RoPE旋转位置编码图形化理解
很多博文用公式描述RoPE的作用,看来看去还是似懂非懂,本文用图形的方式形象化的展示RoPE的作用;
首先,RoPE的核心思想是通过绝对位置编码的方式实现相对位置编码,本文主要围绕下图进行介绍;
假设一个序列 s = [ s 1 , s 2 , . . . , s 100 ] s = [s_1, s_2, ...,s_{100}] s=[s1,s2,...,s100](为了直观,这里取1作为起始位置,以下同理),要计算第100个位置上的注意力,需要得到 q 100 ∗ [ k 1 , k 2 , . . . , k 100 ] q_{100}*[k_1, k_2, ...,k_{100}] q100∗[k1,k2,...,k100],由于是自注意力,这里的 q 100 = k 100 q_{100}=k_{100} q100=k100,如果是常规的绝对位置编码,这里的 q = q 词嵌入 + q 绝对位置嵌入 q=q_{词嵌入}+q_{绝对位置嵌入} q=q词嵌入+q绝对位置嵌入, k k k也相同;
在RoPE中,取 q = q 词嵌入 q=q_{词嵌入} q=q词嵌入,同时假设隐层维度是768,则 q 100 = [ q 100 , 1 , q 100 , 2 , . . . , q 100 , 768 ] q_{100}=[q_{100,1},q_{100,2}, ...,q_{100,768}] q100=[q100,1,q100,2,...,q100,768],因为在RoPE中相当于是二维旋转编码,所以两个两个进行旋转计算,先取 q 100 = [ q 100 , 1 , q 100 , 2 ] q_{100} = [q_{100,1},q_{100,2}] q100=[q100,1,q100,2],同理 k 1 至 k 100 k_1至k_{100} k1至k100也只取前两维。
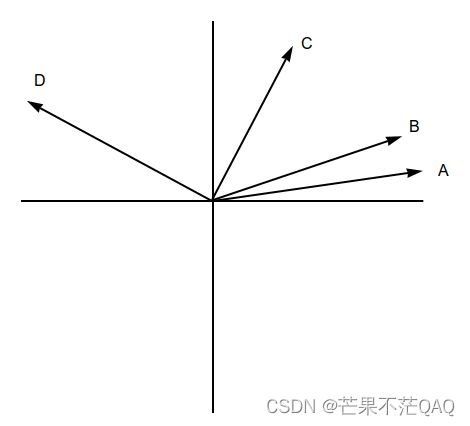
假设这100个词的词嵌入都相等(为了更明显的看出旋转位置带来的差异,后面再解释词嵌入的差异)。由于这里只取二维,所以可以表示成向量的形式,假设所有的词嵌入都用图中A向量表示。
现在每个词嵌入都需融入一个绝对位置嵌入,融入的方式不是常规的与词嵌入相加,而是进行旋转,旋转角度为 i θ i\theta iθ, θ \theta θ用一个固定的角度表示, i i i代表当前的位置下标。比如序列 s 1 s_1 s1旋转 θ \theta θ角得到图中B向量, s 10 s_{10} s10旋转 10 ∗ θ 10*\theta 10∗θ角得到图中C向量, s 100 s_{100} s100旋转 100 ∗ θ 100*\theta 100∗θ角得到图中D向量。这里旋转之后也带来了余弦相似度的变化, q 100 ∗ k 100 q_{100}*k_{100} q100∗k100时相似度为1,结果完全是词嵌入之间的相似度, q 100 ∗ k 10 q_{100}*k_{10} q100∗k10时则带来了 90 ∗ θ 90*\theta 90∗θ角度相似度的差异。所以可以说通过绝对位置编码的方式实现了相对位置编码。
下面再说词嵌入的差异,正常来讲每个token的词嵌入是不一样的,但这是词嵌入本身就带有的差异,RoPE只是在词嵌入基础上增加了位置上的差异,所以是合理的。
由于内积带有线性叠加性,图中多个两维处理之后可以直接叠加到一起,所以原理是相同的。
讲RoPE公式的博文已经很多了,这里就不列公式了,想看公式了解细节的可以移步其他博文。