spring如何解决循环依赖
本文将从spring如何解决循环依赖,以及那些情况下的循环依赖无法解决来分析,由于笔者水平有限,若有错误的地方望各位纠正并讨论。
一、循环引用示列
众所周知再spring中单列bean是支持循环依赖的,下面看代码:
A.class代码:
@Component
public class A {
@Autowired
private B b;
public A(){
System.out.println("init A");
}
}A中注入了一个B;
B.class代码:
@Component
public class B {
@Autowired
private A a;
public B() {
System.out.println("init B");
}
}B中注入了A;
ZKConfig.class配置类代码
@Configuration
@ComponentScan(value = "com.config")
public class ZkConfig {
public static void main(String... args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
//往容器注册一个配置类
ac.register(ZkConfig.class);
ac.refresh();
System.out.println(ac.getBean(A.class));
System.out.println(ac.getBean(B.class));
}
}
打印结果:
init A
init B
com.config.A@44a664f2
com.config.B@7f9fcf7f通过打印结果,可以发现循环引用是没问题的。但如果我们想关闭循环引用呢?
只需调用一下api进行设置就行:
@Configuration
@ComponentScan(value = "com.config")
public class ZkConfig {
public static void main(String... args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(ZkConfig.class);
//关闭循环引用
ac.setAllowCircularReferences(false);
ac.refresh();
System.out.println(ac.getBean(A.class));
System.out.println(ac.getBean(B.class));
}
}
就会看到报错信息:
Error creating bean with name 'a': Unsatisfied dependency expressed through field 'b'; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'b': Unsatisfied dependency expressed through field 'a'; nested exception is org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
这个错就是无法支持循环引用报的错,那spring是如何解决的呢?接着来分析。
二、spring的生命周期
要了解spring如何解决循环依赖的,那么必须要先了解bean如何被创建的即bean的生命周期,下面简单画一下spring的生命周期

1.实列化容器:创建一个spring ApplicationContext 即new AnnotationApplicationContext();创建applicationContext时父类会实列化一个DefaultListableFactory()。
2.调用ac.register()注册一个配置类,后续通过这个类找到我们所有需要注入到容器的bean,也可以通过ac.scanner()扫描包,原理都是一样
3.通过spring内置的beanFactory的后置处理期ConfigurationClassPostProcess解析配置类
4.将解析到的bean封装成beanDefinition放入beanfactory的beanDefinitionMap中用于后续bean的创建
5.遍历beanDefiniton,验证beanDefinition,比如判断这个bean是否为单列或者抽象以及懒加载,就是判断是否需要现在进行实列化
6.将需要进行实列化的bean,首先需推导出一个用来实列化的构造函数进行实列化
7.此时还是还是普通的对象,属性还为空,除非是通过构造函数进行依赖注入的bean,需要进行属性注入,大多数情况下,循环依赖就发生在这里,依赖注入主要是通过AutowireAnnotationBeanPostProcessor和CommonAnnotationBeanPostOrocessor进行的,依赖注入实际上还是通过getBean()从容器中获取一个bean出来,然后通过反射给属性赋值
7.若bean实现了Aware接口会进行回调
8.执行初始化方法如@PostConstruct和实现了isInitializingBean接口和通过xml注入的bean,设置了init-method属性的
9.执行bean后置处理期的after方法,若未出现循环依赖没有提前暴露bean,aop就会发生再这里
10.将bean放入单列池中
11.注册bean的销毁逻辑,销毁bean
大致了解了spring的生命周期后现在我们来讨论一下依赖注入:
下面先看一下方法栈的调用图

可以看到真正创建一个bean之前会先通过红色标记的#DefaultSingleBeanRegistry.getSingleton()先获取一次:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//从一级缓存中获取
Object singletonObject = this.singletonObjects.get(beanName);
//若一级缓存中没有,且当前bean正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//从二级缓存中获取
singletonObject = this.earlySingletonObjects.get(beanName);
/**
* 二级缓存中没有,且允许循环依赖
*二级缓存作用:若涉及到三个及以上对象循环依赖,此时就可以直接从二级缓存中获取到值
*/
if (singletonObject == null && allowEarlyReference) {
//从三级缓存中获取,这里获取到的是一个对象工厂
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
/**
* 从对象工厂中获取到一个半成品bean
*/
singletonObject = singletonFactory.getObject();
//放入到二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//从三级缓存中移除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}我们先看一下这里面涉及到的三个map:
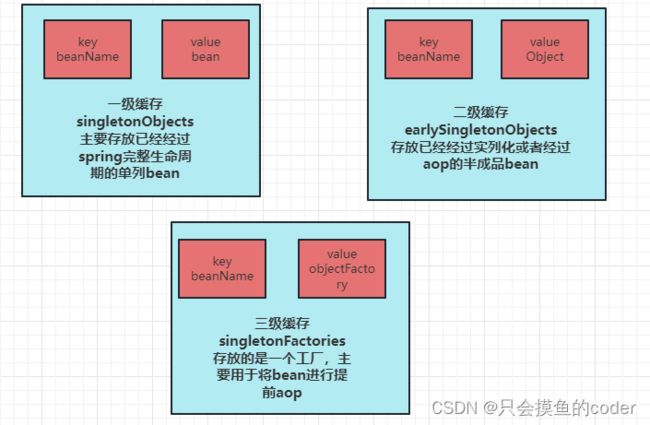
通过代码层面我们可以看到,当从一级缓存获取获取bean实列后进行if判断
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) bean还未创建完成singletonObject一定为空,但这isSingletonCurrentlyInCreation(beanName)是是如何判断的呢?点进去可以看到从判断是否再一个set集合中存在
singletonsCurrentlyInCreation.contains(beanName);
通过集合名字可以很清楚的了解到这个集合存储得是正在创建的bean的名字,那么是从那里put进去的呢?
是在它的重载方法#DefaultSingleBeanRegistry.getSingleton(String beanName, ObjectFactory singletonFactory)中的beforeSingletonCreation()实列化前会先将beanName放入集合中表示正在创建
beforeSingletonCreation(beanName);
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}但是bean第一次创建这个肯定也为空 不会这个if.那接下来我们看一下二级缓存是在那里放入的
可以看到是在对象实列化后
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//添加三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
//添加三级缓存 将匿名对象singletonFactory加入,就是一系列BeanPostprocessor
this.singletonFactories.put(beanName, singletonFactory);
//从二级级缓存中移除
this.earlySingletonObjects.remove(beanName);
//添加到注册的单列集合中
this.registeredSingletons.add(beanName);
}
}
}这里boolean判断时有一个属性allowCircularReferences ,这也在前面我们通过api将这个属性设置为false时循环依赖就会报错的原因,实列化前就将bean放入set集合中了,earlySingletonExposure 这个属性为true,objectFactory就会被添加到二级缓存中,下面我们我们看一看添加的到底是一个什么玩意。
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}代码执行到ObjectFactory.getObject()方法时就会调用getEarlyBeanRefrence(),这里主要就是执行实现了SmartInstantiationAwareBeanPostProcessor的后置处理期,aop就会再这里执行,具体aop怎么执行的就不再这里讨论了 aop的内容点有点多,后面可以单独出一篇文章整理。
至此三级缓存添加完毕,接下来看依赖注入,依赖注入就可以简单理解成调用getBean()从容器中获取,现在我们就来梳理循环引用时依赖注入是如何完成的。

结合上面的代码和图可以看出a注入b时,b进行创建,b再次注入a此时时调用getBean()方法,流程自然会进入前面画的方法栈的调用图的#DefaultSingleBeanRegistry.getSingleton(String beanName, boolean allowEarlyReference)方法。此时我们再来看这段代码
//此时beanName=a,allowEarlyReference=true
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//从单列池中中无法获取到a
Object singletonObject = this.singletonObjects.get(beanName);
//此时a==null,但是此时a是正在创建中的所以 isSingletonCurrentlyInCreation(a)==true
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//从二级缓存中获取,此时未放入二级缓存,singletonObject==null
singletonObject = this.earlySingletonObjects.get(beanName);
//从前面的结果可以看出,这里肯定会进
if (singletonObject == null && allowEarlyReference) {
/**从从三级缓存中获取,beanName==a
*a再实列化后就会添加一个对象工厂singletonFactories中
*所以这里会返回一个ObjectFactory对象,此时singletonFactory不等于空
**/
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//调用getObject()方法,实则会调用到前面传入的匿名函数getEarlyBeanReference()方法中
//但由于a并未存在aop的逻辑,所以这里会返回一个a对象,就是实列化后的对象a
singletonObject = singletonFactory.getObject();
//放入到二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//从三级缓存中移除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}这里就会返回一个半成品的对象a,b完成属性注入后紧接着做b的生命周期的其它事,完成后将b放入单列池中,只不过b中属性a还是一个半成品;
此时栈调用就会返回到 a 属性注入b那里,a的属性注入也完成了,a也做自己生命周期的其他事,完成后将a放入单列池中,此时a和b的bean创建都完成了,b中的a也就是一个具有完整生命周期的bean,因为b中的属性a的指针始终指向的这个对象a。
有的读者可能就会问那么这个二级缓存的意义再那里呢,似乎也没用到?
当我们存在三个以及三个以上的bean循环引用时,这个三级缓存就有用了吧比如:
public A{
@Autowired
private B b;
}
public B{
@Autowired
private A a;
@Autowired
private C c;
}
public C{
@Autowired
private A a;
}
当B注入C时,C进行依赖注入时,a就可以直接从三级缓存中获取当我们完成三级缓存的beanPostProcessor的方法调用时,放入二级缓存,这样其它bean依赖这个bean时就可以直接从二级缓存earlySingletonObjects中获取,没必要再执行三级缓存的逻辑了提高了获取的效率。
那么这个三级缓存的作用,为什么不把对象直接放在二级缓存,那个这个三级缓存就可以不用了?
我么可以想象一下如果a需要进行aop,三级缓存中直接存储的就是一个普通对象a,b对a注入完毕,b中的属性a指针指向的是一个普通的对象,
b的生命周期走完后,此时a进行aop,此时a就是一个代理对象,那么b指向的a就完全没意义了,所以这里需要一个工厂对象对a进行提前暴露,好让b中属性a指向的对象也是一个代理对象
至于为什么spring不直接先提前暴露,再放入二级缓存,这样就可以不用到三级缓存了,这点笔者就不是很清楚了 我猜测,可能作者认为循环依赖且依赖的bean需进行aop的情况比较少,作者还是希望,没有循环依赖的情况下,bean还是最后进行aop,不想提前暴露
这段提前暴露的逻辑也可能不止aop处理
什么情况下循环依赖会失败
1.通过构造函数注入,创建bean之前,这个bean是需要进行实列化,通过构造函数相互引用的bean,都无法完成实列化导致发生死锁所以构造函数注入是不会走添加三级缓存那段逻辑,注定无法完成循环依赖,原型bean注入同样也不走添加三级缓存所以也无法支持循环依赖,
2.当加了@Transaction和@Async的两个bean进行循环引用时,
也可能会出问题,当@Async的bean比@Transaction先进行创建时就会报错
@Async的代理是通过一个单独的后置处理期AsyncAnnotationBeanPostProcessor添加的切面,
不会走提前暴露就是getEarlyBeanRefrence()那段逻辑
而@Transaction是会走提前暴露的,这里就不详细展开了感兴趣的可以自行了解