排序算法 - 快速排序(Lomuto and Hoare 分区)
文章目录
-
- 1.快速排序概念
- 2.算法实现
-
- 2.1 Lomuto 分区方案
- 2.2 Hoare 分区方案
- 2.3 Hoare vs Lomuto
- 3.避免可能的不稳定性
- 4.小礼物
TIP:更多文章笔者考虑同步到 Github 新仓库 javgocn/JavaPlanet,目前内容较少,后续会陆续更新。它将是一个初学者值得关注的仓库,因为每一篇都是用心之作哦 。(阅读体验更人性化一些)
1.快速排序概念
快速排序是一种高效的通用排序算法,由英国计算机科学家托尼·霍尔(Tony Hoare)于 1960 年发明,并于 1961 年发表。尽管有许多新的排序算法被发明,快速排序仍然 是现代计算中常用的排序算法之一。在实际应用中,对于随机数据,它通常比归并排序和堆排序更快,尤其是数据量较大时。
快速排序采用了 “分而治之” 的策略。它的基本思想是从待排序数组中选择一个 “基准(pivot)” 元素,然后根据其他元素与基准元素的大小关系,将它们划分为两个子数组。在每次分区操作结束后,基准元素都被放置在其最终应该出现的位置上。接着,算法对这两个子数组进行递归排序,直到子数组的长度小于等于1。由于这种分区和交换的特性,快速排序有时也被称为分区交换排序(partition-exchange sort)。
快速排序属于比较排序,因为它的核心操作是将数组元素与选定的基准元素进行比较。如果某个元素小于基准元素,它会被放到左子数组;如果大于或等于基准元素,它会被放到右子数组。需要注意的是,由于这种比较和交换的方式,快速排序可能是不稳定的。这意味着原始数据中相等的元素在排序后可能会改变它们的相对顺序。
从性能角度来看,快速排序算法平均需要 O(n log n) 次比较来对 n 个项目进行排序,在最坏的情况下它会进行 O(n^2)次比较。
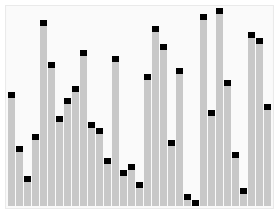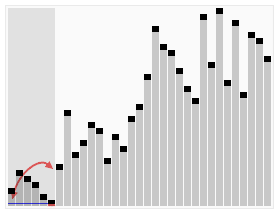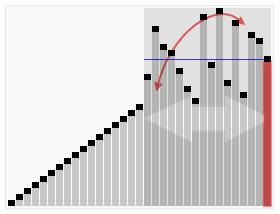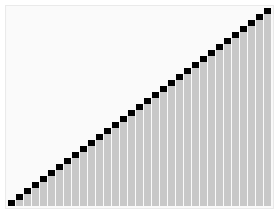
快速排序算法(水平线是基准值)
2.算法实现
上面我们说过,快速排序是基于 “分而治之” 策略的排序方法。它通过一个称为 “分区(partition)” 的步骤来对数组进行排序。由于分区的实现方式可能有所不同,所以快速排序有多种变体,但它们都遵循相同的基本原则。
简单来说,当我们对一个包含至少两个元素的数组进行排序时,快速排序会将其分为两个子数组,确保第一个子数组中的每个元素都不大于第二个子数组中的任何元素。然后,它会递归地对这两个子数组进行同样的操作。
下面是快速排序的基本步骤:
- 检查数组长度:如果数组中的元素少于两个,那么不需要排序,直接返回。如果是对于非常短的数组,我们可能会使用其他排序方法。
- 选择基准值:从数组中选择一个值作为基准(piovt)。选择的方法可能因实现而异,有时甚至可能是随机的。
- 进行分区:根据基准值重新排列数组,确保所有小于基准的元素都在其左侧,而大于基准的元素都在其右侧。等于基准的元素可以放在任意一侧。
- 确认基准位置:大部分分区方法都会确保一轮分区结束后基准值最终位于正确的排序位置。
- 递归排序:对基准左侧和右侧的子数组递归地应用快速排序。
值得注意的是,如何选择基准值和具体的分区方法可能会不同程度的影响快速排序的效率。因此,当我们谈论快速排序的性能时,需要明确使用的具体方法和策略。
下面是一个对随机顺序的数组进行快速排序的完整示意图,图中的深色元素为选择的基准(pivot),在这里它始终被选定为分区中的最后一个元素。
注意 ⚠️:
在快速排序算法中,如果我们每次都选择分区的最后一个元素作为基准来进行排序,那么在某些特定情况下(如数组已经排序或数组中所有元素都相同)这种选择策略会导致算法的性能下降,具体到时间复杂度 为O(n^2)。这是因为在这些特定情况下,每次分区都会非常不均匀,导致递归深度增加,从而增加了总的计算时间。
举个例子就很容易理解了,假设我们有一个已排序的数组:
[1,2,3,4,5,6,7,8,9,10]
如果我们始终选择最后一个元素作为基准来进行分区,那么在第一次分区时,我们选择 10 作为基准。这会导致数组被分为两部分:
左子数组:[1,2,3,4,5,6,7,8,9]
右子树组:[10] (位置确定)
可以看到,这种分区是非常不均匀的。左边的部分包含了 9 个元素,而右边的部分只有 1 个元素。接下来,我们继续对左边的部分进行快速排序。再次选择最后一个元素 9 作为基准,数组又被分为:
左子数组:[1,2,3,4,5,6,7,8]
右子树组:[9] (位置确定)
这个模式会持续下去,每次都选择最后一个元素作为基准,导致每次分区都非常不均匀。由于每次都只能确定一个元素的最终位置(即基准元素),这意味着我们需要进行 n 次递归调用来排序整个数组,其中 n 是数组的长度。这就是为什么递归深度会增加,从而增加了总的计算时间。
在实际的排序过程中,尤其是在处理大数据集时,经常会遇到已经排序的子数组或由相同元素组成的子数组。如果在这种情况下,我们选择中间元素作为基准来进行排序,那么这种选择策略会比选择最后一个元素作为基准的策略有更好的性能。这是因为选择中间元素作为基准更可能使分区均匀,从而减少递归深度和总的计算时间。
下面我们将介绍两种特定的分区方法,那就是 “Lomuto 分区方案” 和 “霍尔(Hoare)分区方案”。
2.1 Lomuto 分区方案
Lomuto 分区方案是快速排序中的一种实现方法,它选择数组的最后一个元素作为基准。在这个方案中,我们使用两个索引 i 和 j 来遍历数组。索引 i 之前的元素都小于基准,而索引 i 到 j 的元素都大于或等于基准。这种方案相对简洁,容易理解,因此经常用于初学者的教材中。
TIP:请记住上面提到的注意点,那就是当数组已经排序或所有元素都相等时,这种方案的性能会下降,时间复杂度可能达到 O(n^2)。
下面是该方案的 Java 实现:
/**
* 快速排序(Lomuto 分区方案)
*/
public class QuickSortLomuto {
/**
* 分区函数,确定基准点的最终位置(索引)
* @param arr 待分区数组
* @param low 当前分区下届
* @param high 当前分区上届
* @return 基准点的位置(索引)
*/
private static int partition(int[] arr,int low,int high){
// Lomuto 分区方案:选择最右边的元素作为基准点
int pivot = arr[high];
// 临时的基准索引 i:用于指向当前小于基准点的元素的位置(循环中,第一步是先自增,然后再使用,所以初值要减 1,从而使得第一次循环时 i 指向的是数组的第一个元素,也就是 j 指向的元素)
int i = low - 1;
// 小于基准点元素的索引 j:用于遍历数组,找出小于基准点的元素
for (int j = low; j < high; j++) {
// 在 j 指针向右移动的过程中,如果遇到小于基准点的元素
if(arr[j] <= pivot){
// 由于临时的基准索引 i 初始值为 low - 1,所以需要先自增,使其指向第一个元素(也就是 j 指向的元素)再进行交换
i++;
// 交换 i 指针(现在指向的是大于基准点的元素)和 j 指针(现在指向的是小于基准点的元素)指向的元素
// 交换后,i 指针指向的是小于基准点的元素,j 指针指向的是大于基准点的元素
swap(arr,i,j);
}
}
// 将临时基准元素索引 i 移动到正确的位置(在较小和较大元素的中间)
i++;
// 交换 i 指针(现在指向的是大于基准点的元素)和 high 指针(现在指向的是基准点)指向的元素
swap(arr,i,high);
// 返回基准点最终的位置(索引)
return i;
}
/**
* 交换数组中的两个元素
* @param arr 数组
* @param i 临时的基准索引
* @param j 遍历找到的小于基准点的元素的索引位置
*/
private static void swap(int[] arr,int i,int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
* 快速排序
* @param arr 待排序数组
* @param low 数组下届
* @param high 数组上届
*/
public static void quickSort(int[] arr,int low,int high){
// 递归终止条件(元素个数小于等于 1 个时,无需排序)
if(low >= high){
return;
}
// 分区,确定基准点的位置
int pivot = partition(arr,low,high);
// 递归调用,对左子数组进行快速排序
quickSort(arr,low,pivot - 1);
// 递归调用,对右子数组进行快速排序
quickSort(arr,pivot + 1,high);
}
public static void main(String[] args) {
int[] arr = {3,7,8,5,2,1,9,5,4};
quickSort(arr,0,arr.length - 1);
System.out.println(Arrays.toString(arr));
}
}
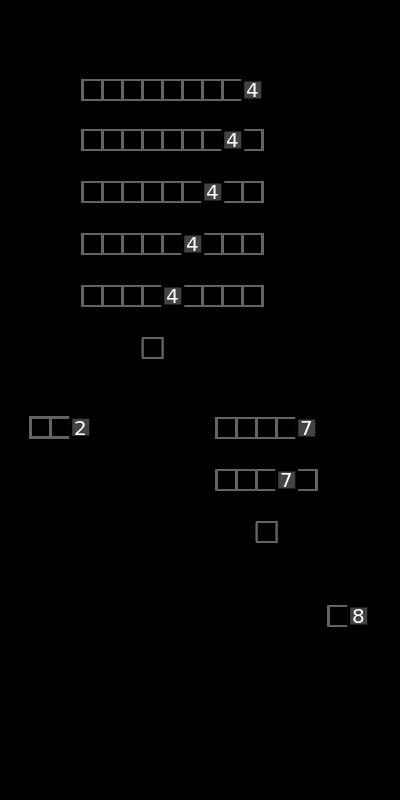
为了更好的理解上述代码的排序过程,结合下图进行再次理解:
2.2 Hoare 分区方案
Tony Hoare (霍尔)提出的原始快速排序分区方案是一种巧妙的方法,它使用两个指针来分区数组。
- 如何移动:这两个指针分别从数组的两端开始,并逐渐向彼此靠近。
- 目的何在:它们的任务是找到一个逆序对,即左侧的元素大于基准值,而右侧的元素小于基准值。
- 如何处理:当找到这样的逆序对时,如果左侧指针仍然在右侧指针的左边,这两个元素就会被交换,因为它们相对于彼此是错序的。
- 后续过程:然后,这两个指针会继续向中间移动,重复这个过程,直到它们交叉为止。
- 如何结束:当指针交叉时,分区完成,交叉点就是分区的界限。
下面是使用霍尔分区方案的快速排序的动画演示图,红色轮廓显示左侧和右侧指针的位置(分别为 i 和 j),黑色轮廓显示排序元素的位置,填充的黑色方块显示正在与之比较的值(基准)。
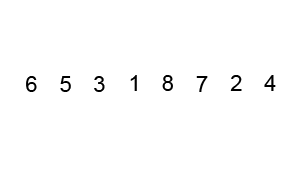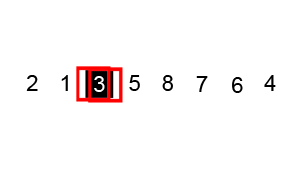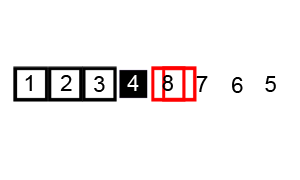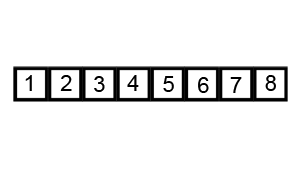
但是,有一个问题需要注意。有时,这种分区方法可能会导致一个子范围包含整个原始范围,这意味着算法没有实际上进行分区。为了解决这个问题,Hoare 提出了一个修正:在分区完成后,我们可以通过移除基准元素来缩小包含基准元素的子范围的大小。如果需要,我们还可以将基准元素与分隔点附近的元素交换,以确保快速排序能够正常终止。
假设我们有以下数组,我们要对其进行快速排序:
A = [8(i), 7, 6, 5(pivot), 4, 3, 2, 1(j)]
假设我们选择中间的元素 5 作为基准。现在,我们使用 Hoare 的方法,从两端开始,寻找逆序对。
- 从左侧开始,我们找到第一个大于 5 的元素是 8
- 从右侧开始,我们找到第一个小于 5 的元素是 1
我们交换这两个元素,得到:
A = [1(i), 7, 6, 5(pivot), 4, 3, 2, 8(j)]
继续这个过程,左指针会移动到 7,右指针会移动到 2,满足逆序对条件,然后交换它们:
A = [1, 2(i), 6, 5(pivot), 4, 3, 7(j), 8]
再次继续,左指针会移动到 6,右指针会移动到 3,满足逆序对条件,然后交换它们:
A = [1, 2, 3(i), 5(pivot), 4, 6(j), 7, 8]
再次继续,左指针会移动到 5,右指针会移动到 4,满足逆序对条件,然后交换它们:
A = [1, 2, 3, 4(i), 5(j), 6, 7, 8]
最后左指针继续向右移动,左指针和右指针最终交叉在 5 的位置(找到分区的界限):
A = [1, 2, 3, 4, 5(i,j), 6, 7, 8]
但是,你会注意到,除了 5 和 6, 7, 8 之外,所有的元素都小于 5。这意味着,如果我们继续这个算法(又重新对整个数组从左右两端开始),左侧的子范围 [1, 2, 3, 4] 会包含整个原始范围根本不会被交换(除了 6, 7, 8),这实际上并没有进行有效的分区。
为了解决这个问题,Hoare 提出了一个修正:在分区完成后,我们可以移除基准元素5,这样左侧的子范围就不再包括它。这意味着,在下一次递归调用时,我们只需要对 [1, 2, 3, 4] 这个子范围进行排序,而不是整个数组。
此外,虽然 Hoare 的原始描述是非常直观的,但在实际实现时,开发者通常会进行一些小的调整以提高效率。例如,为了简化实现,我们可以考虑将等于基准的元素也包括在逆序对的检测中。这样,我们就可以使用 “大于或等于” 和 “小于或等于” 的条件,而不是简单的 “大于” 和 “小于”。这种调整虽然看起来是微不足道的,但它实际上可以简化代码,并确保指针不会超出数组的范围。
最后,为了确保分区总是有效的,我们需要确保选择的基准元素不是范围内的最后一个元素。这是因为,如果基准是最后一个元素,并且所有其他元素都小于它,那么分区将不会前进。为了避免这种情况,我们可以通过选择范围中间的元素作为基准来进行调整。
下面是该方案的 Java 实现:
/**
* 快速排序(Hoare 分区方案)
*/
public class QuickSortHoare {
/**
* 分区函数,确定基准点的最终位置(索引)
* @param arr 待分区数组
* @param low 当前分区下届
* @param high 当前分区上届
* @return 基准点的位置(索引)
*/
private static int partition(int[] arr,int low,int high){
// Hoare 分区方案:选择中间的元素作为基准点
int pivot = arr[low + (high - low) / 2];
// 初始化左右指针
int i = low - 1; // 左指针:寻找大于基准点的元素
int j = high + 1; // 右指针:寻找小于基准点的元素
// 无限循环,直到左右指针相遇(找到分区点)
while (true){
// 将左指针向右移动,直到找到大于或等于基准点的元素
do{
i++;
}while (arr[i] < pivot);
// 将右指针向左移动,直到找到小于或等于基准点的元素
do {
j--;
}while (arr[j] > pivot);
// 如果左右指针相遇,说明找到了分区点,退出循环
if(i >= j){
// 分区点选择 j 的原因
return j;
}
// 找到符合逆序对条件的元素,交换两个元素的位置
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
/**
* 快速排序
* @param arr 待排序数组
* @param low 当前分区下届
* @param high 当前分区上届
*/
public static void quickSort(int[] arr,int low,int high){
// 确保索引在有效范围内
if (low >= 0 && high < arr.length && low < high){
// 分区操作,将数组分为两个分区,返回分区点的位置(索引)
int pivot = partition(arr,low,high);
// 对左分区进行快速排序
quickSort(arr,low,pivot);
// 对右分区进行快速排序
quickSort(arr,pivot + 1,high);
}
}
public static void main(String[] args) {
int[] arr = {6,5,3,1,8,7,2,4};
quickSort(arr,0,arr.length - 1);
System.out.println(Arrays.toString(arr));
}
}
对于上面的代码实现有两个注意点单独解释一下。
- 为什么使用 low + (high - low) / 2 而不是 (low + high) / 2 来计算中间值?
这是为了防止整数溢出。当你有两个非常大的整数(接近 Integer.MAX_VALUE)时,它们的和可能会超过整数的最大值,导致溢出。这种溢出可能会导致计算出的中间值是一个负数或者其他不正确的值。
举个例子,假设 low = Integer.MAX_VALUE - 1 和 hi = Integer.MAX_VALUE,那么 (lo + hi) 就会溢出。但是,使用 low + (high - lo) / 2 就不会有这个问题,因为 high - low 的结果是一个较小的正数,除以 2 后再加上 low 仍然是一个合法的整数。
所以,为了确保代码的健壮性,特别是在处理大数据集时,我们通常使用 low + (high - low) / 2 = low + high/2 - low/2 = low/2 + high/2 = (low + hign)/2 来计算中间值。
- 为什么在指针相遇时选择 return j 作为分区点而不是 return i?
在霍尔分区方案中,我们的目标是找到一个位置 j,使得在这个位置左边的所有元素都小于或等于基准,而右边的所有元素都大于或等于基准。
在循环中,i 指针从左向右移动,直到找到一个大于或等于基准的元素,而 j 指针从右向左移动,直到找到一个小于或等于基准的元素。当 i 和 j 指针交叉时,我们知道 j 指针的左边都是小于或等于基准的元素,而 i 指针的右边都是大于或等于基准的元素。
因此,当指针交叉时,j 是最后一个小于或等于基准的元素的位置,这正是我们想要的分区点。而 i 是第一个大于或等于基准的元素的位置,所以它不是一个合适的分区点。
选择 j 作为分区点可以确保左子数组的所有元素都小于或等于基准,而右子数组的所有元素都大于或等于基准,这是快速排序算法的核心思想。
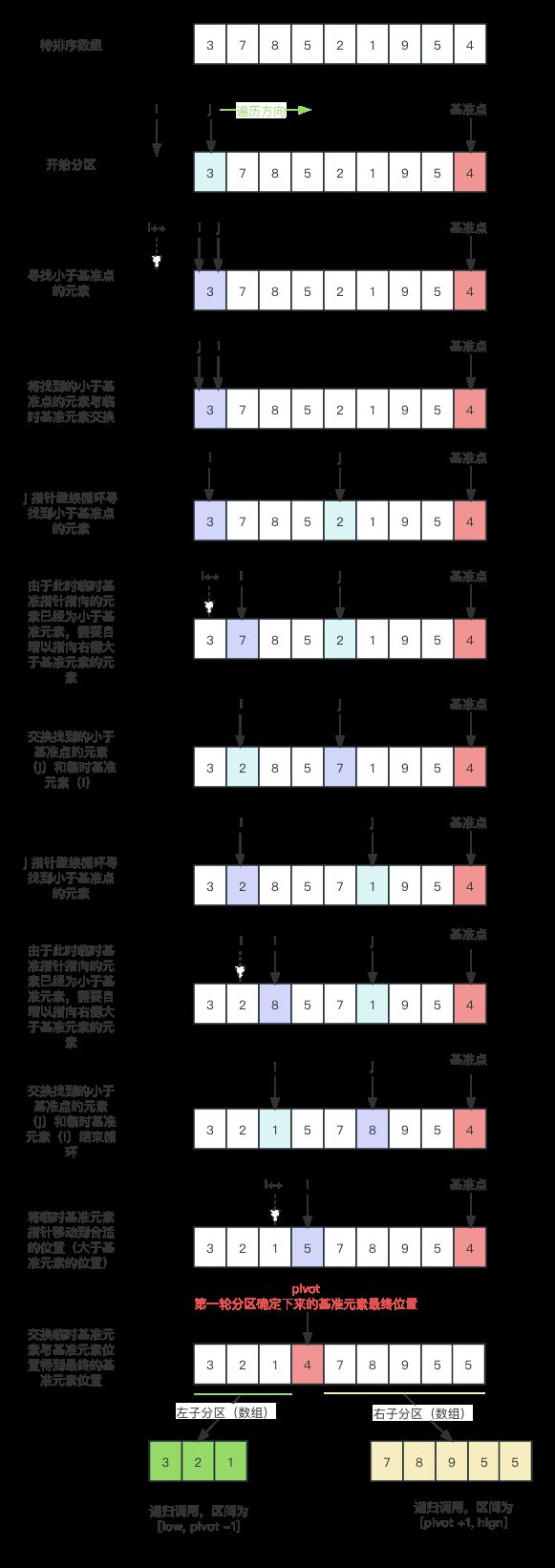
为了更好的理解上述代码的排序过程,我将待排序的数组设置得与下述动图一致,可以结合下图进行再次理解:
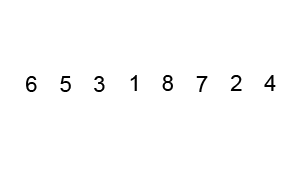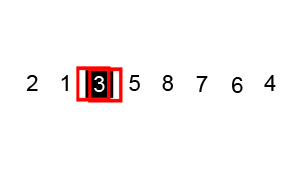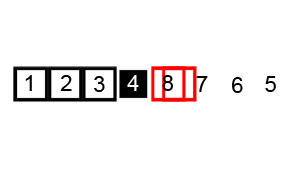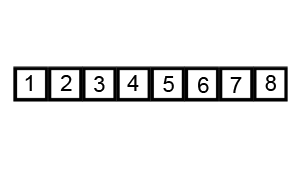
TIP:红色轮廓显示左侧和右侧指针的位置(分别为 i 和 j),黑色轮廓显示排序元素的位置,填充的黑色方块显示正在与之比较的值(基准)。
一开始的待排数组:
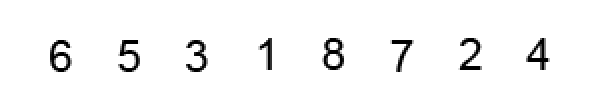
确定基准点元素 3 和左右两端指针的位置:
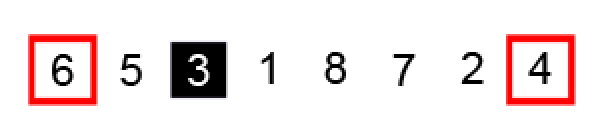
左边 i 指向的元素 6 已经大于基准点 3 保持不动,右边 j 向左移动找到小于基准点的元素 2:
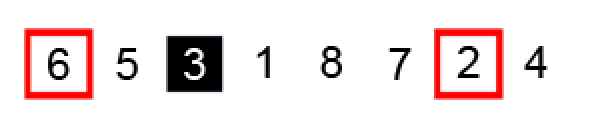
交换 i ,j 指针元素:
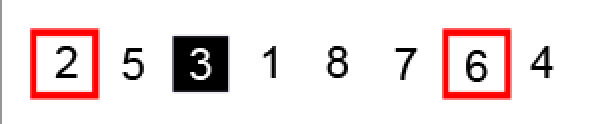
指针继续移动找到下一组逆序对:

交换 i ,j 指针元素:

两个指针继续相向移动,找到分区点:
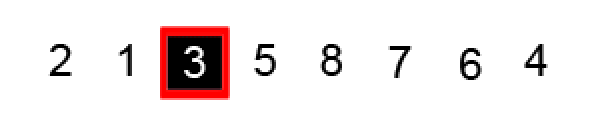
此时 i 指针指针的右边都是大于或等于基准的元素,j 指针的左边都是小于或等于基准的元素。j 是最后一个小于或等于(=)基准的元素的位置,这正是我们想要的分区点。而 i 是第一个大于或等于(=)基准的元素的位置,所以它不是一个合适的分区点。最终选择 j 处索引,确定改点为基准元素最终的位置:
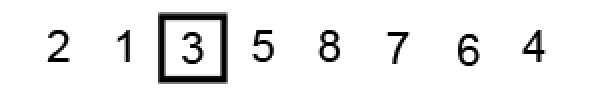
左子分区开始递归排序,确定基准点为 1 和左右两端指针的位置,此时位置刚好符合逆序对条件:
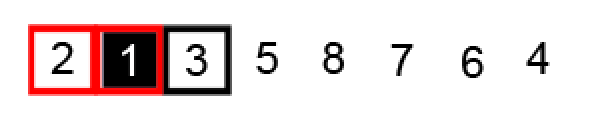
直接交换 i ,j 指针元素:
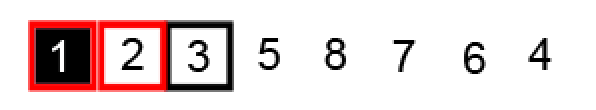
两个指针继续相向移动,找到分区点 1,确定为最终基准元素位置:
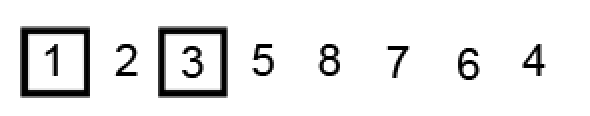
现在只有右子分区,元素个数为 1,不满足索引范围检查条件,不需要排序,直接确定基准元素 2 的位置:
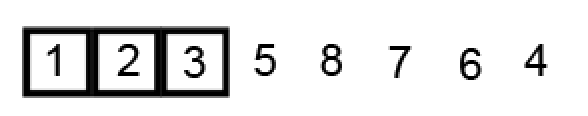
… 省略右子分区排序过程。
2.3 Hoare vs Lomuto
通过上面的了解,我们知道快速排序是一种经典的排序算法,其中一个关键步骤是如何分区数组。有两种流行的分区策略:Hoare 和 Lomuto。这两种策略有各自的优缺点,但从效率上讲,Hoare 的方案通常更胜一筹。
- 效率对比:
- Hoare 分区方案:平均情况下,Hoare 的分区策略只需要 Lomuto 方案的三分之一的交换次数,这使得它在实际应用中更为高效。
- Lomuto 方案:尽管它的实现可能更为直观和简单,但它在某些情况下,特别是当所有值都相等时,可能不会产生平衡的分区。
- 对于已排序的输入:
- 如果选择第一个或最后一个元素作为基准,无论是使用 Hoare 还是 Lomuto 的分区策略,快速排序的性能都会降低到 O(n^2)。
- 但是,如果选择中间元素作为基准,Hoare 的方案在已排序的数据上几乎不需要交换操作,并且可以产生大小近似相等的分区。这导致了快速排序的最佳情况性能,即 O(n log(n))。
- 稳定性:
- 无论是 Hoare 还是 Lomuto 的分区策略,快速排序都不是稳定的。这意味着相等的元素可能会改变它们的相对顺序。
- 基准的最终位置:
- 在 Hoare 的分区策略中,基准的最终位置并不一定是返回的索引。这是因为在分区步骤之后,基准和等于基准的元素可能会出现在分区的任何位置,并且可能在递归达到单个元素的基本情况时才会排序。
结论:尽管 Lomuto 的分区策略在某些教学场景中可能更易于理解,但 Hoare 的分区策略在实际应用中通常更为高效。
3.避免可能的不稳定性
上面也说过了,无论是 Hoare 还是 Lomuto 的分区策略,快速排序都不是稳定的。因为原始数据中相等的元素在排序后可能会改变它们的相对顺序。为了避免这个问题,我们可以在进行元素交换时判断被交换的两个元素是否相等,如果相等则放弃本次交换即可。
以 Lomuto 分区方案为例,优化后的代码如下:
/**
* 快速排序(Lomuto 分区方案)
*/
public class QuickSortLomuto {
/**
* 分区函数,确定基准点的最终位置(索引)
* @param arr 待分区数组
* @param low 当前分区下届
* @param high 当前分区上届
* @return 基准点的位置(索引)
*/
private static int partition(int[] arr,int low,int high){
// Lomuto 分区方案:选择最右边的元素作为基准点
int pivot = arr[high];
// 临时的基准索引 i:用于指向当前小于基准点的元素的位置(循环中,第一步是先自增,然后再使用,所以初值要减 1,从而使得第一次循环时 i 指向的是数组的第一个元素,也就是 j 指向的元素)
int i = low - 1;
// 小于基准点元素的索引 j:用于遍历数组,找出小于基准点的元素
for (int j = low; j < high; j++) {
// 在 j 指针向右移动的过程中,如果遇到小于基准点的元素
if(arr[j] <= pivot){
// 由于临时的基准索引 i 初始值为 low - 1,所以需要先自增,使其指向第一个元素(也就是 j 指向的元素)再进行交换
i++;
// 交换 i 指针(现在指向的是大于基准点的元素)和 j 指针(现在指向的是小于基准点的元素)指向的元素
// 交换后,i 指针指向的是小于基准点的元素,j 指针指向的是大于基准点的元素
if(arr[i] != arr[j]){
swap(arr,i,j);
}
}
}
// 将基准元素索引 i 移动到正确的位置(在较小和较大元素的中间)
i++;
// 交换 i 指针(现在指向的是大于基准点的元素)和 high 指针(现在指向的是基准点)指向的元素
if(arr[i] != arr[high]){
swap(arr,i,high);
}
// 返回基准点最终的位置(索引)
return i;
}
/**
* 交换数组中的两个元素
* @param arr 数组
* @param i 临时的基准索引
* @param j 遍历找到的小于基准点的元素的索引位置
*/
private static void swap(int[] arr,int i,int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
* 快速排序
* @param arr 待排序数组
* @param low 数组下届
* @param high 数组上届
*/
public static void quickSort(int[] arr,int low,int high){
// 递归终止条件(元素个数小于等于 1 个时,无需排序)
if(low >= high){
return;
}
// 分区,确定基准点的位置
int pivot = partition(arr,low,high);
// 递归调用,对左子数组进行快速排序
quickSort(arr,low,pivot - 1);
// 递归调用,对右子数组进行快速排序
quickSort(arr,pivot + 1,high);
}
public static void main(String[] args) {
int[] arr = {3,7,8,5,2,1,9,5,4};
quickSort(arr,0,arr.length - 1);
System.out.println(Arrays.toString(arr));
}
}
4.小礼物
在某些时候,不管是学习数据结构还是算法的相关知识,难免会觉得有些抽象,这时如果有一个工具能够让抽象的概念变得具体,那可就太棒了。下面推荐一个网站就可以满足你的需求:
地址:Data Structure Visualization
该网站中汇集了大部分常见的数据结构与算法的动图展示和单步调试,利用好可以帮助你更好的理解对应的知识点。
例如常见数据结构:

再比如我们上面所说的快速排序:
OK,本次分享到此,如果感觉对你有所帮助记得一键三连哦!!!
参考资料:
- https://en.wikipedia.org/wiki/Quicksort