Scikit-learn强化学习代码批注及相关练习
一、游戏介绍
木棒每保持平衡1个时间步,就得到1分。每一场游戏的最高得分为200分每一场游戏的结束条件为木棒倾斜角度大于41.8°或者已经达到200分。最终获胜条件为最近100场游戏的平均得分高于195。代码中env.step(),的返回值就分别代表了。观测Observation:当前step执行后,环境的观测。奖励Reward:执行上一步动作(action)后,智能体(agent)获得的奖励,不同的环境中奖励值变化范围也有不同,但是强化学习的目标就是总奖励值最大。完成Done表示是否需要将环境重置env.reset,大多数情况下,当Done为True时,就表明当前回合(episode)结束。信息Info:针对调试过程的诊断信息,在标准的智能体仿真评估当中不会使用到这个info。


二、代码批注
import gym
import numpy as np
env = gym.make('CartPole-v0')
max_number_of_steps = 200 # 每一场游戏的最高得分
#---------获胜的条件是最近100场平均得分高于195-------------
goal_average_steps = 195
num_consecutive_iterations = 100
#----------------------------------------------------------
num_episodes = 5000 # 共进行5000场游戏
last_time_steps = np.zeros(num_consecutive_iterations) # 只存储最近100场的得分(可以理解为是一个容量为100的栈)
# q_table是一个256*2的二维数组
# 离散化后的状态共有4^4=256中可能的取值,每种状态会对应一个行动
# q_table[s][a]就是当状态为s时作出行动a的有利程度评价值
# 我们的AI模型要训练学习的就是这个映射关系表
q_table = np.random.uniform(low=-1, high=1, size=(4 ** 4, env.action_space.n))
# 分箱处理函数,把[clip_min,clip_max]区间平均分为num段,位于i段区间的特征值x会被离散化为i
def bins(clip_min, clip_max, num):
return np.linspace(clip_min, clip_max, num + 1)[1:-1]
# 离散化处理,将由4个连续特征值组成的状态矢量转换为一个0~~255的整数离散值
def digitize_state(observation):
# 将矢量打散回4个连续特征值
cart_pos, cart_v, pole_angle, pole_v = observation
# 分别对各个连续特征值进行离散化(分箱处理)
digitized = [np.digitize(cart_pos, bins=bins(-2.4, 2.4, 4)),
np.digitize(cart_v, bins=bins(-3.0, 3.0, 4)),
np.digitize(pole_angle, bins=bins(-0.5, 0.5, 4)),
np.digitize(pole_v, bins=bins(-2.0, 2.0, 4))]
# 将4个离散值再组合为一个离散值,作为最终结果
return sum([x * (4 ** i) for i, x in enumerate(digitized)])
# 根据本次的行动及其反馈(下一个时间步的状态),返回下一次的最佳行动
def get_action(state, action, observation, reward):
next_state = digitize_state(observation) # 获取下一个时间步的状态,并将其离散化
next_action = np.argmax(q_table[next_state]) # 查表得到最佳行动
#-------------------------------------训练学习,更新q_table----------------------------------
alpha = 0.2 # 学习系数α
gamma = 0.99 # 报酬衰减系数γ
q_table[state, action] = (1 - alpha) * q_table[state, action] + alpha * (reward + gamma * q_table[next_state, next_action])
# -------------------------------------------------------------------------------------------
return next_action, next_state
def get_action2(state, action, observation, reward, episode):
next_state = digitize_state(observation)
epsilon = 0.2*(0.95**episode) # ε-贪心策略中的ε
if epsilon <= np.random.uniform(0, 1):
next_action = np.argmax(q_table[next_state])
else:
next_action = np.random.choice([0, 1])
#-------------------------------------训练学习,更新q_table----------------------------------
alpha = 0.2 # 学习系数α
gamma = 0.99 # 报酬衰减系数γ
q_table[state, action] = (1 - alpha) * q_table[state, action] + alpha * (reward + gamma * q_table[next_state, next_action])
# -------------------------------------------------------------------------------------------
return next_action, next_state
# 重复进行一场场的游戏
for episode in range(num_episodes):
observation = env.reset() # 初始化本场游戏的环境
state = digitize_state(observation) # 获取初始状态值
action = np.argmax(q_table[state]) # 根据状态值作出行动决策
episode_reward = 0
# 一场游戏分为一个个时间步
for t in range(max_number_of_steps):
env.render() # 更新并渲染游戏画面
observation, reward, done, info = env.step(action) # 获取本次行动的反馈结果
print(reward)
if done:
reward = -200
action, state = get_action2(state, action, observation, reward, episode) # 作出下一次行动的决策
episode_reward += reward
if done:
# print('%d Episode finished after %f time steps / mean %f' % (episode, t + 1, last_time_steps.mean()))
last_time_steps = np.hstack((last_time_steps[1:], [episode_reward])) # 更新最近100场游戏的得分stack
break
# 如果最近100场平均得分高于195
if (last_time_steps.mean() >= goal_average_steps):
# print('Episode %d train agent successfuly!' % episode)
break
print('Failed!')
三、问题回答
代码中两个策略get_action和get_action2分别对应哪个算法?去除第73-74行游戏结束的reward值赋值,结果有什么变化?
get_action:Q-learning
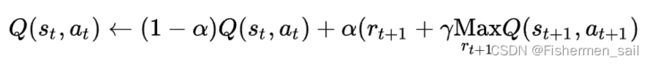
上面的α被称为学习系数,γ被称为报酬衰减系数,rt为时间步为t时得到的报酬。如果在时间步t时,状态为st,我们采取的行动为at,本次行动的有利程度记为Q(st,at)。

get_action2:Q-learning +ε-贪心策略
在get_action2中加入了贪心的策略。以ε的概率以均匀概率随机选一个方向进行移动;以1-ε的概率选择目前为止探索到的对于当前状态的最佳行动方向进行移动。

如果取去掉reward,得不到反馈。在main函数中的开头,这里的意思其实就是每次获得一个最好的action,然后计算,用更好的去填补他。这里evn.step每次返回的reward都是1,if done其实就代表了游戏被迫结束,如果不减值,那么相当于对模型没有反馈,模型会每次会找最好的值,但呢个最好的值是随机算出来的,最终的结果会卡在一个比较低的分数附近上上下下。

