16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
文章目录
- Flink 系列文章
- 一、Table & SQL Connectors 示例:JDBC
-
- 1、maven依赖(java编码依赖)
- 2、创建 JDBC 表
-
- 1)、创建jdbc表,并插入、查询
- 2)、批量插入表数据
- 3)、JDBC 表在时态表关联中作为维表
- 3、连接器参数
- 4、已弃用的配置
-
- 5、特性
- 1)、键处理
- 2)、分区扫描
- 3)、Lookup Cache
- 4)、幂等写入
- 5、JDBC Catalog
-
- 1)、JDBC Catalog 的使用
- 2)、JDBC Catalog for PostgreSQL
- 3)、JDBC Catalog for MySQL
- 6、数据类型映射
本文简单的介绍了flink sql读取外部系统的jdbc示例(每个示例均是验证通过的,并且具体给出了运行环境的版本)。
本文依赖环境是hadoop、kafka、mysql环境好用,如果是ha环境则需要zookeeper的环境。
一、Table & SQL Connectors 示例:JDBC
1、maven依赖(java编码依赖)
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-jdbcartifactId>
<version>3.1.0-1.17version>
dependency>
在连接到具体数据库时,也需要对应的驱动依赖,目前支持的驱动如下:

驱动jar需放在flink的安装目录lib下,且需要重启服务。
本示例jar包有
flink-connector-jdbc_2.11-1.13.6.jar
mysql-connector-java-5.1.5.jar 或
mysql-connector-java-6.0.6.jar(1.17版本中使用的mysql驱动,用上面mysql驱动有异常信息)
2、创建 JDBC 表
JDBC table 可以按如下定义,以下示例中包含创建表、批量插入以及left join的维表。
1)、创建jdbc表,并插入、查询
-- 在 Flink SQL 中注册一张 MySQL 表 'users'
CREATE TABLE MyUserTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'users'
);
-------------------具体事例----------------------------------
-- 在 Flink SQL 中注册一张 MySQL 表 'user'
CREATE TABLE Alan_JDBC_User_Table (
id BIGINT,
name STRING,
age INT,
balance DOUBLE,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.10.44:3306/test',
'table-name' = 'user'
);
-- mysql中的数据
mysql> select * from user;
+----+-------------+------+---------+-----------------------+------------+
| id | name | age | balance | email | pwd |
+----+-------------+------+---------+-----------------------+------------+
| 1 | aa6 | 61 | 60000 | 6@163.com | 123456 |
| 2 | aa4 | 71 | 70000 | 7@163.com | 7123 |
| 4 | test | NULL | NULL | NULL | NULL |
| 5 | test2 | NULL | NULL | NULL | NULL |
| 7 | alanchanchn | 19 | 800 | alan.chan.chn@163.com | vx |
| 8 | alanchan | 19 | 800 | alan.chan.chn@163.com | sink mysql |
+----+-------------+------+---------+-----------------------+------------+
6 rows in set (0.00 sec)
---------在flink sql中建表并查询--------
Flink SQL> CREATE TABLE Alan_JDBC_User_Table (
> id BIGINT,
> name STRING,
> age INT,
> balance DOUBLE,
> PRIMARY KEY (id) NOT ENFORCED
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:mysql://192.168.10.44:3306/test',
> 'table-name' = 'user'
> );
[INFO] Execute statement succeed.
Flink SQL> select * from Alan_JDBC_User_Table;
+----+----------------------+--------------------------------+-------------+--------------------------------+
| op | id | name | age | balance |
+----+----------------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | aa6 | 61 | 60000.0 |
| +I | 2 | aa4 | 71 | 70000.0 |
| +I | 4 | test | (NULL) | (NULL) |
| +I | 5 | test2 | (NULL) | (NULL) |
| +I | 7 | alanchanchn | 19 | 800.0 |
| +I | 8 | alanchan | 19 | 800.0 |
+----+----------------------+--------------------------------+-------------+--------------------------------+
Received a total of 6 rows
2)、批量插入表数据
-- 从另一张表 "T" 将数据写入到 JDBC 表中
INSERT INTO MyUserTable
SELECT id, name, age, status FROM T;
---------创建数据表----------------------
CREATE TABLE source_table (
userId INT,
age INT,
balance DOUBLE,
userName STRING,
t_insert_time AS localtimestamp,
WATERMARK FOR t_insert_time AS t_insert_time
) WITH (
'connector' = 'datagen',
'rows-per-second'='5',
'fields.userId.kind'='sequence',
'fields.userId.start'='1',
'fields.userId.end'='5000',
'fields.balance.kind'='random',
'fields.balance.min'='1',
'fields.balance.max'='100',
'fields.age.min'='1',
'fields.age.max'='1000',
'fields.userName.length'='10'
);
-- 从另一张表 "source_table" 将数据写入到 JDBC 表中
INSERT INTO Alan_JDBC_User_Table
SELECT userId, userName, age, balance FROM source_table;
-- 查看 JDBC 表中的数据
select * from Alan_JDBC_User_Table;
---------------flink sql中查询----------------------------------
Flink SQL> INSERT INTO Alan_JDBC_User_Table
> SELECT userId, userName, age, balance FROM source_table;
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: e91cd3c41ac20aaf8eab79f0094f9e46
Flink SQL> select * from Alan_JDBC_User_Table;
+----+----------------------+--------------------------------+-------------+--------------------------------+
| op | id | name | age | balance |
+----+----------------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | ead5352794 | 513 | 4.0 |
| +I | 2 | 728297a8d9 | 410 | 35.0 |
| +I | 3 | 643c2226cd | 142 | 80.0 |
......
-------------验证mysql中的数据是否写入,此处只查总数----------------
mysql> select count(*) from user;
+----------+
| count(*) |
+----------+
| 2005 |
+----------+
1 row in set (0.00 sec)
3)、JDBC 表在时态表关联中作为维表
-- 1、创建 JDBC 表在时态表关联中作为维表
CREATE TABLE Alan_JDBC_User_Table (
id BIGINT,
name STRING,
age INT,
balance DOUBLE,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.10.44:3306/test',
'table-name' = 'user'
);
-----2、查询表中的数据(实际数据是之前测试的结果) -----
Flink SQL> select * from Alan_JDBC_User_Table;
+----+----------------------+--------------------------------+-------------+--------------------------------+
| op | id | name | age | balance |
+----+----------------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | ead5352794 | 513 | 4.0 |
| +I | 2 | 728297a8d9 | 410 | 35.0 |
| +I | 3 | 643c2226cd | 142 | 80.0 |
| +I | 4 | 6115f11f01 | 633 | 69.0 |
| +I | 5 | 044ba5fa2f | 74 | 71.0 |
| +I | 6 | 98a112dc87 | 729 | 54.0 |
| +I | 7 | 705326a369 | 846 | 99.0 |
| +I | 8 | 532692924f | 872 | 79.0 |
| +I | 9 | b816802948 | 475 | 67.0 |
| +I | 10 | 06906bebb2 | 109 | 57.0 |
......
-----3、创建事实表,以kafka表作为代表 -----
CREATE TABLE Alan_KafkaTable_3 (
user_id BIGINT, -- 用户id
item_id BIGINT, -- 商品id
action STRING, -- 用户行为
ts BIGINT, -- 用户行为发生的时间戳
proctime as PROCTIME(), -- 通过计算列产生一个处理时间列
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',-- 事件时间
WATERMARK FOR event_time as event_time - INTERVAL '5' SECOND -- 在eventTime上定义watermark
) WITH (
'connector' = 'kafka',
'topic' = 'testtopic',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
-----4、发送kafka消息,同时观察事实表中的数据 -----
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic testtopic
>1,1001,"login",1692593500222
>2,1002,"p_read",1692593502242
>
Flink SQL> select * from Alan_KafkaTable_3;
+----+----------------------+----------------------+--------------------------------+----------------------+-------------------------+-------------------------+
| op | user_id | item_id | action | ts | proctime | event_time |
+----+----------------------+----------------------+--------------------------------+----------------------+-------------------------+-------------------------+
| +I | 1 | 1001 | login | 1692593500222 | 2023-08-22 05:33:38.830 | 2023-08-22 05:39:54.439 |
| +I | 2 | 1002 | p_read | 1692593502242 | 2023-08-22 05:33:38.833 | 2023-08-22 05:40:41.284 |
Query terminated, received a total of 2 rows
-----5、以jdbc的维表进行关联查询事实表数据-----
SELECT
kafkamessage.user_id,
kafkamessage.item_id,
kafkamessage.action,
jdbc_dim_table.name,
jdbc_dim_table.age,
jdbc_dim_table.balance
FROM Alan_KafkaTable_3 AS kafkamessage
LEFT JOIN Alan_JDBC_User_Table FOR SYSTEM_TIME AS OF kafkamessage.proctime AS jdbc_dim_table ON kafkamessage.user_id = jdbc_dim_table.id;
Flink SQL> SELECT
> kafkamessage.user_id,
> kafkamessage.item_id,
> kafkamessage.action,
> jdbc_dim_table.name,
> jdbc_dim_table.age,
> jdbc_dim_table.balance
> FROM Alan_KafkaTable_3 AS kafkamessage
> LEFT JOIN Alan_JDBC_User_Table FOR SYSTEM_TIME AS OF kafkamessage.proctime AS jdbc_dim_table ON kafkamessage.user_id = jdbc_dim_table.id;
+----+----------------------+----------------------+--------------------------------+--------------------------------+-------------+--------------------------------+
| op | user_id | item_id | action | name | age | balance |
+----+----------------------+----------------------+--------------------------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | 1001 | login | ead5352794 | 513 | 4.0 |
| +I | 2 | 1002 | p_read | 728297a8d9 | 410 | 35.0 |
- java
该部分示例仅仅是以java实现创建表及查询,简单示例。
// 注册名为 “jdbcOutputTable” 的JDBC表
String sinkDDL = "create table jdbcOutputTable (" +
"id bigint not null, " +
"name varchar(20) , " +
"age int ,"+
"balance bigint,"+
"pwd varchar(20),"+
"email varchar(20) , PRIMARY KEY (id) NOT ENFORCED" +
") with (" +
" 'connector.type' = 'jdbc', " +
" 'connector.url' = 'jdbc:mysql://192.168.10.44:3306/test', " +
" 'connector.table' = 'user', " +
" 'connector.driver' = 'com.mysql.jdbc.Driver', " +
" 'connector.username' = 'root', " +
" 'connector.password' = '123456' )";
tenv.executeSql(sinkDDL);
String sql = "SELECT * FROM jdbcOutputTable ";
String sql2 = "SELECT * FROM jdbcOutputTable where name like '%alan%'";
Table table = tenv.sqlQuery(sql2);
table.printSchema();
DataStream<Tuple2<Boolean, Row>> result = tenv.toRetractStream(table, Row.class);
result.print();
env.execute();
//运行结果
(
`id` BIGINT NOT NULL,
`name` VARCHAR(20),
`age` INT,
`balance` BIGINT,
`pwd` VARCHAR(20),
`email` VARCHAR(20)
)
15> (true,+I[7, alanchanchn, 19, 800, vx, alan.chan.chn@163.com])
15> (true,+I[8, alanchan, 19, 800, sink mysql, alan.chan.chn@163.com])
3、连接器参数

4、已弃用的配置
这些弃用配置已经被上述的新配置代替,而且最终会被弃用。请优先考虑使用新配置。

5、特性
1)、键处理
当写入数据到外部数据库时,Flink 会使用 DDL 中定义的主键。如果定义了主键,则连接器将以 upsert 模式工作,否则连接器将以 append 模式工作。
在 upsert 模式下,Flink 将根据主键判断插入新行或者更新已存在的行,这种方式可以确保幂等性。为了确保输出结果是符合预期的,推荐为表定义主键并且确保主键是底层数据库中表的唯一键或主键。在 append 模式下,Flink 会把所有记录解释为 INSERT 消息,如果违反了底层数据库中主键或者唯一约束,INSERT 插入可能会失败。
有关 PRIMARY KEY 语法的更多详细信息,请参见 22、Flink 的table api与sql之创建表的DDL。
2)、分区扫描
为了在并行 Source task 实例中加速读取数据,Flink 为 JDBC table 提供了分区扫描的特性。
如果下述分区扫描参数中的任一项被指定,则下述所有的分区扫描参数必须都被指定。这些参数描述了在多个 task 并行读取数据时如何对表进行分区。 scan.partition.column 必须是相关表中的数字、日期或时间戳列。
scan.partition.lower-bound 和 scan.partition.upper-bound 用于决定分区的起始位置和过滤表中的数据。如果是批处理作业,也可以在提交 flink 作业之前获取最大值和最小值。
- scan.partition.column:输入用于进行分区的列名。
- scan.partition.num:分区数。
- scan.partition.lower-bound:第一个分区的最小值。
- scan.partition.upper-bound:最后一个分区的最大值。
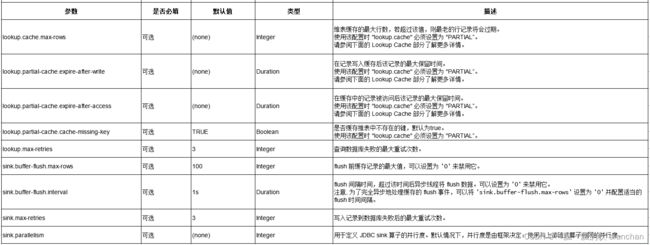
3)、Lookup Cache
JDBC 连接器可以用在时态表关联中作为一个可 lookup 的 source (又称为维表),当前只支持同步的查找模式。
默认情况下,lookup cache 是未启用的,你可以将 lookup.cache 设置为 PARTIAL 参数来启用。
lookup cache 的主要目的是用于提高时态表关联 JDBC 连接器的性能。
默认情况下,lookup cache 不开启,所以所有请求都会发送到外部数据库。
当 lookup cache 被启用时,每个进程(即 TaskManager)将维护一个缓存。Flink 将优先查找缓存,只有当缓存未查找到时才向外部数据库发送请求,并使用返回的数据更新缓存。 当缓存命中最大缓存行 lookup.partial-cache.max-rows 或当行超过 lookup.partial-cache.expire-after-write 或 lookup.partial-cache.expire-after-access 指定的最大存活时间时,缓存中的行将被设置为已过期。 缓存中的记录可能不是最新的,用户可以将缓存记录超时设置为一个更小的值以获得更好的刷新数据,但这可能会增加发送到数据库的请求数。
所以要做好吞吐量和正确性之间的平衡。
默认情况下,flink 会缓存主键的空查询结果,你可以通过将 lookup.partial-cache.cache-missing-key 设置为 false 来切换行为。
4)、幂等写入
如果在 DDL 中定义了主键,JDBC sink 将使用 upsert 语义而不是普通的 INSERT 语句。upsert 语义指的是如果底层数据库中存在违反唯一性约束,则原子地添加新行或更新现有行,这种方式确保了幂等性。
如果出现故障,Flink 作业会从上次成功的 checkpoint 恢复并重新处理,这可能导致在恢复过程中重复处理消息。强烈推荐使用 upsert 模式,因为如果需要重复处理记录,它有助于避免违反数据库主键约束和产生重复数据。
除了故障恢复场景外,数据源(kafka topic)也可能随着时间的推移自然地包含多个具有相同主键的记录,这使得 upsert 模式是用户期待的。
由于 upsert 没有标准的语法,因此下表描述了不同数据库的 DML 语法:

5、JDBC Catalog
JdbcCatalog 允许用户通过 JDBC 协议将 Flink 连接到关系数据库。
目前,JDBC Catalog 有两个实现,即 Postgres Catalog 和 MySQL Catalog。目前支持如下 catalog 方法。其他方法目前尚不支持。
// Postgres Catalog & MySQL Catalog 支持的方法
databaseExists(String databaseName);
listDatabases();
getDatabase(String databaseName);
listTables(String databaseName);
getTable(ObjectPath tablePath);
tableExists(ObjectPath tablePath);
其他的 Catalog 方法现在尚不支持。
1)、JDBC Catalog 的使用
本小节主要描述如果创建并使用 Postgres Catalog 或 MySQL Catalog。
本处描述的版本是flink 1.17,flink1.13版本只支持postgresql,在1.13版本中执行会出现如下异常:
[ERROR] Could not execute SQL statement. Reason:
java.lang.UnsupportedOperationException: Catalog for 'org.apache.flink.connector.jdbc.dialect.MySQLDialect@1bc49bc5' is not supported yet.
JDBC catalog 支持以下参数:
-
name:必填,catalog 的名称。
-
default-database:必填,默认要连接的数据库。
-
username:必填,Postgres/MySQL 账户的用户名。
-
password:必填,账户的密码。
-
base-url:必填,(不应该包含数据库名)
对于 Postgres Catalog base-url 应为 “jdbc:postgresql://:” 的格式。
对于 MySQL Catalog base-url 应为 “jdbc:mysql://:” 的格式。 -
sql
---需要将mysql-connector-java-6.0.6.jar、flink-connector-jdbc-3.1.0-1.17.jar放在flink的lib目录,并重启flink集群
CREATE CATALOG alan_catalog WITH(
'type' = 'jdbc',
'default-database' = 'test',
'username' = 'root',
'password' = '123456',
'base-url' = 'jdbc:mysql://192.168.10.44:3306'
);
USE CATALOG alan_catalog;
---------------------------------------------------
Flink SQL> CREATE CATALOG alan_catalog WITH(
> 'type' = 'jdbc',
> 'default-database' = 'test?useSSL=false',
> 'username' = 'root',
> 'password' = '123456',
> 'base-url' = 'jdbc:mysql://192.168.10.44:3306'
> );
[INFO] Execute statement succeed.
Flink SQL> show CATALOGS;
+-----------------+
| catalog name |
+-----------------+
| alan_catalog |
| default_catalog |
+-----------------+
2 rows in set
Flink SQL> use CATALOG alan_catalog;
[INFO] Execute statement succeed.
- java
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "my_catalog";
String defaultDatabase = "mydb";
String username = "...";
String password = "...";
String baseUrl = "..."
JdbcCatalog catalog = new JdbcCatalog(name, defaultDatabase, username, password, baseUrl);
tableEnv.registerCatalog("my_catalog", catalog);
// 设置 JdbcCatalog 为会话的当前 catalog
tableEnv.useCatalog("my_catalog");
- yaml
execution:
...
current-catalog: alan_catalog # 设置目标 JdbcCatalog 为会话的当前 catalog
current-database: test
catalogs:
- name:alan_catalog
type: jdbc
default-database: test
username: ...
password: ...
base-url: ...
2)、JDBC Catalog for PostgreSQL
- PostgreSQL 元空间映射
除了数据库之外,postgreSQL 还有一个额外的命名空间 schema。一个 Postgres 实例可以拥有多个数据库,每个数据库可以拥有多个 schema,其中一个 schema 默认名为 “public”,每个 schema 可以包含多张表。 在 Flink 中,当查询由 Postgres catalog 注册的表时,用户可以使用 schema_name.table_name 或只有 table_name,其中 schema_name 是可选的,默认值为 “public”。
因此,Flink Catalog 和 Postgres 之间的元空间映射如下:

Flink 中的 Postgres 表的完整路径应该是 “..
这里提供了一些访问 Postgres 表的例子:
-- 扫描 'public' schema(即默认 schema)中的 'test_table' 表,schema 名称可以省略
SELECT * FROM mypg.mydb.test_table;
SELECT * FROM mydb.test_table;
SELECT * FROM test_table;
-- 扫描 'custom_schema' schema 中的 'test_table2' 表,
-- 自定义 schema 不能省略,并且必须与表一起转义。
SELECT * FROM mypg.mydb.`custom_schema.test_table2`
SELECT * FROM mydb.`custom_schema.test_table2`;
SELECT * FROM `custom_schema.test_table2`;
3)、JDBC Catalog for MySQL
- MySQL 元空间映射
MySQL 实例中的数据库与 MySQL Catalog 注册的 catalog 下的数据库处于同一个映射层级。一个 MySQL 实例可以拥有多个数据库,每个数据库可以包含多张表。 在 Flink 中,当查询由 MySQL catalog 注册的表时,用户可以使用 database.table_name 或只使用 table_name,其中 database 是可选的,默认值为创建 MySQL Catalog 时指定的默认数据库。
因此,Flink Catalog 和 MySQL catalog 之间的元空间映射如下: 这里提供了一些访问 MySQL 表的例子(在版本1.17中完成): Flink 支持连接到多个使用方言(dialect)的数据库,如 MySQL、Oracle、PostgreSQL、Derby 等。其中,Derby 通常是用于测试目的。下表列出了从关系数据库数据类型到 Flink SQL 数据类型的类型映射,映射表可以使得在 Flink 中定义 JDBC 表更加简单。
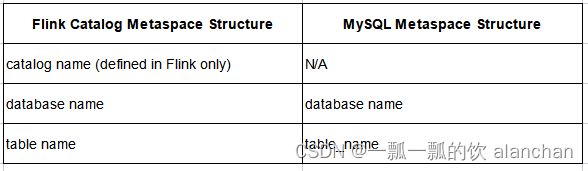
Flink 中的 MySQL 表的完整路径应该是 “”。
-- 扫描 默认数据库(test)中的 'person' 表
select * from alan_catalog.test.person;
select * from test.person;
select * from person;
-- 扫描 'cdhhive' 数据库中的 'version' 表,
select * from alan_catalog.cdhhive.version;
select * from cdhhive.version;
select * from version;
---------------具体操作详见下文------------------
Flink SQL> SET sql-client.execution.result-mode = tableau;
[INFO] Execute statement succeed.
Flink SQL> CREATE CATALOG alan_catalog WITH(
> 'type' = 'jdbc',
> 'default-database' = 'test?useSSL=false',
> 'username' = 'root',
> 'password' = '123456',
> 'base-url' = 'jdbc:mysql://192.168.10.44:3306'
> );
[INFO] Execute statement succeed.
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| alan_catalog |
| default_catalog |
+-----------------+
2 rows in set
Flink SQL> select * from alan_catalog.test.person;
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 11 | 测试修改go语言 | 30 |
| +I | 13 | NameUpdate | 22 |
| +I | 14 | updatejson | 23 |
| +I | 189 | 再试一试 | 12 |
| +I | 191 | test-full-update | 3333 |
| +I | 889 | zhangsanswagger2 | 88 |
| +I | 892 | update | 189 |
| +I | 1001 | testupdate | 19 |
| +I | 1002 | 测试go语言 | 23 |
| +I | 1013 | slene | 0 |
| +I | 1014 | testing | 0 |
| +I | 1015 | testing | 18 |
| +I | 1016 | astaxie | 19 |
| +I | 1017 | alan | 18 |
| +I | 1018 | chan | 19 |
+----+-------------+--------------------------------+-------------+
Received a total of 15 rows
Flink SQL> use catalog alan_catalog;
[INFO] Execute statement succeed.
Flink SQL> select * from test.person;
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 11 | 测试修改go语言 | 30 |
| +I | 13 | NameUpdate | 22 |
| +I | 14 | updatejson | 23 |
| +I | 189 | 再试一试 | 12 |
| +I | 191 | test-full-update | 3333 |
| +I | 889 | zhangsanswagger2 | 88 |
| +I | 892 | update | 189 |
| +I | 1001 | testupdate | 19 |
| +I | 1002 | 测试go语言 | 23 |
| +I | 1013 | slene | 0 |
| +I | 1014 | testing | 0 |
| +I | 1015 | testing | 18 |
| +I | 1016 | astaxie | 19 |
| +I | 1017 | alan | 18 |
| +I | 1018 | chan | 19 |
+----+-------------+--------------------------------+-------------+
Received a total of 15 rows
Flink SQL> use alan_catalog.test;
[INFO] Execute statement succeed.
Flink SQL> select * from person;
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 11 | 测试修改go语言 | 30 |
| +I | 13 | NameUpdate | 22 |
| +I | 14 | updatejson | 23 |
| +I | 189 | 再试一试 | 12 |
| +I | 191 | test-full-update | 3333 |
| +I | 889 | zhangsanswagger2 | 88 |
| +I | 892 | update | 189 |
| +I | 1001 | testupdate | 19 |
| +I | 1002 | 测试go语言 | 23 |
| +I | 1013 | slene | 0 |
| +I | 1014 | testing | 0 |
| +I | 1015 | testing | 18 |
| +I | 1016 | astaxie | 19 |
| +I | 1017 | alan | 18 |
| +I | 1018 | chan | 19 |
+----+-------------+--------------------------------+-------------+
Received a total of 15 rows
Flink SQL> select * from alan_catalog.cdhhive.version;
+----+----------------------+--------------------------------+--------------------------------+
| op | VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+----+----------------------+--------------------------------+--------------------------------+
| +I | 1 | 2.1.1 | Hive release version 2.1.1 |
+----+----------------------+--------------------------------+--------------------------------+
Received a total of 1 row
Flink SQL> use catalog alan_catalog;
[INFO] Execute statement succeed.
Flink SQL> select * from cdhhive.version;
+----+----------------------+--------------------------------+--------------------------------+
| op | VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+----+----------------------+--------------------------------+--------------------------------+
| +I | 1 | 2.1.1 | Hive release version 2.1.1 |
+----+----------------------+--------------------------------+--------------------------------+
Received a total of 1 row
Flink SQL> use alan_catalog.cdhhive;
[INFO] Execute statement succeed.
Flink SQL> select * from version;
+----+----------------------+--------------------------------+--------------------------------+
| op | VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+----+----------------------+--------------------------------+--------------------------------+
| +I | 1 | 2.1.1 | Hive release version 2.1.1 |
+----+----------------------+--------------------------------+--------------------------------+
Received a total of 1 row
6、数据类型映射


以上,简单的介绍了flink sql读取外部系统的jdbc示例。你可能感兴趣的:(#,Flink专栏,flink,sql,大数据,flink,sql,flink,jdbc,flink,流批一体化,flink,connector)