数据科学库Python——Pandas数据合并与分组聚合
假设现在我们有一组从2006年到2016年1000部最流行的电影数据
如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
数据来源:https://www.kaggle.com/damianpanek/sunday-eda/data
第一步:先读取数据,了解基本信息
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
df.head(1)输出结果为:

包含的信息分别有:rank、Tittle等12条信息。
df.shape
>>> (1000, 12) 一共有1000条数据,每条数据包含12列的信息。
我们要统计电影分类,先看看Genre数据的大致模样。
print(df["Genre"].head(3))>>> 0 Action,Adventure,Sci-Fi 1 Adventure,Mystery,Sci-Fi 2 Horror,Thriller 3 Animation,Comedy,Family 4 Action,Adventure,Fantasy Name: Genre, dtype: object
对于这一组电影数据,我们希望统计电影分类(genre)的情况,应该如何处理数据?
思路:重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1。
统计分类的列表
temp_list = df["Genre"].str.split(",").tolist()
print(temp_list)>>>

每一部电影的分类有多个,我们这个时候为了方便表示,可以用一个数组来表示每一部电影的分类情况。
genre_list = list(set([i for j in temp_list for i in j]))
genre_list[0:3]>>>
['Family', 'Music', 'Horror']
构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns = genre_list)
zeros_df.head()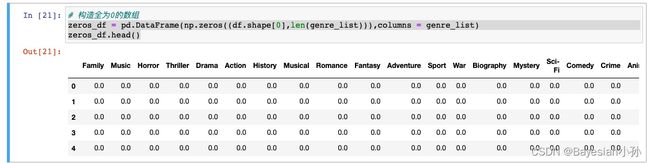
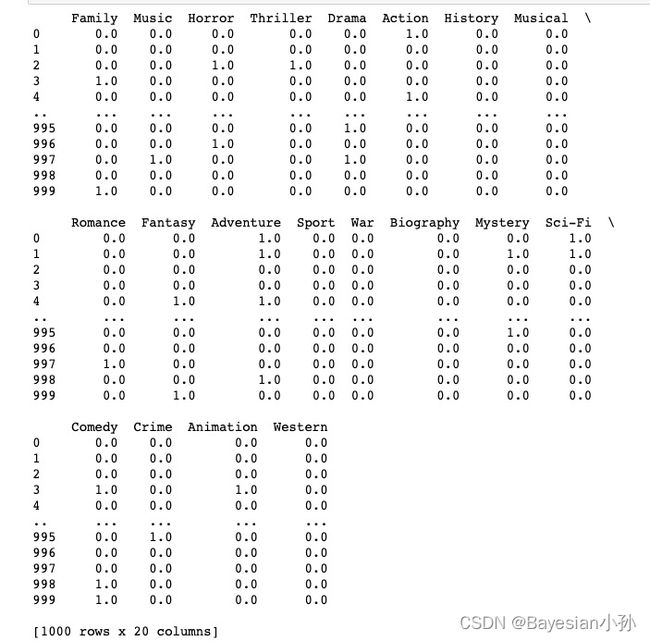
# 给每个电影出现分类的位置赋值1
for i in range(df.shape[0]):
zeros_df.loc[i,temp_list[i]] = 1
pass
print(zeros_df)>>>
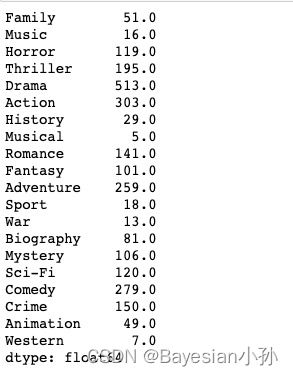
#统计每个分类的电影的数量和
genre_count = zeros_df.sum(axis=0)
print(genre_count)>>>
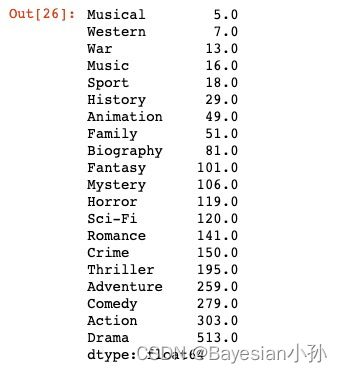
#排序
genre_count = genre_count.sort_values()
_x = genre_count.index
_y = genre_count.values
genre_count.head(20)>>>
#画图
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.8,color="orange")
plt.xticks(range(len(_x)),_x)
plt.show()>>>
