MongoDB高级查询、聚合查询脚本练习
前言
为了巩固前边学习的mongodb聚合、关联查询,模拟一个部门管理的数据库来进行练习
一、数据库设计
1.1、概念模型
- 员工信息表(employee):唯一id、员工编号、员工姓名、所属部门、职位、入职时间、性别、手机号、邮箱、喜好
- 公司部门表(department):部门编号、部门名称、部门地点、负责人工号、部门人数
- 部门职位表(position):唯一id、职位编号、职位名称
- 工资表(salary):唯一id、员工编号、基本工资、五险一金、绩效奖金、补贴、发放时间、实发工资
注:该表设计是按照关系型数据库规则去设计的,本次练习只是为了加深本人对聚合查询、多表连接查询的熟练度。实际上mongodb是非关系型数据库,不宜频繁的多表连接,需要在数据库设计上进行优化
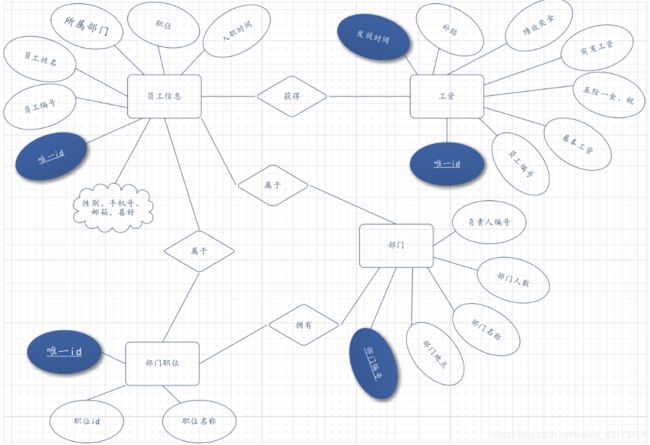
1.2、ER图
员工管理mongodb数据库ER图如下:
二、数据脚本
- department插入数据
db.department.insertMany([
{_id:"1001","depName":"武汉研发部","director" :"E10001","depEmpCount":20,"address":"武汉"},
{_id:"1002","depName":"上海研发部","director" :"E10007","depEmpCount":20,"address":"上海"},
{_id:"1003","depName":"广州研发部","director" :"E10013","depEmpCount":20,"address":"广州"},
{_id:"1004","depName":"人事部","director" :"E10019","depEmpCount":5,"address":"上海"}
])
- employee插入数据(部分)
db.employee.insertMany([
{
"empId" : "E10002",
"name" : "员工2",
"depId" : "1001",
"pos" : [
"技术经理",
"全栈开发"
],
"entryTime" : new Date(),
"ownMess" : {
"sex" : "男",
"phone" : "100002",
"mail" : "[email protected]",
"hobbies" : [
"看书",
"股票"
]
}
},
{
"empId" : "E10003",
"name" : "员工3",
"depId" : "1001",
"pos" : [
"后端开发"
],
"entryTime" : new Date(),
"ownMess" : {
"sex" : "男",
"phone" : "100003",
"mail" : "[email protected]",
"hobbies" : [
"足球",
"乒乓球"
]
}
},
{
"empId" : "E10004",
"name" : "员工4",
"depId" : "1001",
"pos" : [
"后端开发"
],
"entryTime" : new Date(),
"ownMess" : {
"sex" : "男",
"phone" : "100004",
"mail" : "[email protected]",
"hobbies" : [
"游戏",
"唱歌"
]
}
},
{
"empId" : "E10005",
"name" : "员工5",
"depId" : "1001",
"pos" : [
"前端开发"
],
"entryTime" : new Date(),
"ownMess" : {
"sex" : "女",
"phone" : "100005",
"mail" : "[email protected]",
"hobbies" : [
"唱歌",
"跳舞"
]
}
}
])
- salary插入数据:
db.salary.insertMany([
{"empId":"E10007", "baseSalary":19000, "tax":3400 , "bonus":3000 , "subside":700 , "total":20200 , "giveTime": new Date()},
{"empId":"E10013", "baseSalary":20000, "tax":3500 , "bonus":3000 , "subside":700 , "total":20200 , "giveTime": new Date()},
{"empId":"E10019", "baseSalary":15000, "tax":3500 , "bonus":3000 , "subside":700 , "total":15200 , "giveTime": new Date()},
{"empId":"E10003", "baseSalary":10000, "tax":1700 , "bonus":3000 , "subside":700 , "total":12000 , "giveTime": new Date()}
])
- position展示:

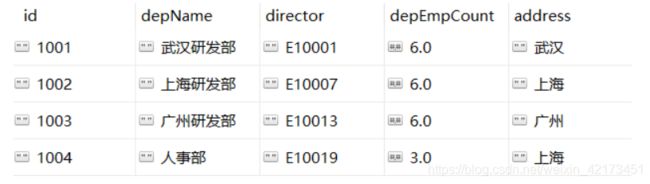
- department展示:
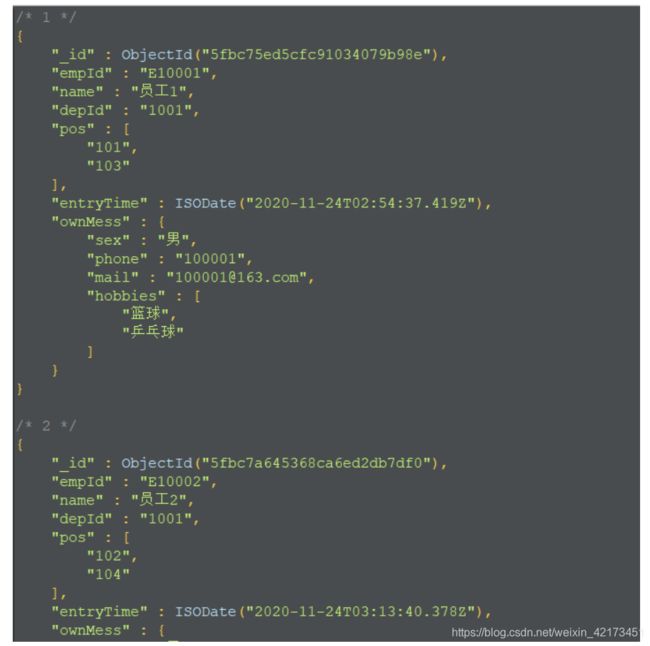
- employee展示(表格+结构化):

- salary展示:

三、查询测试
3.1、单表测试
- 查询工作地点在上海的部门
db.department.find({"address":"上海"}, {_id:0, "depName":1})
结果展示:

- 查询所有的部门负责人的员工编号
db.department.find({}, {_id:0, "director":1})
结果展示:

- 查询研发部有哪几个
# 写法1
db.department.find({"depName":{$regex:"研发部"}})
# 写法2
db.department.find({"depName":/研发部/})
- 查询人数大于5的员工数
db.department.find({"depEmpCount":{$gt:5}},{_id:0, "depName":1, "depEmpCount":1})
- 查询所有部门的总员工数
db.department.aggregate([
{$group:{
_id:null,
"sumCount":{'$sum':'$depEmpCount'}
}},
{$project:{
_id:0,
"sumCount":1
}}
])
- 查询最后入职的两名员工
db.employee.aggregate([
# 根据时间降序排,然后取前两个
{$match:{}},
{$sort:{"entryTime":-1}},
{$limit:2}
])
- 查询喜欢跳舞的员工
db.employee.find({"ownMess.hobbies":{$eq:"跳舞"}}, {_id:0, "name":1})
- 查询每个员工的第一个爱好(笔记)
# 本例麻烦点在于喜爱信息存在子文档(ownMess)的数组(hobbies只包含值元
# 素)中,属于嵌套文档中再嵌套数组。第一个方法是我想麻烦了,开始并不知道
# 3.2之后在聚合中新增了$slice的相关用法
db.employee.aggregate([
{$unwind : {path:"$ownMess.hobbies", includeArrayIndex: "arrayIndex"}},
{$match:{
"arrayIndex" : NumberLong(0)
}},
{$group:{
_id:"$name",
"hobby":{$push:"$ownMess.hobbies"}
}},
{$project:{
_id:1,
"hobby":1
}}
])
# 上面可以简化为
db.employee.aggregate([
{$project:{
_id:0,
"name":1,
"hobbies":{$slice:["$ownMess.hobbies",0,1]}
}}
])
结果展示:

- 查询既喜欢乒乓球又喜欢篮球的员工
# find()下直接用$elemMatch处理数组,用$eq进行匹配
db.employee.find({"ownMess.hobbies":{$all:[{$elemMatch:{$eq:"唱歌"}},{$elemMatch:{$eq:"跳舞"}}]}},{_id:0,"name":1})
# 等同于
db.employee.aggregate([
{$match:{"ownMess.hobbies":{$all:["跳舞","唱歌"]}}},
{$project:{_id:0,"name":1}}
])
结果展示:

- 查询没有填写手机号的员工
db.employee.find({"ownMess.phone":{$exists:false}}, {_id:0, "name":1})
- 查询前五个员工信息
db.employee.find({}).skip(0).limit(5)
# 5-10
db.employee.find({}).skip(5).limit(5)
- 查询该公司一共有多少种岗位
db.position.find({}).count()
- 查询工资在15000以上的员工编号
db.salary.find({"total":{$gt:15000}}, {_id:0, "empId":1})
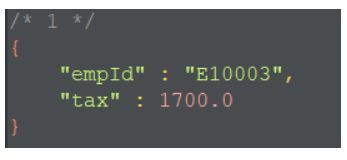
- 查询扣税最少的员工编号
db.salary.aggregate([
# 先排序,再取第一个
{$sort:{"tax":1}},
{$limit:1},
{$project:{
_id:0,
"empId":1,
"tax":1
}}
])
结果展示:
- 查询员工的平均奖金
db.salary.aggregate([
{$group:{
_id:null,
"avgbonus":{$avg:"$bonus"}
}},
{$project:{
_id:0,
"avgbonus":1
}}
])
- 查询员工平均工资
db.salary.aggregate([
{$group:{
_id:null,
"avgRealSalary":{$avg:"$total"}
}},
{$project:{
_id:0,
"avgRealSalary":1
}}
])
3.2、多表测试(
- 查询武汉研发部所有员工信息
db.employee.aggregate([
{$lookup:
{ # 通过部门id进行连表
from: "department",
localField: "depId",
foreignField: "_id",
as: "department_doc"
}
},
{$match:
{
"department_doc.depName": "武汉研发部"
}
},
{$project:
{
_id:0,
"employee_doc":0
}
}
])
- 查询每个部门的员工名字(直接连表)
db.employee.aggregate([
{$lookup:
{
from: "department",
localField: "depId",
foreignField: "_id",
as: "department_doc"
}
},
{$group:
{
_id: "$department_doc.depName",
"ownEmps":{$push:"$name"}
}
},
])
结果展示:

- 查询所有部门负责人的工资
db.salary.aggregate([
{$lookup:
{
from: "department",
localField: "empId",
foreignField: "director",
as: "department_doc"
}
},
{
$match:{
"department_doc":{$ne:[]}
}
},
{
$project:{
_id:0,
"department_doc.depName":1,
"empId":1,
"total":1
}
}
])
结果展示:

- 查询所有部门负责人的姓名
db.department.aggregate([
{$lookup:
{ # 通过负责人员工编号域进行连表
from: "employee",
localField: "director",
foreignField: "empId",
as: "employee_doc"
}
},
{ # 筛选不为空的
$match:{
"employee_doc":{$ne:[]}
}
},
{
$project:{
_id:0,
"depName":1,
"employee_doc.name":1,
}
}
])
- 查询武汉研发部所有员工电话
db.department.aggregate([
# 先连表
{$lookup:
{
from: "employee",
localField: "_id",
foreignField: "depId",
as: "employee_doc"
}
},
{ # 筛选武汉部门的员工信息
$match:{
"depName":"武汉研发部"
}
},
{
$project:{
_id:0,
"depName":1,
"employee_doc.name":1,
"employee_doc.ownMess.phone":1,
}
}
])
结果展示:

- 查询已发工资人员的姓名和实发工资
db.salary.aggregate([
{$lookup:
{
from: "employee",
localField: "empId",
foreignField: "empId",
as: "employee_doc"
}
},
{
$project:{
_id:0,
"employee_doc.name":1,
"total":1
}
}
])
- 查询武汉研发部前端开发(103)的电话
db.department.aggregate([
# 本例直接提供前端编号(本例目的是二表相联)实际上也可以三表
{$lookup:
{
from: "employee",
localField: "_id",
foreignField: "depId",
as: "employee_doc"
}
},
{
$match:{
"depName": "武汉研发部",
"employee_doc.pos": "103"
}
},
{
$project:{
_id:0,
"depName":1,
"employee_doc.pos":1,
"employee_doc.name":1,
"employee_doc.ownMess.phone":1,
}
}
])
- 查询拥有多个职级的员工信息并且给出职级名称
db.employee.aggregate([
# 整体思路:因为pos是数组,职级个数不定,所以,先拆分然后连表、组合并
# 计数,筛选出计数=2(本例中最多只有2个职级,高于2,则$gt:1)
{
$unwind: "$pos"
},
{$lookup:
{
from: "position",
localField: "pos",
foreignField: "posId",
as: "position_doc"
}
},
{
$group:{
_id: "$name",
"posCount":{$sum:1},
"posNameArray":{$push:"$position_doc.posName"}
}
},
{
$match:{
"posCount":{$eq:2}
}
},
{
$project:{
_id:1,
"posNameArray":1
}
}
])
结果展示:

- 查询所有没发工资的员工
db.employee.aggregate([
{$lookup:
{
from: "salary",
localField: "empId",
foreignField: "empId",
as: "salary_doc"
}
},
{
$match:{ # 连表后,直接匹配salary_doc为空的就是没发工资的
"salary_doc":{$eq:[]}
}
},
{
$project:{
_id:0,
"empId":1,
"name":1
}
}
])
结果展示:

- 查询所有的经理信息
db.employee.aggregate([
{ # 可要可不要,加上去后,有两个职级的只显示一个
$unwind:"$pos"
},
{$lookup:
{
from: "position",
localField: "pos",
foreignField: "posId",
as: "position_doc"
}
},
{
$match:{
"position_doc.posName":/经理/
}
}
])
- 查询上海部门的所有员工
db.department.aggregate([
{
$match:{ # 筛选出工作地点在上海的部门
"address": "上海",
}
},
{$lookup:
{ # 筛选之后进行连表,此时的先决条件已经是在上海的部门id
from: "employee",
localField: "_id",
foreignField: "depId",
as: "employee_doc"
}
}
])
三个表以上的连接,实际上就是再加一个lookup
- 查询武汉研发部技术经理的手机号(操作集合:department、employee、position)
db.employee.aggregate([
{
$lookup:{
from: "department",
localField: "depId",
foreignField: "_id",
as: "department_doc"
}
},
# 此处也可以$match进行第一次筛选,然后再次连表
{
$lookup:{
from: "position",
localField: "pos",
foreignField: "posId",
as: "position_doc"
}
},
{
$match:{
"department_doc.depName": "武汉研发部",
"position_doc.posName": {$in: ["技术经理"]}
}
},
{
$project:{
_id: 0,
"department_doc.depName": 1,
"position_doc.posName": 1,
"ownMess.phone": 1
}
}
])
结果:

附表
| SQL 操作/函数 | mongodb聚合操作 |
|---|---|
| where | $match |
| group by | $group |
| having | $match |
| select | $project |
| order by | $sort |
| limit | $limit |
| sum() | $sum |
| count() | $sum |
| join | $lookup (v3.2 新增) |