模拟实现vector
目录
- 模拟实现vector的结构
- 实现接口函数
-
- 构造和析构函数
- 迭代器
- operator[]
- reserve和resize
- 插入和删除
- 拷贝构造
- 赋值重载
- 使用memcpy拷贝导致的问题
模拟实现vector的结构
在设计vector前,我们可以看一下STL源码中,看看原作者是怎么设计vector的
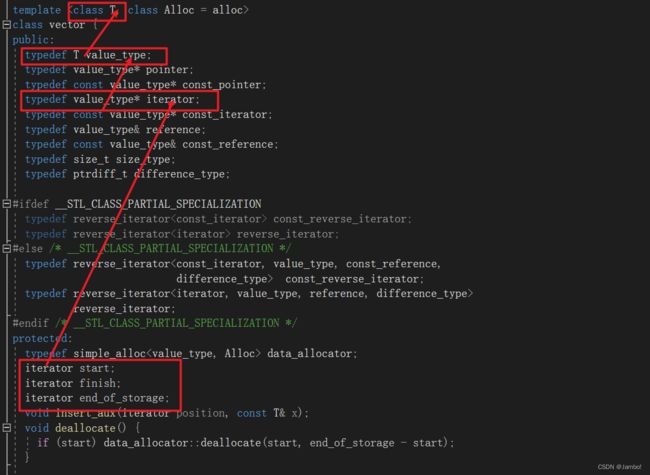
在源码中可以看见有三个iterator类型的成员变量:
iterator start;
iterator finish;
iterator end_of_storage;
iterator是在前面经过typedef过的,iterator实际类型是value_type*
typedef value_type* iterator;
value_type又是经过typedef过的,其类型就是模板参数类型T
typedef T value_type;
所以三个成员变量的类型就是模板参数类型的指针T*
我们这里模拟实现也像源码中一样,使用三个模板参数类型的指针start,finish,end_of_storage
start指向vector中的首元素,finish指向vector中最后一个元素的下一个位置,end_of_storage指向可用容量最后位置的下一个位置
虽然没有直接使用以往的_a,_size,_capaciry为成员变量
但是使用指针也可以表示出size和capacity:_finish - _start就是size,_end_of_storage - _start就是capacity
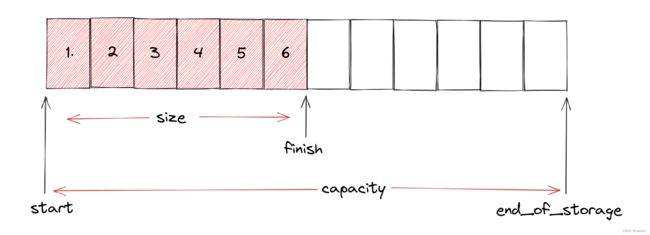
到这里,我们就得到了基本的vector框架:
namespace my_vector
{
template<class T>
class vector
{
typedef T* iterator;
typedef const T* const_iterator;
public:
size_t size()const
{
return _finish - _start;
}
size_t capacity()const
{
return _end_of_storage - _start;
}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}
接下来我们就是实现部分接口函数
实现接口函数
构造和析构函数
无参构造:
vector()
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{}
用n个t构造:
vector(size_t n, const T& t = T())
{
_start = new T[n];
for (size_t i = 0; i < n; i++)
{
_start[i] = t;
}
_finish = _end_of_storage = _start + n;
}
析构函数:
~vector()
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
迭代器
begin()就是返回_start
end()就是返回_finish
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin()const
{
return _start;
}
const_iterator end()const
{
return _finish;
}
operator[]
T& operator[](size_t pos)
{
assert(pos >= 0 && pos < size());
return _start[pos];
}
const T& operator[](size_t pos)const
{
assert(pos >= 0 && pos < size());
return _start[pos];
}
reserve和resize
reserve
void reserve(size_t n)
{
if (n > capacity())
{
T* tmp = new T[n];
if (_start)
{
memcpy(tmp, _start, sizeof(T) * size());
delete _start;
}
_start = tmp;
_finish = _start + size();
_end_of_storage = _start + n;
}
}
上面的写法有一个BUG:
就是:_finish = _start + size();
在size()函数中,返回的值是_finish-_start
_finish = _start + _finish-_start就是_finish = _finish,会出错
所以这里不能_start直接加size()
我们可以在前面保存一份size()的值,最后去加前面保存过的长度,这样就不会发生错误了。
void reserve(size_t n)
{
if (n > capacity())
{
T* tmp = new T[n];
int oldlen = _finish - _start;
if (_start)
{
memcpy(tmp, _start, sizeof(T) * size());
delete[] _start;
}
_start = tmp;
_finish = _start + oldlen;//这里不可以使用_finish = _start + size(),因为size()就是_finish-_start ,_finish = _start + _finish-_start就是_finish = _finish会出错
_end_of_storage = _start + n;
}
}
resize
void resize(size_t n, const T& value = T())
{
if (n <= size())
{
_finish = _start + n;
}
else
{
reserve(n);
while (_finish != _start + n)
{
*_finish = value;
++_finish;
}
}
}
插入和删除
insert
void insert(iterator pos, const T& t)
{
assert(pos >= _start && pos <= _finish);
//检查扩容
if (size() == capacity())
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
//将数据向后挪一位
iterator end = _finish-1;
for (end >= pos)
{
*(end + 1) = *end;
end--;
}
//插入
*pos = t;
_finish++;
}
上面的写法是错误的
因为如果经过了扩容,那么这个时候参数迭代器pos就失效了

所以我们就要在函数内对失效的迭代器进行处理
处理的方法是通过_start到pos的距离,因为扩容完之后,虽然迭代器失效了,但是数据的个数、内容不变,pos指向的数据到_start的距离是不变的,这里我们可以用oldlen存储这个距离
所以新空间的_start + oldlen 就是指向原本那个位置的数据的新迭代器

iterator insert(iterator pos, const T& t)
{
assert(pos >= _start && pos <= _finish);
if (_finish == _end_of_storage)
{
size_t OldLen = pos - _start;//防止迭代器失效
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
pos = _start + OldLen;//防止迭代器失效
//如果经过扩容后,在内存上的数据其实不在原来的那个位置了,这时pos就变成了野指针,所以我们需要在扩容后修改pos的指向,使p修改后的os指向新空间中要插入的那个位置
}
iterator end = _finish-1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
*pos = t;
_finish++;
return pos;
}
//这里返回iterator类型的pos是因为如果在insert后,再使用形参pos可能出现错误,这个pos形参迭代器有可能已经失效了(因为扩容了)
//为了满足用户需要使用形参的迭代器,所以会返回一个处理过的不会失效的迭代器
erase
erase操作也会导致迭代器失效
这里的失效时由于导致删除最后一个元素,导致指向它的迭代器变成野指针
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator cur = pos;
while (cur < _finish)
{
*cur = *(cur + 1);
cur++;
}
_finish--;
return pos;
}
通过复用insert和erase,就可以实现push_back和pop_back
void push_back(const T& t)
{
/*if (_finish == _end_of_storage)
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = t;
_finish++;*/
insert(end(), t);
}
void pop_back()
{
erase(end()-1);
}
拷贝构造
vector(const vector<T>& v)
:_start(nullptr)
,_finish(nullptr)
,_end_of_storage(nullptr)
{
T* tmp = new T[v.size()];
memcpy(tmp, v._start, sizeof(T) * v.size());
_start = tmp;
_finish = _start + v.size();
_end_of_storage = _start + v.capacity();
}
赋值重载
/*vector& operator=(const vector& v)
{
if (this != &v)
{
T* tmp = new T[v.size()];
memcpy(tmp, v._start, sizeof(T) * v.size());
_start = tmp;
_finish = _start + v.size();
_end_of_storage = _start + v.capacity();
}
return *this;
}*/
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
}
//赋值重载现代写法
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
使用memcpy拷贝导致的问题
如果vector中存储数据的类型是含有动态资源,例如:string等
那么使用上面的代码就会出问题,因为使用了memcpy进行拷贝
以往使用memcpy的情况,动态空间中存储的非动态资源
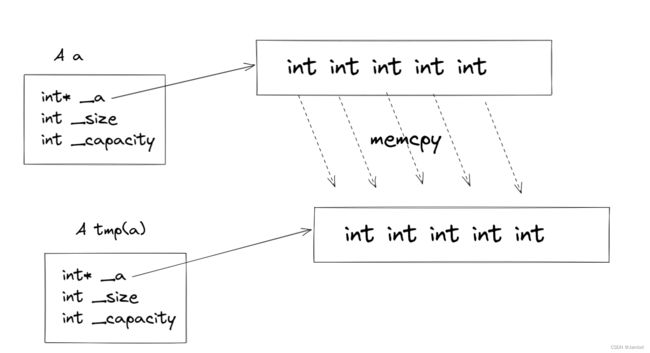
这样不会有问题
如果T的类型是含有动态资源的类型,如string。
如果这里使用memcpy就会导致string对象的浅拷贝
对于内置类型,_start就是指向堆空间上的指针,使用memcpy可以使堆上的值拷贝到tmp中
而对于strng这样深拷贝的类型,_start[i]中存的是_str,_size,_capacity,使用memcpy只会使_str按照字节序进行拷贝,按照字节序拷贝只会把_str的值,也就是动态空间的地址拷贝过去,不会对_str进行深拷贝
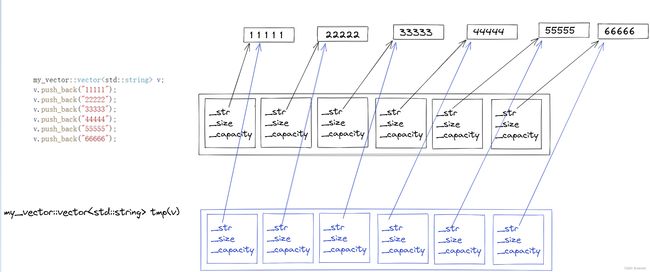
这样有2个指针指向同一块动态空间,一块空间析构2次,会报错
解决方法:在扩容、拷贝构造等需要一个空间往另一空间深拷贝的操作中,不再使用memcpy
可以这样:
for (size_t i = 0; i < size(); i++)
{
tmp[i] = _start[i];
}
T是strng这样深拷贝的类型,调用的是string赋值重载,实现string对象的深拷贝