今天继续与大家分享系列文章《50 years in filesystems》,由 KRISTIAN KÖHNTOPP 撰写。
我们将进入文件系统的第二个十年,即1984年,计算机由微型计算机发展到了桌面和机柜工作站, BSD Fast Filing System 登场。
回看第一篇: 1974-Unix V7 File System
早期的 Unix 文件系统已经表现得很好,但也存在一些明显的问题。这些问题在操作系统 BSD(Berkeley Software Distribution)中进行了许多修复。 BSD 起源于 20 世纪 70 年代末和 80 年代初,由加州大学伯克利分校的计算机科学系开发和推广。在 Leffler、McKusick 等人撰写的的书中《The Design and Implementation of the 4.3BSD UNIX Operating System》有所记录。
1984 年发表的一篇经典论文《A Fast File System for UNIX》中,可以找到更简明、也更学术的讨论。该论文的作者包括 Marshall McKusick、Bill Joy(当时在Sun公司)、Samuel Leffler(当时在LucasFilm 公司)和 Robert Fabry。该论文提出了一个对 Unix 文件系统的重新实现方案,旨在提升文件系统的吞吐能力、优化存储空间的分配和增强数据访问的局部性。
The hardware
在1984 年,4.3BSD 所针对的计算机是桌面和机柜工作站。这些机器具有 32 位数据寄存器和 32 位地址寄存器。
外部数据和地址总线的大小各不相同:早期的 68k 系列 CPU 总线尺寸较小。 但在 1984 年,Motorola 68020 诞生了。它是首款提供完整 32 位宽度总线的 68k 系列,集成了大约 200,000 个晶体管在芯片上。后来,68030 将原本独立的 MMU(内存管理单元)集成到了芯片上,而 68040 则将原本独立的 FPU(浮点运算单元)也集成到了芯片上。

早期的 Sun 工作站,如 Sun-3系列,采用了这些 CPU。但 Sun 公司从伯克利实验性的 RISC 系统中借鉴了设计思路,并于1986年发布了基于 SPARC 架构的 Sun-4 系列工作站。SPARC 架构采取了一些妥协的策略,但运行地很好,在 Sun 公司被 Oracle 收购之前持续得到改进与发展。然而,在之后的发展中 Oracle 先后终止了 SPARC和 Itanium CPU 架构的发展。
Curt Schimmel 在《UNIX Systems for Modern Architectures》一书中讨论了 SPARC 在 MMU、寄存器和内存访问设计上所做的权衡,以及为什么这样做是合理的。与此同时,在1985年,MIPS 架构首次亮相,这是另一系列的 RISC CPU 架构。它也是一个完全的 32位系统,被用于 SGI 工作站。
惠普公司也有另一种 RISC 类型的 CPU,即 PA-RISC,它是“Spectrum”研究计划的产物,在1986 年上市(后来被 Intel 的一款失败产品 Itanium 取代)。
计算机系统领域的先锋公司 DEC自己有 VAX,这是一种具有 CISC CPU 的 32 位机柜式计算机,从 1977 年开始就已经存在。直到 1992 年,他们才转向 RISC 架构,而后采用 Alpha AXP(“DEC Alpha”)架构,完全实现了 64 位。尽管这个架构很有趣,但它的存在时间不长:1998年被康柏公司收购后,该 CPU 停产,其知识产权于 2001 年出售给了英特尔。
总的来说,1984 年的工作站类型系统的主内存容量在几十 MB 左右,运行时的系统时钟频率在几十 MHz 左右。

传统文件系统的短板
在 20 世纪 80 年代,32 位 VAX 系统被用于典型的工作站任务,包括图像处理和 VLSI 芯片设计等工作。当时使用的 Unix 文件系统在处理文件大小、 I/O 速度和文件数量方面出现了结构性问题。此外,只有 512 字节的 I/O 大小大大降低了磁盘子系统的性能。
论文中提到,文件系统的元数据和数据严格分离,即元数据位于文件系统的前部,而实际数据则位于文件系统的后部。这种分离设计有助于提高文件系统的性能和扩展性。
一个150MB 的传统 Unix 文件系统由4MB 的inode(索引节点)和146MB 的数据组成。这种组织方式将 inode 信息与数据分隔开来,因此访问文件通常需要从文件的 inode 到其数据之间进行一次长距离寻道。在一个目录中,文件通常不会被分配到 4MB 的 inode 连续槽位中,这就导致在对目录中多个文件的 inode 执行操作时,需要访问许多非连续的 inode 块。
正是因为这个元数据和数据分离的设计带来的问题,BSD FFS (BSD Fast Filing System) 的一个主要目标是改善文件系统的布局,将元数据和数据更加靠近,将单个目录中的文件存储得更加紧凑,避免文件被分散成小碎片,从而提高加载效率。
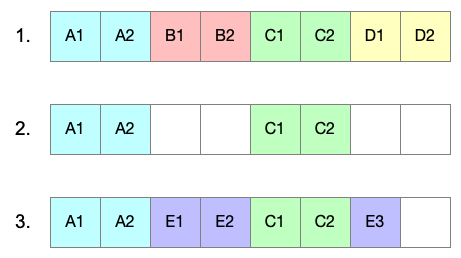
碎片化:首先,创建四个文件,每个文件使用两个块。然后删除了文件 B 和 D。接着,空闲的空间被一个占用三个块大小的文件E回收,但是文件 E 被存储在不连续的块中。这导致了小的磁盘寻道和较慢的 I/O 操作。
另一个明确的目标是增加磁盘块的大小。较大的磁盘块在两个方面有助于提高吞吐量:
- 较大的磁盘块提供了更大的 I/O 单元,因此可以在单个 I/O 操作中传输更多的数据;
- 较大的磁盘块还允许文件系统在一个间接块中存储更多的文件指针,大大减少了对间接块的访问次数。
该论文引用了一个 Unix 文件系统经过优化后的吞吐量,大约是理论最大值的4%,这是非常低效的。这主要归因于文件的碎片化,即文件中相邻块的非连续存储。对于碎片整理,虽然在 1976 年已经提出,但被认为不可行而被放弃。作者们希望通过在文件的初始存储位置上合理地放置文件来解决这个问题。
BSD FFS 的创新之处
理解柱面组和扇区
BSD FFS 的设计基于对硬盘的物理布局的理解,包括柱面、磁头和扇区(CHS)。它将硬盘分成柱面组,相邻的磁道属于同一个柱面组。
tu
当硬盘旋转时,不同的磁头进入盘片堆中,就像一个梳子。每个磁头在磁盘上标记一个磁道,控制器硬件将该磁道细分为物理磁盘块。所有磁头标记的磁道组成一个柱面。柱面组是一组连续的柱面。(图像来源:OSTEP,第3页)
每个柱面组都是一个传统 Unix 文件系统的迷你版本,包括超级块的副本、自己的本地索引节点区域以及本地索引节点和块使用位图。位图的使用也是新颖的,它们取代了传统文件系统中使用的空闲列表。由于文件系统知道 CHS 布局的信息,它能够确保每个副本的超级块不总是放置在同一盘片上,以提高文件系统对硬盘故障的容错性。
在 RAID(冗余磁盘阵列)论文发表之前几年,根据 Katz 的说法,RAID也是在伯克利开发的,时间为1983/1984年。
Katz 还提到,在那个时候,Stonebraker 一直在开发 Ingres(Postgres的前身),并提到他对低提交延迟的要求推动了改善 FFS 和后来 RAID 磁盘带宽的尝试。然而,对于RAID 分类的正统的研究直到1987年才开始。
许多初创公司和存储公司都将 RAID 论文作为他们开发的基础,其中包括 NetApp 和 EMC(通过Data General的Clariion 磁盘阵列)。
BSD FFS 不仅了解磁盘的 CHS 几何结构,还了解处理器速度和磁盘的旋转速度。这使得它能够配置并在超级块中记录交错因子,以优化磁盘 I/O 吞吐量。
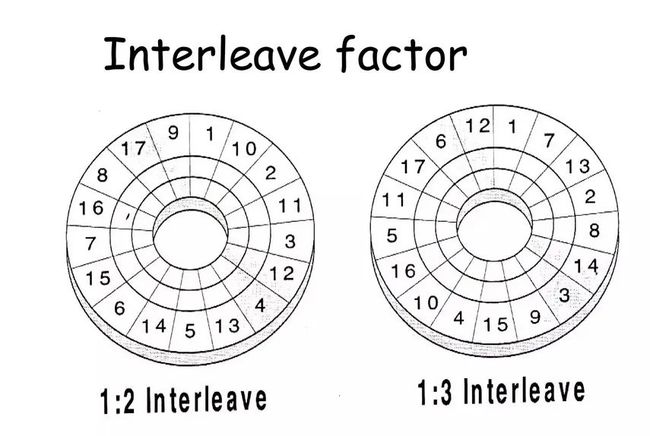
硬盘持续不断地旋转,但是 CPU 需要时间来设置下一次传输。在此期间,磁头可能已经超过了下一个块的起始边界,现在系统需要等待一次完整的旋转才能进行写入。使用适当的交错因子,相邻的块号不会被连续地存储在磁盘上,而是在它们之间交错插入其他块。这给了 CPU 足够的时间来思考和设置下一个块的传输。
CPU速度越快,所需的交错因子就越低。
随着硬盘开始配备集成控制器,并开始隐藏 CHS几何结构,并最终被线性块地址(LBA)取代,所有这些优化相对变得无关紧要。然而,在过去的十到十五年间,这些优化为系统提供了显著的性能优势。
大分块、小片段和尾部合并
在内部,FFS 使用至少4 KB大小的逻辑块。这些逻辑块,通过最多不超过两级间接块可以创建出最大 4GB 的文件。
较大的块可以提高 I/O 速度,但它们也会带来存储开销,因为文件的大小会按块递增。由于 FFS中的逻辑块由多个物理块组成,因此 FFS引入了片段(fragment)的概念,以公开较小的内部物理块。片段表示逻辑块内部的更小存储单位。通过引入片段的概念,FFS 可以更细粒度地管理和利用存储空间。尾部打包(tail packing)是一种技术,可以将多个文件的末尾存储在同一个逻辑块中。在传统的文件系统中,当文件的末尾部分不足以填满一个完整的物理块时,会导致空间浪费。因此,尾部打包的方法可以减少空间浪费。同时,通过利用片段的概念,尾部打包可以尽可能提升存储空间利用率。
为了防止进入片段逐渐增长和不断需要重新布局的阶段,此处系统采用的设计是:系统预先分配空间以填满逻辑块,并且尾部打包仅在文件关闭(即取消预分配)时才会发生。
长距离寻址分配策略
BSD FFS 引入了一系列布局策略,用于控制新目录、新文件的放置以及大文件的处理。全局策略主要关注选择适合的柱面组来存放数据,而本地策略则负责柱面组内的具体放置。
新的文件系统布局采用柱面组。每个柱面组都有自己的 inode 表,以及用于 inode 和块的空闲空间位图。文件系统旨在防止碎片化。
在某些情况下,是无法实现的:例如,如果一个柱面组的大小为 512 MB,并且要写入一个大于512 MB的文件,它将使用该柱面组中的一个 inode,但所有可用的空闲块已经用完。如果要将第二个文件放置到该柱面组中,inode可以被使用,但是该文件的数据块需要放置在其他地方,这是不理想的。
对于大文件,最好强制进行长距离寻道,从一个柱面组切换到下一个柱面组。文件系统可以从每一兆字节文件大小开始强制执行这样的长距离寻道。这将均匀地使用相邻柱面组之间的空闲块,同时在每个柱面组中保留一定数量的空闲块供其他文件使用。
这会有意地使文件产生碎片,但同时也确保碎片足够大以支持大文件的 I/O。碎片化(文件中块的非相邻放置)只有在碎片太小以至于无法高效读取时才会真正成为性能问题。
目录分配策略
相同目录中的文件通常会一起使用。将同一目录中的所有文件放置在同一个柱面组中是很有效的做法。
当然,这样做时还需要将不同的目录放置在不同的柱面组中,以确保文件系统空间的均匀使用。这意味着一个像这样的 Shell 脚本:

这个脚本将创建名为 fileXX 的十个文件,并将它们全部放置在与当前目录相同的柱面组中。
它还会在当前目录下创建十个名为 dirXX 的子目录。条件允许的话,每个子目录都会被放置在不同的柱面组中。FFS 会选择那些空闲 inode 数量高于平均水平且已有目录数量最少的柱面组。在柱面组中选择 inode 的方式是“下一个可用的”,因为整个柱面组的 inode 表只占用 8-16 个块。
为了放置数据块,考虑到这台机器所需的交错因子,FFS 投入了很多精力来寻找旋转最优的块。
BSD FFS 要求文件系统始终保持一定的可用空间。如果文件系统填满超过90%,许多算法将退化为传统文件系统的性能水平。
BSD FFS 其他改进
更大 Inode 和分块地址
例如,inode 号现在是 32 位数字。这个改变使得文件系统中可能的文件数量从 64K 增加到 42亿。
Inode 的大小已经翻倍:它现在被强制为 128 字节的大小(其中有 20 个未使用的字节)。此外,磁盘块地址现在是 4 个字节。在 4KB 块大小的情况下,这足以支持 42 亿个块,或者最大 16TB 的文件系统大小。
文件长度被记录在一个 quad 中,这样可以支持超过 4GB 的单个文件大小。
Inode 现在包含 12 个直接块和三种类型的间接块。在 4KB 块大小的情况下,每个间接块可以容纳 1024 个块地址,因此每个文件可以容纳 12 + 1024 + 1024^2 + 1024^3 = 1074791436 个块,或者最大文件大小略大于 4TB。
Unix 用户 ID 和组 ID 长度仍然限制为一个 short 类型,每个系统的用户和组数量限制为 64 K。
即使 inode 中的时间类型仍然限制为 4 字节,但已经为 8 字节的时间戳预先分配了空间。
长文件名
传统文件系统中,目录项具有固定的 16 字节长度,其中 2 字节用于存储 inode 号,14字节用于存储文件名。
BSD FFS 定义了更复杂的目录项结构。一个目录项包含一个 4 字节的 inode 号,一个 2 字节的记录长度和一个 2 字节的名称长度,然后是实际的文件名。路径中的每个文件或者目录名限制为 255 字节,目录项的长度向上取整到下一个 4 字节边界。
目录仍然基本上是一个链表,因此在大型目录中搜索名称是很慢的。而在目录中搜索可用空间则更加复杂:为了创建一个新的目录条目,我们需要从开头开始遍历目录,试图找到当前结构中足够大以容纳待创建名称的空隙。如果找不到空隙,则将新名称追加到末尾,从而增加目录的大小。
目录中的空闲空间不会通过压缩来回收,只有在新的文件名称恰好适合时才会最终重新使用,也就是说当系统需要在目录中创建新的目录项或文件时,它会首先尝试找到一个已有的空间,其大小足够容纳待创建的名称。如果找到这样的空间,系统将把新的名称插入到该空间中,利用已有的空闲空间,而无需增加目录的大小。然而,如果没有足够大的空间可用,系统将追加新的名称到目录的末尾,从而增加目录的大小。
符号链接
传统的文件系统允许一个文件拥有多个名称,使用link()系统调用和硬链接机制。硬链接有数量限制(一个 short 类型,最多 64K 个名称)。
硬链接(hardlink)可能会意外丢失,例如,通过使用某些编辑器保存一个有硬链接的文件时。如果编辑器将文件保存为 filename.new,然后取消链接旧的 filename 并将新文件移动到相应位置,那么文件的硬链接属性将会被修改。
硬链接(hardlink)是指在文件系统中创建的指向同一文件或目录的多个文件名。它们与原始文件(或目录)共享相同的 inode(索引节点),因此它们实际上是相同的文件,只是具有不同的文件名。硬链接允许多个文件名引用同一份数据,节省存储空间,并且对文件的更改会在所有硬链接之间保持同步。
硬链接还会多次引用原始文件的 inode,而 inode 是特定于文件系统的, 因此它们不能跨越文件系统。
BSD 引入了一种新的文件类型(l,符号链接),并在链接文件中放置一个“替换文件名”,用于确定链接目标位置。它可以是绝对路径或相对路径(相对于符号链接文件的位置)。
当尝试访问符号链接时,系统将在 namei() 函数中重新解析文件名,使用链接中的文件名,从而将 open() 系统调用重定向到链接指向的位置。简单来说,符号链接提供了一个文件名的替代方式,当访问符号链接时,实际上是在访问链接的目标文件。
由于重定向发生在 namei() 中,它可以跨文件系统,因此新的链接类型不受单个文件系统的限制。它也不计入任何链接计数限制。
重命名系统调用
BSD 引入了 rename() 系统调用。过去,则需要通过调用 unlink() 和 link() 实现。由于这涉及多个系统调用,该操作不是原子操作:它可能会部分执行,并且容易受到恶意干扰。
配额
BSD 引入了文件系统使用配额的概念:这是对用户或组可以使用的文件数量和磁盘空间量设置的软限制 (soft limit)和硬限制(hard limit)。
为了有效地实现它们,需要做如下修改:
- 现在,如果一个用户想要把自己文件的所有者改为其他用户,那么他必须拥有特权操作的权限。否则,他就只能创建一个只有自己能访问的目录,然后把目录里的所有文件都发送给目标用户。这样一来,这些文件就会占用另一个用户的配额,而不是自己的配额。
- 类似地,不再允许将文件的组员身份更改为任意组。只允许设置为该用户所属的某个组。
- 最后,新创建的目录和文件继承自它们的父目录,而不是用户的主要组。这样,项目目录中的文件将计入项目的配额,而不是用户主要组配额。
咨询式文件锁
4.2BSD 中已经引入了咨询式文件锁。为了实现这种机制,它引入了新的 flock() 系统调用。
- 文件锁可以是共享的(读锁)或独占的(写锁);
- 它们总是作用于整个文件,而不是字节范围;
- 不尝试检测死锁;
- 它们与文件描述符绑定。因此,当进程死亡时,其文件句柄会自动关闭,从而自动释放所有持有的锁。这非常健壮,直到 dup() 和 fork() 开始发挥作用。
后来,POSIX 试图改进这一点,引入了第二种完全不同的锁系统 fcntl()。它存在一些缺陷,但可以对字节范围进行操作,并实现了一些基本的死锁检测。
在这类实现了这两种文件锁机制的内核中如Linux系统,这两种锁机制互不兼容,也不知道对方的存在。
在 《Advisory File Locking – My take on POSIX and BSD locks》这篇文章中进一步讨论了所有这些内容,并提供了示例程序。
总体表现
在论文中,作者指出了以下优点:
- Ls 和ls -l 命令的速度很快,因为单个目录中文件的 inode 位于同一个柱面组内。因此,读取和列出目录时,寻道次数非常少,寻道距离也很短(除了子目录,它们通常要保证彼此的距离很远)。测试发现,当检索一个没有包含子目录的目录时,速度提高了8倍;
- 在传统文件系统中,理论最大带宽的利用率仅为3%,而在使用不同的控制器硬件的情况下,这一利用率增加到了22%甚至47%。作者对这些结果感到非常自豪,因为这些结果是在实际的生产系统上产生的。尽管文件的数量和规模可能会改变,但文件系统在其生命周期内能够持续相对稳定的吞吐量。
这些改进解决了主要的需求,即提高吞吐量和稳定的布局,使性能不会随时间降低。
此外,还进行了许多提升用户体验的改进,使得 BSD 在团队使用的过程中表现地更好;以及开启了一些新功能。
虽然 Linux 中并没有 BSD 代码,但 Ext2 文件系统基本上是对 BSD FFS 的重新实现。
无论是 BSD FFS 还是 Linux ext2,它们仍然是非日志文件系统,在发生崩溃后需要进行文件系统检查。它们在处理具有许多条目的目录方面也表现不佳,在处理深层次目录结构时稍好一些。为了跟上不断增长的存储容量,BSD FFS 和 Linux ext2 这两个文件系统需要进行额外的改进和优化,以便能够更好地支持处理大容量存储介质和大型文件系统。
此外,仍然存在其他一些不太明显的限制:文件系统代码中的几个位置受到锁的保护,使得在具有高并发性的系统上扩展某些操作变得困难。
直到1994年,SGI 的 XFS 才开始解决这些问题,经过了另外十年的时间。
未完待续。
如有帮助的话欢迎关注我们项目 Juicedata/JuiceFS 哟! (0ᴗ0✿)