Attention机制理解(参考代码和理论)
Attention机制(全局和局部attention)
1 .Luong Attention(全局attention)
基于注意力机制的解码
解码器RNN一个词语一个词语地产生回复句子,它利用编码器得到的上下文向量以及每个时间步的隐向量来产生句子的下一个词语。它一直产生词语直到产生句子结束符号EOS_token。仅仅使用标准RNN做解码器,会使得模型丢失掉丰富的编码端信息,因为整个句子的信息都被保存到一个上下文向量中。
考虑到人们在对话时,回复语句中的每个词语会和输入语句中的不同部分的词语相关,那么在模型解码的每个时间步,通过对输入语句中的相关词语施加更多的“注意力”,即更好地关注到编码端的相关信息,那么就能解码出更好的词语。因此解码器在解码时候的每个时间步都关注到输入句子中的某一特定部分,而不是在每个时间步都使用相同的编码器得到的上下文向量。如下图所示, h t h_t ht为当前回复端解码器的状态, h s ˉ \bar{h_s} hsˉ为输入端编码器任意位置的状态, h t h_t ht对输入端不同的 h s ˉ \bar{h_s} hsˉ有不同的注意力得分,相关的状态得分高,不相关的状态得分低,所有得分为 a t a_t at(长度为编码端句子的长度),将注意力得分与对应编码状态相乘再相加得到新的加权上下文向量 c t c_t ct,与 h t h_t ht一起用于解码出 h t ~ ~\widetilde{h_t} ht 。
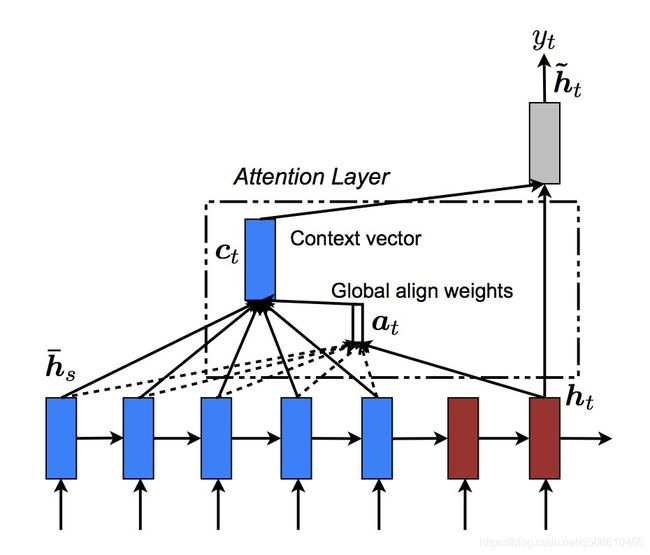
Luong等人提出三种计算注意力得分的方法(也叫全局Attention):
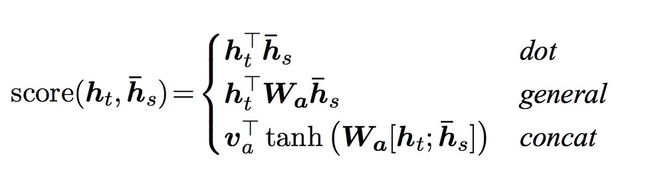
# Luong的attention layer 全局attention
class Attn(torch.nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = torch.nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = torch.nn.Linear(self.hidden_size * 2, hidden_size)
self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size))
def dot_score(self, hidden, encoder_output):
return torch.sum(hidden * encoder_output, dim=2)
def general_score(self, hidden, encoder_output):
energy = self.attn(encoder_output)
return torch.sum(hidden * energy, dim=2)
def concat_score(self, hidden, encoder_output):
energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1), encoder_output), 2)).tanh()
return torch.sum(self.v * energy, dim=2)
def forward(self, hidden, encoder_outputs):
# 根据给定的方法计算注意力score
if self.method == 'general':
attn_energies = self.general_score(hidden, encoder_outputs)
elif self.method == 'concat':
attn_energies = self.concat_score(hidden, encoder_outputs)
elif self.method == 'dot':
attn_energies = self.dot_score(hidden, encoder_outputs)
# 转换最大长度和batch_size的维度
attn_energies = attn_energies.t()
#返回标准化得分
return F.softmax(attn_energies, dim=1).unsqueeze(1)
解码器计算图 如下:
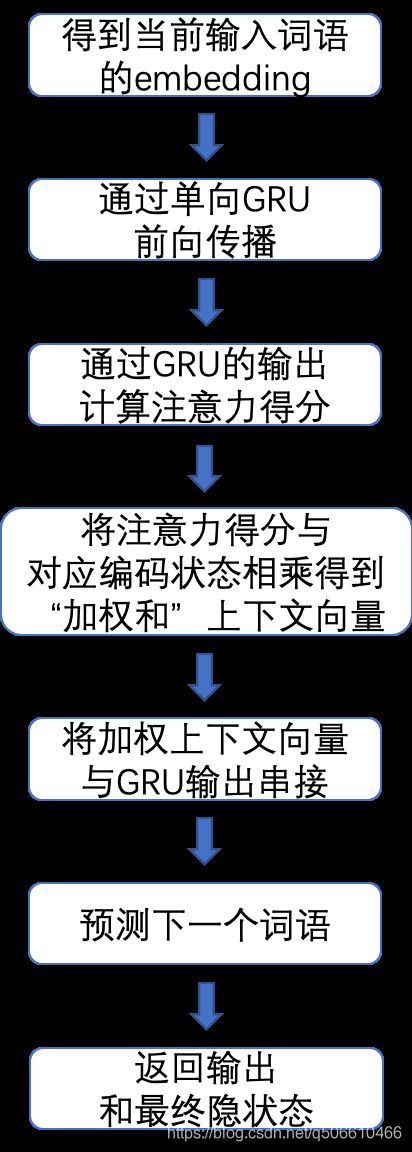
输入
input_step:每一步输入序列batch(一个单词);shape =(1,batch_size)
last_hidden:GRU的最终隐藏层;shape =(n_layers x num_directions,batch_size,hidden_size)
encoder_outputs:编码器模型的输出;shape =(max_length,batch_size,hidden_size)
输出
output: 一个softmax标准化后的张量, 代表了每个单词在解码序列中是下一个输出单词的概率;shape =(batch_size,voc.num_words)
hidden: GRU的最终隐藏状态;shape =(n_layers x num_directions,batch_size,hidden_size)
class LuongAttnDecoderRNN(nn.Module):
"""
基于注意力机制的解码器
"""
def __init__(self, attn_model, embedding, hidden_size, output_size, n_layers=1, dropout=0.1):
super(LuongAttnDecoderRNN, self).__init__()
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout = dropout
# 定义层
self.embedding = embedding
self.embedding_dropout = nn.Dropout(dropout)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout))
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.attn = Attn(attn_model, hidden_size)
def forward(self, input_step, last_hidden, encoder_outputs):
# 注意:我们一次运行这一步(单词)
# 获取当前输入词语的embedding
embedded = self.embedding(input_step)
embedded = self.embedding_dropout(embedded)
# 单向GRU前向传播
rnn_output, hidden = self.gru(embedded, last_hidden)
# 从当前GRU输出计算注意力
attn_weights = self.attn(rnn_output, encoder_outputs)
# 将注意力权重乘以编码器输出以获得新的“加权和”上下文向量
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
# 串接加权上下文向量和GRU输出
rnn_output = rnn_output.squeeze(0)
context = context.squeeze(1)
concat_input = torch.cat((rnn_output, context), 1)
concat_output = torch.tanh(self.concat(concat_input))
# 预测下一个单词
output = self.out(concat_output)
output = F.softmax(output, dim=1)
# 返回输出和最终隐状态
return output, hidden
2.Bahdanau Attention(局部attention)
Bahdanau Attention会使用前一次的隐藏状态来计算attention weight,所以我们会在代码中的GRU之前使用attention的操作,同时会把attention的结果和word embedding的结果进行concat,作为GRU的输出(参考的是pytorch Toritul)。Bahdanau使用的是双向的GRU,会使用正反的encoder的output的concat的结果作为encoder output
其attention weight的计算方式为:
Bahdanau Attention的match函数, a i j = v a T t a n h ( W a Z i − 1 , + U a h j ) a_i^j = v^T_a tanh (W_aZ_{i-1},+U_ah_j) aij=vaTtanh(WaZi−1,+Uahj),计算出所有的 a i j a_i^j aij之后,在计算softmax,得到 a ^ i j \hat{a}_i^j a^ij,即 a ^ i j = e x p ( a i j ) ∑ e x p ( a i j ) \hat{a}_i^j = \frac{exp(a_i^j)}{\sum exp(a_i^j)} a^ij=∑exp(aij)exp(aij)
其中
- v a T 是 一 个 参 数 矩 阵 , 需 要 被 训 练 , W a 是 实 现 对 Z i − 1 的 形 状 变 化 v_a^T是一个参数矩阵,需要被训练,W_a是实现对Z_{i-1}的形状变化 vaT是一个参数矩阵,需要被训练,Wa是实现对Zi−1的形状变化,
- U a 实 现 对 h j 的 形 状 变 化 ( 矩 阵 乘 法 , 理 解 为 线 性 回 归 , 实 现 数 据 形 状 的 对 齐 ) U_a实现对h_j的形状变化(矩阵乘法,理解为线性回归,实现数据形状的对齐) Ua实现对hj的形状变化(矩阵乘法,理解为线性回归,实现数据形状的对齐),
- Z i − 1 是 d e c o d e r 端 前 一 次 的 隐 藏 状 态 , h j 是 e n c o d e r 的 o u t p u t Z_{i-1}是decoder端前一次的隐藏状态,h_j是encoder的output Zi−1是decoder端前一次的隐藏状态,hj是encoder的output
如下图所示
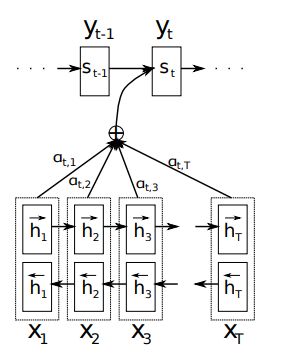
# 局部attention
class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias=False)
def forward(self, hidden, encoder_outputs, mask):
# hidden = [batch size, dec hid dim]
# encoder_outputs = [doc len, batch size, enc hid dim * 2]
batch_size = encoder_outputs.shape[1]
doc_len = encoder_outputs.shape[0]
# 对decoder的状态重复doc_len次,用来计算和每个encoder状态的相似度
hidden = hidden.unsqueeze(1).repeat(1, doc_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
# hidden = [batch size, doc len, dec hid dim]
# encoder_outputs = [batch size, doc len, enc hid dim * 2]
# 使用全连接层计算相似度
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
# energy = [batch size, doc len, dec hid dim]
# 转换尺寸为[batch, doc len]的形式作为和每个encoder状态的相似度
attention = self.v(energy).squeeze(2)
# attention = [batch size, doc len]
# 规避encoder里pad符号,将这些位置的权重值降到很低
attention = attention.masked_fill(mask == 0, -1e10)
# 返回权重
return F.softmax(attention, dim=1)
局部attention 的 decoder
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs, mask):
# input = [batch size]
# hidden = [batch size, dec hid dim]
# encoder_outputs = [doc len, batch size, enc hid dim * 2]
# mask = [batch size, doc len]
input = input.unsqueeze(0)
# input = [1, batch size]
embedded = self.dropout(self.embedding(input))
# embedded = [1, batch size, emb dim]
a = self.attention(hidden, encoder_outputs, mask)
# a = [batch size, doc len]
a = a.unsqueeze(1)
# a = [batch size, 1, doc len]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
# encoder_outputs = [batch size, doc len, enc hid dim * 2]
weighted = torch.bmm(a, encoder_outputs)
# weighted = [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
# weighted = [1, batch size, enc hid dim * 2]
rnn_input = torch.cat((embedded, weighted), dim=2)
# rnn_input = [1, batch size, (enc hid dim * 2) + emb dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
# output = [seq len, batch size, dec hid dim * n directions]
# hidden = [n layers * n directions, batch size, dec hid dim]
# seq len, n layers and n directions 在decoder为1的情况比较多, 所以:
# output = [1, batch size, dec hid dim]
# hidden = [1, batch size, dec hid dim]
# output和hidden应该是相等的,output == hidden
assert (output == hidden).all()
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim=1))
# prediction = [batch size, output dim]
return prediction, hidden.squeeze(0), a.squeeze(1)
总结
两种Attention的区别
Luong Attenion(也叫全局attention)使用的是当前一次的decoder的output来计算得到attention weight,所以在代码中会在GRU的后面进行attention的操作,同时会把context vector和gru的结果进行concat的操作,最终的output。Luong使用的是多层GRU,只会使用最后一层的输出(encoder output)
其中计算attn_weights时,rnn_output 和 encoder_outputs 的形状相同,所以在Attention模块计算权重使用的是 * 号 乘法
Bahdanau Attention(也叫局部attention)会使用前一次的隐藏状态来计算attention weight,所以我们会在代码中的GRU之前使用attention的操作,同时会把attention的结果和word embedding的结果进行concat,作为GRU的输出(参考的是pytorch Toritul)。Bahdanau使用的是双向的GRU,会使用正反的encoder的output的concat的结果作为encoder output,
计算attention weights的方法不同
-
Bahdanau Attention的match函数, a i j = v a T t a n h ( W a Z i − 1 , + U a h j ) a_i^j = v^T_a tanh (W_aZ_{i-1},+U_ah_j) aij=vaTtanh(WaZi−1,+Uahj),计算出所有的 a i j a_i^j aij之后,在计算softmax,得到 a ^ i j \hat{a}_i^j a^ij,即 a ^ i j = e x p ( a i j ) ∑ e x p ( a i j ) \hat{a}_i^j = \frac{exp(a_i^j)}{\sum exp(a_i^j)} a^ij=∑exp(aij)exp(aij)其中
- v a T 是 一 个 参 数 矩 阵 , 需 要 被 训 练 , W a 是 实 现 对 Z i − 1 的 形 状 变 化 v_a^T是一个参数矩阵,需要被训练,W_a是实现对Z_{i-1}的形状变化 vaT是一个参数矩阵,需要被训练,Wa是实现对Zi−1的形状变化,
- U a 实 现 对 h j 的 形 状 变 化 ( 矩 阵 乘 法 , 理 解 为 线 性 回 归 , 实 现 数 据 形 状 的 对 齐 ) U_a实现对h_j的形状变化(矩阵乘法,理解为线性回归,实现数据形状的对齐) Ua实现对hj的形状变化(矩阵乘法,理解为线性回归,实现数据形状的对齐),
- Z i − 1 是 d e c o d e r 端 前 一 次 的 隐 藏 状 态 , h j 是 e n c o d e r 的 o u t p u t Z_{i-1}是decoder端前一次的隐藏状态,h_j是encoder的output Zi−1是decoder端前一次的隐藏状态,hj是encoder的output
-
Luong Attenion整体比Bahdanau Attention更加简单,他使用了三种方法来计算得到权重- 矩阵乘法:general
- 直接对decoder的隐藏状态进行一个矩阵变换(线性回归),然后和encoder outputs进行矩阵乘法
- dot
- 直接对decoder的隐藏状态和encoder outputs进行矩阵乘法
- concat
- 把decoder的隐藏状态和encoder的output进行concat,把这个结果使用tanh进行处理后的结果进行对齐计算之后,和encoder outputs进行矩阵乘法
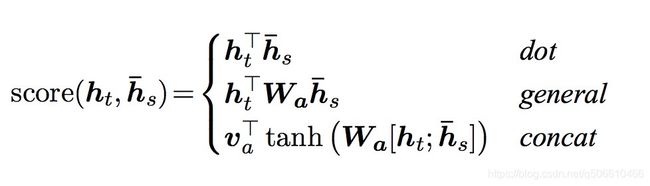
h t 是当前的decoder hidden state, h s 是所有的encoder 的hidden state(encoder outputs) h_t\text{是当前的decoder hidden state,}h_s\text{是所有的encoder 的hidden state(encoder outputs)} ht是当前的decoder hidden state,hs是所有的encoder 的hidden state(encoder outputs) - 矩阵乘法:general
最终两个attention的结果区别并不太大