论文阅读_医疗NLP_ SMedBERT
介绍
英文题目:SMedBERT: A Knowledge-Enhanced Pre-trained Language Model with Structured Semantics for Medical Text Mining
中文题目:SMedBERT: 基于结构化语义的医学文本挖掘知识增强的预训练语言模型
论文地址:https://arxiv.org/pdf/2108.08983/n
领域:自然语言处理,生物医疗
发表时间:2021
作者:Taolin Zhang,华东师范大学,阿里巴巴,丁香园
出处:ACL
被引量:1
代码和数据:https://github.com/MatNLP/SMedBERT,含模型下载地址
阅读时间:22.06.22
读后感
提出SMedBERT模型,将知识注入医疗自然语言模型。它使用大规模的医疗数据,同时又融入了知识图中实体连接的语义结构。
外部数据使用了OpenKG和丁香园;利用了知识图中实体的邻居信息及其类别信息;
使用注意力方法,将已有知识注入预训练模型。
名词解析
KEPLMs(Knowledge-Enhanced Pre-trained Language Models):知识增强的预训练语言模型
mention-spans:句中某个字对应的实体
介绍
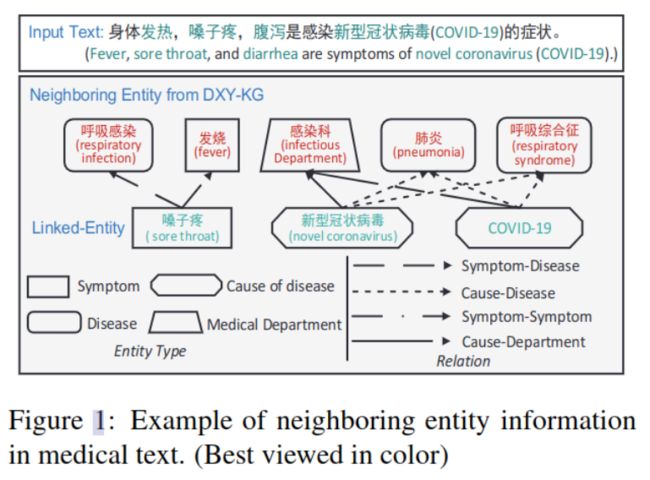
图-1中示例了一个外部知识图,图中用不同的线框表示出不同类型的实体,以及实体之间的不同关系。通过知识图中的邻居关系(类型、连接关系),可以丰富文本的语义信息;另外,将图中邻居关系作为“上下文”可补充纯文本的上下文。
主要贡献
- 使用了类别和邻居节点的注意力,以减少引入知识图时带来的干扰
- 将知识图中的邻居作为上下文训练模型
方法
符号介绍
w:单字
h:每个字的向量表示
N:字串中最大长度(可理解成文本长度)
em:单字对应的实体
E:实体集合
R:关系集合
(h,r,t):知识图中三元组(头实体、关系、尾实体)
Γent和Γrel:分别是实体的表示和关系的表示
Nem:实体em的邻居
K:实体em最重要的前K个邻居
Z:知识图中实体个数
d:向量维度
M:预测训练的实例条数
模型概览
整体逻辑如图-2所示:
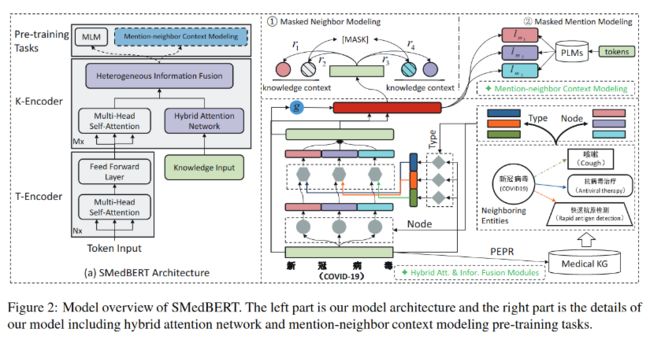
左侧是简单的流程图,分成三部分,
- 最下面的部分左边是对文本做嵌入token embedding,和BERT一样;右边引入了知识图,对于每个可能提及的实体取 top-K 个最重要的邻居。
- 中间混和知识图和基于上下文的嵌入
- 上面部分是训练模型,也包含两部分,左边是和BERT类似的MLM训练,右边将知识图中的三元组以上下文的方式组合,训练模型。
右侧图对上述逻辑做了进一步细化。(1)以输入文本是”新冠病毒“为例,刚好是个四字词,所以也作为一个单一的实体,将它送入知识图(右下),利用PERP算法找到与它关系最大的K个实体,它们是咳嗽、抗病毒治疗、快速抗原检测三个实体节点Node,分属三个类别Type;(2)使用它们做注意力将知识注入上下文语言模型混合(左);(3)将知识图中的邻居作为上下文训练自然语言模型,学习实体间关系。
实体的Top-K邻居
为了从知识图中选择最重要的前k个邻居。这里基于PPR算法(排序算法),扩展成PEPR(Personalized Entity PageRank)。
Vi计算方法如下:
Vi = (1 − α)A ·Vi−1 + αP
其中A是正则化的邻接矩阵,α是阻尼系数,P是均匀分布跳跃概率向量,用于引入随机性,即使某节点和谁都不连着,也能访问到。V是针对每个节点em迭代计算的向量,可将它看成节点的重要性,重要性由它的邻接关系A和其自身的重要程度(V初始值)构成。
V初始化的计算方法如下:

当实体em在训练集E中出现时,其初值为em在训练集中出现的频率tem除以训练集中所有实体的频率相加T(出现次数越多越重要);如果未出现,则使用1除以训练集实例数。不断迭代计算,当Vi-1与Vi相近时,停止迭代。
领居的混合注意力
融入邻居类型注意力
不同的邻居类型有不同影响,使用τ 代表不同类型,hτ将所有该类型邻居的向量相加:
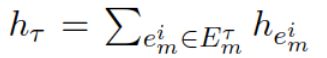
另外,利用训练实体的上下文信息(类似BERT)计算实体的表示h’em:

其中fsp是自注意力池化;hi~j是上下文的表示;σ是非线性激活函数GELU;Wbe是投影函数;LN是正则化函数。
然后针对每种邻居类型计算注意力权重:
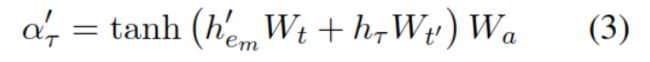
通过知识图中的邻居和上下文共同计算权值α。
融入邻居节点注意力
除了类型,邻居节点的语义Node的影响也不同,因此也利用邻居的语义计算注意力权重,以去掉干扰信息。也使用了从上下文中学到的h’em,以及邻居的表示hemi:
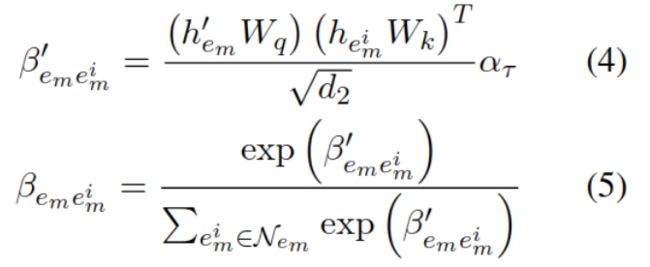
β也是注意力权重,根据上下文的表示和邻居的表示计算,式(5)进行了归一化。
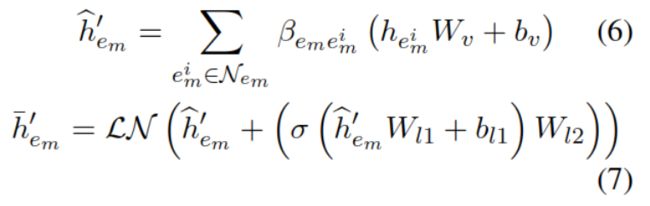
最后利用实体的前K个邻居节点计算实体的表示h^,h-又做了残差和投影转换。
利用门控加入信息
将文本的一般表示转换成注入知识的表示,使用门控方法减少知识带来的噪声。
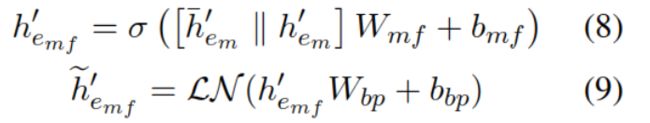
其中||表示串联(结合上下文和邻居表示),hemf是注入了知识的实体表示。计算输出hif:

gi可看作门控,先利用实体本身的嵌入hi和注入了知识的h’emf,计算门控参数gi,然后用gi对加了知识的表示加权。最终,相当于给hi补充了一些知识图中挖掘出来的信息。
利用邻居信息作为上下文建模
除了基本的BERT遮蔽方法以外,又加入了以下两种遮蔽训练方法。
遮蔽了邻居的模型 MNeM
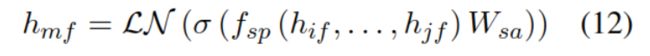
hmf是融入了知识和上下文的向量em的表示,hr 作为关系的表示。正例使用知识图中存在的连接,负例使用 SGNS(基于负采样的skip-gram)方法。使用TransR 来度量相似度。损失函数如下:
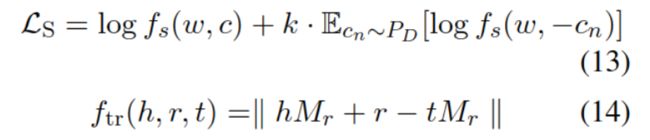
其中w是目标词,c是其上下文,fs用于度量目标词和上下文的匹配程度。式13的前半部分计算正例,后半部分计算负例。
将句中实体作为目标词,将其知识图中的领域作为上下文。使用采样的softmax来计算其目标函数LMNeM:
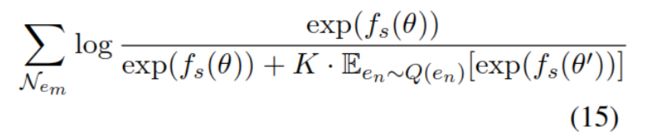
θ 是知识图中的三元组,头实体是em,尾实体是其邻居。θ '是负例三元组,尾实体是负例采样(具体方法Q(en)见附录B),上式的大概意思是说,分子是正例,分母是正例加负例。定义度量函数 f 如下:

其中 Mr 是在实体和关系间映射的矩阵, μ 是缩放系数,向量乘积为1,则它俩为共线性。上式的大概意思是头实体和关系相加后应该约等于尾实体,则说明该关系成立,详见TransR。由于对于每个实体en都要计算|henMr|,公式又做了进一步简化(略)。
遮蔽了实体的模型 MMeM
利用上下文信息计算实体:

其中ym是实体em的表示,hip是预训练的医疗BERT模型,使用hmif表示我们模型生成的实体em的表示。对于s中的实例,计算以下损失函数,让我们模型训练出的表示尽量与BERT的表示一致。
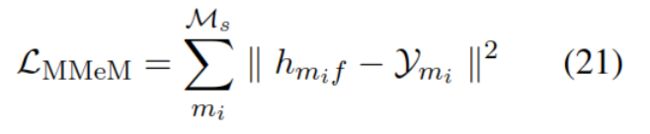
模型训练
损失函数计算方法如下:
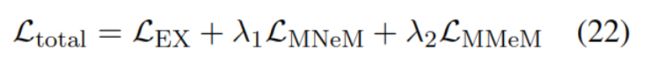
实验
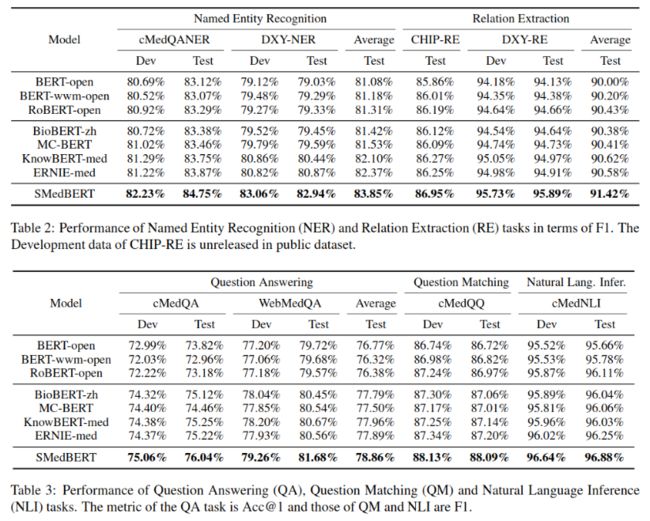
预训练使用4.9GB数据,知识图使用OpenKG和丁香园数据,用TransR方法训练。测试使用CBLUE提供的数据集训练下游任务。
主实验结果如下:
外部数据
http://www.openkg.cn/dataset/symptom-in-chinese
核心训练代码在 run_pretraining*