linux系统编程-进程和线程相关、锁机制
1、进程的创建
使用fork()创建进程
系统调用 fork()允许一进程(父进程)创建一新进程(子进程)。需要注意的点有:
a、子进程拷贝父进程的栈、数据段、堆,与父进程共享文本段。
b、库函数 exit(status)终止一进程,将进程占用的所有资源(内存、文件描述符等)归还内核,父进程可使用系统调用 wait()来获取该状态。
c、系统调用 execve(pathname,argv,envp)加载一个新程序,这将丢弃现存的程序文本段,并为新程序重新创建栈、数据段以及堆。
d、调用 fork()之后,系统将率先“垂青”于哪个进程是无法确定的,可通过sleep休眠进程实现先后执行顺序。
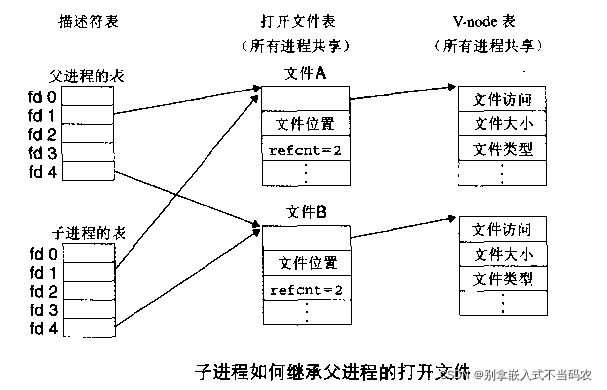
e、子进程对文件描述符的继承,之前有讲过,fork之后父子进程的文件描述符指向同一句柄,如下,也就是说,如果子进程更新了文件偏移量,那么这种改变也会影响到父进程中相应的描述符:
f、如果简单的将父进程虚拟内存页拷贝到新的子进程,那就太浪费了。原因有很多,其中之一是:fork()之后常常伴随着 exec(), 这会用新程序替换进程的代码段,并重新初始化其数据段、堆段和栈段,所以出现了写时复制这种技术来避免浪费。
2、进程的终止
exit和_exit的区别
同样都是终止状态为 0 表示进程“功成身退”,而非 0 值则表示进程因异常而退出。
exit()会执行的动作如下。
调用退出处理程序(通过 atexit()和 on_exit()注册的函数)
刷新 stdio 流缓冲区。
使用由 status 提供的值执行_exit()系统调用。
退出处理函数
有时应用程序需要在进程终止时自动执行一些操作,可使用**atexit()和on_exit()**来注册退出处理函数。
注意:1、通过 fork()创建的子进程会继承父进程注册的退出处理函数。而进程调用 exec()时,会移除所有已注册的退出处理程序。
2、当应用程序调用 exit()时,这些函数的执行顺序与注册顺序相反。
3、atexit和on_exit的区别是前者注册的func函数不带参数,后者可带arg参数。
3、监控子进程
wait()系统调用
系统调用 wait()等待调用进程的任一子进程终止,需注意:
1、如果调用进程并无之前未被等待的子进程终止,调用将一直阻塞,直至某个子进程终止。
2、如果 status 非空,那么关于子进程如何终止的信息则会通过 status 指向的整型变量返回。
3、将终止子进程的 ID 作为 wait()的结果返回
例如使用如下代码中的循环来等待调用进程的所有子进程退出:
while((childpid=wait(NULL)) != -1)
continue;
if(errno != ECHILD)
return -1;
waitpid()系统调用
与wait相比:
1、wait()将无法等待某个特定子进程的完成,只能按顺序等待下一个子进程的终止。
2、如果没有子进程退出,wait()总是保持阻塞。waitpid可指定参数执行非阻塞的等待。
3、使用 wait()只能发现那些已经终止的子进程。对于子进程因某个信号,或是已停止子进程收到 SIGCONT 信号后恢复执行的情况就无能为力了,waitpid可以。
pid_t waitpid(pid_t pid,int *status,int options);
pid:参数 pid 用来表示需要等待的具体子进程,如果 pid 等于-1,则等待任意子进程
options:位掩码,WUNTRACED返回因信号而停止的子进程信息,WCONTINUED返回那些因收到 SIGCONT 信号而恢复执行的已停止子进程的状态信息,WNOHANG如果参数 pid 所指定的子进程并未发生状态改变,则立即返回,而不会阻塞,在这种情况下,waitpid()返回 0。
4、僵尸进程、孤儿进程、守护进程
僵尸进程:如果父进程创建了某一子进程,但并未执行 wait(),那么在内核的进程表中将为该子进程永久保留一条记录。如果存在大量此类僵尸进程,它们势必将填满内核进程表,从而阻碍新进程的创建。
守护进程:守护进程是指在后台运行的,没有控制终端与之相连的进程。它独立于控制终端,周期性地执行某种任务
5、为 SIGCHLD 建立信号处理程序
使用场景:。父进程调用不带 WNOHANG 标志的 wait(),或 waitpid()方法,此时如果尚无已经终止的子进程,那么调用将会阻塞一方面,有时可能并不希望父进程以阻塞的方式来等待子进程的终止;另一方面,反复调用非阻塞的 waitpid()会造成 CPU 资源的浪费;所以为 SIGCHLD 建立信号处理程序提供一种方法,既可以非阻塞等待子进程终止,也不会浪费cpu资源。
无论一个子进程于何时终止,系统都会向其父进程发送 SIGCHLD 信号,所以可以安装信号处理程序来捕获它,在处理程序中,可以使用 wait()来收拾僵尸进程。当调用信号处理程序时,会暂时将引发调用的信号阻塞起来,且不会对SIGCHLD 之流的标准信号进行排队处理,,如果相继有两个子进程终止,即使产生了两次 SIGCHLD 信号,父进程也只能捕获到一个,所以通常采用下面的方式:处理程序内部循环以 WNOHANG 标志来调用 waitpid(),直至再无其他终止的子进程需要处理为止:
void sigfunc(){
while(waitpid(-1,NULL,WNOHANG)>0)
continue;
}
int main()
{
switch(fork()){
case -1:
return -1;
case 0:
....
exit(0);
default:
signal(SIGCHLD,sigfunc);
break;
return 0;
}
6、程序的执行execve()
系统调用 execve()可以将新程序加载到某一进程的内存空间,可用于加载二进制可执行文件和shell脚本:
int execve(const char *filename, char *const argv[], char *const envp[]);
参数 argv 则指定了传递给新进程的命令行参数。
参数 envp 指定了新程序的环境列表。
注意:
1、因为同一进程依然存在,所以进程 ID 仍保持不变。
2、无需检查 execve()的返回值,因为该值总是雷打不动地等于-1。通常,可以通过 errno 来判断出错原因。
7、使用system()执行shell命令
程序可通过调用 system()函数来执行任意的 shell 命令:
int system(const char *command);
system调用方便快捷但低效,因为使用 system()运行命令需要创建至少两个进程。一个用于运行 shell,另外一个或多个则用于 shell 所执行的命令。
8、进程记账
进程记账这一内核特性会使系统在每个进程结束后记录一条账单信息,这条账单记录包含了内核为该进程所维护的多种信息,包括终止状态以及进程消耗的CPU 时间。
特权进程可利用系统调用 acct()来打开和关闭进程记账功能:
int acct(const char *acctfile);
参数 acctfile 中指定一个现有常规文件的路径名。记账文件通常的路径名是/var/log/pacct 或/usr/account/pacct。一旦打开进程记账功能,每当一进程终止时,就会有一条 acct 记录写入记账文件。
9、系统调用clone()
系统调用 clone()也能创建一个新进程,但与 fork()不同的是,克隆生成的子进程继续运行时不以调用处为起点,转而去调用以参数 func 所指定的函数,func 又称为子函数。(这一点类似与线程的创建)。
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
注意两点:
1、当函数 func 返回或是调用 exit()(或_exit())之后,克隆产生的子进程就会终止。照例,父进程可以通过 wait()一类函数来等待克隆子进程。
2、因为克隆产生的子进程可能(类似 vfork())共享父进程的内存,所以它不能使用父进程的栈。相反,调用者必须分配一块大小适中的内存空间供子进程的栈使用,同时将这块内存的指针置于参数 child_stack 中
10、线程的特点
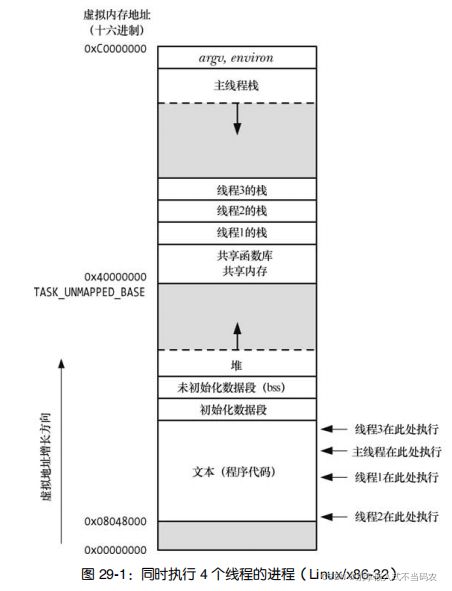
一个进程可以包含多个线程。同一程序中的所有线程均会独立执行相同程序,且共享同一份全局内存区域,其中包括初始化数据段、未初始化数据段,以及堆内存段。注意线程栈不是共享的,如下图:
面试高频考点:线程和进程的区别:
1、进程是一个程序的运行实例,例如我们通常的做法是fork调用创建一个新的进程以后,马上调用execve去运行一个新的程序;而线程都是独立的运行相同的程序。
2、子进程的创建是对父进程堆、栈和数据段的完全复制,而线程是共享一个进程的内存区域,所以我们常说一个进程可包含多个线程。
3、因为线程是共享一份内存区域的,所以线程间的数据共享很简单(全局变量)。相形之下,进程间的数据共享需要更多的投入。(例如,创建共享内存段或者使用管道pipe)。
4、因为线程是共享一份内存区域的,某个线程中的 bug可能会危及该进程的所有线程,因为它们共享着相同的地址空间和其他属性。相比之下,进程间的隔离更彻底。
5、创建线程要快于创建进程。线程间的上下文切换,其消耗时间一般也比进程要短。 -->高频考点:进程、线程切换都做了哪些操作?
面试高频考点:进程、线程切换都做了哪些操作?
进程上下文就是进程运行所依赖的环境,我们把已执行过的进程指令和数据在相关寄存器与堆栈中的内容称为进程上文,把正在执行的指令和数据在寄存器与堆栈中的内容称为进程正文,把待执行的指令和数据在寄存器与堆栈中的内容称为进程下文。
进程切换包括切换进程的虚拟地址空间和切换硬件上下文。
进程地址空间使用mm_struct结构体来描述,其中有一个成员pgd至关重要,pgd中保存的是进程的页全局目录的虚拟地址,fork的时候,如果是创建进程,需要分配设置mm_struct,其中会分配进程页全局目录所在的页,然后将首地址赋值给pgd,切换时内核会将进程的pgd虚拟地址转化为物理地址存放在的页表基址寄存器里,当访问用户空间地址的时候mmu会通过这个寄存器来做遍历页表获得物理地址,完成了这一步,也就完成了进程的地址空间切换。
进程执行的内核栈还是前一个进程的,当前执行流也还是前一个进程的,需要做切换。处理器状态切换就是将前一个进程的sp,pc等寄存器的值保存到一块内存上,然后将即将执行的进程的sp,pc等寄存器的值从另一块内存中恢复到相应寄存器中,恢复sp完成了进程内核栈的切换,恢复pc完成了指令执行流的切换。
11、线程相关API
创建线程
函数 pthread_create()负责创建一条新线程:
#include 终止线程的方法
1、线程 start 函数执行 return 语句并返回指定值。
2、线程调用 pthread_exit()(详见后述)。
3、调用 pthread_cancel()取消线程(在 32.1 节讨论)。
4、任意线程调用了 exit(),或者主线程执行了 return 语句(在 main()函数中),都会导致进程中的所有线程立即终止。
pthread_exit()函数将终止调用线程,且其返回值可由另一线程通过调用 pthread_join()来获取:
void pthread_exit(void *retval);
参数retval 指定了线程的返回值。
获取自身线程ID、判断线程ID是否相等
一个线程可以通过 pthread_self()来获取自己的线程 ID:
void pthread_self(void);
函数 pthread_equal()可检查两个线程的 ID 是否相同:
int pthread_equal(pthread_t t1,pthread_t t2);
注意不能使用==进行判断,必须将 pthread_t 作为一种不透明的数据类型加以对待,所以函数 pthread_equal()是必须的。
连接已终止的线程
函数 pthread_join()等待由 thread 标识的线程终止,这种操作被称为连接,类似与进程的wait()和waitpid()。:
int pthread_join(pthread_t thread,void **retval);
pthread_join()执行的功能类似于针对进程的 waitpid()调用,不过二者之间存在一些显著差别:
1、线程之间的关系是对等的。进程中的任意线程均可以调用 pthread_join()与该进程的任何其他线程连接起来。
2、无法“连接任意线程”(对于进程,则可以通过调用 waitpid(-1, &status, options)做到这一点),也不能以非阻塞(nonblocking)方式进行连接。
线程分离
有时,程序员并不关心线程的返回状态,只是希望系统在线程终止时能够自动清理并移除之,可以调用 pthread_detach(),将该线程标记为处于分离状态。
int pthread_detach(pthread_t thread);
使用 pthread_detach(),线程可以自行分离:
pthread_detach(pthread_self());
其他线程调用了 exit(),或是主线程执行 return 语句时,即便遭到分离的线程也还是会受到影响,会马上终止。也就是说,pthread_detach()只是控制线程终止之后所发生的事情,而非何时或如何终止线程。
12、线程、进程、内核的同步方法
a、互斥量和互斥体
用于线程的互斥量
互斥量使用特定的数据类型:pthread_mutex_t,使用互斥量前要先初始化,使用的函数如下:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
简单的使用可以使用默认的属性初始化互斥量,函数的后一个参数设置为NULL即可。
对互斥量加锁解锁的函数如下:
#include 函数pthread_mutex_trylock会尝试对互斥量加锁,如果该互斥量已经被锁住,函数调用失败,返回EBUSY,否则加锁成功返回0,线程不会被阻塞。
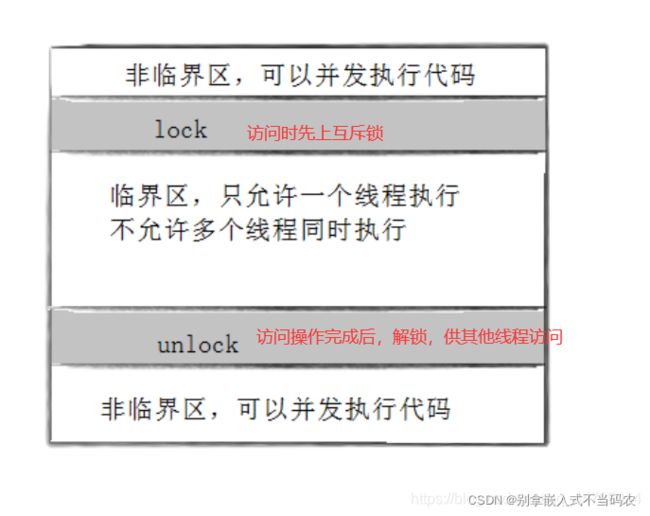
注意加锁是对临界区的保护,抑或对数据结构的保护,加锁时应该遵循下图:
一个使用互斥量的例子:
#include 内核中使用的互斥体
内核中存在与线程互斥量基本相同的东西叫互斥体,他的特点是:
1、 mutex 可以导致休眠,因此不能在中断中使用 mutex,中断中只能使用自旋锁。
2、和信号量一样, mutex 保护的临界区可以调用引起阻塞的 API 函数。
3、因为一次只有一个线程可以持有 mutex,因此,必须由 mutex 的持有者释放 mutex。并且 mutex 不能递归上锁和解锁。
相关API:
DEFINE_MUTEX(name) //定义并初始化一个 mutex 变量。
void mutex_init(mutex *lock) //初始化 mutex。
void mutex_lock(struct mutex *lock) //获取 mutex,也就是给 mutex 上锁。如果获取不到就进休眠。
void mutex_unlock(struct mutex *lock) //释放 mutex,也就给 mutex 解锁。
int mutex_trylock(struct mutex *lock) //尝试获取 mutex,如果成功就返回 1,如果失败就返回 0。
int mutex_is_locked(struct mutex *lock) //判断 mutex 是否被获取,如果是的话就返回1,否则返回 0。
b、条件变量
互斥量防止多个线程同时访问同一共享变量。而条件变量允许一个线程就某个共享变量的状态变化通知其他线程,并让其他线程等待(阻塞于)这一通知,(这有点类似于进程中的信号机制)。
在生产者消费者模型中,消费者线程要知道现有的资源是否可用,就需要不断的查询,如下面的代码:
pthread_mutex_t counter_mutex = PTHREAD_MUTEX_INITIALIZER;
int avail=0; //全局变量,表示可用资源
void produce(){
pthread_mutex_lock(&counter_mutex);
avail++;
pthread_mutex_unlock(&counter_mutex);
}
void comsume(){
pthread_mutex_lock(&counter_mutex);
while(avail>0){ //消费线程需要不断的查询
avail--;
}
pthread_mutex_unlock(&counter_mutex);
}
int main(int argc, char **argv) {
//创建两个线程,一个生产者,一个消费者
pthread_t tidA, tidB;
pthread_create(&tidA, NULL, produce, NULL); //生产者线程
pthread_create(&tidB, NULL, comsume, NULL); //消费者线程
//等待两个线程结束
pthread_join(tidA, NULL);
pthread_join(tidB, NULL);
return 0;
}
上述代码虽然可行,但由于主线程不停地循环检查变量 avail 的状态,故而造成 CPU 资源的浪费。采用了条件变量,这一问题就迎刃而解:允许一个线程休眠(等待)直至接获另一线程的通知(收到信号)去执行某些操作。
条件变量总是结合互斥量使用。条件变量就共享变量的状态改变发出通知,而互斥量则提供对该共享变量访问的互斥。
相关API:
初始化条件变量:
pthread_cond_t cond = PTHREAD_COND_INITIALIZER; //静态初始化
int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr); //动态初始化
int pthread_cond_destroy(pthread_cond_t *cond); //销毁
生产者线程使用pthread_cond_signal()唤醒消费者线程,表示此时有资源可以使用;消费者线程使用pthread_cond_wait()等待条件变量,当资源不可用时就阻塞:
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_wait(pthread_cond_t *cond,pthread_mutex_t *mutex);
修改前面的代码,将条件变量和互斥量运用到生产者-消费者模型中:
pthread_mutex_t mutex_lock = PTHREAD_MUTEX_INITIALIZER; //互斥量
pthread_cond_t cond = PTHREAD_COND_INITIALIZER; //条件变量
int avail=0; //全局变量,表示可用资源
void produce(){
pthread_mutex_lock(&counter_mutex);
avail++;
pthread_mutex_unlock(&counter_mutex);
pthread_cond_signal(&cond); //条件变量唤醒消费者线程
}
void comsume(){
pthread_mutex_lock(&counter_mutex);
while(avail==0){ //资源为0不可用,阻塞
pthread_cond_wait(&cond,&mutex_lock);
}
while(avail>0){ //资源可用,消耗资源,一旦资源减少到0,又阻塞等待生产者线程唤醒
avail--;
}
pthread_mutex_unlock(&counter_mutex);
}
int main(int argc, char **argv) {
//创建两个线程,一个生产者,一个消费者
pthread_t tidA, tidB;
pthread_create(&tidA, NULL, produce, NULL); //生产者线程
pthread_create(&tidB, NULL, comsume, NULL); //消费者线程
//等待两个线程结束
pthread_join(tidA, NULL);
pthread_join(tidB, NULL);
return 0;
}
c、读写锁
读写锁与互斥量的功能类似,对临界区的共享资源进行保护,互斥量一次只让一个线程进入临界区,读写锁比它有更高的并行性。读写锁有以下特点:
1.如果一个线程用读锁锁定了临界区,那么其他线程也可以用读锁来进入临界区,这样就可以多个线程并行操作。
2.如果一个线程用写锁锁住了临界区,那么其他线程不管是读锁还是写锁都会发生阻塞。
一个读写锁为pthread_rwlock_t类型,动静态初始化读写锁:
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER; //静态
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr); //动态
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock); //销毁读写锁
读写锁加锁与解锁:
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); //加读锁
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock); //加写锁
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock); //解
非阻塞加锁:
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); //非阻塞加读锁
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock); //非阻塞加写锁
try类函数加锁:如果获取不到锁,会立即返回错误EBUSY,不会阻塞。
例子:四个线程同时读写全局变量index,一二线程写全局变量,加写锁,三四线程读全局变量,加读锁:
#include d、自旋锁
分为线程自旋锁和内核自旋锁、主要介绍一下内核自旋锁。(在内核中断上半部里自旋锁用得比较多)
适用于SMP系统,在单核系统上,自旋锁不会真正的自旋,例如在一个双核的机器上有两个线程(线程A和线程B),它们分别运行在Core0和Core1上,线程A先获取到自旋锁,执行临界区代码,此时线程B想要获取自旋锁,就会在在 Core1上进行忙等待并不停的进行锁请求,直到得到这个锁为止。试想如果在单核系统上,一个进程A首先获得了自旋锁,这个时候发生了调度轮到进程B运行,进程B想要获取自旋锁,就要占用cpu不断的忙等待,而进程B获取到自旋锁的条件是进程A释放自旋锁,cpu被占用进程A将永远不会被调度到,也不会释放锁,那岂不是发生了死锁?所以在单核系统上,linux做了改进,不会真正的自旋。
DEFINE_SPINLOCK(spinlock_t lock) //定义并初始化一个自选变量。
int spin_lock_init(spinlock_t *lock) //初始化自旋锁。
void spin_lock(spinlock_t *lock) //获取指定的自旋锁,也叫做加锁。
void spin_unlock(spinlock_t *lock) //释放指定的自旋锁。
int spin_trylock(spinlock_t *lock) //尝试获取指定的自旋锁,如果没有获取到就返回 0
int spin_is_locked(spinlock_t *lock) //检查指定的自旋锁是否被获取,如果没有被获取就返回非 0,否则返回 0。
1、被自旋锁保护的临界区一定不能调用任何能够引起睡眠和阻塞的API 函数,否则的话会可能会导致死锁现象的发生。
2、Linux内核中,自旋锁是不可递归的。如果试图递归获取一个已经获取的锁,那么获取到的条件肯定是这个锁已经被释放,但这个时候你又在不断的自旋,不可能释放锁,所以发生了死锁。
3、在内核代码中,获取自旋锁之前一定要先禁止本地中断(当前处理器的中断),否则,中断程序就会打断正持有锁的内核代码,有可能会试图去争用这个已经被持有的自旋锁。这样就会造成双重请求死锁(中断处理程序会自旋,等待该锁重新可用,但锁的持有者在这个处理程序执行完之前是不可能运行的)。
在内核代码中使用自旋锁禁止本地中断:
void spin_lock_irq(spinlock_t *lock) //禁止本地中断,并获取自旋锁。
void spin_unlock_irq(spinlock_t *lock) //激活本地中断,并释放自旋锁。
void spin_lock_irqsave(spinlock_t *lock,unsigned long flags) //保存中断状态,禁止本地中断,并获取自旋锁。
void spin_unlock_irqrestore(spinlock_t*lock, unsigned long flags) //将中断状态恢复到以前的状态,并且激活本地中断,释放自旋锁。
通常spin_lock_irqsave和spin_unlock_irqrestore在庞大的内核代码上运用较多。
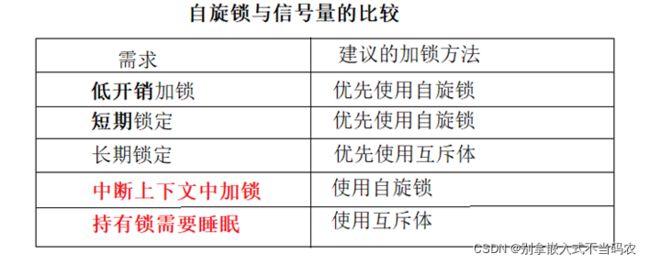
内核自旋锁的使用场景:低开销短期加锁,或在中断里加锁考虑使用自旋锁。
e、信号量
信号量同样分为用户态和内核态使用的信号量,在用户态使用的信号量又有POSIX标准和SYSTEM V标准的信号量,两种标准的信号量有一些区别,这里不展开详细说明,POSIX信号量通常运行性能更优,所以详细说明一下POSIX标准信号量。
有名信号量和无名信号量
在 POSIX 标准中,信号量分两种,一种是无名信号量,一种是有名信号量。无名信号量一般用于线程间同步或互斥,而有名信号量一般用于进程间同步或互斥。它们的区别和管道及命名管道的区别类似,无名信号量则直接保存在进程内存中,而有名信号量要求创建一个文件。虽然常规如此,但实际上无名信号量也可用于进程间同步,例如在共享内存区中使用无名信号量。这同样也适用于互斥量和条件变量,虽然通常用作线程同步,也可以和共享内存区同用,用作进程间同步。
二值信号量和计数信号量
二值信号量:信号量的值只有0和1,这和互斥量很类似,若资源被锁住,信号量的值为0,若资源可用,则信号量的值为1;与互斥量的区别是,互斥量只能由申请加锁的线程释放锁,而信号量的PV操作不必是同时一个线程。
计数信号量:信号量的值在0到一个大于1的限制值(POSIX指出系统的最大限制值至少要为32767)。该计数表示可用的资源的个数。
信号量的PV操作
等待一个信号量(P操作)。该操作会检查信号量的值,如果其值小于或等于0,那就阻塞,直到该值变成大于0,然后等待进程将信号量的值减1,进程获得共享资源的访问权限。这整个操作必须是一个原子操作。
挂出一个信号量(V操作)。该操作将信号量的值加1,如果有进程阻塞着等待该信号量,那么其中一个进程将被唤醒。该操作也必须是一个原子操作。
相关API
sem_t *sem_open(const char *name, int oflag,mode_t mode, unsigned int value); //打开有名信号量
sem_open用于创建或打开一个信号量,信号量是通过name参数即信号量的名字来进行标识的。
oflag参数可以为:0,O_CREAT,O_EXCL。如果为0表示打开一个已存在的信号量,如果为O_CREAT,表示如果信号量不存在就创建一个信号量,如果存在则打开被返回。此时mode和value需要指定。如果为O_CREAT | O_EXCL,表示如果信号量已存在会返回错误。
mode参数用于创建信号量时,表示信号量的权限位,和open函数一样包括:S_IRUSR,S_IWUSR,S_IRGRP,S_IWGRP,S_IROTH,S_IWOTH。
value表示创建信号量时,信号量的初始值。
int sem_close(sem_t *sem); //关闭信号量
int sem_unlink(const char *name); //删除信号量
int sem_init(sem_t *sem, int pshared, unsigned int value); //初始化无名信号量
int sem_destroy(sem_t *sem); //销毁信号量
sem_init()第一个参数是指向一个已经分配的sem_t变量。第二个参数pshared表示该信号量是否由于进程间通步,当pshared = 0,那么表示该信号量只能用于进程内部的线程间的同步。当pshared != 0,表示该信号量存放在共享内存区中,使使用它的进程能够访问该共享内存区进行进程同步。第三个参数value表示信号量的初始值。
int sem_wait (sem_t *sem); //P操作、用于获取信号量,首先会测试指定信号量的值,如果大于 0 ,就会将它减 1 并立即返回,如果等于 0 ,那么调用线程会进入睡眠,直到指定信号量的值大于 0。
int sem_trywait (sem_t * sem); //和sem_wait的差别是,当信号量的值等于0的,调用线程不会阻塞,直接返回,并标识EAGAIN错误。
int sem_post(sem_t *sem); //V操作,使该信号量的值加1,如果有等待的线程,那么会唤醒等待的一个线程。
int sem_getvalue(sem_t *sem, int *sval);
返回当前信号量的值,通过sval输出参数返回,如果当前信号量已经上锁(即同步对象不可用),那么返回值为0,或为负数,其绝对值就是等待该信号量解锁的线程数。
信号量的持续性
有名信号量是随内核持续的。当有名信号量创建后,即使当前没有进程打开某个信号量它的值依然保持。直到内核重新自举或调用sem_unlink()删除该信号量。
无名信号量的持续性要根据信号量在内存中的位置:
如果无名信号量是在单个进程内部的数据空间中,即信号量只能在进程内部的各个线程间共享,那么信号量是随进程的持续性,当进程终止时它也就消失了。
如果无名信号量位于不同进程的共享内存区,因此只要该共享内存区仍然存在,该信号量就会一直存在。所以此时无名信号量是随内核的持续性。
信号量的继承
对于有名信号量在父进程中打开的任何有名信号量在子进程中仍是打开的,且是同一个信号量。
如果无名信号量是在单个进程内部的数据空间中,那么信号量就是进程数据段或者是堆栈上,当fork产生子进程后,该信号量只是原来的一个拷贝,和之前的信号量是独立的。
如果无名信号量位于不同进程的共享内存区,那么fork产生的子进程中的信号量仍然会存在该共享内存区,所以该信号量仍然保持着之前的状态。
信号量与互斥量结合使用,消费者与生产者的例子程序:
使用信号量和互斥量实现多个生产者和消费者模型。要在多个生产者和消费者模型必须和mutex互斥锁搭配使用才行,sem信号量只是控制并发数的,不能对临界区进行保护。在下面这个例子中,创建了3个线程,A线程为生产者线程,B、C为消费者线程,初始可消耗资源为5,可以从打印结果看到,conter资源计数永远不会小于0。
#include 输出结果:
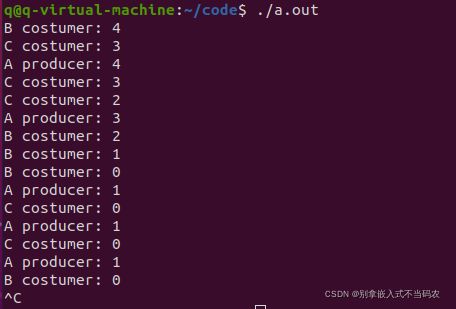
程序代码里为什么要定义两个信号量生产者和消费者信号量?生产者信号量表示不能无限制的生产。
13、线程取消
前面说到过任意线程调用了 exit(),或者主线程执行了 return 语句(在 main()函数中),都会导致进程中的所有线程立即终止。那么如何在主线程或某一线程中,只取消掉我想要终止的那个进程呢?可以用到pthread_cancel调用
int pthread_cancel(pthread_t thread);
14、死锁问题
15、进程的优先级和调度策略
a、进程的优先级
进程的优先级,也就是nice值,nice值从-20~19,-20为最高优先级,19为最低优先级。nice 值是一个权重因素,它导致内核调度器倾向于调度拥有高优先级的进程。给一个进程赋一个低优先级(即高 nice 值)并不会导致它完全无法用到 CPU,但会导致它使用 CPU 的时间变少。(联系到之前学习过的内核CFS调度算法,也就是进程的运行时间和权重影响着进程在红黑树中的位置,运行时间越短,权重越高的进程在红黑树中的位置越靠左,在内核每发起一次调度的时候,越倾向于调度到该进程)。
getpriority()和 setpriority()系统调用允许一个进程获取和修改自身或其他进程的 nice 值。
int getpriority(int which,id_t who); //获取nice值
int setpriority(int which,id_t who,int prio); //设置进程的nice值
which参数可为:
PRIO_PROCESS :操作进程 ID 为 who 的进程。
PRIO_PGRP :操作进程组 ID 为 who 的进程组中的所有成员。
PRIO_USER :操作所有真实用户 ID 为 who 的进程。
b、进程调度策略
分为非实时调度策略SCHED_OTHER和实时调度策略:SCHED_RR 和 SCHED_FIFO。SCHED_OTHER是linux对进程常用的调度策略,SCHED_RR和SCHED_FIFO是一种软实时调度策略(linux上其实不能真正做到实时,需要操作系统的支持),这两种策略中任意一种策略进行调度的进程的优先级要高于SCHED_OTHER来调度的进程,实时进程的优先级其数值从 1(最低)~99(最高)。
SCHED_OTHER、SCHED_RR 、SCHED_FIFO的区别
在 SCHED_RR策略中,优先级相同的进程以循环时间分享的方式执行。进程每次使用 CPU 的时间为一个固定长度的时间片。一旦被调度执行之后,使用 SCHED_RR 策略的进程会保持对 CPU 的控制直到下列条件中的一个得到满足:
1、达到时间片的终点了。
2、自愿放弃 CPU,这可能是由于执行了一个阻塞式系统调用或调用了 sched_yield()。
3、终止了。
4、被一个优先级更高的进程抢占了。
当运行在 SCHED_RR 策略下的进程丢掉 CPU 之后将会被放置在与其优先级级别对应的队列的队尾。而被抢占的进程仍然位于与其优先级级别对应的队列的队头。
SCHED_RR 和SCHED_OTHER之间最重要的差别在于 SCHED_RR 策略存在严格的优先级级别,高优先级的进程总是优先于优先级较低的进程。也就是说只要存在高优先级的进程,低优先级的进程永远不会被调用到。而在 SCHED_OTHER 策略中,高优先级的进程不会独占 CPU,它仅仅在调度决策时为进程提供了一个较大的权重,所以低优先级的进程也有机会使用到CPU,哪一个进程能够被调用到是无法准确控制的,而SCHED_RR 策略允许精确控制进程被调用的顺序。
SCHED_FIFO 策略中不存在时间片。一旦一个 SCHED_FIFO 进程获得了CPU 的控制权之后,它就会一直执行直到下面某个条件被满足:
1、自动放弃 CPU(采用的方式与前面描述的 SCHED_FIFO 策略中的方式一样)。
2、终止了。
3、被一个优先级更高的进程抢占了。
在第一种情况中,进程会被放置在与其优先级级别对应的队列的队尾。在最后一种情况中,当高优先级进程执行结束之后(被阻塞或终止了),被抢占的进程会继续执行(即被抢占的进程位于与其优先级级别对应的队列的队头)。
c、修改调度策略
sched_setscheduler()系统调用修改进程 ID 为 pid 的进程的调度策略和优先级。
int sched_setscheduler(pid_t pid, int policy,const struct sched_param *param);
sched_param结构体用于额外的调度策略,这里暂时忽略不谈,policy参数取值可为:
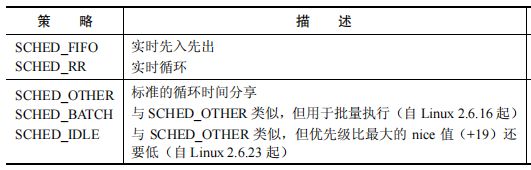
成功调用 sched_setparam()会将 pid 指定的进程移到与其优先级级别对应的队列的队尾,并且通过 fork()创建的子进程会继承父进程的调度策略和优先级,并且在 exec()调用中会保持这些信息。
d、如何防止实时进程锁住系统
1、使用 alarm()设置一个警报定时器。如果进程的运行时间超出了由 alarm()调用指定的秒数,那么该进程会被 SIGALRM 信号杀死。
2、创建一个拥有高实时优先级的看门狗进程,看门狗进程间隔一段时间喂狗。如果某一实时进程长时间占用CPU导致看门狗进程无法喂狗,则触发看门狗复位。
16、进程资源限制
获取系统资源信息
getrusage用于 获得进程的相关资源信息。如:用户开销时间,系统开销时间,接收的信号量等等;
int getrusage(int who, struct rusage *usage);
//当调用成功后,返回0,否则-1;
who:可能选择有
RUSAGE_SELF:获取当前进程的资源使用信息。以当前进程的相关信息来填充rusage(数据)结构
RUSAGE_CHILDREN:获取子进程的资源使用信息。rusage结构中的数据都将是当前进程的子进程的信息
usage:指向存放资源使用信息的结构指针。
struct rusage {
struct timeval ru_utime; // user time used
struct timeval ru_stime; // system time used
long ru_maxrss; // maximum resident set size
long ru_ixrss; // integral shared memory size
long ru_idrss; // integral unshared data size
long ru_isrss; // integral unshared stack size
long ru_minflt; // page reclaims
long ru_majflt; // page faults
long ru_nswap;// swaps
long ru_inblock; // block input operations
long ru_oublock; // block output operations
long ru_msgsnd; // messages sent
long ru_msgrcv; //messages received
long ru_nsignals; // signals received
long ru_nvcsw; // voluntary context switches
long ru_nivcsw; // involuntary context switches
};
读取和修改资源限制
获取或设置资源使用限制,linux下每种资源都有相关的软硬限制,软限制是内核强加给相应资源的限制值,硬限制是软限制的最大值,RLIM_INFINITY:表示不对资源限制。
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
struct rlimit结构体(描述软硬限制),原型如下:
struct rlimit {
rlim_t rlim_cur;
rlim_t rlim_max;
};
resource参数说明:
RLIMIT_AS //进程的最大虚内存空间,字节为单位。
RLIMIT_CORE //内核转存文件的最大长度。
RLIMIT_CPU //最大允许的CPU使用时间,秒为单位。当进程达到软限制,内核将给其发送SIGXCPU信号,这一信号的默认行为是终止进程的执行。然而,可以捕捉信号,处理句柄可将控制返回给主程序。如果进程继续耗费CPU时间,核心会以每秒一次的频率给其发送SIGXCPU信号,直到达到硬限制,那时将给进程发送 SIGKILL信号终止其执行。
RLIMIT_DATA //进程数据段的最大值。
RLIMIT_FSIZE //进程可建立的文件的最大长度。如果进程试图超出这一限制时,核心会给其发送SIGXFSZ信号,默认情况下将终止进程的执行。
RLIMIT_LOCKS //进程可建立的锁和租赁的最大值。
RLIMIT_MEMLOCK //进程可锁定在内存中的最大数据量,字节为单位。
RLIMIT_MSGQUEUE //进程可为POSIX消息队列分配的最大字节数。
RLIMIT_NICE //进程可通过setpriority() 或 nice()调用设置的最大nice值。
RLIMIT_NOFILE //指定比进程可打开的最大文件描述词大一的值,超出此值,将会产生EMFILE错误。
RLIMIT_NPROC //用户可拥有的最大进程数。
RLIMIT_RTPRIO //进程可通过sched_setscheduler 和 sched_setparam设置的最大实时优先级。
RLIMIT_SIGPENDING //用户可拥有的最大挂起信号数。
RLIMIT_STACK //最大的进程堆栈,以字节为单位。