强化学习--PPO(完结)
系列文章目录
强化学习
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 前言
- 一、强化学习是什么?
- 二、核心算法(PPO近端策略优化) Proximal Policy Optimization
-
- 多线程版本的例子
- 总结
前言
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。
一、强化学习是什么?
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
理解:强化学习其实就是和人一样,一开始是什么都不懂的,所谓吃一堑长一智,他像一个新生的孩子,它在不断的试错过程中慢慢知道了做什么有奖励,做什么对得到奖励会有一定的价值,做什么会被打。在这个过程中不会像监督学习一样有个师傅带你,完全需要自己去摸索,就像修仙宗门一样,有背景的宗门弟子是继承掌门之位(监督),创立宗门的人是开山立派(强化),必须一步一个脚印去不断成长。
其实强化学习吸引我的就是因为它主要使用在游戏上,例如:
在 Flappy bird 这个游戏中,我们需要简单的点击操作来控制小鸟,躲过各种水管,飞的越远越好,因为飞的越远就能获得更高的积分奖励。
机器有一个玩家小鸟——Agent
需要控制小鸟飞的更远——目标
整个游戏过程中需要躲避各种水管——环境
躲避水管的方法是让小鸟用力飞一下——行动
飞的越远,就会获得越多的积分——奖励

二、核心算法(PPO近端策略优化) Proximal Policy Optimization
Proximal Policy Optimization,简称PPO,即近端策略优化,是对Policy Graident,即策略梯度的一种改进算法。PPO的核心精神在于,通过一种被称之为Importce Sampling的方法,将Policy Gradient中On-policy的训练过程转化为Off-policy,即从在线学习转化为离线学习,某种意义上与基于值迭代算法中的Experience Replay有异曲同工之处。通过这个改进,训练速度与效果在实验上相较于Policy Gradient具有明显提升。
PPO主要是为了解决Policy Gradient 不好确定Learning rate(或者Step size)的问题.因为如果step size过大,学出来的Policy 会一直乱动,不会收敛,但如果Step Size太小,对于完成训练,我们会等到绝望.PPO利用New Policy和 Old Policy的比例,限制了New Policy 的更新幅度,让 Policy Gradient对稍微大点的Step size不那么敏感。
其中规定概念:KL散度
KL散度即两个分布的相对熵H_p(Q) - H§:使用不正确的分布Q代替真实分布P时所产生的额外代价。只有当两个分布一致时,KL散度为0,否则总是正的。在PPO中,KL散度用来衡量policy π与π_old的偏离程度,期望两者是接近的。
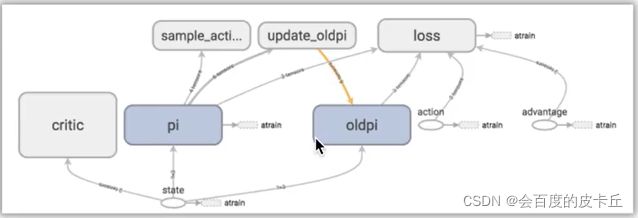
class PPO(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
self.sample_op = tf.squeeze(pi.sample(1), axis=0) # operation of choosing action
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
# ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
surr = ratio * self.tfadv # surrogate loss
self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
self.sess.run(tf.global_variables_initializer())
def update(self):
global GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
if GLOBAL_EP < EP_MAX:
UPDATE_EVENT.wait() # wait until get batch of data
self.sess.run(self.update_oldpi_op) # copy pi to old pi
data = [QUEUE.get() for _ in range(QUEUE.qsize())] # collect data from all workers
data = np.vstack(data)
s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
# update actor and critic in a update loop
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
UPDATE_EVENT.clear() # updating finished
GLOBAL_UPDATE_COUNTER = 0 # reset counter
ROLLING_EVENT.set() # set roll-out available
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return norm_dist, params
def choose_action(self, s):
s = s[np.newaxis, :]
a = self.sess.run(self.sample_op, {self.tfs: s})[0]
return np.clip(a, -2, 2)
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
训练游戏得到的效果还是很稳定的

Worker和A3C中的Worker没太大区别,但这里并未使用多线程,所以有点出入。
class Worker(object):
def __init__(self, wid):
self.wid = wid
self.env = gym.make(GAME).unwrapped
self.ppo = GLOBAL_PPO
def work(self):
global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
s = self.env.reset()
ep_r = 0
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
if not ROLLING_EVENT.is_set(): # while global PPO is updating
ROLLING_EVENT.wait() # wait until PPO is updated
buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer, use new policy to collect data
a = self.ppo.choose_action(s)
s_, r, done, _ = self.env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r + 8) / 8) # normalize reward, find to be useful
s = s_
ep_r += r
GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size, no need to wait other workers
if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
v_s_ = self.ppo.get_v(s_)
discounted_r = [] # compute discounted reward
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
buffer_s, buffer_a, buffer_r = [], [], []
QUEUE.put(np.hstack((bs, ba, br))) # put data in the queue
if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
ROLLING_EVENT.clear() # stop collecting data
UPDATE_EVENT.set() # globalPPO update
if GLOBAL_EP >= EP_MAX: # stop training
COORD.request_stop()
break
# record reward changes, plot later
if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
GLOBAL_EP += 1
print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
多线程版本的例子
EP_MAX = 1000
EP_LEN = 500
N_WORKER = 4 # parallel workers
GAMMA = 0.9 # reward discount factor
A_LR = 0.0001 # learning rate for actor
C_LR = 0.0001 # learning rate for critic
MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
UPDATE_STEP = 15 # loop update operation n-steps
EPSILON = 0.2 # for clipping surrogate objective
GAME = 'CartPole-v0'
env = gym.make(GAME)
S_DIM = env.observation_space.shape[0]
A_DIM = env.action_space.n
class PPONet(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
w_init = tf.random_normal_initializer(0., .1)
lc = tf.layers.dense(self.tfs, 200, tf.nn.relu, kernel_initializer=w_init, name='lc')
self.v = tf.layers.dense(lc, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
self.pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.int32, [None, ], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
a_indices = tf.stack([tf.range(tf.shape(self.tfa)[0], dtype=tf.int32), self.tfa], axis=1)
pi_prob = tf.gather_nd(params=self.pi, indices=a_indices) # shape=(None, )
oldpi_prob = tf.gather_nd(params=oldpi, indices=a_indices) # shape=(None, )
ratio = pi_prob/(oldpi_prob + 1e-5)
surr = ratio * self.tfadv # surrogate loss
self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
self.sess.run(tf.global_variables_initializer())
def update(self):
global GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
if GLOBAL_EP < EP_MAX:
UPDATE_EVENT.wait() # wait until get batch of data
self.sess.run(self.update_oldpi_op) # copy pi to old pi
data = [QUEUE.get() for _ in range(QUEUE.qsize())] # collect data from all workers
data = np.vstack(data)
s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + 1].ravel(), data[:, -1:]
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
# update actor and critic in a update loop
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
UPDATE_EVENT.clear() # updating finished
GLOBAL_UPDATE_COUNTER = 0 # reset counter
ROLLING_EVENT.set() # set roll-out available
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l_a = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
a_prob = tf.layers.dense(l_a, A_DIM, tf.nn.softmax, trainable=trainable)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return a_prob, params
def choose_action(self, s): # run by a local
prob_weights = self.sess.run(self.pi, feed_dict={self.tfs: s[None, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
class Worker(object):
def __init__(self, wid):
self.wid = wid
self.env = gym.make(GAME).unwrapped
self.ppo = GLOBAL_PPO
def work(self):
global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
s = self.env.reset()
ep_r = 0
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
if not ROLLING_EVENT.is_set(): # while global PPO is updating
ROLLING_EVENT.wait() # wait until PPO is updated
buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer, use new policy to collect data
a = self.ppo.choose_action(s)
s_, r, done, _ = self.env.step(a)
if done: r = -10
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r-1) # 0 for not down, -11 for down. Reward engineering
s = s_
ep_r += r
GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size, no need to wait other workers
if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE or done:
if done:
v_s_ = 0 # end of episode
else:
v_s_ = self.ppo.get_v(s_)
discounted_r = [] # compute discounted reward
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, None]
buffer_s, buffer_a, buffer_r = [], [], []
QUEUE.put(np.hstack((bs, ba, br))) # put data in the queue
if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
ROLLING_EVENT.clear() # stop collecting data
UPDATE_EVENT.set() # globalPPO update
if GLOBAL_EP >= EP_MAX: # stop training
COORD.request_stop()
break
if done: break
# record reward changes, plot later
if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
GLOBAL_EP += 1
print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
if __name__ == '__main__':
GLOBAL_PPO = PPONet()
UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
UPDATE_EVENT.clear() # not update now
ROLLING_EVENT.set() # start to roll out
workers = [Worker(wid=i) for i in range(N_WORKER)]
GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
GLOBAL_RUNNING_R = []
COORD = tf.train.Coordinator()
QUEUE = queue.Queue() # workers putting data in this queue
threads = []
for worker in workers: # worker threads
t = threading.Thread(target=worker.work, args=())
t.start() # training
threads.append(t)
# add a PPO updating thread
threads.append(threading.Thread(target=GLOBAL_PPO.update,))
threads[-1].start()
COORD.join(threads)
# plot reward change and test
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
env = gym.make('CartPole-v0')
while True:
s = env.reset()
for t in range(1000):
env.render()
s, r, done, info = env.step(GLOBAL_PPO.choose_action(s))
if done:
break
总结
系统的去学习强化学习的想法是去试着学完之后玩一下超级玛丽,然鹅,哎,学完吧,这些小游戏完全无法引起我的兴趣,看看之后有没有更好的例子去学习吧。