耕地单目标语义分割实践——Pytorch网络过程实现理解
一、卷积操作
(一)普通卷积(Convolution)


(二)空洞卷积(Atrous Convolution)
根据空洞卷积的定义,显然可以意识到空洞卷积可以提取到同一输入的不同尺度下的特征图,具有构建特征金字塔的基础。

(三)深度可分离卷积(Depthwise-Separable Convolution)
在对深度可分离卷积具有一定的了解后,我产生了一种“既然模型参数大幅度减少了,那么该模型的运行时间应该也会大幅度缩减”的想法。可是,当我分别在GPU、CPU上进行实验时,我发现结果并不与我当初所想相同。后经过查阅资料[13][14]进一步加深了我对硬件计算优势以及深度可分离卷积的理解。(注:1)实际上,通常我们一层卷积之后都会加深特征图深度,但是我所设计的实验保持了原有深度前向计算。同时,一个卷积网络也应顾及到模型精确性适当使用DSC而非完全;2)参考资料[13]具有与我相同思想的不同模型之间的对比试验)
适合GPU运算的运算类型有1)大量轻量级运算;2)高度并行运算:3)计算密集型:4)浮点型运算等。CPU擅长于串行运行。
 (图源: 三分钟搞懂CPU, GPU, FPGA计算能力 - 知乎)
(图源: 三分钟搞懂CPU, GPU, FPGA计算能力 - 知乎)
针对DSC有可能出现模型参数大幅度减少,但模型运行时间却不下降的现象,可能存在以下原因:
1)许多深度学习加速器和库(如CUDA和cuDNN),对深度可分离卷积的优化可能不够;
2)尽管深度可分离卷积需要的乘、加运算较少,但与普通卷积相比,它可能需要更多的内存访问操作,这在GPU上可能导致效率降低;
3)受限于自身设备的显存容量。

(四)转置卷积(Transpose Convolution)
转置卷积是一种卷积,它将输入和核进行了重新排列,同卷积一般是做下采样不同,它通常用作上采样。如果卷积将输入从(h,w)变成了(h‘,w'),同样超参数下转置卷积将(h‘,w')变成(h,w)。
转置卷积可以变为对应核的矩阵乘法。转置卷积是一种变化了输入和核的卷积,来得到上采样的目的,其并不等同于数学上的反卷积概念。在深度学习中,反卷积神经网络指用了转置卷积的神经网络。

二、池化操作
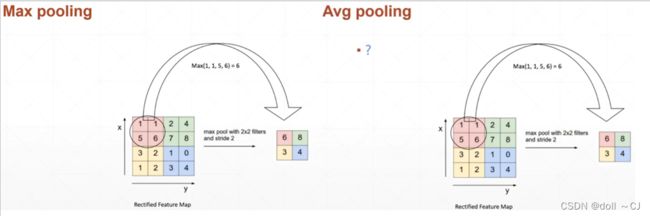
池化操作主要的作用为1)减少网络计算量与内存消耗;2)增加感受野大小;3)增加平移不变性(即较小的特征偏移也不影响特征输出)。从某种角度上来说,Pooling操作是一种对现存硬件计算能力和存储设备的妥协,其在某些卷积神经网络(如Resnet)可以被忽略。
三、数据归一化操作
数据归一化操作中(以BatchNormal为例),β和γ参数是需要计算梯度更新的学习参数,数据归一化行为在Train、Test过程中是不一样的。在Train过程中,我们需要不断计算反向梯度更新β、γ参数,而在Test过程中我们是会固定前面学习得到的β、γ参数(Pytorch中测试调用net.eval())。
批量归一化的主要作用:
1)控制传入下一层的特征图数据,有效减少梯度爆炸和梯度消失的可能;
2)减少对参数初始化的依赖;
3)便于应用更高的学习率,实现更快的收敛。

四、深度学习中的Batch、Epoch
反向梯度计算以更新模型权值等参数发生于一个Batch迭代后。初期训练时,我认为足够的Batch样本数对于模型的快速收敛较为重要。那么,如果受限于自身GPU显存限制,我们可以进一步权衡在CPU上训练更多样本数的Batch,而放宽训练时间这一要求。
在合理范围内,增大Batch_Size具有以下优点[11]:
1)内存利用率提高了,大矩阵乘法的并行化效率提高;
2)跑完一次epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快;
3)在一定范围内,一般来说Batch Size越大,其确定的下降方向越可能对准极值低点,训练引起损失震荡越小。
 (图源: 【深度学习训练之Batch】_深度学习batch_哈哈哈哈海的博客-CSDN博客)
(图源: 【深度学习训练之Batch】_深度学习batch_哈哈哈哈海的博客-CSDN博客)
五、在.ipynb文件中调用不同路径位置文件的方法
(1)首先被引.ipynb文件转换为.py文件,然后在.ipynb文件中头部添加sys.path.insert(0,r"绝对路径")或sys.path.append(r“绝对路径”)[17]。
(2)编写.ipynb解析文件置于同一文件夹下[16]。
Pytorch参考资料:
[1] 在CV/NLP/DL领域中,有哪些修改一行代码或者几行代码提升性能的算法? - 圈圈的回答 - 知乎
https://www.zhihu.com/question/427088601/answer/1544199551.
[2]在CV/NLP/DL领域中,有哪些修改一行代码或者几行代码提升性能的算法? - 陀飞轮的回答 - 知乎 https://www.zhihu.com/question/427088601/answer/1587333057
[3]PyTorch 中文文档
[4]课时61 什么是卷积-1_哔哩哔哩_bilibili
[5]PyTorch Forums
[6]https://en.wikipedia.org/wiki/Convolutional_neural_network
[7]数字图像处理:第四版/(美)拉斐尔C.冈萨雷斯(Rafael C.Gonzalez),(美)理查德E.伍兹(Richard E.Woods)著;阮秋琦等译.——北京:电子工业出版社,2020.5.
[8]深入理解空洞卷积 - 知乎
[9]演示分组,深度,深度可分离卷积|3D卷积神经网络_哔哩哔哩_bilibili
[10]卷积神经网络之深度可分离卷积(Depthwise Separable Convolution) - 知乎
[11]谈谈深度学习中的 Batch_Size_机器学习batch size作用_ycheng_sjtu的博客-CSDN博客
[12]pytorch统计模型参数量并输出_pytorch输出模型参数量_xidaoliang123的博客-CSDN博客
[13]薰风读论文:MobileNet 详解深度可分离卷积,它真的又好又快吗? - 知乎
[14]三分钟搞懂CPU, GPU, FPGA计算能力 - 知乎
Python参考资料:
[15]Python:为什么类中的私有属性可以在外部赋值并访问_python 类外访问私有属性_Ding Jiaxiong的博客-CSDN博客
[16]调用jupyter notebook文件内的函数一种简单方法_AlexInML的博客-CSDN博客
[17]Jupyter Notebook引入外部的py文件中的方法_dirtyboy6666的博客-CSDN博客