Greenplum介绍、安装与部署
Greenplum官方出了视频教程,本人认为对于新手用户快速上手有着很大帮助。本文以文字图片形式记录,加入了一些本人在使用和实际业务调试中的感受,希望对感兴趣的朋友有所帮助。第一节主要是“介绍、安装与部署”
Greenplum介绍与市场地位
| 图1 Greenplum产品发展历程 |
|---|
| 图2 Greenplum市场地位 |
|---|
Greenplum架构设计
早期的scale up(纵向扩展)架构是在单节点上添加硬件资源,如CPU、内存和存储,在纵向上获得扩展,从而获得计算和存储能力的提升。scale up早期可以快速的到达升级的目的,操作起来相对比较简单。但是硬件资源的添加会达到极限,这主要是因为服务器、主板的各种插槽和数量是有限的,同时共用的系统总线的带宽也是有限的。Postgresql可以通过增加硬件资源来处理1GB至1TB的数据,但超过1TB的数据量就已经力不从心。
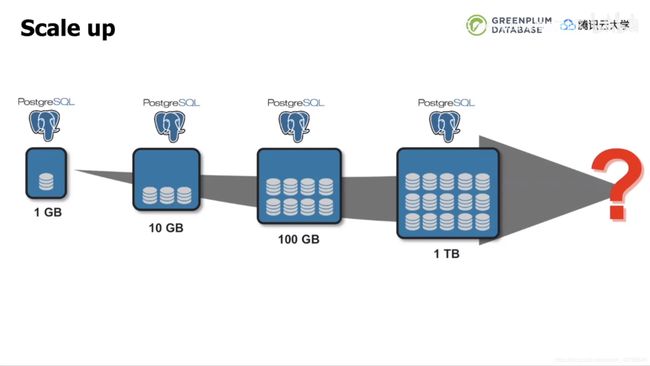
| 图3 Scale up架构 |
|---|
进阶的Scale out架构又称为横向扩展,其在分布式环境下通过增加节点来提供更多的存储、计算能力。每台postgresql数据库能处理1TB的数据量,通过不断增加服务器,可以处理数百TB乃至PB级数据,每个节点都有自己独立的硬件资源来分别计算,拥有较高的可扩展能力和鲁棒性,很好的解决了海量数据增长的计算存储需求。

| 图4 Scale out架构 |
|---|
Greenplum正是基于scale out架构设计。Greenplum对大数据量的存储和处理是通过将数据和负载分配到多个服务器来完成的。架构中管理节点和数据节点一起工作,当有查询时,管理节点生成查询计划并派发、协调segment并行计算。每个数据节点都有一个或多个postgresql数据库实例,有着自己的cpu、内存和磁盘。这是典型的share nothing架构(相互不干扰,没有共用资源和资源争抢的情况)。位于数据节点和管理节点之间的网络层是用于连续数据处理流水线的高速互联。正是因为网络层的存在Greenplum才能实现同一个集群中多个postgresql实例的高效协同和并行计算。GP的加载也是并行机制,所有的segment均参与检索数据、解析验证数据或计算哈希值等,从而实现快速的加载数据。
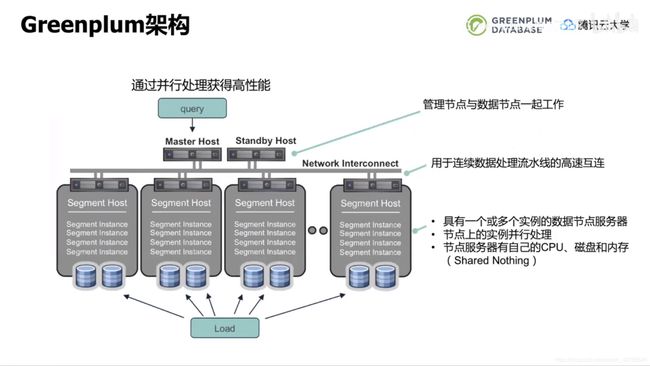
| 图5 Greenplum架构 |
|---|
Greenplum的架构主要分为三大类。第一类是管理节点master,它是系统的入口,当有应用需连接数据库时,首先要连接的是master的IP和端口。它出力所有的用户连接和生成查询计划,同时数据库系统管理工具也需要在master上执行,例如启动、停止数据库,查看数据库状态。master服务器不包含任何用户数据,从这一点来看,master节点对硬盘容量的要求比数据节点低了很多。
第二类是Interconnect,这是GP数据库的连接层,他负责元祖的重新清洗和运输,是网络的基础设施,目前一般是万兆或双万兆的配置。支持TCP和UDP协议。
第三类是segment主机。每个segment宿主机包括用户数据的一部分,每个都有自己的CPU磁盘和内存(shared nothing),用户无法直接访问segment服务器,所有用户的客户端连接都是通过master进入。

| 图6 Greenplum架构组成 |
|---|
Greenplum有几个让人眼前一亮的特点。
1.开放的架构
——采用普通的X86服务器、linux操作系统,对硬件要求不高
2. 高性能
3. 高可扩展性
——当目前的数据库配置在若干年后无法满足业务需求时,可以通过增加数据节点的方式来解决,理论上GP数据节点的数量可以达到千台左右。目前国内使用的单一集群有在200个节点左右的。Greenplum与一体机(TCA?)测试的加载性能可以达到每小时16TB。

| 图7 Greenplum几个特点 |
|---|
Greenplum机器选型
Greenplum运行在普通的X86服务器上即可,具体配置如下图所示。需要强调的是,在实际的环境测试表明,硬盘数量越多,I/O性能越好。24块硬盘用于数据盘,留出2块Hot Spare盘,在其他盘有损坏时,这两块盘可以迅速顶替。为了达到最优性能,建议生产系统按照图中所示来设置。
关于网络,从用途上划分可以分为三种。
1.用于管理
——用于启停服务器,该网络配置千兆交换机即可
2.用于集群内部数据交换和通信
——需要万兆交换机支持LACP模式的链路聚合方式
3.集群和外部应用的网络通信
——要求较高的话可以独立出来,否则可以和集群内部网络共同使用
(如果财力雄厚,买硬件和软件时,顺便购买服务,后期遇到各种奇葩问题时方便定位解决)
| 图8 机器选型一般配置 |
|---|
Greenplum安装与部署
系统准备-操作系统
GP6支持在Redhat6/7、centos6/7以及Ubuntu18.04上部署。需要强调的是如果要使用资源组功能的话,在Redhat/centos6上需要升级内核,否则性能会被降低(7.1和7.2也需要升级),最好直接使用最新的版本。PXF组件需要用到Java,主要用来和Hadoop系统进行连接。Java版本为open JDK8/11,或者oracle JDK8/11

| 图9 操作系统 |
|---|
系统准备-最小硬件要求
GP对于系统硬件要求不高,如果仅仅是用于测试或者开发,16G的内存就可以了。数据库本身所占空间并不大,每个节点预留150MB用于GP安装,每个segment实例预留约300MB用于元数据存储,其余空间主要看用户的数据存储量。网络是ipv4或ipv6协议即可。

| 图10 最小硬件要求 |
|---|
系统准备-存储
GP支持部署在虚拟化系统中,前提是使用块设备存储,并且挂载为XFS文件系统(GP仅支持XFS)

| 图11 存储 |
|---|
容量估算
容量估算主要取决于3个因素:
1.服务器可用容量
2.用户数据大小
3.GP数据库自身所需空间,包括元数据和日志
以前文机器选型中的配置为例,具体的容量估算见下图:

| 图12 存储容量估算 |
|---|
注:
1.磁盘在70%可以获得较好性能
2.primary与mirror占用空间相同,同时需留出一定空间作为缓存中间结果
3.在用户数据大小这块,经过页、行、列和属性的开销,用户数据装载到数据库后约为1.4倍
4.GP数据库自身所占空间较小,几乎可以忽略
禁用防火墙和SELinux
建议禁用防火墙(注意6和7的区别)

| 图13 禁用防火墙和SELinux |
|---|
操作系统内核调优
GP的Shared_buffers默认为125MB,一般不用调整。需要关注一下SHMMAX(共享内存段的单个最大尺寸)和SHMALL(所有共享内存的使用)
可以根据以下算式估算:
SHMMAX:
echo $(expr $(getconf _PHYS_PAGES)/2)
SHMALL:
echo $(expr $(getconf _PHYS_PAGES)/2 * $(getconf PAGE_SIZE))
一般SHMALL为物理内存一半即可。

| 图14 内核调优1 |
|---|

| 图15 内核调优2 |
|---|
时钟设置
GP对外是个整体,它的内部的时钟需保持一直(实际测试及时不一致也不影响部署)
master与生产环境的时钟服务器保持一致

| 图16 时钟设置 |
|---|
系统资源限制
系统资源限制主要是可打开文件的最大数量和最大进程数量。在RHEL/CentOS 6/7中还需要修改相应的conf文件,防止恢复原值。

| 图17 系统资源限制 |
|---|
磁盘I/O及其他参数
| 图18 磁盘I/O及其他参数 |
|---|
注:
1.设置I/O调度策略为deadline是为了在很小的延迟内获得更好的I/O性能
2.透明大页可能会降低GP性能,所以需要关闭
3.进程间通信在登陆时改为no,防止GP初始化时出现信号量相关的问题
创建用户
创建组和用户时,加上ID,目的是为了保持一致。在有的备份系统中(NFS或者其他)会对用户ID和组ID进行坚持,如果不一致,可能会进行失败。所以尽量保证UID和GID一致
- 创建组
groupadd -g 599 gpadmin
- 创建组
useradd -g gpadmin -u 600 gpadmin
echo "password" |passwd - gpadmin --stdin
Greenplum软件安装
GP分为商业版和开源版,二者除了在部分组件上有所差异外,核心功能都是一致的。

| 图19 Greenplum软件安装 |
|---|
安装好GP后需要在集群内的主机之间建立互信和创建目录。GP提供一个非常简便的主机间建立互信的工具gpssh-exkeys。成功建立互信后,可以便捷的使用一些GP工具,并且不需要输入密码。例如gpscp(快速拷贝文件到各个节点),gpssh(快速登录至各个节点执行命令)。

| 图20 建立互信和目录 |
|---|
在建立互信之后,建议检测一下磁盘和网络的性能。需要注意的是在检测网络时有-r N和-r M两个选项,前者是1对1的网络测试,后者是多点对多点的网络测试(矩阵式),如果是双万兆网络,需要配合-r M才能看出实际性能是否能达到2000MB/s

| 图21 测试磁盘和网络 |
|---|
现在可以进行数据库初始化。GP自身有很多模版,包括初始化数据库。我们拷贝一份初始化模版后进行编辑其中决定primary实例数量的是“declare -a DATA_DIRECTORY =”,一个目录代表一个实例。决定mirror数量的是“declare -a MIRROR_DATA_DIRECTORY =”(配置mirror时,要么不配置,要么与primary保持一致)。大家会比较关系一个节点到底建几个实例比较合适,这个由CPU核数和实际应用的并发决定。如果并发较少,并且希望提升性能,可以提升primary实例数量(结合具体业务来看,如果不怕麻烦,可以多配置几种,进行性能测试)。初始化配置文件配置完成之后,就可以运行“gpinitsystem -c”来初始化数据库

| 图22 初始化数据库 |
|---|
配置Standby
Standby可以在初始化数据库时配置,也可以给已经部署好的GP添加。后者首先再相应节点安装好GP、建立互信、创建数据目录,然后用“gpinitstandby -s”进行初始化,
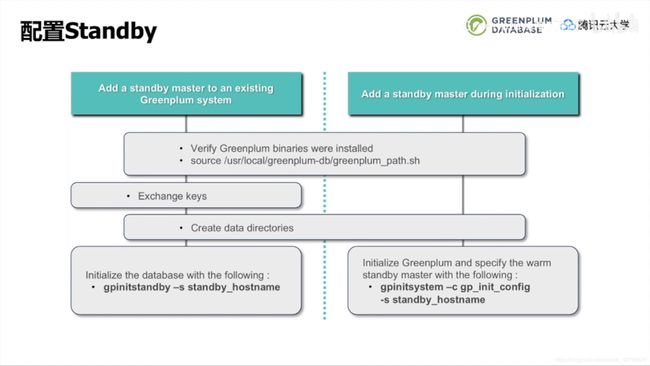
| 图23 初始化Standby |
|---|
Master Failover和Restortoration
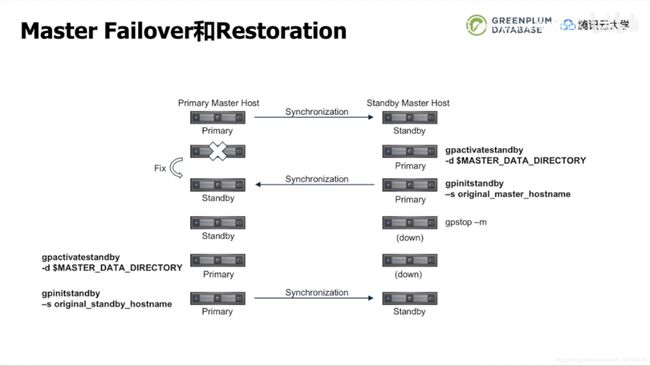
下面介绍一下当配置好standby后,GP主备切换的逻辑。
- 正常情况下,主备保持同步
- 当Master失效后,主备同步断开,此时在Standby上执行gpactivatestandby将该节点升为Master
- 当原本的Master修复后,在当前Master上执行gpinitstandby来激活Standby,此时主备恢复同步(注意此时主备角色已经切换)
- 为了恢复主备角色,首先使用gpstop -m停止当前Master
- 在当前Standby上执行gpactivatestandby,将其提升为Master
- 最后在当前Master上执行gpinitstandby来激活Standby(此时主备角色与初始相同)
GP商业版提供了主备切换(高可用)的功能,但开源版并未实现自动切换,需要手动执行。
| 图24 主备切换 |
|---|
配置Segment主实例镜像
镜像segment与standby同样作为GP高可用的一部分,可以在初始化数据库时启用,也可以在已经部署好的GP集群中使用gpaddmirrors添加(需要一个配置文件)。镜像的分布策略主要分为group(组镜像)和spread(散布镜像),当二者都不满足用户需求时,可以通过修改配置文件自定义分部策略。需要注意的是spread分布策略是将镜像一个个分布在其余主机节点上,此时需要保证segment主机节点数量大于每个主机节点上的primary segment的数量。

| 图25 segment主实例镜像 |
|---|
配置环境变量
数据库部署好后还需要配置一些环境变量。$GPHOME下有个greenplum_path.sh,需要source执行一下。下图给出配置的示范,实际的目录和端口要根据实际情况配置。

| 图26 配置环境变量 |
|---|
Greenplum使用小技巧
性能测试参考值
如果机器性能好,那么GP数据库运行起来的效果会更好(似乎是废话)。不过很多客户会关系到底怎样的机器性能才可以称之为“不错”或者“完美”,毕竟关系到投入多少资金。其实这个没有固定的说法,这里可以给一个使用gpcheckperf跑出的实际例子作为参考,其中磁盘有24块,网络为双万兆,采用模式4绑定,具体数值如下图所示。对于GP这种常用于数据仓库的产品而言,读的速率更快一些,写的速率相对更慢一些。
| 图27 性能测试参考值 |
|---|
GP也遵循木桶理论,往往性能最差的机器会拖慢整个集群的效率(例如查询时,需要汇总各个segment节点的数据)。在排查机器性能以及其他问题时,建议在实际业务上线前排查,否则等到实际业务跑起来了,留给DBA排查的时间窗口就很短了,往往还需要深夜通宵排查(笔者感触颇深)。
另外安装完毕后请重启所有服务器,重启之后在每个节点依次检查之前修改的参数有没有成功,不要怕麻烦,一个运行良好的数据库会给DBA省去很多麻烦。
日志输出与查看
在管理与解决数据库问题时,一定要意识到日志的重要性。我们在安装的时候可能会遇到莫名其妙的问题,也不知道为什么会出现,而GP的命令有一些option可以控制日志输出“-D”或者“-v”,加上这些参数后会打印更详细的日志。GP的命令很多是基于python写的(至少从GP6.10后开始,许多命令开始使用go来编写,可能是考虑到在多进程下的优势吧),可以利用print函数来打印变量值,来帮助进一步判断。
在初始化数据库的时候,有2个日志记录了非常详细的信息,分别是startup.log和*.csv(当前时间),遇到问题时可以多看一下。

| 图28 日志输出与查看 |
|---|
程序调试、监控工具安装
部署好GP只是万里长征的第一步,我们不能依靠祷告来保证数据库不出现任何异常。事实上实际的业务场景下总是会遇到一些问题,因此我们最好提前在各个数据库服务器上安装程序调试、监控工具。包括系统状态、网络状态、进程状态等。
- strace
- pstat
- gcore
- gdb
- nmon
- netperf
- netserver
同时GP自身也提供了packcore和gpmt,可以帮助收集报错信息,包括比较严重的panic信息等。GP商业版提供了GPCC(GP Command Center),图形化的监控界面,可以查看系统状态和SQL状态(超时,被锁)以及SQL的查询计划树等(付费功能就是香)。
常见问题
- 切换用户时未切换环境变量
注意不要遗漏su后的- - RHEL/CentOS 6防火墙禁了之后服务器重启又Active
可能是虚拟化工具libvert把防火墙拉起来了,需要同时禁掉这个进程
chkconfig libvertd off
- 磁盘读写性能不理想
如果服务器内存超过64G,请按照先前推荐的参数来设置
vm.dirty_backgroud_bytes = 1610612736 # 1.5GB
vm.dirty_bytes = 4294967296 # 4GB
如果dirty_bytes设置过小,可能会强行将缓存数据刷到硬盘上,无法充分利用服务器内存和磁盘的性能,影响I/O。