InfluxDB-FLUX语法介绍以及查询InfluxDB
文章目录
-
- FLUX 语法
-
- 介绍
- 最简示例
- FLUX 的基本语法
-
- 注释
- 变量与复制
- 基本表达式
- 谓词表达式
- 控制语句
- FLUX 中的数据类型
-
- 十个基本数据类型
-
- Boolean (布尔型)
- bytes (字节)
- Duration 持续时间
- Regular expression 正则表达式
- String 字符串
- Time 时间点
- Float 浮点数
- Integer 整数
- UIntegers 无符号整数
- Null 空值
- FLUX 类型不代表 InfluxDB 类型
- 4 个复合类型
-
- Record(记录)
- Array(数组)
- Dictionary(字典)
- function(函数)
- 函数包
- FLUX 查询 InfluxDB
-
- FLUX 查询InfluxDB 的语法
- 表、表流以及序列
- filter 维度过滤
- 类型转换函数与下划线字段
- map 函数
- 自定义管道函数
- 在文档中区分管道函数和普通函数
- window 和 aggregateWindow 函数
- yield 和 join
FLUX 语法
介绍
Flux 是一种函数式的数据脚本语言,它旨在将查询、处理、分析和操作数据统一为一种语法。
想要从概念上理解 FLUX,你可以想想水处理的过程。我们从源头把水抽取出来,然后按照我们的用水需求,在管道上进行一系列的处理修改(去除沉积物,净化)等,最终以消耗品的方式输送到我们的目的地(饮水机、灌溉等)。
注意:InfluxData 公司对 FLUX 语言构想并不是仅仅让它作为 InfluxDB 的特定查询语言,而是希望它像 SQL 一样,成为一种标准。按照这个计划,FLUX 语言应该具备处理来自不同数据源的数据的能力。
注意InfluxDB 支持的 FLUX 语言版本:
需要注意,因为 InfluxDB 是一个用 Go 语言编写的数据库,它的整个项目成果就是一个单独的可执行二进制文件,所以 FLUX 语言其实也会被编译到同一个文件里。这意味着InfluxDB 和 FLUX 会有版本绑定的关系。
这里,我放了一个链接 https://docs.influxdata.com/flux/v0.x/influxdb-versions/ ,它是官方 FLUX 文档的一部分,这里明确记录了 InfluxDB 版本的 FLUX 语言版本的对应关系。

最简示例
与处理水一样,使用 FLUX 语言进行查询时会执行以下操作。
-
从数据源中查询指定数量的数据
-
根据时间或字段筛选数据
-
将数据进行处理或者聚合以得到预期结果
-
返回最终的结果
下面 3 个示例的处理逻辑都是一样的,只不过数据源有所不同,
这 3 个示例只是让大家看一下语法,不需要运行。
-
示例 1:从 InfluxDB 查询数据并聚合
from(bucket: "example-bucket") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "example-measurement") |> mean() |> yield(name: "_results") -
示例 2:从CSV 文件查询数据并聚合
import "csv" csv.from(file: "path/to/example/data.csv") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "example-measurement") |> mean() |> yield(name: "_results") -
示例 3:从PostgreSQL 数据库查询数据并聚合
import "sql" sql.from( driverName: "postgres", dataSourceName: "postgresql://user:password@localhost", query: "SELECT * FROM TestTable", ) |> filter(fn: (r) => r.UserID == "123ABC456DEF") |> mean(column: "purchase_total") |> yield(name: "_results")
上面 3 个示例用的函数都是一模一样的,下面来讲解示例中出现的代码:
-
from( )函数可以指定数据源。
-
| >管道转发符,将一个函数的输出转发给下一个函数。
-
range( ),fliter( ) 两个函数在根据列的值对数据进行过滤
-
mean( )函数在计算所剩数据的平均值。
-
yield( ) 将最终的计算结果返回给用户。
虽然,FLUX 语言的自我定位一个脚本语言,但是我们必须注意它也是一个查询语言的事实。因此,一个 FLUX 脚本想要成功执行,它就必须返回一个表流。就像是 SQL 语言想要正确执行,它就必须返回一张表。
表流是 FLUX 里提出一种数据结构。另外需要注意,我们后面的代码,如果只返回一个单值,比如单个整数或者字符串这种,那就必须把这个值转换成表流才能运行。这个时候必须使用 array.from 函数。
示例如下:
from "array
x = 1
array.from(rows: [{"value":x}])
array.from 函数的作用就是把 x 这个单值,包装在了一个表流里面返回了。
FLUX 的基本语法
注释
在 FLUX 脚本中,没有多行注释一说,用户只能写单行注释。如果一行以两个斜杠开头,那么这一行中的所有内容会被视为注释。
示例:
// 这是一行注释。
变量与复制
使用赋值运算符(=)将表达式的结果赋值变量,最终你可以使用变量名来返回变量的值。
示例:
s = "foo" // string
i = 1 // integer
f = 2.0 // float (floating point number)
s // Returns foo
i // Returns 1
f // Returns 2.0
基本表达式
FLUX 支持基本的表达式,比如:
- +数字相加或字符串拼接
- - 数字减法
- * 数字相乘
- / 数字除法
- % 取模
示例:
1 + 1
// Returns 2
10 * 3
// Returns 30
(12.0 + 18.0) / (2.0 ^ 2.0) + (240.0 % 55.0)
// Returns 27.5
"John " + "Doe " + "is here!"
// Returns John Doe is here!
谓词表达式
(1)比较运算符
谓词表达式使用比较运算符和逻辑运算符来实现,谓词表达式的最后的返回结果只能为 true 或 false
示例:
"John" == "John"
// Returns true
41 < 30
// Returns false
"John" == "John" and 41 < 30
// Returns false
"John" == "John" or 41 < 30
// Returns true
另外
-
=~可以判断一个字符串时候能被正则表达式匹配上。
-
!~是=~的反操作,判断一个字符串是不是不能被某个正则表达式匹配。
例如:
"abcdefg" =~ "abc|bcd"
// Returns true
"abcdefg" !~ "abc|bcd"
// Returns false
(2)逻辑运算符
在 FLUX 语言中,表示与逻辑需要使用关键字 and,表示或逻辑需要使用关键字 or。示例:
a = true
b = false
x = a and b
// Returns false
y = a or b
// Returns true
最后,not 可以用来进行逻辑取反。示例:
a = true
b = not a
// Returns false
控制语句
所谓控制语句是指一个编程语言中用来空值代码执行顺序的语法。比如:
-
if else
-
for while 循环
-
try catch 异常捕获
不过,在 InfluxDB 中,这些语法统统没有。唯一一个和 if else 比较像的是 FLUX 语言中的条件子句,它和 python 中的条件子句功能一样且语法相似,和 java 语言相比的话它有些像三元表达式。
示例如下:
x = 0
y = if x == 0 then "hello" else "world"
此处,if then else 被我们成为条件子句,你需要先指定一个条件,然后当条件为 true 的时候,条件子句会返回 then 后面的内容,也就是"hello"。如果是 flase,那么就会返回else 后面的内容,也就是"world"。
FLUX 中的数据类型
十个基本数据类型
Boolean (布尔型)
使用 bool( )函数可以将下述的 4 个基本数据类型转换为 boolean:
- string(字符串):字符串必须是 “true” 或 “false”
- float(浮点数):值必须是 0.0(false)或 1.0(true)
- int(整数):值必须是 0(false)或 1(true)
- uint(无符号整数):值必须是 0(false)或 1(true)
示例:
bool(v: "true")
// Returns true
bool(v: 0.0)
// Returns false
bool(v: 0)
// Returns false
bool(v: uint(v: 1))
// Returns true
bytes (字节)
注意是 bytes(复数)不是byte,bytes 类型表示一个由字节组成的序列。
(1)定义 bytes
FLUX 没有提供关于 bytes 的语法。可以使用bytes 函数将字符串转为bytes。
bytes(v:"hello")
// Returns [104 101 108 108 111]
注意:只有字符串类型可以转换为 bytes。
(2)将表示十六进制的字符串转为 bytes
引入"contrib/bonitoo-io/hex"包
使用 hex.bytes() 将表示十六进制的字符串转为 bytes
import "contrib/bonitoo-io/hex"
hex.bytes(v: "FF5733")
// Returns [255 87 51] (bytes)
(3)使用 **display( )**函数获取 bytes 的字符串形式
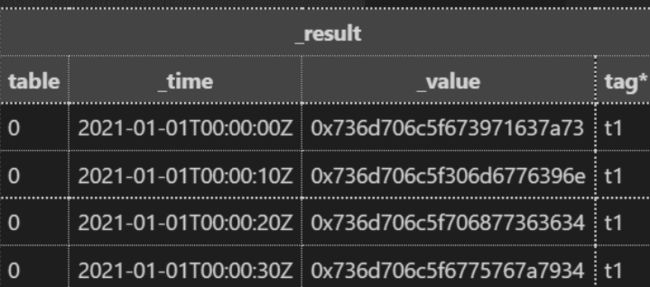
使用 display( )返回字节的字符串表示形式。bytes 的字符串表示是 0x 开头的十六进制表示。示例:
import "sampledata"
sampledata.string()
|> map(fn: (r) => ({r with _value: display(v: bytes(v: r._value))}))
Duration 持续时间
持续时间提供了纳秒级精度的时间长度。
持续时间的语法:
-
ns:纳秒
-
us:微秒
-
ms:毫秒
-
s :秒
-
m :分钟
-
h :小时
-
d :天
-
w :周
-
mo:日历月
-
y :日历年
示例:
1ns // 1 纳秒
1us // 1 微妙
1ms // 1 毫秒
1s // 1 秒
1m // 1 分钟
1h // 1 小时
1d // 1 天
1w // 1 星期
1mo // 1 日历月
1y // 1 日历年
3d12h4m25s // 3 天 12 小时 4 分钟又 25 秒
注意!持续时间的声明不要包含先导 0
比如:
01m // 解析为整数 0 和 1 分钟的持续时间
02h05m //解析为整数 0、2 小时的持续时间,整数 0 和 5 分钟的持续时间。而不是 2小时又 5 分钟
将其他数据类型解释为持续时间:
使用 duration( )函数可以将以下基本数据类型转换为持续时间:
- 字符串:将表示持续时间字符串的函数转换为持续时间。
- int:将整数先解释为纳秒再转换为持续时间
- unit:将整数先解释为纳秒再转换为持续时间。
duration(v: "1h30m")
// Returns 1h30m
duration(v: 1000000)
// Returns 1ms
duration(v: uint(v: 3000000000))
// Returns 3s
注意!你可以在 FLUX 语言中使用 duration 类型的变量与时间做运算,但是你不能在table 中创建 duration 类型的列。
duration 的算术运算:
要对 duration 进行加法、减法、乘法或除法操作,需要按下面的步骤来。
-
使用 int( )或 unit()将持续时间转换为int 数值
-
使用算术运算符进行运算
-
把运算的结果再转换回Duration 类型
示例:
duration(v: int(v: 6h4m) + int(v: 22h32s))
// 返回 1d4h4m32s
duration(v: int(v: 22h32s) - int(v: 6h4m))
// 返回 15h56m32s
duration(v: int(v: 32m10s) * 10)
// 返回 5h21m40s
duration(v: int(v: 24h) / 2)
// 返回 12h
注意!声明持续时间的时候不要包含前导 0,前面的零会被 FLUX 识别为整数
时间和持续时间相加运算:
- 导入 date 包
- 使用 date.add( )函数将持续时间和时间相加
示例:
import "date"
date.add(d: 1w, to: 2021-01-01T00:00:00Z)
// 2021-01-01 加上一周
// Returns 2021-01-08T00:00:00.000000000Z
时间和持续时间相减运算:
-
导入 date 包
-
使用 date.add( )函数从时间中减去持续时间
示例:
import "date"
date.sub(d: 1w, from: 2021-01-01T00:00:00Z)
// 2021-01-01 减去一周
// Returns 2020-12-25T00:00:00.000000000Z
Regular expression 正则表达式
(1)定义一个正则表达式
FLUX 语言是 GO 语言实现的,因此使用 GO 的正则表达式语法。正则表达式需要声明在正斜杠之间/ /
(2)使用正则表达式进行逻辑判断
使用正则表达式进行逻辑判断,需要使用 =~ 和 != 操作符。=~ 的意思是左值(字符串)能够被右值匹配,!~表示左值(字符串)不能被右值匹配。
"abc" =~ /\w/
// Returns true
"z09se89" =~ /^[a-z0-9]{7}$/
// Returns true
"foo" !~ /^f/
// Returns false
"FOO" =~ /(?i)foo/
// Returns true
(3)将字符串转为正则表达式
- 引入 regexp 包
- 使用 regexp.compile( ) 函数可以将字符串转为正则表达式
import "regexp"
regexp.compile(v: "^- [a-z0-9]{7}")
// Returns ^- [a-z0-9]{7} (regexp type)
(4)将匹配的子字符串全部替换
- 引入 regexp 包
- 使用 regexp.replaceAllString( )函数,并提供下列参数:
-
r:正则表达式
-
v:要搜索的字符串
-
t: 一旦匹配,就替换为该字符串
-
示例:
import "regexp"
regexp.replaceAllString(r: /a(x*)b/, v: "-ab-axxb-", t: "T")
// Returns "-T-T-"
(5)得到字符串中第一个匹配成功的结果
- 导入 regexp 包
- 使用 regexp.findString( )来返回正则表达式匹配中的第一个字符串,需要传递以下参数:
-
r:正则表达式
-
v:要进行匹配的字符串
-
示例:
import "regexp"
regexp.findString(r:"abc|bcd",v:"xxabcwwed")
// Returns "abc"
String 字符串
(1)定义一个字符串
字符串类型表示一个字符序列。字符串是不可改变的,一旦创建就无法修改。
字符串是一个由双引号括起来的字符序列,在 FLUX 中,还支持你用\x 作为前缀的十六进制编码来声明字符串。
示例:
"abc"
"string with double \" quote"
"string with backslash \\"
"日本語"
"\xe6\x97\xa5\xe6\x9c\xac\xe8\xaa\x9e"
(2)将其他基本数据类型转换为字符串
使用 srting( )函数可以将下述基本类型转换为字符串:
-
boolean 布尔值
-
bytes 字节序列
-
duration 持续时间
-
float 浮点数
-
uint 无符号整数
-
time 时间
string(v: 42)
// 返回 "42"
使用 display( )函数可以将任何类型的值输出为相应的字符串类型。示例:
x = bytes(v: "foo")
display(v: x)
// Returns "0x666f6f"
(3)将正则表达式转换为字符串
因为正则表达式也是一个基本数据类型,所以正则表达式也可以转换为字符串,但是需要借助额外的包。
-
引入 regexp 包
-
使用 regexp.compile( )
Time 时间点
(1)定义一个时间点
一个 time 类型的变量其实是一个纳秒精度的时间点。
示例:时间点必须使用RFC3339 的时间格式进行声明:
YYYY-MM-DD
YYYY-MM-DDT00:00:00Z
YYYY-MM-DDT00:00:00.000Z
(2)date 包
date 包里的函数主要是用来从Time 类型的值里提取年月日秒等信息的。比如 date.hour:
import "date"
x = 2020-01-01T19:22:31Z
date.hour(t:x)
//Returns 19
Float 浮点数
(1)定义一个浮点数
FLUX 中的浮点数是 64 位的浮点数。
一个浮点数包含整数位,小数点,和小数位。示例:
0.0
123.4
-123.456
(2)科学计数法
FLUX 没有直接提供科学计数法语法,但是你可以使用字符换写出一个科学计数法表示的浮点数,再使用float( )函数将该字符串转换为浮点数。
示例:
1.23456e+78
// Error: error @1:8-1:9: undefined identifier e
float(v: "1.23456e+78")
// Returns 1.23456e+78 (float)
(3)无限
FLUX 也没有提供关于无限的语法,定义无限要使用字符串与 float( )函数结合的方式。示例:
+Inf
// Error: error @1:2-1:5: undefined identifier Inf
float(v: "+Inf")
// Returns +Inf (float)
(4)Not a Number 非数字
FLUX 语言不支持直接从语法上声明 NAN,但是你可以使用字符串与 float( )函数的方法声明一个NaN 的 float 类型变量。
示例:
NaN
// Error: error @1:2-1:5: undefined identifier NaN
float(v: "NaN")
// Returns NaN (float)
(5)将其他基本类型转换为 float
使用 float 函数可以将基本数据类型转换为 float 类型的值。
- string:必须得是一个符合数字格式的字符串或者科学计数法。
- bool:true 转换为 1.0,false 转换为 0.0
- int(整数)
- uint(无符号整数)
示例:
float(v: "1.23")
// 1.23
float(v: true)
// Returns 1.0
float(v: 123)
// Returns 123.0
(6)对浮点数进行逻辑判断
使用 FLUX 表达式来比较浮点数。逻辑表达式两侧必须是同一种类型。示例:
12345600.0 == float(v: "1.23456e+07")
// Returns true
1.2 > -2.1
// Returns true
Integer 整数
(1)定义一个整数
一个 integer 的变量是一个 64 位有符号的整数。
- 类型名称:int
- 最小值:-9223372036854775808
- 最大值:9223372036854775807
一个整数的声明就是普通的整数写法,前面可以加- 表示负数。-0 和 0 是等效的。示例:
02
1254
-1254
(2)将数据类型转换为整数
使用 int( )函数可以将下述的基本类型转换为整数:
- string:字符串必须符合整数格式,由数字[0-9]组成
- bool:true 返回 1,0 返回 false
- duration:返回持续时间的纳秒数
- time:返回时间点对应的 Unix 时间戳纳秒数
- float:返回小数点前的整数部分,也就是截断
- unit:返回等效于无符号整数的整数,如果超出范围,就会发生整数环绕
int(v: "123")
// 123
int(v: true)
// Returns 1
int(v: 1d3h24m)
// Returns 98640000000000
int(v: 2021-01-01T00:00:00Z)
// Returns 1609459200000000000
int(v: 12.54)
// Returns 12
你可以在将浮点数转换为整数之前进行舍入操作。
当你将浮点数转换为整数时,会进行截断操作。如果你想进行四舍五入,可以使用math 包中的 round( )函数。
(3)将表示十六进制数字的字符串转换为整数
将表示十六进制数字的字符串转换为整数,需要。
-
引入 contrib/bonito-io/hex 包
-
使用 hex.int( )函数将表示十六进制数字的字符串转换为整数
import "contrib/bonitoo-io/hex"
hex.int(v: "e240")
// Returns 123456
UIntegers 无符号整数
FLUX 语言里不能直接声明无符号整数,但这却是一个 InfluxDB 中具备的类型。在FLUX 语言中,我们需要使用 uint 函数来讲字符串、整数或者其他数据类型转换成无符号整数。
示例:
uint(v: "123")
// 123
uint(v: true)
// Returns 1
uint(v: 1d3h24m)
// Returns 98640000000000
uint(v: 2021-01-01T00:00:00Z)
// Returns 1609459200000000000
uint(v: 12.54)
// Returns 12
uint(v: -54321)
// Returns 18446744073709497295
Null 空值
(1)定义一个 Null 值
FLUX 语言并不能在语法上直接支持声明一个 Null,但是我们可以通过 debug.null 这个函数来声明一个指定类型的空值。
示例:
import "internal/debug"
// Return a null string
debug.null(type: "string")
// Return a null integer
debug.null(type: "int")
// Return a null boolean
debug.null(type: "bool")
(2)定义一个 null
截至目前,还无法在 FLUX 语言中手动地声明一个NULL 值。
注意!空字符串不是 null 值。
(3)判断值是否为 null
你可以使用 exists(存在)这个关键字来判断目标值是不是非空,如果是空值我们会得到一个 false,如果不是空值我们会得到一个 true。
示例:
import "array"
import "internal/debug"
x = debug.null(type: "string")
y = exists x
// Returns false
FLUX 类型不代表 InfluxDB 类型
需要注意,FLUX 语言里有些基本数据类型比如持续时间(Duration)和正则表达式是不能放在表流里面充当字段类型的。简单来说,Duration 类型和正则表达式类型都是 FLUX 语言特有的。有些类型是为了让 FLUX 在编写代码时更加方便,让它能够拥有更多的特性, 但这并不代表这些类型能够存储到 InfluxDB 中。
4 个复合类型
Record(记录)
(1)定义一个 Record
一个记录是一堆键值对的集合,其中键必须是字符串,值可以是任意类型,在键上没有空白字符的前提下,键上的双引号可以省略。
在语法上,record 需要使用{}声明,键值对之间使用英文逗号(,)分开。另外,一个Record 的内容可以为空,也就是里面没有键值对。
示例:0
{foo: "bar", baz: 123.4, quz: -2}
{"Company Name": "ACME", "Street Address": "123 Main St.", id: 1123445}
(2)从 record 中取值
-
点表示法取值
如果 key 中没有空白字符,那么你可以使用 .key 的方式从 record 中取值。示例:
c = {name: "John Doe", address: "123 Main St.", id: 1123445} c.name // Returns John Doe c.id // Returns 1123445 -
中括号方式取值
可以使用[" "]的方式取值,当 key 中有空白字符的时候,也只能用这种方式来取值。
c = {"Company Name": "ACME", "Street Address": "123 Main St.", id: 1123445} c["Company Name"] // Returns ACME c["id"] // Returns 1123445
(3)嵌套与链式取值
Record 类型可以进行嵌套引用。
从嵌套的 Record 中引用值的时候可以采用链式调用的方式。链式调用时,点表示法和中括号还可以混用。
customer =
{
name: "John Doe",
address: {
street: "123 Main St.",
city: "Pleasantville",
state: "New York"
}
}
customer.address.street
// Returns 123 Main St.
customer["address"]["city"]
// Returns Pleasantville
customer["address"].state
// Returns New York
(4)record 的 key 是静态的
record 类型变量中的 key 是静态的,一旦声明,其中的 key 就被定死了。一旦你访问这个 record 中一个没有的key,就会直接抛出异常。正常的话应该返回null。
o = {foo: "bar", baz: 123.4}
o.key
// Error: type error: record is missing label haha
// 错误:类型错误:record 找不到 haha 这个标签
(5)操作 records
使用 with 操作符可以拓展一个 record,当原始的 record 中有这个 key 时,原先 record 的值会被覆盖;如果原先的 record 中没有制定的 key,那么会将旧 record 中的所有元素和with 中指定的元素复制到一个新的 record 中。
示例: 覆盖原先的值,并添加一个 key 为 pet,value 为"Spot"的元素。
c = {name: "John Doe", id: 1123445}
{c with name: "Xiao Ming", pet: "Spot"}
// Returns {id: 1123445, name: Xiao Ming, pet: Spot}

(6)列出一个 record 中所有的 keys
-
导入 experimental(实验的)包。
-
使用 expertimental.objectyKeys(o:c)方法来拿到一个 record 的所有key。
示例:
import "experimental"
c = {name: "John Doe", id: 1123445}
experimental.objectKeys(o: c)
// Returns [name, id]
(7)比较两个 record 是否相等
可以使用双等号= =来判断两个 record 是否相等。如果两个 record 的每个 key,每个key 对应的 value 和类型都相同,那么两个 record 就相等。示例:
{id: 1, msg: "hello"} == {id: 1, msg: "goodbye"}
// Returns false
{foo: 12300.0, bar: 34500.0} == {bar: float(v: "3.45e+04"), foo:
float(v: "1.23e+04")}
// Returns true
(8)将 record 转为字符串
使用 display( )函数可以将 record 转为字符串。示例:
x = {a: 1, b: 2, c: 3}
display(v: x)
// Returns "{a: 1, b: 2, c: 3}"
(9)嵌套 Record 的意义
注意,嵌套的 Record 无法放到 FLUX 语言返回的表流中,这个时候会发生类型错误, 它会说 Record 类型不能充当某一列的类型。那 FLUX 为什么还支持对 Record 进行嵌套使用呢?
其实这是为了一些网络通讯的功能来服务,在 FLUX 语言中我们有一个 http 库。借助这个函数库,我们可以向外发送 http post 请求,而这种时候我们就有可能要发送嵌套的json。细心的同学可能发现,我们的 record 在语法层面上和 json 语法是统一的,而且FLUX 语言提供了一个 json 函数库,借助这个库中的 encode 函数,我们可以轻易地将一个record 转为 json 字符串然后发送出去。
Array(数组)
(1)定义一个 Array
数据是一个由相同类型的值构成的有序序列。
在语法上,数组是用方括号[ ]起来的一堆同类型元素,元素之间用英文逗号( , )分隔, 并且类型必须相同。
示例:
["1st", "2nd", "3rd"]
[1.23, 4.56, 7.89]
[10, 25, -15]
(2)从 Array 中取值
可以使用中括号[ ] 加索引的方式从数组中取值,数组索引从 0 开始。示例:
arr = ["one", "two", "three"]
arr[0]
// Returns one
arr[2]
// Returns two
(3)遍历一个数组
(4)检查一个数组中是否包含某元素
示例:使用 contains( )函数可以检查一个数组中是否包含某个元素。
names = ["John", "Jane", "Joe", "Sam"]
contains(value: "Joe", set: names)
// Returns true
Dictionary(字典)
(1)定义一个字典
字典和记录很像,但是 key-value 上的要求有所不同。
一个字典是一堆键值对的集合,其中所有键的类型必须相同,且所有值的的类型必须相同。
在语法上,dictionary 需要使用方括号[ ]声明,键的后面跟冒号(:)键值对之间需要使用英文逗号( , )分隔。
示例:
[0: "Sun", 1: "Mon", 2: "Tue"]
["red": "#FF0000", "green": "#00FF00", "blue": "#0000FF"]
[1.0: {stable: 12, latest: 12}, 1.1: {stable: 3, latest: 15}]
(2)引用字典中的值
-
导入 dict 包
-
使用 dict.get( )并提供下述参数:
dict:要取值的字典
key:要用到的 key
default:默认值,如果对应的 key 不存在就返回该值
示例:
import "dict"
positions =
[
"Manager": "Jane Doe",
"Asst. Manager": "Jack Smith",
"Clerk": "John Doe",
]
dict.get(dict: positions, key: "Manager", default: "Unknown position")
// Returns Jane Doe
dict.get(dict: positions, key: "Teller", default: "Unknown position")
// Returns Unknown position
(3)从列表创建字典
-
导入 dict 包
-
使用 dict.fromList( )函数从一个由 records 组成的数组中创建字典。其中,数组中的每个 record 必须是{key:xxx,value:xxx}形式
示例:
import "dict"
list = [{key: "k1", value: "v1"}, {key: "k2", value: "v2"}]
dict.fromList(pairs: list)
// Returns [k1: v1, k2: v2]
(4)向字典中插入键值对
-
导入 dict 包
-
使用 dict.insert( )函数添加一个新的键值对,如果 key 早就存在,那么就会覆盖这个 key 对应的value。
示例:
import "dict"
exampleDict = ["k1": "v1", "k2": "v2"]
dict.insert(dict: exampleDict, key: "k3", value: "v3")
// Returns [k1: v1, k2: v2, k3: v3]
(5)从字典中移除键值对
-
引入 dict 包
-
使用 dict.remove 方法从字典中删除一个键值对
示例:
import "dict"
exampleDict = ["k1": "v1", "k2": "v2"]
dict.remove(dict: exampleDict, key: "k2")
// Returns [k1: v1]
function(函数)
(1)声明一个函数
一个函数是使用一组参数来执行操作的代码块。函数可以是命名的,也可以是匿名的。在小括号( )中声明参数,并使用箭头=\将参数传递到代码块中。
示例:
square = (n) => n * n
square(n:3)
// Returns 9
FLUX 不支持位置参数。调用函数时,必须显示指定参数名称。
(2)为函数提供默认值
我们可以为某些函数指定默认值,如果为函数指定了默认值,也就意味着在调用这个函数时,有默认值的函数时非必须的。
示例:
chengfa = (a,b=100) => a* b
chengfa(a:3)
// Returns 300
函数包
Flux 的标准库使用包组织起来的。包将 Flux 的众多函数分门别类,默认情况下加载universe 包,这个包中的函数可以不用 import 直接使用。其他包的函数需要在你的 Flux 脚本中先用 import 语法导入一下。
示例:
import "array"
import "math"
import "influxdata/influxdb/sample"
但是,截至目前,虽然你可以自定义函数,但是你无法自定义包。如果希望将自己的自定义函数封装在一个包里以供复用,那就必须从源码上进行修改。
这是 FLUX 语言的文档 https://docs.influxdata.com/flux/v0.x/ ,通常来说我们使用FLUX 的文档主要是用它来查看一些函数怎么用。
FLUX 查询 InfluxDB
FLUX 查询InfluxDB 的语法
使用 FLUX 语言查询 InfluxDB,必须以 from -\ range 打头。例如:
from(bucket: "test_init")
|> range(start: -1h)
range 必须紧跟在 from 后面,不这么写的话会直接报错。
表、表流以及序列
我们知道 InfluxDB 是使用序列的方式去管理数据的。而 FLUX 语言又企图兼容一些关系型数据库的查询,而关系型数据库里的数据结构就是一个有行有列的 table。因此对于FLUX 语言来说,就需要将序列和表统一成一个东西。
所以 FLUX 引入了表流的概念。
简单来说,FLUX 可以一次性查出多个序列,这个时候一个序列对应一张表,而表流其实就是多张表的集合。同时表流和表的关系其实是全表和子表的关系,子表是全表按照_field,tag_set 和_measurement 进行 group by 之后的结果。在这种情况下,如果调用聚合函数,其实只会在子表中进行聚合。
最后,如果一张表对应的是一个序列了,那么一张表里的一行其实就对应着序列中的一个数据点了。
filter 维度过滤
使用 filert 函数可以对数据按照_measurement、标签集和字段级进行过滤。
类型转换函数与下划线字段
Flux 语言中有很多不用指定字段名称的管道函数,比如 toInt()。其实 toInt()这个函数默认要求你的字段中必须要有_value 字段,没有_value 字段的话也会直接报错。
其实在我们查询出来的数据中,以下划线开头的字段其实代表了一种约定,就是FLUX 中有很多函数想要正常运行时要依赖于这些下划线打头的字段的。
所以原则上来说,程序员应该遵守这些约定,不要擅自更改下划线开头的字段。
map 函数
map 函数的作用是遍历表流中的每一条数据。示例:
import "array"
array.from(rows: [{"name":"tony"},{"name":"jack"}])
|> map(fn: (r)=> {
return if r["name"] == "tony" then {"_name": "tony 不是jack"} else {"_name":"jack 不是 tony"}
})
这里需要注意,map 函数需要我们传递一个参数 fn,它要求传递一个单个参数输入, 且输出必须是record 的函数,其中输入数据的类型会是 record。
自定义管道函数
此处,我们定义一个管道函数,它可以将表流中的_value 字段的值乘上 x 倍。
big100 = (table=<-,x) => {
return table
|> map(fn: (r) => ({r with "_value":r["_value"]*x}))
}
接下来我们调用刚才声明的函数,最终整个脚本如下:
big100 = (table=<-,x) => {
return table
|> map(fn: (r) => ({r with "_value":r["_value"]*x}))
}
from(bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> big100(x:100)
可以自行运行查看函数效果。
这里需要强调的是,管道函数的第一个参数必须写成 table=<-,它表示通过管道符输入进来的表流数据,需要注意,table 并不一定写成table 但是=<-的格式绝对不能变。
在文档中区分管道函数和普通函数
再次来到函数文档。
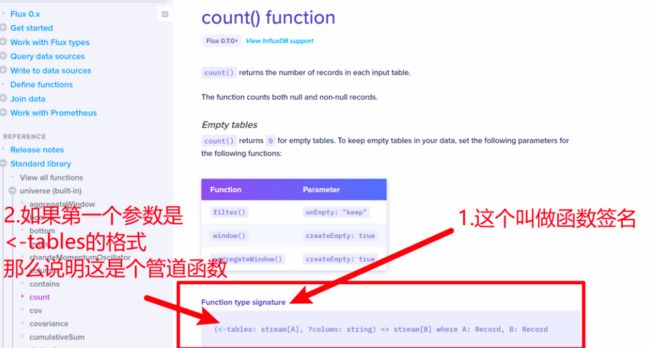
当我们看到一个函数文档,它会有一个区域叫做 Function type Signature(函数签名),它表示着函数接收哪些参数以及会返回什么。最前面的小括号里的内容就是参数列表,如果参数列表的第一个参数是<-tables: stream[A],那就表示它是一个可以接收表流输入的管道函数。
反之,如果没有<-tables: stream[A],那么它就是一个普通函数。
window 和 aggregateWindow 函数
window 函数和 aggregateWindow 函数其实代表着 InfluxDB 中的两种开窗方式,两者不同的地方在于,window 函数会将整个表流重新分组。window 开窗后,是按照序列+窗口的方式对整个表流进行分组。但是 aggregateWindow 函数会保留原来的分组方式,这样一来, 使用 aggregateWindow 函数进行开窗后的表流,仍然是按照序列的方式来分组的。
yield 和 join
当 flux 脚本中出现未被赋值给某个变量的表流时,InfluxDB 执行 FLUX 脚本时会自动帮他们在管道的最后面加上|> yield(name: “_result”)函数,yield 函数其实是指定了我们当前这个表流是整个 FLUX 脚本最后返回的结果,而且这个结果的名字叫"_result"。当 FLUX 脚本中出现多个为赋值给变量的表流时,给多个表流自动补上|>yield(name:“_result”)就会出问题了,这是因为当有多个表流后面都有|>yield 时,其实相当于一个 FLUX 脚本会返回多个结果。但是此处要求名称是不能重复的,所以当有多个未赋值的表流时,就必须显示指定 yield(name:“xxx”),而且名称千万不可重复。
但是,在一个 FLUX 脚本里同时返回多个结果集并不是推荐的操作,这通常会让程序的逻辑变的很奇怪,我们之所以能在一个 FLUX 脚本里面写多次 from 函数,其实是为了方便我们进行join 的。
再但是,并不建议在 FLUX 脚本中使用 join 操作,这必须要谈到 FLUX 脚本的常见使用场景,就是每隔一段时间进行一次查询。如果这个时候,我用一个 from 从 InfluxDB 中查询数据,其中有 code=01 等机器编号信息。然后我再用一个 from 去查询 mysql,得到一张机器的属性表。接下来对两张表进行 join,这在逻辑上很合理,但最大的问题就是FLUX 脚本无法实现数据的缓存。如果我这个 FLUX 脚本是每 15 秒执行一次,那就会导致我们需要每 15 秒要去 mysql 上全表扫描一遍机器信息表,效率十分低下。
个人建议仅使用 FLUX 进行简单的查询,然后在应用层的程序里进行 join 操作。