计算内存方法
首先我们要知道计算内存大小的三种方式:
sizeof-
class_getInstanceSize; -
malloc_size。
接下来我们定义一个LGPerson类,分析这三种方法。代码如下:
LGPerson * p = [LGPerson alloc];
LGPerson * q;
NSLog(@"对象类型占用内存大小=%lu",sizeof(p));
NSLog(@"对象类型占用内存大小=%lu",sizeof(q));
NSLog(@"对象实际内存大小====%lu",class_getInstanceSize([p class]));
NSLog(@"对象实际内存大小====%lu",class_getInstanceSize([q class]));
NSLog(@"对象实际分配内存大小=%lu",malloc_size((__bridge const void *)(p)));
NSLog(@"对象实际分配内存大小=%lu",malloc_size((__bridge const void *)(q)));
打印结果:
2020-09-29 14:02:17.810194+0800 KCObjc[20870:761876] 对象类型占用内存大小=8
2020-09-29 14:02:17.810897+0800 KCObjc[20870:761876] 对象类型占用内存大小=8
2020-09-29 14:02:17.811068+0800 KCObjc[20870:761876] 对象实际内存大小====8
2020-09-29 14:02:17.811165+0800 KCObjc[20870:761876] 对象实际内存大小====0
2020-09-29 14:02:17.811265+0800 KCObjc[20870:761876] 对象实际分配内存大小=16
2020-09-29 14:02:17.811352+0800 KCObjc[20870:761876] 对象实际分配内存大小=0
由打印结果可以分析出
-
sizeof()传入是类型,可以放基本数据类型、对象、指针。可用来计算类型占用内存大小,这个在编译器编译阶段就会确定,所以sizeof(p)和sizeof(q)的结果都是一样的,p和q都是指针类型,指针大小为8个字节。 -
class_getInstanceSize计算对象的实际内存大小,大小由类的属性和变量来决定,实际上并不是严格意义上的对象内存大小。由下面代码可知,底层进行8字节对齐。
# define WORD_MASK 7UL
static inline uint32_t word_align(uint32_t x) {
return (x + WORD_MASK) & ~WORD_MASK;
}
LGPerson类中没有其他的属性和变量,但是继承了NSObject,NSObject中有一个isa指针,所以内存大小是8字节。
-
malloc_size系统分配的内存大小,是按16字节对齐的方式,即是按16的倍数分配 ,不足则系统会自动填充字节。
内存对齐原则
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。在iOS中,Xcode默认为#pragma pack(8),即`8字节对齐。
内存对齐原则主要有以下三点:
-
数据成员对齐规则:struct(结构)或者union(联合)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如数据、结构体等)的整数倍开始(例如int在32位机中是4字节,则要从4的整数倍地址开始存储) -
数据成员为结构体:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储(例如:struct a里面存有struct b,b里面有char(1字节)、int(4字节)、double(8字节)等元素,则b应该从8的整数倍开始存储) -
结构体的整体对齐规则:结构体的总大小,即sizeof的结果,必须是其内部做大成员的整数倍,不足的要补齐
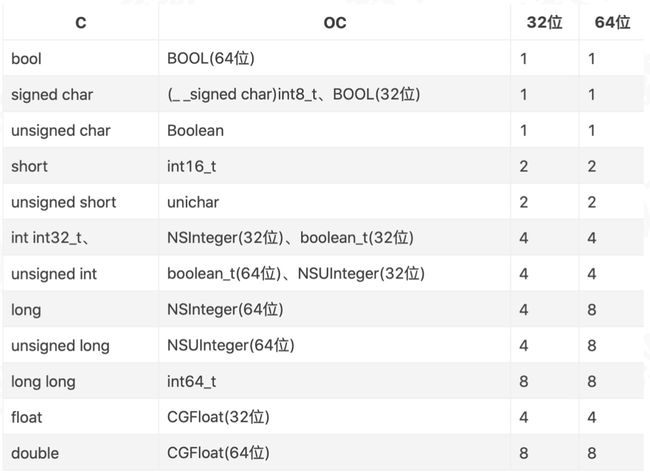
下表是各种数据类型在iOS中的占用内存大小,根据对应类型来计算结构体中内存大小
结构体对齐
如下代码,我们用实例进行探究结构体对齐:
struct LGStruct1{
long a; // 8
int b; // 4
short c; // 2
char d; // 1
} LGStruct1;
struct LGStruct2{
long a; // 8
char d; // 1
int b; // 4
short c; // 2
} LGStruct2;
int main(int argc, const char * argv[]) {
@autoreleasepool {
NSLog(@"---%lu------%lu",sizeof(LGStruct1),sizeof(LGStruct2));
}
return 0;
}
打印结果
2020-09-29 15:52:17.811352+0800 KCObjc[20870:761876] -----16------24
由上述代码可看出两个结构体定义的变量和变量类型都一致,唯一的区别只是在于定义变量的顺序不一致,那么为什么会占用的内存大小不相等呢?其实这就是iOS中的内存对齐原则。下面我们就根据内存对齐原则来进行简单的分析和计算LGStruct1内存大小的详细过程:
- 变量
a: 占8个字节,从0开始,min(0,8),即0 ~ 7存储a - 变量
b: 占4个字节,从8开始,min(8,4),即8 ~ 11存储b - 变量
c: 占2个字节,从12开始,min(12,2),即12~ 13存储c - 变量
d: 占1个字节,从14开始,min(14,1),即14存储d
因此LGStruct1的内存大小是15字节,而LGStruct1中最大的变量是a占8个字节,所以LGStruct1需要实际内存必须是8的倍数(内存对齐原则),15字节不是8的倍数,15向上取整到16 ,所以系统自动填充成16字节,最终sizeof(LGStruct1)的大小是16.
LGStruct2内存大小的详细过程
- 变量
a: 占8个字节,从0开始,min(0,8),即0 ~ 7存储a - 变量
d: 占1个字节,从8开始,min(8,1),即8存储d - 变量
b: 占4个字节,从9开始,min(9,4),9 % 4 != 0,继续往后移动直到找到可以整除4的位置12,min(12,4),即12 ~ 15存储b - 变量
c: 占2个字节,从16开始,min(16,2),即16 ~ 17存储c
因此LGStruct2的需要的内存大小为18字节,而LGStruct2中最大变量long的字节数为8,所以LGStruct2实际的内存大小必须是8的整数倍,18向上取整到24,主要是因为24是8的整数倍,所以 sizeof(LGStruct2) 的结果是24
LGStruct2内存中的存储情况图
结构体嵌套结构体
上面的2个示例只是简单的定义数据成员,如果我们在结构体中嵌套结构体结果又会是怎样的?我们继续探究,看下面代码:
struct LGStruct3{
long a; // 8
int b; // 4
short c; // 2
char d; // 1
struct LGStruct1 Str;
}LGStruct3;
int main(int argc, const char * argv[]) {
@autoreleasepool {
NSLog(@"LGStruct1----%lu",sizeof(LGStruct1));
NSLog(@"LGStruct2----%lu",sizeof(LGStruct2));
NSLog(@"LGStruct3----%lu",sizeof(LGStruct3));
}
return 0;
}
//结果
2020-09-30 11:02:46.509957+0800 001-内存对齐原则[22800:939799] LGStruct1----16
2020-09-30 11:02:46.511196+0800 001-内存对齐原则[22800:939799] LGStruct2----24
2020-09-30 11:02:46.512537+0800 001-内存对齐原则[22800:939799] LGStruct3----32
LGStruct3内存大小存储情况的详细过程
- 变量
a: 占8个字节,从0开始,min(0,8),即0 ~ 7存储a - 变量
b: 占4个字节,从8开始,min(8,4),即8 ~ 11存储b - 变量
c: 占2个字节,从12开始,min(12,2),即12~ 13存储b - 变量
d: 占1个字节,从14开始,min(14,1),即14存储d - 变量
Str: 结构体变量Str,根据内存对齐原则结构体成员要从其内部最大元素大小的整数倍地址开始存储,LGStruct1中最大的变量是long 8字节,所以Str从16位置开始存储,而Str的为15字节,即LGStruct1存储16-31位置
因此LGStruct3的内存大小是32字节,而LGStruct1中最大变量为Str,其最大成员内存字节数为8,所以LGStruct3内存必须是8的倍数,32是8的倍数,最终sizeof(LGStruct3)的大小是32
其内存存储情况如下图所示
内存优化(属性重排)
从上述的示例中,我们可以得出一个结论即结构体的内存大小与结构体成员内存大小的顺序有关
- 若
结构体数据成员是由内存从小到大的顺序定义的,根据内存对齐原则来计算内存大小,需要增加较多的内存占位符,这样做浪费内存。 - 若
结构体数据成员是由内存从大到小的顺序定义的,根据内存对齐规则来计算结构体内存大小,我们只需要补齐少量内存占位符即可满足内存对齐规则。
第二种方式就是苹果采用的将类中的属性进行重排,来达到优化内存的目的。以下面这个示例来进行说明苹果中属性重排,即内存优化:
- 自定义
LGPerson类,并定义几个属性
//LGPerson.h
@interface LGPerson : NSObject
@property (nonatomic, copy) NSString *name;
@property (nonatomic, copy) NSString *nickName;
// @property (nonatomic, copy) NSString *hobby;
@property (nonatomic, assign) int age;
@property (nonatomic, assign) long height;
@property (nonatomic) char c1;
@property (nonatomic) char c2;
@end
//LGPerson.m
@implementation LGPerson
@end
- 在
main中创建LGPerson的实例对象,并对其属性赋值
int main(int argc, char * argv[]) {
@autoreleasepool {
LGPerson *person = [LGPerson alloc];
person.name = @"Cooci";
person.nickName = @"KC";
person.age = 18;
person.c1 = 'a';
person.c2 = 'b';
NSLog(@"%@",person);
}
return 0;
}
-
断点调试person,根据LGPerson的对象地址,查找出属性的值
- 通过地址找出
name&nickName
image.png
- 通过地址找出
-
通过
0x0000001200006261地址找出age等数据时,发现无法找出age等数据值,这是因为苹果中针对age、c1、c2属性的内存进行了重排,将他们存储在同一块内存中,-
age通过0x00000012读取 -
c1通过0x61读取(a的ASCII码是97) -
c2通过0x62读取(b的ASCII码是98)
image.png
-
特殊的
double和float
我们尝试把LGPerson中的height属性类型修改为double,并赋值
@property (nonatomic, assign) double height;
//赋值身高
person.height = 178;
我们发现直接po打印
0x4066400000000000,打印不出height的数值178。 这是因为编译器po打印默认当做int类型处理。p/x (double)178:我们以16进制打印double类型值打印,发现完全相同。
- 综上总结苹果中的内存对齐思想:
- 大部分的内存都是通过固定的内存块进行读取。
- 尽管我们在内存中采用了内存对齐的方式,但并不是所有的内存都可以进行浪费的,苹果会自动对
属性进行重排,以此来优化内存.
8字节对齐与16字节对齐
前面我们提及了8字节对齐和16字节对齐,这时我们就有疑问,什么时候在哪里采用哪种字节对齐,接下来我们继续源码探索
- 我们在objc4源码中搜索
class_getInstanceSize,可以在runtime.h找到:
/**
* Returns the size of instances of a class.
*
* @param cls A class object.
*
* @return The size in bytes of instances of the class \e cls, or \c 0 if \e cls is \c Nil.
*/
OBJC_EXPORT size_t
class_getInstanceSize(Class _Nullable cls)
OBJC_AVAILABLE(10.5, 2.0, 9.0, 1.0, 2.0);
在objc-class.mm可以找到:
size_t class_getInstanceSize(Class cls)
{
if (!cls) return 0;
return cls->alignedInstanceSize();
}
进入alignedInstanceSize:
// Class's ivar size rounded up to a pointer-size boundary.
uint32_t alignedInstanceSize() const {
return word_align(unalignedInstanceSize());
}
进入word_align:
#ifdef __LP64__ // 64位操作系统
# define WORD_SHIFT 3UL
# define WORD_MASK 7UL // 7字节遮罩
# define WORD_BITS 64
#else
# define WORD_SHIFT 2UL
# define WORD_MASK 3UL
# define WORD_BITS 32
#endif
static inline uint32_t word_align(uint32_t x) {
// (x + 7) & (~7) --> 8字节对齐
return (x + WORD_MASK) & ~WORD_MASK;
}
可以看到:
- 系统内部设定64位操作系统,统一使用
8字节对齐。对于一个对象来说,其真正的对齐方式是8字节对齐。 - 因外部处理对象太多,系统为了防止一些容错,会采用
align16为内存块来存取,主要是因为采用8字节对齐时,两个对象的内存会紧挨着,显得比较紧凑,而16字节比较宽松,避免越界访问,提高效率,利于苹果以后的扩展。
16字节内存对齐算法
目前已知的16字节内存对齐算法有两种
-
alloc源码分析中的align16
static inline size_t align16(size_t x) {
return (x + size_t(15)) & ~size_t(15);
}
-
malloc源码分析中的segregated_size_to_fit
#define SHIFT_NANO_QUANTUM 4
#define NANO_REGIME_QUANTA_SIZE (1 << SHIFT_NANO_QUANTUM) // 16
static MALLOC_INLINE size_t
segregated_size_to_fit(nanozone_t *nanozone, size_t size, size_t *pKey)
{
size_t k, slot_bytes;
if (0 == size) {
size = NANO_REGIME_QUANTA_SIZE; // Historical behavior
}
k = (size + NANO_REGIME_QUANTA_SIZE - 1) >> SHIFT_NANO_QUANTUM; // round up and shift for number of quanta
slot_bytes = k << SHIFT_NANO_QUANTUM; // multiply by power of two quanta size
*pKey = k - 1; // Zero-based!
return slot_bytes;
}
算法原理:k + 15 >> 4 << 4 ,其中右移4 + 左移4相当于将后4位抹零,跟 k/16 * 16一样 ,是16字节对齐算法,小于16就成0了
以 k = 2为例,如下图所示

为什么需要16字节对齐
原因有一下几点:
- 通常内存是由一个个
字节组成的,cpu在存取数据时,并不是以字节为单位存储,而是以块为单位存取,块的大小为内存存取力度。频繁存取字节未对齐的数据,会极大降低cpu的性能,所以可以通过减少存取次数来降低cpu的开销,同时使访问更安全,不会产生访问混乱的情况。 - 16字节对齐,是由于在一个对象中,第一个属性
isa占8字节,当然一个对象肯定还有其他属性,当无属性时,会预留8字节,即16字节对齐,如果不预留,相当于这个对象的isa和其他对象的isa紧挨着,容易造成访问混乱。
总结
综合前文提及的获取内存大小的方式
-
class_getInstanceSize:是采用8字节对齐,参照的对象的属性内存大小 -
malloc_size:采用16字节对齐,参照的整个对象的内存大小,对象实际分配的内存大小必须是16的整数倍