exception 子类中还有一些受检异常。
只要是 RuntimeException 的子类,则表示程序在操作的时可以不必使用 try catch 进行处理,如果有异常发生,则由 JVM 进行处理,当然,也可以通过 try catch 处理;如果继承的是 Exception,那么就必须进行 try-catch处理。
4.7 自定义异常
编写一个类, 继承 Exception,并重写一参构造方法,即可完成自定义受检异常类型。
编写一个类, 继承 RuntimeExcepion,并重写一参构造方法,即可完成自定义运行时异常类型。
/**
* @Author: 小白的 Soda
* @Description: 根据里氏替换原则,在使用 Exception 的地方,都可以使用 MyException 来替代
* @Date Created in 2021-12-01 21:15
* @Modified By:
*/
public class MyException extends Exception{
public MyException() {
this("出现了异常");
}
public MyException(String message) {
super(message);
}
}
4.8 异常处理常见的面试题
\1. try-catch-finally 中哪个部分可以省略?
答:catch 和 finally 可以省略其中一个 , catch 和 finally 不能同时省略
注意: 格式上允许省略 catch 块, 但是发生异常时就不会捕获异常了,我们在开发中也不会这样去写代码.
\2. try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
答:finally中的代码会执行
详解:
执行流程:
1. 先计算返回值, 并将返回值存储起来, 等待返回
2. 执行finally代码块
3. 将之前存储的返回值, 返回出去
注意: 如果返回的是变量,返回值是在 finally 运算之前复制的一份变量内容,不管 finally 对原变量做任何的改变,返回的值都不会改变。如果返回的是对象,并且在 finally 中对对象的属性做改变,则之前复制的一份内容是复制的一份地址,那么返回的对象当中的属性也会是相应的改变之后的值。
\3. try、catch、finally 中,如果都包含 return 代码,返回值以谁的为最终返回值?
答:finally 中的返回值为最终返回值。
详解:
执行流程:
1. 先计算返回值, 并将返回值存储起来, 等待返回
2. 执行finally代码块
3. 将之前存储的返回值, 返回出去;
\4. 如果 try 或 catch 通过 System.exit(0) 退出程序,finally 块还执行吗?
答:不执行。
详解:
System.exit(0) 表示停止 JVM,JVM 虚拟机停止则所有 Java 代码停止。
五、IO
5.1 File类
是 java 中的文件/文件夹的抽象表示形式,即一个 File 类的对象,就表示一个文件或者文件夹(但是也有可能文件不存在)。
5.1.1 File类常用的构造方法
在使用File类描述文件时,这个File的对象描述的文件可以不存在。
1. File(String pathName)
pathName:文件路径
2. File(String pathName,String fileName)
pathName:文件路径
fileName:文件名称
3. File(File parent, String fileName)
parent:父文件夹的file对象
fileName:文件的名称
5.1.2 File类常用的方法
文件:
public static void main(String[] args) {
File file = new File("C:\\Users\\24980\\Desktop\\a.txt");
// 删除文件
// boolean delete = file.delete();
// System.out.println("删除结果:" + delete);
// 创建文件,当文件已经存在的时候创建失败
try {
boolean newFile = file.createNewFile();
System.out.println(newFile);
} catch (IOException e) {
System.out.println("创建出问题啦!");
e.printStackTrace();
}
}
文件夹:
public static void main(String[] args) {
File dir = new File("C:\\Users\\24980\\Desktop\\哈哈哈");
// 创建单层目录
boolean mkdir = dir.mkdir();
System.out.println(mkdir);
// 创建多层不存在的文件夹
//boolean mkdirs = dir.mkdirs();
// 删除文件夹,当文件夹未清空,删除是失败的
//boolean delete = dir.delete();
//System.out.println(delete);
}
程序退出时删除:
File dir = new File("C:\\Users\\24980\\Desktop\\哈哈哈");
dir.deleteOnExit();
文件类操作方法还有很多,更多方法请查阅API。
5.1.3 绝对路径和相对路径
绝对路径是指目录下的绝对位置,直接到达目标位置,通常是从盘符开始的路径。 完整的描述文件位置的路径就是绝对路径。
相对路径就是指由这个文件所在的路径引起的跟其它文件(或文件夹)的路径关系。
5.2 FileFilter ( 文件过滤器 )
FileFilter接口用于获取文件时筛选文件。
5.3 IO流
java中io流的设计参考了装饰者设计模式。
5.3.1 IO流的概念
I:input 输入,O:output输出。输入与输出是一个相对的概念。比如程序从硬盘中读取一个文件,这种操作相对于我们的程序而言, 是在进行输入操作,相对于我们的硬盘而言, 是在进行输出操作 。反之则相反。
5.3.2 Java中流的分类
从操作上来说, 分为两种流:
\1. 输入流
\2. 输出流
但是通常情况, 我们指的流的分类是:
\1. 字节 byte 流
- 输出流顶级父类 : OutputStream
- 输入流顶级父类 : InputStream
\2. 字符 char 流(基于字节流的上层封装)
- 输出流顶级父类 : Writer
- 输入流顶级父类 : Reader
5.3.3 OutputStream 字符输出流
常用的方法有:
- void write(int b);
向输出流指向的位置 , 输出一个字节.
- void write(byte[] bytes);
向输出流指向的位置 , 输出一个字节数组 .
- void write(byte[] bytes, int start, int end);
向输出流指向的位置 , 输出一个字节数组的一部分 (从start开始, 到end结束 , 包含开始, 不包含结束)
- void close();
关闭流, 释放占用的硬件资源.
5.3.4 FileOutputStream 文件字节输出流
FileOutputStream 是 OuputStream 的实现类 , 是用于将字节输出到文件中的 类。文件输出流输出时, 指向的文件可以不存在, 如果不存在则会创建文件并输出 。
构造方法:
- FileOutputStream(String filePath);
通过文件的绝对路径 , 创建一个指向文件的输出流。
- FileOutputStream(String filePath, boolean append);
参数1. filePath: 创建的流指向的文件路径
参数2. append : 设置流是否为追加模式
(当值为false时, 会将之前的数据清空)
(当值为true时, 会接着之前的文件继续存储)
- FileOutputStream(File file);
通过文件的file对象 , 创建一个指向文件的输出流。
- FileOutputStream(File file,boolean append);
参数1. file : 创建的流 , 指向的文件
参数2. append : 设置流是否为追加模式
(当值为false时, 会将之前的数据清空)
(当值为true时, 会接着之前的文件继续存储)
5.3.5 InputStream 输入流
常用方法:
- int read()
一次读取一个字节,(这个字节 使用0-255的int值来表示) 并返回 , 如果读取到流的尾部则返回-1
- int read(byte[] bytes);
一次读取一个字节数组 , 并将读取的内容存储到bytes中 , 返回的是读取的字节个数 , 当读取到流尾部时返回-1
- int read(byte[] bytes,int offIndex,int length)
bytes: 读取的字节数组, 存储的位置
offIndex: 读取的一组字节, 存储在bytes中的起始位置
length: 读取的一组字节的长度
这个方法读取完毕后, 新的数据存储在bytes数组的offIndex下标到 offIndex+length下标
- void close();
关闭流, 释放资源
5.3.6 FileInputStream 文件输入流
构造方法:
- FileInputStream(String filePath);
根据一个文件的路径, 创建一个指向此文件的输入流
- FileInputStream(File file);
根据一个file对象, 创建一个指向file表示的文件的输入流
5.3.7 Writer 字符输出流
使用字符流进行输出操作时, 都是在操作缓冲管道。当管道缓冲满时, 才会一次性写出到文件中。
常用方法:
- void write(int ch);
一次写出一个字符
- void write(char[] chars);
一次写出一个字符数组
- void write(char[] chars, int start, int end);
一次写出一个字符数组的一部分,从start开始 到end结束, 含start 不含end
- void write(String text);
一次写出一个字符串到流指向的位置
- void flush();
刷新缓冲管道 : 强制将管道中的缓存数据输出到流指向的位置, 并清空管道
- void close();
释放资源, 字符输出流在关闭时 , 会自动执行flush操作
5.3.8 FileWriter/FileReader 文件字符输出/输入流
FileWriter 文件字符输出流:
常用方法:
- FileWriter(String filePath);
通过文件的绝对路径 , 创建一个指向文件的输出流
- FileWriter(String filePath,boolean append);
参数1. filePath: 创建的流 , 指向的文件路径
参数2. append : 设置流是否为追加模式
(当值为false时, 会将之前的数据清空)
(当值为true时, 会接着之前的文件 继续存储)
- FileWriter(File file);
通过文件的file对象 , 创建一个指向文件的输出流
- FileWriter(File file,boolean append);
参数1. file : 创建的流 , 指向的文件
参数2. append : 设置流是否为追加模式
(当值为false时, 会将之前的数据清空)
(当值为true时, 会接着之前的文件 继续存储)
public static void main(String[] args) throws IOException {
Writer wr = new FileWriter("C:\\Users\\24980\\Desktop\\a.txt");
// 一次写出一个字符
// char c = '好';
// wr.write(c);
// 一次写出一组字符
char[] chars = "山有木兮木有枝,心念君兮君不知".toCharArray();
// wr.write(chars);
// 一次写出一个字符数组,并指出开始下标写出的个数
// wr.write(chars, 2, 5);
// 一次写出一个字符串
// wr.write("山有木兮木有枝");
// 一次写出一个字符串,且重复追加
wr.append("山有木兮木有枝,").append("心念君兮君不知,").append("心念君兮君不知.");
wr.close();
}
FileReader 文件字符输入流:
常用方法:
int read();
一次读取一个字符, 并按照int的方式返回! 当读取到流尾部时 返回-1
int read(char[] chars);
一次读取一个字符数组, 并将读取到的数据存储到chars中, 返回读取的字符个数, 当读取到流的尾部时返回-1;
int read(char[] chars,int offset ,int length);
一次读取一个字符数组的一部分 , 读取的数据存储在chars中的offset到offset+length下标中,返回读取的字符个数, 当读取到流的尾部时返回-1
void close();
关闭流 ,释放资源
public static void main(String[] args) throws IOException {
Reader r = new FileReader("C:\\Users\\24980\\Desktop\\a.txt");
// 一次读取一个字符
// char c = (char) r.read();
// System.out.println(c);
// 一次读取一组字符
// int len = 0;
// char[] chars = new char[100];
// len = r.read(chars);
// System.out.println(len);
// System.out.println(Arrays.toString(chars));
char[] chars = new char[100];
int len = 0;
len = r.read(chars, 5, 5);
System.out.println(len);
System.out.println(Arrays.toString(chars));
r.close();
}

5.3.9 BufferedReader 逐行读取字符流
构造方法不是传入文件地址, 而是传入其他的字符输入流。
构造方法:
BufferedReader(Reader r);
常用方法:
String readLine();
读取一行数据, 返回读取到的内容, 如果读取到流的尾部返回null;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("C:\\Users\\24980\\Desktop\\a.txt"));
// 一次读取一行是数据
// String line = br.readLine();
// System.out.println(line);
// line = br.readLine();
// System.out.println(line);
// 一行行读取整个文件
String line = null;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}
5.3.10 PrintStream | PrintWriter 打印流
构造方法:
\1. PrintStream(OutputStream os) | PrintWriter(Writer w);
根据一个流, 创建一个打印流
\2. PrintStream(String filePath) | PrintWriter(String filePath);
根据一个文件的绝对路径, 创建一个打印流
\3. PrintStream(File file) | PrintWriter(File file);
根据一个文件的file对象, 创建一个打印流
\4. PrintStream(File file,String charsetName); | PrintWriter(File file,String charsetName);
根据一个文件的file对象 和 字符编码名称 创建一个打印流
public static void main(String[] args) throws Exception {
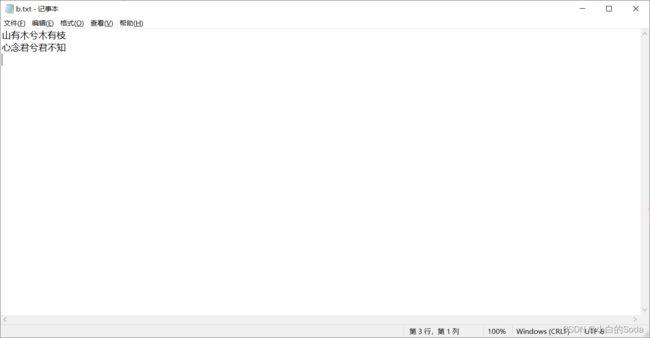
PrintStream ps = new PrintStream("C:\\Users\\24980\\Desktop\\b.txt");
ps.print("山有木兮");
ps.println("木有枝");
ps.println("心念君兮君不知");
ps.close();
}
public static void main(String[] args) throws Exception {
PrintWriter ps = new PrintWriter("C:\\Users\\24980\\Desktop\\b.txt");
ps.print("山有木兮");
ps.println("木有枝");
ps.println("心念君兮君不知");
ps.close();
}
5.3.11 转换流
用于将字节流转换为字符流,转换后得到的字符流,操作的方式与文件字符流一致。
5.3.12 OutputStreamWriter 字节转字符输出流
通过构造方法, 进行转换:
- OutputStreamWriter(OutputStream os);
参数1. 根据一个字节流, 创建一个字符流
- OutputStreamWriter(OutputStream os,Sting charsetName);
参数1. 根据一个字节流, 创建一个字符流
参数2. 字节流转换为字符流时, 使用的字符编码集的名称
5.3.13 InputStreamReader 字节转字符输入流
通过构造方法, 进行转换:
- InputStreamReader(InputStream is);
参数1. 根据一个字节流, 创建一个字符流
- InputStreamReader(InputStream is,Sting charsetName);
参数1. 根据一个字节流, 创建一个字符流
参数2. 字节流转换为字符流时, 使用的字符编码集的名称;
public static void main(String[] args) throws Exception {
// 字节输出流转字符输出流
FileOutputStream fos = new FileOutputStream("C:\\Users\\24980\\Desktop\\b.txt");
// 字节操作
// byte[] bytes = "山有木兮木有枝".getBytes();
// fos.write(bytes);
// fos.flush();
// bytes = "心念君兮君不知".getBytes();
// fos.write(bytes);
// fos.close();
// 转换流
// OutputStreamWriter osw = new OutputStreamWriter(fos);
// osw.write("hello world");
// osw.close();
// 转换成打印流
PrintWriter pw = new PrintWriter(fos, false);
pw.println("你好 世界");
pw.close();
}
5.4 对象序列化
序列化最大的用处在网络编程上面,通过流传输数据(通过序列化流传输对象)。
对象序列化流指的是: 将Java中的对象,存储到本地文件中的过程
构造方法:
ObjectOutputStream(OutputStream os)
常用方法:
writeObject(Object o);
对象反序列化流指的是: 将本地文件中存储的Java对象, 读取到内存中的过程
构造方法:
ObjectInputStream(InputStream is);
常用方法:
Object o = 对象.readObject();
5.4.1 Serializable 序列化接口
Java中我们编写的类的对象, 默认情况下是不能参与序列化,需要实现一个标记接口: Serializable , 才可以被序列化
标记接口:
接口中不包含任何的抽象, 实现后对于实现类来说, 类的接口没有发生改变, 仅仅是多了一个父接口。
注意: 对象在序列化时, 会依次序列化它的属性值。
属性值的类型, 也必须实现序列化接口
5.4.2 什么情况下属性不会被序列化
\1. 被static 修饰的属性不会被序列化。因为静态的属性不依赖于对象,我们的对象序列化操作,就不会操作这些静态的属性;
\2. 被transient修饰的属性,序列化时会被忽略,反序列化时是默认的值。
import java.io.*;
import java.util.Objects;
/**
* @Author: 小白的 Soda
* @Description:
* @Date Created in 2021-12-05 20:52
* @Modified By:
*/
public class Test6 {
public static void main(String[] args) throws Exception {
// FileOutputStream fos = new FileOutputStream("C:\\Users\\24980\\Desktop\\person.txt");
// ObjectOutputStream oos = new ObjectOutputStream(fos);
// Person person = new Person("张三", 18);
// oos.writeObject(person);
// oos.close();
FileInputStream fis = new FileInputStream("C:\\Users\\24980\\Desktop\\person.txt");
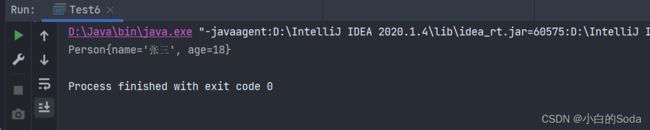
ObjectInputStream ois = new ObjectInputStream(fis);
Person o = (Person) ois.readObject();
System.out.println(o);
ois.close();
}
}
// Serializable 是一个标记接口,当实现该接口后,jvm便可对该类的对象进行序列化
class Person implements Serializable {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) {return true;}
if (o == null || getClass() != o.getClass()) {return false;}
Person person = (Person) o;
return age == person.age && name.equals(person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
六、异常处理和IO之间的配合使用–异常日志
工具类:
import java.io.*;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @Author: 小白的 Soda
* @Description:
* @Date Created in 2021-12-05 21:19
* @Modified By:
*/
public class LogUtil {
private static File dir = new File("C:\\Users\\24980\\Desktop");
public static void log(Exception e) {
File dir2 = new File(dir, new SimpleDateFormat("yyyy-MM-dd").format(new Date()));
if (!dir2.exists()) {
dir2.mkdirs();
}
// 将异常信息,存储到文件中
PrintWriter pw = null;
try {
pw = new PrintWriter(new FileOutputStream(new File(dir2, "log.txt"), true));
} catch (Exception ex) {
ex.printStackTrace();
}
pw.print(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()));
e.printStackTrace(pw);
pw.println();
pw.println();
pw.close();
}
}
测试:
/**
* @Author: 小白的 Soda
* @Description:
* @Date Created in 2021-12-05 21:23
* @Modified By:
*/
public class Test7 {
public static void main(String[] args) {
int[] arr = {};
try {
arr[1] = 10;
} catch (ArrayIndexOutOfBoundsException e) {
LogUtil.log(e);
}
}
}
效果:

七、多线程编程
学习的时候可以利用类比法进行理解,但是类比法容易失真。可以将CPU看成一个包含多个车间的工厂,只能同时支持一个车间运作,进程可以看作一个车间,线程则可以看作每个工人,内存则可以看作物料,可以共享但是不能同时操作,然后就涉及到了锁的相关概念。
当我们的程序需要同时做多件事情的时候,我们就需要用到多线程编程。
关于多线程学习的路径:
理解什么是多线程 —> 线程的基本使用 —> 理解并使用同步(包含了锁的使用) —> 学习并掌握JUC —> 理解线程执行的底层逻辑
7.1 相关内容
多线程相关内容可参见java多线程的那些事儿。
7.2 一些注意点
如果在实现Runnable接口时,新申请一个线程之后,直接调用run方法,不调用start方法,线程就不会被启动,而是直接被扔进了main线程顺序执行:
/**
* @Author: 小白的 Soda
* @Description:
* @Date Created in 2021-12-06 19:57
* @Modified By:
*/
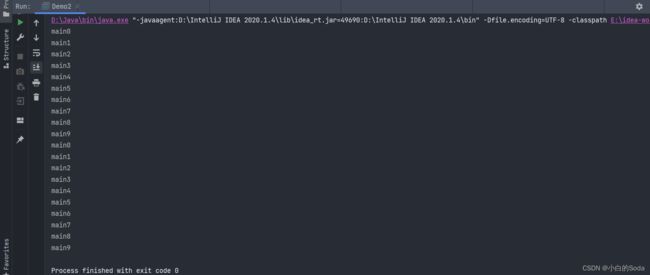
public class Demo2 {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.run(); // 此处直接调用run方法,没有调用start
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + i);
}
}
static class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + i);
}
}
}
}
结果:
但是调用start后,就会新开一个线程并执行:
/**
* @Author: 小白的 Soda
* @Description:
* @Date Created in 2021-12-06 19:57
* @Modified By:
*/
public class Demo2 {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new MyRunnable());
thread.start();
for (int i = 0; i < 20; i++) {
Thread.sleep(100);
System.out.println(Thread.currentThread().getName() + i);
}
}
static class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+ ":" + i);
}
}
}
}
为了更好的演示效果,所以加了200ms的休眠:

应当注意,在我们自己实现的run方法中,线程休眠时无法抛出异常,而只能try-catch。
线程的生命周期:
可分为线程创建,就绪,执行,阻塞,线程死亡。就绪态、执行态、阻塞态之间的相互转换,此处不做描述。java中线程的状态有:NEW, RUNNABLE, BLOCKED, WAITING(无限期等待另一个线程执行特定操作), TIMED_WAITING(正在等待另一个线程执行最多指定等待时间的操作的线程处于此状态), TERMINATED。但是这几个状态都是虚拟机状态,不反映任何操作系统线程状态。
线程的同步:
同步即排队,异步即并行。
同步就是线程安全,效率较低,线程安全可以有效的解决临界资源出错问题。
异步表示线程非安全,效率高。
非静态同步方法的锁对象是:this
静态同步方法的锁对象是:类名.class
线程安全问题:
当多个线程同时操作一段数据时,容易发生问题。
如何避免死锁:
\1. 顺序上锁
\2. 反向解锁
\3. 不要回头
面试题:
\1. java存在单线程程序吗?
答案:不存在,当一个java程序运行时,至少会执行两个线程,一个是main线程,一个是GC线程。
\2. 同步方法和同步代码块谁好?
存在即合理,不同的应用场景,各有优劣。同步方法可以很便捷的让一个类的所有非静态同步方法在一把锁上排队;同步代码块的粒度更细,最小可以控制单行代码排队,较为灵活。
八、网络编程
相关内容可参见:网络编程基础
简单示例:
Server:
import java.io.IOException;
import java.io.PrintStream;
import java.net.ServerSocket;
import java.net.Socket;
/**
* @Author: 小白的 Soda
* @Description:
* @Date Created in 2021-12-10 19:19
* @Modified By:
*/
public class Server {
public static void main(String[] args) throws IOException {
// 创建服务器程序
ServerSocket serverSocket = new ServerSocket(12345);
// 等待客户端连接
Socket accept = serverSocket.accept();
// 通过IO操作回复客户端
PrintStream printStream = new PrintStream(accept.getOutputStream());
printStream.println("你好,客户端");
printStream.close();
// 释放资源
serverSocket.close();
}
}
Client:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.Socket;
/**
* @Author: 小白的 Soda
* @Description:
* @Date Created in 2021-12-10 19:18
* @Modified By:
*/
public class Client {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 12345);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String s = bufferedReader.readLine();
System.out.println("服务器响应:" + s);
bufferedReader.close();
socket.close();
}
}
上面的示例中,如果Server和Client都同时先发消息,或者先收消息,就会陷入死锁,必须得确定一个收发消息的次序。
九、XML与JSON
9.1 XML简介
xml(eXtensible Markup Language):可扩展标记语言。与平台无关,是一门独立的标记语言,且具有自我描述性。
xml广泛应用于网络数据传输、数据存储、配置文件中。
9.2 xml文件
.xml 文件是保存xml数据的一种方式(xml数据也可以以其他方式存在,比如在内存中构建xml数据),xml语言 != .xml 文件。
9.3 xml语法格式
\1. XML文档声明
\2. 标记 ( 元素 / 标签 / 节点)
XML文档,由一个个的标记组成
语法:
开始标记(开放标记):
<标记名称> 结束标记(闭合标记):
标记名称: 自定义名称,必须遵循以下命名规则:
1.名称可以含字母、数字以及其他的字符
2.名称不能以数字或者标点符号开始
3.名称不能以字符 “xml”(或者 XML、Xml)开始
4.名称不能包含空格,不能包含冒号(:)
5.名称区分大小写
标记内容: 开始标记与结束标记之间 ,是标记的内容
例:
Soda \3. 一个XML文档中, 必须有且且仅允许有一个根标记
正例:
张三
李四
反例:
李四
麻子 \4. 标记可以嵌套, 但是不允许交叉
正例:
李四
18
反例:
李四
18
\5. 标记的层级称呼 (子标记, 父标记 , 兄弟标记, 后代标记 ,祖先标记)
例如:
李四
180cm
李四
200cm
其中:
name是person的子标记,也是person的后代标记
name是persons的后代标记
name是length的兄弟标记
person是name的父标记
persons是name的祖先标记
\6. 标记名称 允许重复
\7. 标记除了开始和结束 , 还有属性
标记中的属性, 在标记开始时描述, 由属性名和属性值组成
格式:
在开始标记中, 描述属性
可以包含多个属性, 且每一个属性是一个键值对
属性名不允许重复 , 键与值之间使用等号连接, 多个属性之间使用空格分割
属性值必须被引号引住
案例:
李四
18
李四
20
\8. 注释
注释不能写在文档声明前
注释不支持嵌套注释
格式:
注释开始:
注释结束: -->
9.4 java中xml的解析方式
在java中xml的解析方式有如下四种:
\1. SAX解析
解析方式:事件驱动机制
SAX解析器,逐行读取XML文件解析,每当解析到一个标签的开始/结束/内容/属性时,就会触发事件
优点:
解析能够立即开始,而不是等待所有的数据被处理
逐行加载,节省内存,有助于解析大于系统内存的文档
有时不必解析整个文档,可以在某个条件得到满足时停止解析
缺点:
\1. 单向解析,无法定位文档层次,无法同时访问同一文档的不同部分数据(因为逐行解析, 当解析第n行是, 第n-1行已经被释放了, 无法在进行操作了)。
\2. 无法得知事件发生时元素的层次, 只能自己维护节点的父/子关系。
\3. 只读解析方式, 无法修改XML文档的内容。
\2. DOM解析
DOM解析使用与平台和语言无关的方式表示XML文档的官方W3C标准,分析该结构通常需要加载整个文档和内存中建立文档树模型,程序员可以通过操作文档树,来完成数据的获取/修改/删除等操作
优点:
文档在内存中加载, 允许对数据和结构做出更改
访问是双向的,可以在任何时候在树中双向解析数据
缺点:
文档全部加载在内存中 , 消耗资源大
\3. JDOM解析
目的是成为Java特定文档模型,它简化与XML的交互并且比使用DOM实现更快,是第一个Java特定模型。
优点:
使用具体类而不是接口,简化了DOM的API。
大量使用了Java集合类,方便了Java开发人员。
缺点:
没有较好的灵活性。
性能不是那么优异。
\4. DOM4J解析
是JDOM的一种智能分支,合并了许多超出基本XML文档表示的功能,包括集成的XPath支持、XML Schema支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项, DOM4J是一个非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。越来越多的Java软件都在使用DOM4J来读写XML。
9.5 DOM4J解析xml
步骤:
// 先引入jar文件----> dom4j.jar
// 创建指向xml文件的流
FileInputStream fis = new FileInputStream("文件路径");
// 创建读取工具
SAXReader sr = new SAXReader();
// 使用读取工具对象,读取流对象,得到文档对象
Document document = sr.read(fis);
// 获取根元素对象
Element root = doc.getRootElement();
Document 文档对象:
指加载到内存中的整个xml文档
常用方法:
Element root = doc.getRootElement(); // 获取根元素对象
Element root = doc.addRootElement(“根节点名”); // 添加根节点
Element 元素对象:
指xml中的单个节点
常用方法:
\1. 获取节点名称
String getName(); \2. 获取节点内容
String getText(); \3. 设置节点内容
String setText(); \4. 根据子节点的名称 , 获取匹配名称的第一个子节点对象
Element element(String 子节点名称); \5. 获取所有的子节点对象
Listelements(); \6. 获取节点的属性值
String attributeValue(String 属性名称); \7. 获取子节点的内容
String elementText(String 子节点名称); \8. 添加子节点
Element addElement(String 子节点名称); \9. 添加属性
void addAttribute(String 属性名,String 属性值);
9.6 java生成xml
步骤:
\1. 通过文档帮助器 (DocumentHelper) , 创建空的文档对象
Document doc = DocumentHelper.createDocument();
\2. 通过文档对象, 向其中添加根节点
Element root = doc.addElement(“根节点名称”);
\3. 通过根节点对象root , 丰富子节点
Element e = root.addElement(“元素名称”);
\4. 创建一个文件输出流,用于存储XML文件
FileOutputStream fos = new FileOutputStream(“要存储的路径”);
\5. 将文件输出流, 转换为XML文档输出流
XMLWriter xw = new XMLWriter(fos);
\6. 写出文档
xw.write(doc);
\7. 释放资源
xw.close();
9.7 JSON
相关的内容,可以参见这篇文章的部分内容:07夯实基础之JavaEE基础
十、枚举、注解、反射
枚举、注解、反射在后面的框架学习中便可以体会到其用处。
10.1 枚举
枚举:用于定义有限数量的一组同类常量。枚举中定义的常量是该枚举中的实例。
定义格式:
权限修饰符 enum 枚举名称 {
实例1,实例2,实例3,实例4;
}
例:
public enum Level { LOW(30), MEDIUM(15), HIGH(5), URGENT(1); private int levelValue; private Level(int levelValue) { this.levelValue = levelValue; } public int getLevelValue() { return levelValue; } }
由于所有的枚举都继承自java.lang.Enum类,所以枚举对象不能再继承其他的类(java是单继承的),但是枚举可以实现接口,且每个枚举对象都可以实现自己的抽象方法。
注意:
一旦定义了枚举,最好不要修改里面的值,除非修改是必要的(牵一发而动全身)
枚举类默认继承的是java.lang.Enum类而不是Object类
枚举类不能有子类,因为其枚举类默认被final修饰
只能有private构造方法
switch中使用枚举时,直接使用常量名,不用携带类名
不能定义name属性,因为自带name属性
不要为枚举类中的属性提供set方法,不符合枚举最初设计初衷
10.2 注解
注解(Annotation)又称标注,是java的一中注释机制。java中的类、方法、变量、参数、包都可以被标注。和普通的注释不同,java注解可以通过反射机制获取标注的内容,且普通注释在编译时不会进入字节码文件,但是注解可以被嵌入到字节码文件中。jvm可以保留注解内容,在运行时可以获取到标注内容,且支持自定义注解。
注解主要用于编译格式检查、反射解析、生成帮助文档、跟踪代码依赖等。
内置注解:
@Override : 重写
定义在java.lang.Override
@Deprecated:废弃
定义在java.lang.Deprecated
@SafeVarargs
Java 7 开始支持,忽略任何使用参数为泛型变量的方法或构造函数调用产生的警告
@FunctionalInterface: 函数式接口
Java 8 开始支持,标识一个匿名函数或函数式接口
@Repeatable:标识某注解可以在同一个声明上使用多次
Java 8 开始支持,标识某注解可以在同一个声明上使用多次
@SuppressWarnings:抑制编译时的警告信息
\1. @SuppressWarnings(“unchecked”) 抑制单类型的警告
\2. @SuppressWarnings(“unchecked”,“rawtypes”) 抑制多类型的警告
\3. @SuppressWarnings(“all”) 抑制所有类型的警告
(参数意义可参见官方API文档)
元注解:
元注解是作用在其他注解上的注解,可以用于描述其他注解的信息。
@Retention - 标识这个注解怎么保存,是只在代码中,还是编入class文件中,或者是在运行时可以通过反射访问。
@Documented - 标记这些注解是否包含在用户文档中 javadoc。
@Target - 标记这个注解应该是哪种 Java 成员。
@Inherited - 标记这个注解是自动继承的
\1. 子类会继承父类使用的注解中被@Inherited修饰的注解
\2. 接口继承关系中,子接口不会继承父接口中的任何注解,不管父接口中使用的注解有没有被@Inherited修饰
\3. 类实现接口时不会继承任何接口中定义的注解
自定义注解:
定义格式:
@interface 自定义注解名{}注意:
\1. 定义的注解,自动继承了java.lang,annotation.Annotation接口
\2. 注解中的每一个方法,实际是声明的注解配置参数
\3. 方法的名称就是配置参数的名称
\4. 方法的返回值类型,就是配置参数的类型,且只能是:基本类型/Class/String/enum中的类型
\5. 可以通过default来声明参数的默认值
\6. 如果只有一个参数成员,一般参数名为value
\7. 注解元素必须要有值,我们定义注解元素时,经常使用空字符串、0作为默认值。
@interface
使用 @interface 定义注解时,意味着它实现了 java.lang.annotation.Annotation 接口,即该注解就是一个Annotation。
定义 Annotation 时,@interface 是必须的。
注意:它和我们通常的 implemented 实现接口的方法不同。Annotation 接口的实现细节都由编译器完成。通过 @interface 定义注解后,该注解不能继承其他的注解或接口。
@Documented
类和方法的 Annotation 在缺省情况下是不出现在 javadoc 中的。如果使用 @Documented 修饰该 Annotation,则表示它可以出现在 javadoc 中。
定义 Annotation 时,@Documented 可有可无;若没有定义,则 Annotation 不会出现在 javadoc 中。
@Target(ElementType.TYPE)
ElementType 是 Annotation 的类型属性,而 @Target 的作用,就是来指定 Annotation 的类型属性。
@Target(ElementType.TYPE) 的意思就是指定该 Annotation 的类型是 ElementType.TYPE。这就意味着,Annotation 是来修饰"类、接口(包括注释类型)或枚举声明"的注解。
定义 Annotation 时,@Target 可有可无。若有 @Target,则该 Annotation 只能用于它所指定的地方;若没有 @Target,则该 Annotation 可以用于任何地方。
@Retention(RetentionPolicy.RUNTIME)
RetentionPolicy 是 Annotation 的策略属性,而 @Retention 的作用,就是指定 Annotation 的策略属性。
@Retention(RetentionPolicy.RUNTIME) 的意思就是指定该 Annotation 的策略是 RetentionPolicy.RUNTIME。这就意味着,编译器会将该 Annotation 信息保留在 .class 文件中,并且能被虚拟机读取。
定义 Annotation 时,@Retention 可有可无。若没有 @Retention,则默认是 RetentionPolicy.CLASS。
10.3 反射
在运行状态动态获取信息以及动态调用对象方法的功能被称为java的反射机制。
类加载器:
Java类加载器(Java Classloader)是Java运行时环境(Java Runtime Environment)的一部分,负责动态加载Java类到Java虚拟机的内存空间中。
java默认有三种类加载器:BootstrapClassLoader、ExtensionClassLoader、App ClassLoader。
BootstrapClassLoader(引导启动类加载器):
嵌在JVM内核中的加载器,该加载器是用C++语言写的,主要负载加载JAVA_HOME/lib下的类库,引导启动类加载器无法被应用程序直接使用。
ExtensionClassLoader(扩展类加载器):
ExtensionClassLoader是用JAVA编写,且它的父类加载器是Bootstrap。
是由sun.misc.Launcher$ExtClassLoader实现的,主要加载JAVA_HOME/lib/ext目录中的类库。
它的父加载器是BootstrapClassLoader
App ClassLoader(应用类加载器):
App ClassLoader是应用程序类加载器,负责加载应用程序classpath目录下的所有jar和class文件。它的父加载器为ExtensionClassLoader
类的加载通常是按需加载,即使用时才加载,java中在加载类的时候,用到了双亲委派模型,能够避免类被重复加载,相关的知识点大家可以去了解一些jvm的基础知识。
在Java中,每一个字节码文件被加载到内存之后,都会有一个与之对应的class类型对象,得到class类型对象的方式:
\1. 如果在编写代码时, 知道类的名称, 且类已经存在, 可以通过
包名.类名.class 得到一个类的类对象
\2. 如果拥有类的对象, 可以通过
Class对象.getClass() 得到一个类的类对象
\3. 如果在编写代码时, 知道类的名称 , 可以通过
Class.forName(包名+类名): 得到一个类的类对象
注意:
当通过上述方式获取类对象时,如果类在内存中没有,则会进行加载,如果已经存在,便不会重复加载,而是进行重复利用。
通过class对象获取一个类的构造器:
\1. 通过指定的参数类型, 获取指定的单个构造方法
getConstructor(参数类型的class对象数组)
例如:
构造方法如下: Person(String name,int age)
得到这个构造方法的代码如下:
Constructor c = p.getClass().getConstructor(String.class,int.class);
\2. 获取构造方法数组
getConstructors();
- 获取所有权限的单个构造方法
getDeclaredConstructor(参数类型的class对象数组)
- 获取所有权限的构造方法数组
getDeclaredConstructors();
拿到类的构造器之后,通过 构造器对象.newInstance(Object… para)创建相应的对象。
通过class对象获取一个类的方法:
\1. getMethod(String methodName , class… clss)
根据参数列表的类型和方法名, 得到一个方法(public修饰的)
\2. getMethods();
得到一个类的所有方法 (public修饰的)
\3. getDeclaredMethod(String methodName , class… clss)
根据参数列表的类型和方法名, 得到一个方法(除继承以外所有的:包含私有, 共有, 保护, 默认)
\4. getDeclaredMethods();
得到一个类的所有方法 (除继承以外所有的:包含私有, 共有, 保护, 默认)
得到方法之后可以通过 方法名.invoke(Object o, Object… para)执行方法。
通过class对象获取类的属性:
\1. getDeclaredField(String filedName)
根据属性的名称, 获取一个属性对象 (所有属性)
\2. getDeclaredFields()
获取所有属性
\3. getField(String filedName)
根据属性的名称, 获取一个属性对象 (public属性)
\4. getFields()
获取所有属性 (public)
对属性的操作:
\1. get(Object o );
参数: 要获取属性的对象
获取指定对象的此属性值
\2. set(Object o , Object value);
参数1. 要设置属性值的 对象
参数2. 要设置的值
设置指定对象的属性的值
\3. getName()
获取属性的名称