JAVA核心技术36讲笔记
快速访问地址 https://github.com/a870439570/interview-docs
文章目录
-
-
-
- 谈谈你对Java平台的理解?“Java是解释执行”,这句话正确吗?
- Exception和Error有什么区别?
- 谈fnal、fnally、 fnalize有什么不同?
- 强引用、软引用、弱引用、幻象引用有什么区别?
- String、StringBufer、StringBuilder有什么区别?
- 谈谈Java反射机制,动态代理是基于什么原理
- int和Integer有什么区别?谈谈Integer的值缓存范围。
- 对比Vector、ArrayList、LinkedList有何区别?
- 对比Hashtable、HashMap、TreeMap 有什么不同?
- Java提供了哪些IO方式? NIO如何实现多路复用?
- 谈谈接口和抽象类有什么区别?
- 谈谈你知道的设计模式?请手动实现单例模式, Spring等框架中使用了哪些模式?
- synchronized和ReentrantLock有什么区别?
- synchronized底层如何实现?什么是锁的升级、降级?
- 一个线程两次调用start()方法会出现什么情况?谈谈线程的生命周期和状态转移。
- 什么情况下Java程序会产生死锁?如何定位、修复?
- Java并发包提供了哪些并发工具类?
- 并发包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么区别?
- Java并发类库提供的线程池有哪几种? 分别有什么特点?
- AtomicInteger底层实现原理是什么?如何在自己的产品代码中应用CAS操作?
- 请介绍类加载过程,什么是双亲委派模型?
- 有哪些方法可以在运行时动态生成一个Java类?
- 谈谈JVM内存区域的划分,哪些区域可能发生OutOfMemoryError?
- Java对象是不是都创建在堆上的呢?
- 什么是OOM问题,它可能在哪些内存区域发生?
- 如何监控和诊断JVM堆内和堆外内存使用?
- Java常见的垃圾收集器有哪些?
- 如何判断一个对象是否可以回收
- 常见的垃圾收集算法
- 在垃圾收集的过程,对应到Eden、 Survivor、 Tenured等区域会发生什么变化呢?
- java内存模型中的happen-before是什么?
- JVM优化Java代码时都做了什么?
- 谈谈常用的分布式ID的设计方案?Snowflake是否受冬令时切换影响?
-
-
谈谈你对Java平台的理解?“Java是解释执行”,这句话正确吗?
- 一次编译、到处运行”说的是Java语言跨平台的特性,Java的跨平台特性与Java虚拟机的存在密不可分,可在不同的环境中运行。比如说Windows平台和Linux平台都有相应的JDK,安装 好JDK后也就有了Java语言的运行环境。其实Java语言本身与其他的编程语言没有特别大的差异,并不是说Java语言可以跨平台,而是在不同的平台都有可以让Java语言运行的环境而已,所以 才有了Java一次编译,到处运行这样的效果。
- 程序从源代码到运行的三个阶段:编码——编译——运行——调试。Java在编译阶段则体现了跨平台的特点。编译过程大概是这样的:首先是将Java源代码转化成.CLASS文件字节码,这是第 一次编译。.class文件就是可以到处运行的文件。然后Java字节码会被转化为目标机器代码,这是是由JVM来执行的,即Java的第二次编译。
- Java是解析运行吗? 不正确! Java源代码经过Javac编译成.class文件 .class文件经JVM解析或编译运行。
Exception和Error有什么区别?
Exception和Error都是继承了Throwable类,在Java中只有Throwable类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。Exception是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。Error是指在正常情况下,不大可能出现的情况,绝大部分的Error都会导致程序(比如JVM自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常 见的比如OutOfMemoryError之类,都是Error的子类。Exception又分为可检查(checked)异常和不检查(unchecked)异常,可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分- 不检查异常就是所谓的运行时异常,类似
NullPointerException、ArrayIndexOutOfBoundsException之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕 获,并不会在编译期强制要求。

异常处理的基本原则:
尽量不要捕获类似Exception这样的通用异常,而是应该捕获特定异常
不要生吞(swallow)异常。这是异常处理中要特别注意的事情,因为很可能会导致非常难以诊断的诡异情况。
谈fnal、fnally、 fnalize有什么不同?
fnal可以用来修饰类、方法、变量,分别有不同的意义,fnal修饰的class代表不可以继承扩展,fnal的变量是不可以修改的,而fnal的方法也是不可以重写的(override)。fnally则是Java保证重点代码一定要被执行的一种机制。我们可以使用try-fnally或者try-catch-fnally来进行类似关闭JDBC连接、保证unlock锁等动作。fnalize是基础类java.lang.Object的一个方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收。fnalize机制现在已经不推荐使用,并且在JDK 9开始被标记 为deprecated。
强引用、软引用、弱引用、幻象引用有什么区别?
强引用:我们平常典型编码Object obj = new Object()中的obj就是强引用。通过关键字new创建的对象所关联的引用就是强引用。 当JVM内存空间不足,JVM宁愿抛出OutOfMemoryError运 行时错误(OOM),使程序异常终止,也不会靠随意回收具有强引用的“存活”对象来解决内存不足的问题。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式 地将相应(强)引用赋值为 null,就是可以被垃圾收集的了,具体回收时机还是要看垃圾收集策略。软引用:软引用通过SoftReference类实现。 软引用的生命周期比强引用短一些。只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象:即JVM 会确保在抛出 OutOfMemoryError 之前,清理软引用指向的对象。软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用 队列中。后续,我们可以调用ReferenceQueue的poll()方法来检查是否有它所关心的对象被回收。如果队列为空,将返回一个null,否则该方法返回队列中前面的一个Reference对象弱引用弱引用通过WeakReference类实现。 弱引用的生命周期比软引用短。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了具有弱引用的对象,不管当前内存空间足够与否,都会 回收它的内存。由于垃圾回收器是一个优先级很低的线程,因此不一定会很快回收弱引用的对象。弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾 回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。弱应用同样可用于内存敏感的缓存。幻象引用,有时候也翻译成虚引用,你不能通过它访问对象。幻象引用仅仅是提供了一种确保对象被fnalize以后,做某些事情的机制。如果 一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如 果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
String、StringBufer、StringBuilder有什么区别?
String被声明成为fnal class,所有属性也都是fnal的。也由于它的不可 变性,类似拼接、裁剪字符串等动作,都会产生新的String对象。Java为了避免在一个系统中产生大量的String对象,引入了字符串常量池,创建一个字符串时,首先检查池中是否有值相同的字符串对 象,如果有则不需要创建直接从池中刚查找到的对象引用;如果没有则新建字符串对象,返回对象引用,并且将新创建的对象放入池中。但是,通过new方法创建的String对象是不检查字符串 池的,而是直接在堆区或栈区创建一个新的对象,也不会把对象放入池中。上述原则只适用于通过直接量给String对象引用赋值的情况。String提供了inter()方法。调用该方法时,如果常量池中包括了一个等于此String对象的字符串(由equals方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并且 返回此池中对象的引用StringBufer和StringBuilder都实现了AbstractStringBuilder抽象类,拥有几乎一致对外提供的调用接口;其底层在内存中的存储方式与String相同,都是以一个有序的字符序列(char类型 的数组)进行存储,不同点是StringBufer/StringBuilder对象的值是可以改变的,并且值改变以后,对象引用不会发生改变;两者对象在构造过程中,首先按照默认大小申请一个字符数组,由 于会不断加入新数据,当超过默认大小后,会创建一个更大的数组,并将原先的数组内容复制过来,再丢弃旧的数组。因此,对于较大对象的扩容会涉及大量的内存复制操作,如果能够预先评 估大小,可提升性能。- 唯一需要注意的是:
StringBufer是线程安全的,但是StringBuilder是线程不安全的。可参看Java标准类库的源代码,StringBufer类中方法定义前面都会有synchronize关键字。为 此,StringBufer的性能要远低于StringBuilder。
谈谈Java反射机制,动态代理是基于什么原理
反射机制是Java语言提供的一种基础功能,赋予程序在运行时自省(introspect,官方用语)的能力。通过反射我们可以直接操作类或者对象,比如获取某个对象的类定义,获取类 声明的属性和方法,调用方法或者构造对象,甚至可以运行时修改类定义。动态代理是一种方便运行时动态构建代理、动态处理代理方法调用的机制,很多场景都是利用类似机制做到的,比如用来包装RPC调用、面向切面的编程(AOP)。JDK动态代理:基于Java反射机制实现,必须要实现了接口的业务类才能用这种办法生成代理对象。新版本也开始结合ASM机制。cglib动态代理:基于ASM机制实现,通过生成业务类的子类作为代理类。
int和Integer有什么区别?谈谈Integer的值缓存范围。
int是我们常说的整形数字,是Java的8个原始数据类型(Primitive Types,boolean、byte 、short、char、int、foat、double、long)之一。Java语言虽然号称一切都是对象, 但原始数据类型是例外。Integer是int对应的包装类,它有一个int类型的字段存储数据,并且提供了基本操作,比如数学运算、int和字符串之间转换等。在Java 5中,引入了自动装箱和自动拆箱功能 (boxing/unboxing),Java可以根据上下文,自动进行转换,极大地简化了相关编程。- Integer的值默认缓存 是-128到127之间。缓存上限值实际是可以根据需要调整的,JVM提供了参数设置:
-XX:AutoBoxCacheMax=N。 - 不管是Integer还Boolean等,都被声明为“private fnal”,所以,它们同样是不可变类型!
对比Vector、ArrayList、LinkedList有何区别?
Vector是线程安全的动态数组,。Vector内部是使用对象数组来保存数据,可以根据需要自动增加 容量,当数组已满时,会创建新的数组,并拷贝原有数组数据。Vector在扩容时会提高1倍ArrayList是动态数组实现,不是线程安全的,性能要好很多。与Vector近似,ArrayList也是可以根据需要调整容量,不过两者的调整逻辑有所区 别。ArrayList扩容时是增加50%。Vector和ArrayList作为动态数组,其内部元素以数组形式顺序存储的,所以非常适合随机访问的场合。除了尾部插入和删除元素,往往性能会相对较差,比如我们在中间位置插 入一个元素,需要移动后续所有元素。LinkedList是Java提供的双向链表,它不需要像上面两种那样调整容量,也不是线程安全的。LinkedList进行节点插入、删除却要高效得多,但是随机访问性能则要比动态数组慢。
TreeSet支持自然顺序访问,但是添加、删除、包含等操作要相对低效(log(n)时间)。
HashSet则是利用哈希算法,理想情况下,如果哈希散列正常,可以提供常数时间的添加、删除、包含等操作,但是它不保证有序。
LinkedHashSet,内部构建了一个记录插入顺序的双向链表,因此提供了按照插入顺序遍历的能力,与此同时,也保证了常数时间的添加、删除、包含等操作,这些操作性能略 低于HashSet,因为需要维护链表的开销。
在遍历元素时,HashSet性能受自身容量影响,所以初始化时,除非有必要,不然不要将其背后的HashMap容量设置过大。而对于LinkedHashSet,由于其内部链表提供的方便,遍历性能只和元素多少有关系。
Java提供的默认排序算法:
对于原始数据类型,目前使用的是所谓双轴快速排序,是一种改进的快速排序算法,早期版本是相对传统的快速排序
对于对象数据类型,目前则是使用TimSort,思想上也是一种归并和二分插入排序结合的优化排序算法
对比Hashtable、HashMap、TreeMap 有什么不同?
元素特性:HashTable 中的key、value都不能为null;HashMap中的key、value可以为null,很显然只能有一个key为null的键值对,但是允许有多个值为null的键值对;TreeMap 中当未实现 Comparator 接口时,key 不可以为null;当实现 Comparator 接口时,若未对null情况进行判断,则key不可以为null,反之亦然。顺序特性:HashTable 、HashMap具有无序特性。TreeMap 是利用红黑树来实现的(树中的每个节点的值,都会大于或等于它的左子树种的所有节点的值,并且小于或等于它的右子树中的所有节点的 值),实现了SortMap接口,能够对保存的记录根据键进行排序。所以一般需要排序的情况下是选择TreeMap 来进行,默认为升序排序方式(深度优先搜索),可自定义实现Comparator接口 实现排序方式。初始化与增长方式:初始化时:HashTable 在不指定容量的情况下的默认容量为11,且不要求底层数组的容量一定要为2的整数次幂;HashMap默认容量为16,且要求容量一定为2的整数次幂。 扩容时:Hashtable将容量变为原来的2倍加1;HashMap扩容将容量变为原来的2倍。HashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象。当获取对象时, 通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存 键值对对象。当两个不同的键对象的hashcode相同时,它们会储存在同一个bucket位置的链表中,可通过键对象的equals()方法用来找到键值对。如果链表大小超过阈值 ( 8),链表就会被改造为树形结构(红黑树)。
解决哈希冲突有哪些典型方法呢?
开放定址法:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈 希地址pi ,将相应元素存入其中。
再哈希法:当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)…,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
链地址法:这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用 于经常进行插入和删除的情况。
Java提供了哪些IO方式? NIO如何实现多路复用?
传统的java.io包,它基于流模型实现,提供了我们最熟知的一些IO功能,比如File抽象、输入输出流等。交互方式是同步、阻塞的方式。- 很多时候,人们也把java.net下面提供的部分网络API,比如Socket、ServerSocket、HttpURLConnection也归类到同步阻塞IO类库,因为网络通信同样是IO行为。
在Java 1.4中引入了NIO框架(java.nio包),提供了Channel、Selector、Bufer等新的抽象,可以构建多路复用的、同步非阻塞IO程序,同时提供了更接近操作系统底层 的高性能数据操作方式。在Java 7中,NIO有了进一步的改进,也就是NIO 2,引入了异步非阻塞IO方式,也有很多人叫它AIO(Asynchronous IO)。异步IO操作基于事件和回调机制,可以简单 理解为,应用操作直接返回,而不会阻塞在那里,当后台处理完成,操作系统会通知相应线程进行后续工作。
NIO多路复用的局限性是什么呢?
由于nio实际上是同步非阻塞io,是一个线程在同步的进行事件处理,当一组事channel处理完毕以后,去检查有没有又可以处理的channel。这也就是同步+非阻塞。同步,指每个准备好 的channel处理是依次进行的,非阻塞,是指线程不会傻傻的等待读。只有当channel准备好后,才会进行。那么就会有这样一个问题,当每个channel所进行的都是耗时操作时,由于是同步操 作,就会积压很多channel任务,从而完成影响。那么就需要对nio进行类似负载均衡的操作,如用线程池去进行管理读写,将channel分给其他的线程去执行,这样既充分利用了每一个线程,又不至于都堆积在一个线程中,等待执行
谈谈接口和抽象类有什么区别?
接口是对行为的抽象,它是抽象方法的集合,利用接口可以达到API定义和实现分离的目的。接口,不能实例化;不能包含任何非常量成员,同时,没有非静态方法实现,也就是说要么是抽象方法,要么是静态方法。 Java标准类库中,定义了非常多的接口,比如java.util.List。抽象类是不能实例化的类,用abstract关键字修饰class,其目的主要是代码重用。除了不能实例化,形式上和一般的Java类并没有太大区别,可以有一个或者多个抽象方法,也可
以没有抽象方法。抽象类大多用于抽取相关Java类的共用方法实现或者是共同成员变量,然后通过继承的方式达到代码复用的目的。 Java标准库中,比如collection框架,很多通用
部分就被抽取成为抽象类,例如java.util.AbstractList。
进行面向对象编程,掌握基本的设计原则是必须的,我今天介绍最通用的部分,也就是所谓的
S.O.L.I.D原则。
单一职责类或者对象最好是只有单一职责,在程序设计中如果发现某个类承担着多种义务,可以考虑进行拆分。
开关原则设计要对扩展开放,对修改关闭。换句话说,程序设计应保证平滑的扩展性,尽量避免因为新增同类功能而修改已有实现,这样可以少产出些回归(regression)问题。
里氏替换这是面向对象的基本要素之一,进行继承关系抽象时,凡是可以用父类或者基类的地方,都可以用子类替换。
接口分离我们在进行类和接口设计时,如果在一个接口里定义了太多方法,其子类很可能面临两难,就是只有部分方法对它是有意义的,这就破坏了程序的内聚性。对于这种情况,可以通过拆分成功能单一的多个接口,将行为进行解耦。在未来维护中,如果某个接口设计有变,不会对使用其他接口的子类构成影响
依赖反转实体应该依赖于抽象而不是实现。也就是说高层次模块,不应该依赖于低层次模块,而是应该基于抽象。实践这一原则是保证产品代码之间适当耦合度的法宝
谈谈你知道的设计模式?请手动实现单例模式, Spring等框架中使用了哪些模式?
- 设计模式可以分为创建型模式、结构型模式和行为型模式。
创建型模式,是对对象创建过程的各种问题和解决方案的总结,包括各种工厂模式(Factory、 Abstract Factory)、单例模式(Singleton)、构建器模式(Builder)、原型模式(ProtoType)。结构型模式,是针对软件设计结构的总结,关注于类、对象继承、组合方式的实践经验。常见的结构型模式,包括桥接模式(Bridge)、适配器模式(Adapter)、装饰者模式(Decorator)、代理模式(Proxy)、组合模式(Composite)、外观模式(Facade)、享元模式(Flyweight)等。行为型模式,是从类或对象之间交互、职责划分等角度总结的模式。比较常见的行为型模式有策略模式(Strategy)、解释器模式(Interpreter)、命令模式(Command)、观察者模式(Observer)、迭代器模式(Iterator)、模板方法模式(Template Method)、访问者模式(Visitor)。更多相关内容你可以参考:https://en.wikipedia.org/wiki/Design_Patterns
InputStream是一个抽象类,标准类库中提供了FileInputStream、 ByteArrayInputStream等各种不同的子类,分别从不同角度对InputStream进行了功能扩展,这是典型的装饰器模式应用案例。识别装饰器模式,可以通过识别类设计特征来进行判断,也就是其类构造函数以相同的抽象类或者接口为输入参数
创建型模式尤其是工厂模式,在我们的代码中随处可见,我举个相对不同的API设计实践。比如, JDK最新版本中 HTTP/2 Client API,下面这个创建HttpRequest的过程,就是典型的构建器模式(Builder),通常会被实现成fuent风格的API,也有人叫它方法链。使用构建器模式,可以比较优雅地解决构建复杂对象的麻烦,这里的“复杂”是指类似需要输入的参数组合较多,如果用构造函数,我们往往需要为每一种可能的输入参数组合实现相应的构造函数,一系列复杂的构造函数会让代码阅读性和可维护性变得很差。
Spring等如何在API设计中使用设计模式
BeanFactory和ApplicationContext应用了工厂模式
在Bean的创建中, Spring也为不同scope定义的对象,提供了单例和原型等模式实现。
AOP领域则是使用了代理模式、装饰器模式、适配器模式等。
各种事件监听器,是观察者模式的典型应用。
类似JdbcTemplate等则是应用了模板模式。
synchronized和ReentrantLock有什么区别?
synchronized是Java内建的同步机制,它提供了互斥的语义和可见性,当一个线程已经获取当前锁时,其他试图获取的线程只能等待或者阻塞在那里。ReentrantLock,通常翻译为再入锁,是Java 5提供的锁实现,它的语义和synchronized基本相同。再入锁通过代码直接调用lock()方法获取,代码书写也更加灵活。与此同时, ReentrantLock提供了很多实用的方法,能够实现很多synchronized无法做到的细节控制,比如可以控制fairness,也就是公平性,或者利用定义条件等。但是,编码中也需要注意,必须要明确调用unlock()方法释放,不然就会一直持有该锁。
synchronized底层如何实现?什么是锁的升级、降级?
synchronized代码块是由一对儿monitorenter/monitorexit指令实现的, Monitor对象是同步的基本实现单元。在Java 6之前, Monitor的实现完全是依靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作。现代的(Oracle) JDK中, JVM对此进行了大刀阔斧地改进,提供了三种不同的Monitor实现,也就是常说的三种不同的锁:偏向锁(Biased Locking)、轻量级锁和重量级锁,大大改进了其性能。- 所谓锁的升级、降级,就是JVM优化synchronized运行的机制,当JVM检测到不同的竞争状况时,会自动切换到适合的锁实现,这种切换就是锁的升级、降级。
- 当没有竞争出现时,
默认会使用偏斜锁。JVM会利用CAS操作,在对象头上的Mark Word部分设置线程ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。这样做的假设是基于在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定,使用偏斜锁可以降低无竞争开销。 - 如果有另外的线程试图锁定某个已经被偏斜过的对象, JVM就需要撤销(revoke)偏斜锁,并切换到轻量级锁实现。轻量级锁依赖CAS操作Mark Word来试图获取锁,如果重试成功,就使用普通的轻量级锁;否则,进一步升级为重量级锁。
你知道“自旋锁”是做什么的吗?它的使用场景是什么?
自旋锁:竞争锁的失败的线程,并不会真实的在操作系统层面挂起等待,而是JVM会让线程做几个空循环(基于预测在不久的将来就能获得),在经过若干次循环后,如果可以获得锁,那么进入临界区,如果还不能获得锁,才会真实的将线程在操作系统层面进行挂起。
适用场景:自旋锁可以减少线程的阻塞,这对于锁竞争不激烈,且占用锁时间非常短的代码块来说,有较大的性能提升,因为自旋的消耗会小于线程阻塞挂起操作的消耗。如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用cpu做无用功,线程自旋的消耗大于线程阻塞挂起操作的消耗,造成cpu的浪费
在单核CPU上,自旋锁是无用,因为当自旋锁尝试获取锁不成功会一直尝试,这会一直占用CPU,其他线程不可能运行,
同时由于其他线程无法运行,所以当前线程无法释放锁。
一个线程两次调用start()方法会出现什么情况?谈谈线程的生命周期和状态转移。
- Java的线程是不允许启动两次的,第二次调用必然会抛出IllegalThreadStateException,这是一种运行时异常,多次调用start被认为是编程错误。
- 新建(NEW),表示线程被创建出来还没真正启动的状态,可以认为它是个Java内部状态。
- 就绪(RUNNABLE),表示该线程已经在JVM中执行,当然由于执行需要计算资源,它可能是正在运行,也可能还在等待系统分配给它CPU片段,在就绪队列里面排队。
- 阻塞(BLOCKED),这个状态和我们前面两讲介绍的同步非常相关,阻塞表示线程在等待Monitor lock。比如,线程试图通过synchronized去获取某个锁,但是其他线程已经独占了,那么当前线程就会处于阻塞状态。
- 等待(WAITING),表示正在等待其他线程采取某些操作。一个常见的场景是类似生产者消费者模式,发现任务条件尚未满足,就让当前消费者线程等待(wait),另外的生产者线程去准备任务数据,然后通过类似notify等动作,通知消费线程可以继续工作了。 Thread.join()也会令线程进入等待状态。
- 计时等待(TIMED_WAIT),其进入条件和等待状态类似,但是调用的是存在超时条件的方法,比如wait或join等方法的指定超时版本
什么情况下Java程序会产生死锁?如何定位、修复?
死锁是一种特定的程序状态,在实体之间,由于循环依赖导致彼此一直处于等待之中,没有任何个体可以继续前进。死锁不仅仅是在线程之间会发生,存在资源独占的进程之间同样也可能出现死锁。通常来说,我们大多是聚焦在多线程场景中的死锁,指两个或多个线程之间,由于互相持有对方需要的锁,而永久处于阻塞的状态。

定位死锁最常见的方式就是利用jstack等工具获取线程栈,然后定位互相之间的依赖关系,进而找到死锁。如果是比较明显的死锁,往往jstack等就能直接定位,类似JConsole甚至 可以在图形界面进行有限的死锁检测。- 使用Java提供的标准管理API,ThreadMXBean,其直接就提供 fndDeadlockedThreads()方法用于定位死锁。但是要注意的是,对线程进行快照本身是一个相对重量级的操作,还是要慎重选择频度和时机。
public class ThreadMXBeanTest {
public static void main(String[] args) {
ThreadMXBean mbean = ManagementFactory.getThreadMXBean();
Runnable dlCheck = new Runnable() {
@Override
public void run() {
long[] threadIds = mbean.findDeadlockedThreads();
if (threadIds != null) {
ThreadInfo[] threadInfos = mbean.getThreadInfo(threadIds);
System.out.println("Detected deadlock threads:");
for (ThreadInfo threadInfo : threadInfos) {
System.out.println(threadInfo.getThreadName());
}
}
}
};
ScheduledExecutorService scheduler =Executors.newScheduledThreadPool(1);
// 稍等5秒,然后每10秒进行一次死锁扫描
scheduler.scheduleAtFixedRate(dlCheck, 5L, 10L, TimeUnit.SECONDS);
Test1 t=new Test1();
new Thread(new Runnable() {
@Override
public void run() {
t.t1();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
t.t2();
}
}).start();
}
public static class Test1{
Object obj1=new Object();
Object obj2=new Object();
public void t1(){
synchronized (obj1){
System.out.println(Thread.currentThread().getName()+": obj1--------");
try {
Thread.sleep(1000);
synchronized (obj2){
System.out.println(Thread.currentThread().getName()+" obj2--------");
}
}catch (InterruptedException e){
}
}
}
public void t2(){
synchronized (obj2){
System.out.println(Thread.currentThread().getName()+" t2 obj2--------");
try {
Thread.sleep(1000);
synchronized (obj1){
System.out.println(Thread.currentThread().getName()+" t2 obj1--------");
}
}catch (InterruptedException e){
}
}
}
}
}
如
何在编程中尽量预防死锁呢?
尽量避免使用多个锁,并且只有需要时才持有锁
如果必须使用多个锁,尽量设计好锁的获取顺序
使用带超时的方法,为程序带来更多可控性。
有时候并不是阻塞导致的死锁,只是某个线程进入了死循环,导致其他线程一直等待,这种问题如何诊断呢?
可以通过linux下top命令查看cpu使用率较高的java进程,进而用top -Hp pid查看该java进程下cpu使用率较高的线程。再用jstack命令查看线程具体调用情况,排查问题
Java并发包提供了哪些并发工具类?
- 提供了比synchronized更加高级的各种同步结构,包括
CountDownLatch、CyclicBarrier、Semaphore等。CountDownLatch,允许一个或多个线程等待某些操作完成。CyclicBarrier,一种辅助性的同步结构,允许多个线程等待到达某个屏障。Semaphore, Java版本的信号量实现,它通过控制一定数量的允许(permit)的方式,来达到限制通用资源访问的目的。 - 各种
线程安全的容器,比如最常见的ConcurrentHashMap、有序的ConcunrrentSkipListMap,或者通过类似快照机制,实现线程安全的动态数组CopyOnWriteArrayList等。 - 各种
并发队列实现,如各种BlockedQueue实现,比较典型的ArrayBlockingQueue、SynchorousQueue或针对特定场景的PriorityBlockingQueue等。 - 强大的
Executor框架,可以创建各种不同类型的线程池,调度任务运行等,绝大部分情况下,不再需要自己从头实现线程池和任务调度器。
你使用过类似CountDownLatch的同步结构解决实际问题吗?
一个页面有A,B,C三个网络请求,其中请求C需要请求A和请求B的返回数据作为参数,用过CountdownLatch解决。
需求是每个对象一个线程,分别在每个线程里计算各自的数据,最终等到所有线程计算完毕,我还需要将每个有共通的对象进行合并,所以用它很合适。
并发包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么区别?
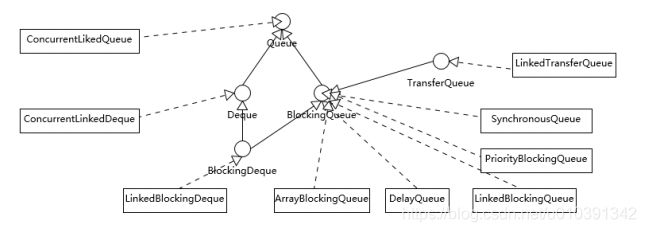
Concurrent类型基于lock-free,在常见的多线程访问场景,一般可以提供较高吞吐量。而LinkedBlockingQueue内部则是基于锁,并提供了BlockingQueue的等待性方法。ArrayBlockingQueue是最典型的的有界队列,其内部以fnal的数组保存数据,数组的大小就决定了队列的边界,所以我们在创建ArrayBlockingQueue时,都要指定容量LinkedBlockingQueue,容易被误解为无边界,但其实其行为和内部代码都是基于有界的逻辑实现的,只不过如果我们没有在创建队列时就指定容量,那么其容量限制就自动被设置为Integer.MAX_VALUE,成为了无界队列。SynchronousQueue,这是一个非常奇葩的队列实现,每个删除操作都要等待插入操作,反之每个插入操作也都要等待删除动作。其内部容量是0PriorityBlockingQueue是无边界的优先队列,虽然严格意义上来讲,其大小总归是要受系统资源影响DelayedQueue和LinkedTransferQueue同样是无边界的队列。对于无边界的队列,有一个自然的结果,就是put操作永远也不会发生其他BlockingQueue的那种等待情况。
在日常的应用开发中,如何进行选择呢?
考虑应用场景中对队列边界的要求。 ArrayBlockingQueue是有明确的容量限制的,而LinkedBlockingQueue则取决于我们是否在创建时指定, SynchronousQueue则干脆不能缓存任何元素。
从空间利用角度,数组结构的ArrayBlockingQueue要比LinkedBlockingQueue紧凑,因为其不需要创建所谓节点,但是其初始分配阶段就需要一段连续的空间,所以初始内存需求更大。
通用场景中, LinkedBlockingQueue的吞吐量一般优于ArrayBlockingQueue,因为它实现了更加细粒度的锁操作。
ArrayBlockingQueue实现比较简单,性能更好预测,属于表现稳定的“选手”。
如果我们需要实现的是两个线程之间接力性(handof)的场景,你可能会选择CountDownLatch,但是SynchronousQueue也是完美符合这种场景的,而且线程间协调和数据传输统一起来,代码更加规范。
Java并发类库提供的线程池有哪几种? 分别有什么特点?
Executors目前提供了5种不同的线程池创建配置:
newCachedThreadPool(),它是一种用来处理大量短时间工作任务的线程池,具有几个鲜明特点:它会试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程;如果线程闲置的时间超过60秒,则被终止并移出缓存;长时间闲置时,这种线程池,不会消耗什么资源。其内部使用SynchronousQueue作为工作队列。newFixedThreadPool(int nThreads),重用指定数目(nThreads)的线程,其背后使用的是无界的工作队列,任何时候最多有nThreads个工作线程是活动的。这意味着,如果任务数量超过了活动队列数目,将在工作队列中等待空闲线程出现;如果有工作线程退出,将会有新的工作线程被创建,以补足指定的数目nThreads。newSingleThreadExecutor(),它的特点在于工作线程数目被限制为1,操作一个无界的工作队列,所以它保证了所有任务的都是被顺序执行,最多会有一个任务处于活动状态,并且不允许使用者改动线程池实例,因此可以避免其改变线程数目。newSingleThreadScheduledExecutor()和newScheduledThreadPool(int corePoolSize),创建的是ScheduledExecutorService,可以进行定时或周期性的工作调度,区别在于单一工作线程还是多个工作线程newWorkStealingPool(int parallelism),这是一个经常被人忽略的线程池,Java 8才加入这个创建方法,其内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序。
ThreadPoolExecutor参数详解
corePoolSize,所谓的核心线程数,可以大致理解为长期驻留的线程数目。于不同的线程池,这个值可能会有很大区别,比如newFixedThreadPool会将其设置为nThreads,而对于newCachedThreadPool则是为0。
maximumPoolSize,顾名思义,就是线程不够时能够创建的最大线程数
keepAliveTime和TimeUnit,这两个参数指定了额外的线程能够闲置多久,显然有些线程池不需要它。
workQueue,工作队列,必须是BlockingQueue。
线程池大小的选择策略:
如果我们的任务主要是进行计算,那么就意味着CPU的处理能力是稀缺的资源。如果线程太多,反倒可能导致大量
的上下文切换开销。所以,这种情况下,通常建议按照CPU核的数目N或者N+1。
如果是需要较多等待的任务,例如I/O操作比较多,可以参考Brain Goetz推荐的计算方法:线程数 = CPU核数 × (1 + 平均等待时间/平均工作时间)
AtomicInteger底层实现原理是什么?如何在自己的产品代码中应用CAS操作?
AtomicIntger是对int类型的一个封装,提供原子性的访问和更新操作,其原子性操作的实现是基于CAS(compare-and-swap)技术。- 所谓CAS,表征的是一些列操作的集合,获取当前数值,进行一些运算,利用CAS指令试图进行更新。如果当前数值未变,代表没有其他线程进行并发修改,则成功更新。否则,可能出现不同的选择,要么进行重试,要么就返回一个成功或者失败的结果。
- 于CAS的使用,你可以设想这样一个场景:在数据库产品中,为保证索引的一致性,一个常见的选择是,保证只有一个线程能够排他性地修改一个索引分区,
请介绍类加载过程,什么是双亲委派模型?
- 一般来说,我们把Java的类加载过程分为三个主要步骤:加载、链接、初始化,具体行为在Java虚拟机规范里有非常详细的定义。
首先是加载阶段(Loading),它是Java将字节码数据从不同的数据源读取到JVM中,并映射为JVM认可的数据结构(Class对象),这里的数据源可能是各种各样的形态,如jar文件、 class文件,甚至是网络数据源等;如果输入数据不是ClassFile的结构,则会抛出ClassFormatError。加载阶段是用户参与的阶段,我们可以自定义类加载器,去实现自己的类加载过程。第二阶段是链接(Linking),这是核心的步骤,简单说是把原始的类定义信息平滑地转化入JVM运行的过程中。这里可进一步细分为三个步骤:
验证: 这是虚拟机安全的重要保障,JVM需要核验字节信息是符合Java虚拟机规范的,否则就被认为是VerifyError,这样就防止了恶意信息或者不合规的信息害JVM的运行,验证阶段有可能触发更多class的加载。
准备,创建类或接口中的静态变量,并初始化静态变量的初始值。但这里的“初始化”和下面的显式初始化阶段是有区别的,侧重点在于分配所需要的内存空间,不会去执行更进一步的JVM指令
解析,在这一步会将常量池中的符号引用替换为直接引用。在Java虚拟机规范中,详细介绍了类、接口、方法和字段等各个方面的解析。
最后是初始化阶段(initialization),这一步真正去执行类初始化的代码逻辑,包括静态字段赋值的动作,以及执行类定义中的静态初始化块内的逻辑,编译器在编译阶段就会把这部分逻辑整理好,父类型的初始化逻辑优先于当前类型的逻辑。- 再来谈谈
双亲委派模型,简单说就是当类加载器(Class-Loader)试图加载某个类型的时候,除非父加载器找不到相应类型,否则尽量将这个任务代理给当前加载器的父加载器去做。使用委派模型的目的是避免重复加载Java类型。

有哪些方法可以在运行时动态生成一个Java类?
- 我们可以从常见的Java类来源分析,通常的开发过程是,开发者编写Java代码,调用javac编译成class文件,然后通过类加载机制载入JVM,就成为应用运行时可以使用的Java类了。
- 有一种笨办法,直接用ProcessBuilder之类启动javac进程,并指定上面生成的文件作为输入,进行编译。最后,再利用类加载器,在运行时加载即可。
- 你可以考虑使用Java Compiler API,这是JDK提供的标准API,里面提供了与javac对等的编译器功能,具体请参考java.compiler相关文档。
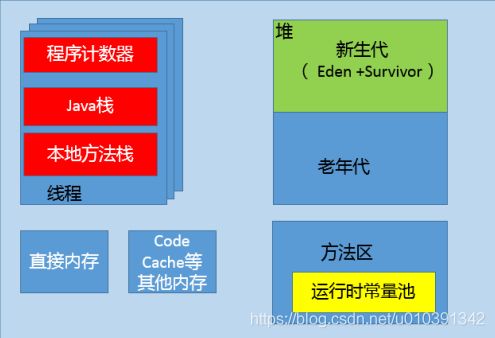
谈谈JVM内存区域的划分,哪些区域可能发生OutOfMemoryError?
- 通常可以把
JVM内存区域分为下面几个方面,其中,有的区域是以线程为单位,而有的区域则是整个JVM进程唯一的。 程序计数器:在JVM规范中,每个线程都有它自己的程序计数器,并且任何时间一个线程都只有一个方法在执行,也就是所谓的当前方法。程序计数器会存储当前线程正在执行的Java方法的JVM指令地址;或者,如果是在执行本地方法,则是未指定值(undefned)。Java虚拟机栈:早期也叫Java栈。每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个的栈帧(Stack Frame),对应着一次次的Java方法调用。前面谈程序计数器时,提到了当前方法;同理,在一个时间点,对应的只会有一个活动的栈帧,通常叫作当前帧,方法所在的类叫作当前类。如果在该方法中调用了其他方法,对应的新的栈帧会被创建出来,成为新的当前帧,一直到它返回结果或者执行结束。 JVM直接对Java栈的操作只有两个,就是对栈帧的压栈和出栈。栈帧中存储着局部变量表、操作数栈、动态链接、方法正常退出或者异常退出的定义等堆(Heap),它是Java内存管理的核心区域,用来放置Java对象实例,几乎所有创建的Java对象实例都是被直接分配在堆上。堆被所有的线程共享,在虚拟机启动时,我们指定的“Xmx”之类参数就是用来指定最大堆空间等指标。堆也是垃圾收集器重点照顾的区域,所以堆内空间还会被不同的垃圾收集器进行进一步的细分,最有名的就是新生代、老年代的划分。方法区(Method Area)。这也是所有线程共享的一块内存区域,用于存储所谓的元(Meta)数据,例如类结构信息,以及对应的运行时常量池、字段、方法代码等。由于早期的Hotspot JVM实现,很多人习惯于将方法区称为永久代, Oracle JDK 8中将永久代移除,同时增加了元数据区(Metaspace)运行时常量池,这是方法区的一部分。如果仔细分析过反编译的类文件结构,你能看到版本号、字段、方法、超类、接口等各种信息,还有一项信息就是常量池。 Java的常量池可以存放各种常量信息,不管是编译期生成的各种字面量,还是需要在运行时决定的符号引用,所以它比一般语言的符号表存储的信息更加宽泛。本地方法栈(Native Method Stack)。它和Java虚拟机栈是非常相似的,支持对本地方法的调用,也是每个线程都会创建一个
Java对象是不是都创建在堆上的呢?
- 有一些观点,认为通过逃逸分析, JVM会在栈上分配那些不会逃逸的对象,这在理论上是可行的,但是取决于JVM设计者的选择
- 目前很多书籍还是基于JDK 7以前的版本, JDK已经发生了很大变化, Intern字符串的缓存和静态变量曾经都被分配在永久代上,而永久代已经被元数据区取代。但是, Intern字符串缓存和静态变量并不是被转移到元数据区,而是直接在堆上分配,所以这一点同样符合对象实例都是分配在堆上。
什么是OOM问题,它可能在哪些内存区域发生?
- OOM如果通俗点儿说,就是JVM内存不够用了, javadoc中对
OutOfMemoryError的解释是,没有空闲内存,并且垃圾收集器也无法提供更多内存。在抛出OutOfMemoryError之前,通常垃圾收集器会被触发,尽其所能去清理出空间。当然,也不是在任何情况下垃圾收集器都会被触发的,比如,我们去分配一个超大对象,类似一个超大数组超过堆的最大值, JVM可以判断出垃圾收集并不能解决这个问题,所以直接抛出OutOfMemoryError。
从我前面分析的数据区的角度,除
了程序计数器,其他区域都有可能会因为可能的空间不足发OutOfMemoryError,简单总结如下:
堆内存不足是最常见的OOM原因之一,抛出的错误信息是“java.lang.OutOfMemoryError:Java heap space”,原因可能千奇百怪,例如,可能存在内存泄漏问题;也很有可能就是堆的大小不合理,比如我们要处理比较可观的数据量,但是没有显式指定JVM堆大小或者指定数值偏小;或者出现JVM处理引用不及时,导致堆积起来,内存无法释放等。- 而对于Java虚拟机栈和本地方法栈,这里要稍微复杂一点。如果我们写一段程序不断的进行递归调用,而且没有退出条件,就会导致不断地进行压栈。类似这种情况, JVM实际会抛出StackOverFlowError;当然,如果JVM试图去扩展栈空间的的时候失败,则会抛出OutOfMemoryError。
对于老版本的Oracle JDK,因为永久代的大小是有限的,并且JVM对永久代垃圾回收(如,常量池回收、卸载不再需要的类型)非常不积极,所以当我们不断添加新类型的时候,永久代出现OutOfMemoryError也非常多见,尤其是在运行时存在大量动态类型生成的场合;类似Intern字符串缓存占用太多空间,也会导致OOM问题。对应的异常信息,会标记出来和永久代相关: “java.lang.OutOfMemoryError: PermGen space”。随着元数据区的引入,方法区内存已经不再那么窘迫,所以相应的OOM有所改观,出现OOM,异常信息则变成了: “java.lang.OutOfMemoryError: Metaspace”。- 直接内存不足,也会导致OOM
我在试图分配一个100M bytes大数组的时候发生了OOME,但是GC日志显示,明明堆上还有远不止100M的空
间,你觉得可能问题的原因是什么?想要弄清楚这个问题,还需要什么信息呢?
- 从不同的垃圾收集器角度来看:首先,数组的分配是需要连续的内存空间的。所以对于使用年轻代和老年代来管理内存的垃圾收集器,堆大于 100M,表示的是新生代和老年代加起来总和大于100M,而新生代和老年代各自并没有大于 100M 的连续内存空间。进一步,又由于大数组一般直接进入老年代(会跳过对对象的年龄的判断),所以,是否可以认为老年代中没有连续大于 100M 的空间呢。
- 对于 G1 这种按 region 来管理内存的垃圾收集器,可能的情况是没有多个连续的 region,它们的内存总和大于 100M。当然,不管是哪种垃圾收集器以及收集算法,当内存空间不足时,都会触发 GC,只不过,可能 GC 之后,还是没有连续大于 100M 的内存空间,于是 OOM了。
如何监控和诊断JVM堆内和堆外内存使用?
- 可以使用综合性的图形化工具,如JConsole、 VisualVM(注意,从Oracle JDK 9开始, VisualVM已经不再包含在JDK安装包中)等。这些工具具体使用起来相对比较直观,直接连接到Java进程,然后就可以在图形化界面里掌握内存使用情况。
以JConsole为例,其内存页面可以显示常见的堆内存和各种堆外部分使用状态。
- 也可以使用命令行工具进行运行时查询,如jstat和jmap等工具都提供了一些选项,可以查看堆、方法区等使用数据。
- 或者,也可以使用jmap等提供的命令,生成堆转储(Heap Dump)文件,然后利用jhat或Eclipse MAT等堆转储分析工具进行详细分析。
- 如果你使用的是Tomcat、 Weblogic等Java EE服务器,这些服务器同样提供了内存管理相关的功能。
- 另外,从某种程度上来说, GC日志等输出,同样包含着丰富的信息。
- JConsole官方教程。我这里特别推荐Java Mission Control(JMC),这是一个非常强大的工具,不仅仅能够使用JMX进行普通的管理、监控任务,还可以配合Java Flight Recorder(JFR)技术,以非常低的开销,收集和分析JVM底层的Profling和事件等信息。
堆内部是什么结构?
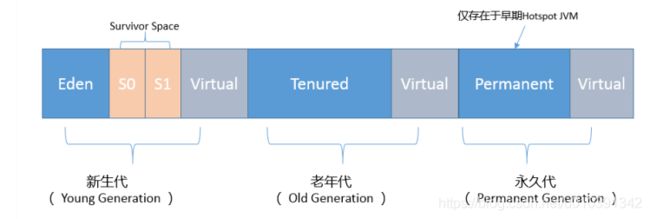
你可以看到,按照通常的GC年代方式划分, Java堆内分为:
新生代
- 新生代是大部分对象创建和销毁的区域,在通常的Java应用中,绝大部分对象生命周期都是很短暂的。其内部又分为Eden区域,作为对象初始分配的区域;两个Survivor,有时候也叫from、 to区域,被用来放置从Minor GC中保留下来的对象。
- JVM会随意选取一个Survivor区域作为“to”,然后会在GC过程中进行区域间拷贝,也就是将Eden中存活下来的对象和from区域的对象,拷贝到这个“to”区域。这种设计主要是为了防止内存的碎片化,并进一步清理无用对象。
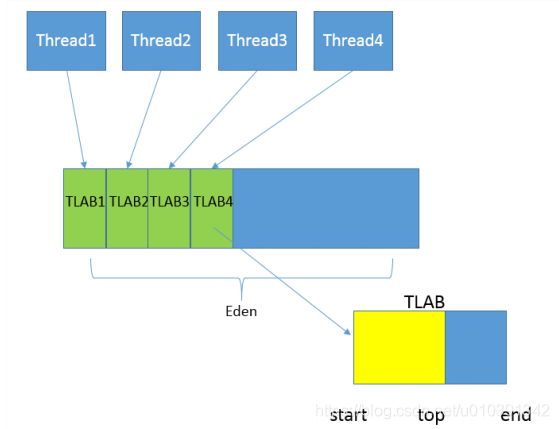
- 从内存模型而不是垃圾收集的角度,对Eden区域继续进行划分, Hotspot JVM还有一个概念叫做(TLAB)。这是JVM为每个线程分配的一个私有缓存区域,否则,多线程同时分配内存时,为避免操作同一地址,可能需要使用加锁等机制,进而影响分配速度,TLAB仍然在堆上,它是分配在Eden区域内的。其内部结构比较直观易懂, start、 end就是起始地址, top(指针)则表示已经分配到哪里了。所以我们分配新对象, JVM就会移动top,当top和end相遇时,即表示该缓存已满, JVM会试图再从Eden里分配一块儿。
老年代
- 放置长生命周期的对象,通常都是从Survivor区域拷贝过来的对象。当然,也有特殊情况,我们知道普通的对象会被分配在TLAB上;如果对象较大, JVM会试图直接分配在Eden其他位置上;如果对象太大,完全无法在新生代找到足够长的连续空闲空间, JVM就会直接分配到老年代。
永久代
- 这部分就是早期Hotspot JVM的方法区实现方式了,储存Java类元数据、常量池、 Intern字符串缓存,在JDK 8之后就不存在永久代这块儿了。
利用JVM参数,直接影响堆和内部区域的大小
- 最大堆体积:
-Xmx value - 初始的最小堆体积:
-Xms value - 老年代和新生代的比例:
-XX:NewRatio=value。默认情况下,这个数值是3,意味着老年代是新生代的3倍大;换句话说,新生代是堆大小的1/4。也可以不用比例的方式调整新生代的大小,直接-XX:NewSize=value参数,设定具体的内存大小数值。
Java常见的垃圾收集器有哪些?
Serial GC,它是最古老的垃圾收集器, “Serial”体现在其收集工作是单线程的,并且在进行垃圾收集过程中,会进入臭名昭著的“Stop-The-World”状态。当然,其单线程设计也意味着精简的GC实现,无需维护复杂的数据结构,初始化也简单,所以一直是Client模式下JVM的默认选项。- 从年代的角度,通常将其老年代实现单独称作
Serial Old,它采用了标记-整理(Mark-Compact)算法,区别于新生代的复制算法。Serial GC的对应JVM参数是:-XX:+UseSerialGC ParNew GC,很明显是个新生代GC实现,它实际是Serial GC的多线程版本,最常见的应用场景是配合老年代的CMS GC工作,下面是对应参数-XX:+UseConcMarkSweepGC -XX:+UseParNewGCCMS GC,基于标记-清除(Mark-Sweep)算法 设计目标是尽量减少停顿时间,这一点对于Web等反应时间敏感的应用非常重要,一直到今天,仍然有很多系统使用CMS GC。但是, CMS采用的标记-清除算法,存在着内存碎片化问题,所以难以避免在长时间运行等情况下发生full GC,导致恶劣的停顿。另外,既然强调了并发(Concurrent), CMS会占用更多CPU资源,并和用户线程争抢。Parrallel GC,在早期JDK 8等版本中,它是server模式JVM的默认GC选择,也被称作是吞吐量优先的GC。它的算法和Serial GC比较相似,尽管实现要复杂的多,其特点是新生代和老年代GC都是并行进行的,在常见的服务器环境中更加高效。开启选项是:-XX:+UseParallelGC另外, Parallel GC引入了开发者友好的配置项,我们可以直接设置暂停时间或吞吐量等目标, JVM会自动进行适应性调整,例如下面参数:
-XX:MaxGCPauseMillis=value,
-XX:GCTimeRatio=N //GC时间和用户时间比例 = 1 / (N+1)
查看jdk垃圾收集器:java -XX:+PrintCommandLineFlags -version
- G1 GC这是一种兼顾吞吐量和停顿时间的GC实现,是Oracle JDK 9以后的默认GC选项。 G1可以直观的设定停顿时间的目标,相比于CMS GC, G1未必能做到CMS在最好情况下的延时停顿,但是最差情况要好很多。
- G1 GC仍然存在着年代的概念,但是其内存结构并不是简单的条带式划分,而是类似棋盘的一个个region。 Region之间是复制算法,但整体上实际可看作是标记-整理(MarkCompact)算法,可以有效地避免内存碎片,尤其是当Java堆非常大的时候, G1的优势更加明显。
- G1吞吐量和停顿表现都非常不错,并且仍然在不断地完善,与此同时CMS已经在JDK 9中被标记为废弃(deprecated),所以G1 GC值得你深入掌握。
如何判断一个对象是否可以回收
主要是两种基本算法, 引用计数和可达性分析
引用计数算法,顾名思义,就是为对象添加一个引用计数,用于记录对象被引用的情况,如果计数为0,即表示对象可回收。Java并没有选择引用计数,是因为其存在一个基本的难题,也就是很难处理循环引用关系。Java选择的可达性分析, Java的各种引用关系,在某种程度上,将可达性问题还进一步复杂化,这种类型的垃圾收集通常叫作追踪性垃圾收集。其原理简单来说,就是将对象及其引用关系看作一个图,选定活动的对象作为GC Roots,然后跟踪引用链条,如果一个对象和GC Roots之间不可达,也就是不存在引用链条,那么即可认为是可回收对象。 JVM会把虚拟机栈和本地方法栈中正在引用的对象、静态属性引用的对象和常量,作为GC Roots。
常见的垃圾收集算法
复制(Copying)算法:将活着的对象复制到to区域,拷贝过程中将对象顺序放置,就可以避免内存碎片化。这么做的代价是,既然要进行复制,既要提前预留内存空间,有一定的浪费;另外,对于G1这种分拆成为大量regio GC,复制而不是移动,意味着GC需要维护region之间对象引用关系,这个开销也不小,不管是内存占用或者时间开销。标记-清除(Mark-Sweep)算法,首先进行标记工作,标识出所有要回收的对象,然后进行清除。这么做除了标记、清除过程效率有限,另外就是不可避免的出现碎片化问题,这就导致其不适合特别大的堆;否则,一旦出现Full GC,暂停时间可能根本无法接受。标记-整理(Mark-Compact),类似于标记-清除,但为避免内存碎片化,它会在清理过程中将对象移动,以确保移动后的对象占用连续的内存空间。
在垃圾收集的过程,对应到Eden、 Survivor、 Tenured等区域会发生什么变化呢?
- 这实际上取决于具体的GC方式,先来熟悉一下通常的垃圾收集流程,我画了一系列示意图,希望能有助于你理解清楚这个过程。
第一, Java应用不断创建对象,通常都是分配在Eden区域,当其空间占用达到一定阈值时,触发minor GC。仍然被引用的对象(绿色方块)存活下来,被复制到JVM选择的Survivor区域,而没有被引用的对象(黄色方块)则被回收。注意,我给存活对象标记了“数字1”,这是为了表明对象的存活时间。
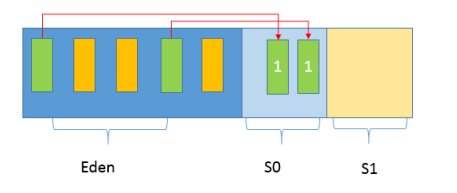
第二, 经过一次Minor GC, Eden就会空闲下来,直到再次达到Minor GC触发条件,这时候,另外一个Survivor区域则会成为to区域, Eden区域的存活对象和From区域对象,都会被复制到to区域,并且存活的年龄计数会被加1。
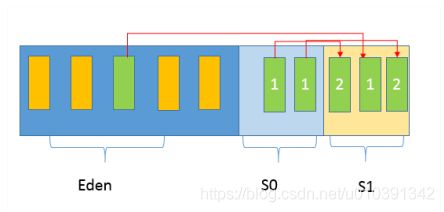
第三, 类似第二步的过程会发生很多次,直到有对象年龄计数达到阈值,这时候就会发生所谓的晋升(Promotion)过程,如下图所示,超过阈值的对象会被晋升到老年代。
这个阈值是可以通过参数指定:-XX:MaxTenuringThreshold=
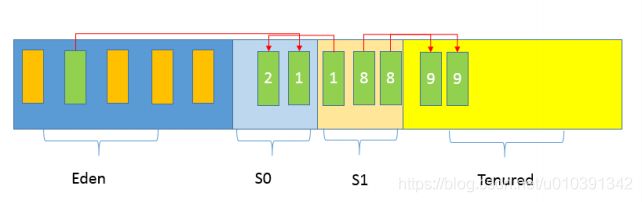
后面就是老年代GC,具体取决于选择的GC选项,对应不同的算法。通常我们把老年代GC叫作Major GC,将对整个堆进行的清理叫作Full GC,但是这个也没有那么绝对,因为不同的老年代GC算法其实表现差异很大,例如CMS, “concurrent”就体现在清理工作是与工作线程一起并发运行的。
JDK又增加了两种全新的GC方式,分别是:
Epsilon GC,简单说就是个不做垃圾收集的GC,似乎有点奇怪,有的情况下,例如在进行性能测试的时候,可能需要明确判断GC本身产生了多大的开销,这就是其典型应用场景。ZGC,这是Oracle开源出来的一个超级GC实现,具备令人惊讶的扩展能力,比如支持T bytes级别的堆大小,并且保证绝大部分情况下,延迟都不会超过10 ms。虽然目前还处于实验阶段,仅支持Linux 64位的平台,但其已经表现出的能力和潜力都非常令人期待。
java内存模型中的happen-before是什么?
- Happen-before关系,是Java内存模型中保证多线程操作可见性的机制,也是对早期语言规范中含糊的可见性概念的一个精确定义。
- 线程内执行的每个操作,都保证happen-before后面的操作,这就保证了基本的程序顺序规则,这是开发者在书写程序时的基本约定。
- 对于volatile变量,对它的写操作,保证happen-before在随后对该变量的读取操作。
- 对于一个锁的解锁操作,保证happen-before加锁操作。
- 对象构建完成,保证happen-before于fnalizer的开始动作。
- 甚至是类似线程内部操作的完成,保证happen-before其他Thread.join()的线程等。
- 这些happen-before关系是存在着传递性的,如果满足a happen-before b和b happen-before c,那么a happen-before c也成立。
- JMM内部的实现通常是依赖于所谓的内存屏障,通过禁止某些重排序的方式,提供内存可见性保证,也就是实现了各种happen-before规则。与此同时,更多复杂度在于,需要尽量确保各种编译器、各种体系结构的处理器,都能够提供一致的行为。
可从四个维度去理解JMM
- 从JVM运行时视角来看, JVM内存可分为JVM栈、本地方法栈、 PC计数器、方法区、堆;其中前三区是线程所私有的,后两者则是所有线程共有的
- 从JVM内存功能视角来看, JVM可分为堆内存、非堆内存与其他。其中堆内存对应于上述的堆区;非堆内存对应于上述的JVM栈、本地方法栈、 PC计数器、方法区;其他则对应于直接内存
- 从线程运行视角来看, JVM可分为主内存与线程工作内存。 Java内存模型规定了所有的变量都存储在主内存中;每个线程的工作内存保存了被该线程使用到的变量,这些变量是主内存的副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量
- 从垃圾回收视角来看, JVM中的堆区=新生代+老年代。新生代主要用于存放新创建的对象与存活时长小的对象,新生代=E+S1+S2;老年代则用于存放存活时间长的对象
JVM优化Java代码时都做了什么?
- JVM在对代码执行的优化可分为
运行时化和即时编译器优化。运行时优化主要是解析执行和动态编译通用的一些机制,比如说锁机制(如偏向锁)、内存分配机制(如TLAB)。除此之外,还有一些专门优化器执行效率的,比如说模板解析器,内联缓存。 - J
VM的即时编译器优化是指将热点代码以方法为单位转换成机器码,直接运行在底层硬件之上。它采用了多种优化方式,包括静态编译器可以使用的如方法内联、逃逸分析,也?包括基于程序运行profle的投机性优化,这个怎么理解了?比如我有一条instanceof指令,在编译之前的运行过程中,测试对像的类一直是同一个,那么即时编译器可以假设编译之后的执行过程中还会是这一个类,并且根据这个类直接返回instanceof的结果。如果出现了其他类,那么就抛弃这段编译后的机器码,并且切换回解析执行。
谈谈常用的分布式ID的设计方案?Snowflake是否受冬令时切换影响?
- 基于数据库自增序列的实现。这种方式优缺点都非常明显,好处是简单易用,但是在扩展性和可靠性等方面存在局限性。
- 基于Twitter 早期开源的Snowflake的实现,以及相关改动方案。

- 整体长度通常是64 (1 + 41 + 10+ 12 = 64)位,适合使用Java语言中的long类型来存储。
- 头部是1位的正负标识位。跟着的高位部分包含41位时间戳,通常使用
System.currentTimeMillis() - 后面是
10位的WorkerID,标准定义是5位数据中心 + 5位机器ID,组成了机器编号,以区分不同的集群节点。 - 最后的12位就是单位毫秒内可生成的序列号数目的理论极限。