同态加密&隐私保护【更新中】
关于《密码学》
# Paillier 加法同态加密
Paillier加密算法的推导
Paillier同态加密的介绍以及c++实现
paillier加密算法原理详解
paillier
# 函数加密(FE)
PRF (Pseudo-Random Functions) 【1】 【2】
# 谓词加密(Predicate encryption)
密码介绍 【1】【2】
Inner Product Predicate Encryption(IPPE)
Shen-Shi-Waters Encryption (SSW)
# 属性基加密(ABE)
【1】【2】
# CKKS 全同态加密 - 复数近似
【0】
【1】【1】【1】CKKS 同态加密方案
【2】 同态加密:CKKS原理之旋转(Rotation)
【3】 Paillier 和 CKKS 的效率对比
【4】【4】C++实现:SEAL库
【5】【5】Python实现:TenSEAL库。密文向量乘明文矩阵【paper:Algorithms in helib】,它可以使用多线程来更快地运行。(参数含义)
# 证据加密
- [STOC:GGSW13],简介请见 Link
关于《查询》
总览
相关知识点 词条
多维查询 树结构
Trie结构 好多树
最近邻检索的简单综述
数据库系统概论
参考文献
特征点匹配和数据库查、图像检索本质上是同一个问题,都可以归结为一个通过距离函数在高维矢量之间进行相似性检索的问题,如何快速而准确地找到查询点的近邻,不少人提出了很多高维空间索引结构和近似查询的算法。
一般说来,索引结构中相似性查询有两种基本的方式:
1)范围查询,范围查询时给定查询点和查询距离阈值,从数据集中查找所有与查询点距离小于阈值的数据;
2)K近邻查询,就是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,它就是最近邻查询。
其他:(dynamic) skyline查询
针对特征点匹配也有两种方法:
1)线性扫描,也就是穷举搜索,依次计算样本集E中每个样本到输入实例点的距离,然后抽取出计算出来的最小距离的点即为最近邻点。此种办法简单直白,但当样本集或训练集很大时,它的缺点就立马暴露出来了。举个例子,在物体识别的问题中,可能有数千个甚至数万个SIFT特征点,而去一一计算这成千上万的特征点与输入实例点的距离,明显是不足取的。
2)构建数据索引,因为实际数据一般都会呈现簇状的聚类形态,因此我们想到建立数据索引,然后再进行快速匹配。索引树是一种树结构索引方法,其基本思想是对搜索空间进行层次划分。根据划分的空间是否有混叠可以分为Clipping和Overlapping两种。前者划分空间没有重叠,其代表就是k-d树;后者划分空间相互有交叠,其代表为R树。
R-tree
什么是R树?
R tree基本原理
经典查找算法 — R树
空间数据索引 R Tree(R树)完全解析及Java实现
Oracle Spatial中的空间索引
图解MySQL索引——B-Tree
- B树:Balanced
- R树是一棵用来存储高维数据的平衡树。每个R树的叶子结点包含了多个指向不同数据的指针。
- eg:地图上根据经纬度坐标查找,需要x,y共同起作用来搜索。
- R树采用了一种称为MBR (Minimal Bounding Rectangle) 的方法,“最小边界矩形”。从叶子结点开始用矩形将空间框起来,结点越往上,框住的空间就越大,以此对空间进行分割。
- R树的查询效率会因重叠区域的增大而大大减弱,在最坏情况下,其时间复杂度甚至会由对数搜索退化成线性搜索。
M-tree
【1】 Metric-Tree
【2】 M-tree 代码
【3】M-Tree for Similarity Search
【4】 M-tree
a variant of metric-trees: Spill-Trees
kd-tree
【1】 KD树+BBF算法
【2】一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
VP Tree (Vantage Point Tree)
【1】
【2】
【3】MVP Tree (multi-vantage point tree)
Quad-Tree
Hanan Samet. 1984. The Quadtree and Related Hierarchical Data
Structures. ACM Comput. Surv. 16, 2 (June 1984), 187–260.
DOI:https://doi.org/10.1145/356924.356930
Learned Index
The Case for Learned Index Structures, SIGMOD, 2018. Jeffrey Dean 联署论文
论文解读 【youtube视频】 【1】 【2】【3】 【4】
- Learned Index Structures 的主要思想是将数据结构替换为机器学习的模型,查找操作变成了根据key做索引数据位置的预测。相比传统的tree index,用一个函数(也就是learned index的model)来表示 【key值和position关系】。
- 优点:1.查询用时快;2.内存空间很小。
- 在全量(离线数据)+增量(实时写数据)的场景下,可以用learned index构建全量索引,增量仍然采用传统的方式构建索引。
空间填充曲线
Z阶曲线(Z-Order Curve):GeoHash 空间索引
Hilbert曲线
Peano曲线
【1】
XZ阶曲线:
从数学的角度上看,可以将空间填充曲线看成是一种把d 维空间数据转换到1维连续空间上的映射函数。
最常用的方法包括Z-Ordering[5]、Hilbert[6]曲线和XZ-Ordering,其中Z-Ordering和Hilbert曲线主要用于管理点对象,XZ-Ordering用于管理空间扩展对象,如线和多边形对象。
Python实现knn查询
Python 统计学习方法——kd Tree实现K近邻搜索 【1】 【2】
K近邻(KNN)算法、KD树及其python实现
kd-tree找最邻近点 Python实现
浅谈KNN算法原理及python程序简单实现、KD树、球树
RNN:我是谁的kNN?多维反向k邻近查询
查询
vChain,关于可验证的查询
Voronoi图
【1】
【2】
【3】《GIS算法基础 》Delaunay三角网与Voronoi图算法
【4】【计算几何】Delaunay 三角化原理与实现
【5】Delaunay三角剖分算法初探
【6】基于Delaunay图的快速最大内积搜索算法
【7】基于空间离散点的有限元三角形网格自动生成,Delaunay中文介绍
关于《距离》
机器学习中距离和相似性度量方法
时间序列聚类综述
![]()
时间序列距离
【1】基于动态规划思想的时间序列距离方法介绍
【2】时间序列聚类、相似性度量
【公众号:时序人】
【时间序列-数据集】,文件解压密码:attempttoclassify,以前是someone。
编辑距离
【1】
【2】
DTW (Dynamic Time Warping)
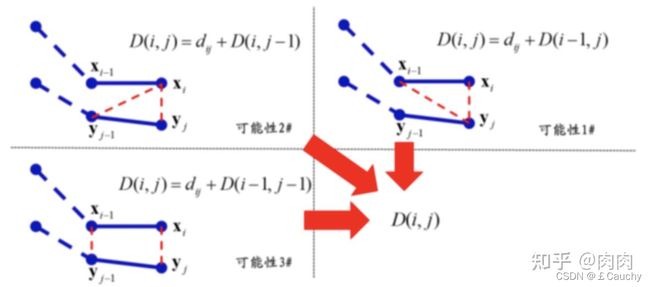
【1】DTW动态时间规整
【2】基于DTW的时序分类
【3】DTW算法Python实现:(包:dtw; dtw_c; fastdtw)
【4】fast-DTW及其代码详解
【5】文章:Searching and mining trillions of time series subsequences under dynamic time warping
【6】DTW优化:使用DTW实现万亿级别序列匹配
TWED
空间序列距离、曲线 / 轨迹相似
【1】【交通行业】轨迹相似性度量介绍
【2】轨迹相似性度量
【3】判断两条轨迹(或曲线)的相似度
【4】判断两条曲线相似度_时间序列相似性度量综述
【5】轨迹相似性度量方法
【6】如何通过轨迹相似性度量方法,发现新冠易感人群

Fréchet distance
Hausdorff distance
汉明距离 (Hamming distance)
余弦距离
关于《特征匹配》
SIFT算法
SIFT图像特征匹配,即尺度不变特征变换(Scale-invariant feature transform)算法,是由David G.Lowe于1999年提出,并在2004年加以完善。
利用SIFT方法检测图像特征点的实质就是在不同尺度空间上查找特征点,这些特征点对应的就是不同尺寸的地物。SIFT配准方法主要分为以下几个步骤:
- DOG尺度空间的建立
- 尺度空间中提取关键点
- 生成特征描述子
- 特征点匹配
- 后续的配准流程,如转换模型求解、重采样等。
【1】SIFT图像匹配及其python实现
ANN 近似近邻查询
- LSH,
- ITQ,
- NSW,HNSW(Hierarchical Navigable Small World)【1】
【1】基准数据集
【2】最近邻搜索和近似最近邻搜索(NN和ANN)和库
【3】随机投影森林-一种近似最近邻方法(ANN)
【4】Product Quantization:【5】
将高维数据量化划分为一些独立的低维子空间的Cartesian乘积,称之为PQ法。
3.2 矢量量化
其代表是乘积量化(PQ)。它的主要思想是将特征向量进行正交分解,在分解后的低维正交子空间上进行量化,由于低维空间可以采用较小的码本进行编码,因此可以降低数据存储空间 。
PQ方法采用基于查找表的非对称距离计算(Asymmetric Distance Computation,ADC)快速求取特征向量之间的距离,在压缩比相同的情况下,比采用汉明距离的二值编码方法,采用ADC的PQ方法的检索精度更高。
【5】参考文献
其他
- 洋葱路由器
- 安全多方计算技术 (Security Multi-Party Computation, SMC) 【1】,【2】
- 时空数据:轨迹数据的地理关联建模与分析
- 保序加密
代码实现
[scipy.spatial]