文档在线预览(一)通过将txt、word、pdf、ppt文件转成图片实现在线预览功能
文章目录
- 一、前言
-
- 1、aspose
- 2 、poi + pdfbox
- 3 spire
- 二、将文件转换成图片,并生成到本地
-
- 1、将word文件转成图片
-
- (1)使用aspose
- (2)使用pdfbox
- (3)使用spire
- 2、将txt文件转成图片(同word文件转成图片)
-
- (1)使用aspose
- 3、将pdf文件转图片
-
- (1)使用aspose
- (2)使用pdfbox
- (3)使用spire
- 4、将ppt文件转图片
-
- (1)使用aspose
- (2)使用pdfbox
- (3)使用spire
- 三、利用多线程提升文件写入本地的效率
- 四、将文件转换成图片流
-
- 1、将word文件转成图片流
-
- (1)使用aspose
- (2)使用pdfbox
- (3)使用spire
- 2、将txt文件转成图片流
-
- (1)使用aspose
- 3、将pdf转成图片流
-
- (1)使用aspose
- (2)使用pdfbox
- (3)使用spire
- 4、将ppt文件转图片流
-
- (1)使用aspose
- (2)使用pdfbox
- (3)使用spire
- 总结
一、前言
如果不想网页上的文章被复制(没错,说的就是某点),如果想实现文档不需要下载下来就能在线预览查看(常见于文档付费下载网站、邮箱附件预览),该怎么做?常见的做法就是将他们转化成图片。
以下代码分别提供基于aspose、pdfbox、spire来实现来实现txt、word、pdf、ppt、word等文件转图片的需求。
1、aspose
Aspose 是一家致力于.Net ,Java,SharePoint,JasperReports和SSRS组件的提供商,数十个国家的数千机构都有用过aspose组件,创建、编辑、转换或渲染 Office、OpenOffice、PDF、图像、ZIP、CAD、XPS、EPS、PSD 和更多文件格式。注意aspose是商用组件,未经授权导出文件里面都是是水印(尊重版权,远离破解版)。
需要在项目的pom文件里添加如下依赖
<dependency>
<groupId>com.asposegroupId>
<artifactId>aspose-wordsartifactId>
<version>23.1version>
dependency>
<dependency>
<groupId>com.asposegroupId>
<artifactId>aspose-pdfartifactId>
<version>23.1version>
dependency>
<dependency>
<groupId>com.asposegroupId>
<artifactId>aspose-cellsartifactId>
<version>23.1version>
dependency>
<dependency>
<groupId>com.asposegroupId>
<artifactId>aspose-slidesartifactId>
<version>23.1version>
dependency>
2 、poi + pdfbox
因为aspose和spire虽然好用,但是都是是商用组件,所以这里也提供使用开源库操作的方式的方式。
POI是Apache软件基金会用Java编写的免费开源的跨平台的 Java API,Apache POI提供API给Java程序对Microsoft Office格式档案读和写的功能。
Apache PDFBox是一个开源Java库,支持PDF文档的开发和转换。 使用此库,您可以开发用于创建,转换和操作PDF文档的Java程序。
需要在项目的pom文件里添加如下依赖
<dependency>
<groupId>org.apache.pdfboxgroupId>
<artifactId>pdfboxartifactId>
<version>2.0.4version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>5.2.0version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>5.2.0version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-scratchpadartifactId>
<version>5.2.0version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-excelantartifactId>
<version>5.2.0version>
dependency>
3 spire
spire一款专业的Office编程组件,涵盖了对Word、Excel、PPT、PDF等文件的读写、编辑、查看功能。spire提供免费版本,但是存在只能导出前3页以及只能导出前500行的限制,只要达到其一就会触发限制。需要超出前3页以及只能导出前500行的限制的这需要购买付费版(尊重版权,远离破解版)。这里使用免费版进行演示。
spire在添加pom之前还得先添加maven仓库来源
<repository>
<id>com.e-iceblueid>
<name>e-icebluename>
<url>https://repo.e-iceblue.cn/repository/maven-public/url>
repository>
接着在项目的pom文件里添加如下依赖
免费版:
<dependency>
<groupId>e-icebluegroupId>
<artifactId>spire.office.freeartifactId>
<version>5.3.1version>
dependency>
付费版版:
<dependency>
<groupId>e-icebluegroupId>
<artifactId>spire.officeartifactId>
<version>5.3.1version>
dependency>
二、将文件转换成图片,并生成到本地
1、将word文件转成图片
(1)使用aspose
public static void wordToImage(String wordPath, String imagePath) throws Exception {
Document doc = new Document(wordPath);
File file = new File(wordPath);
String filename = file.getName();
String pathPre = imagePath + File.separator + filename.substring(0, filename.lastIndexOf("."));
for (int i = 0; i < doc.getPageCount(); i++) {
Document extractedPage = doc.extractPages(i, 1);
String path = pathPre + (i + 1) + ".png";
extractedPage.save(path, SaveFormat.PNG);
}
}
验证结果:
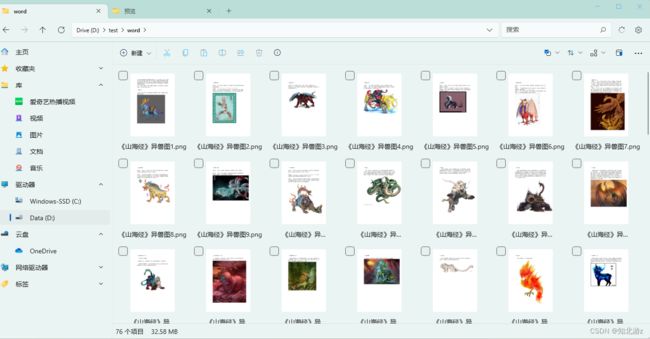
(2)使用pdfbox
word转图片没找到特别好的免费方案,只能先转pdf,再转图片。。。
public void wordToImage(String wordPath, String imagePath) throws Exception {
imagePath = FileUtil.getNewFileFullPath(wordPath, imagePath, "png");
try(FileInputStream fileInputStream = new FileInputStream(wordPath);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()){
XWPFDocument document = new XWPFDocument(fileInputStream);
PdfOptions pdfOptions = PdfOptions.create();
PdfConverter.getInstance().convert(document, byteArrayOutputStream, pdfOptions);
document.close();
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray());
PDDocument doc = PDDocument.load(byteArrayInputStream);
PDFRenderer renderer = new PDFRenderer(doc);
for (int i = 0; i < doc.getNumberOfPages(); i++) {
BufferedImage image = renderer.renderImageWithDPI(i, 144); // Windows native DPI
String pathname = imagePath + (i + 1) + ".png";
ImageIO.write(image, "PNG", new File(pathname));
}
doc.close();
}
}
验证结果:
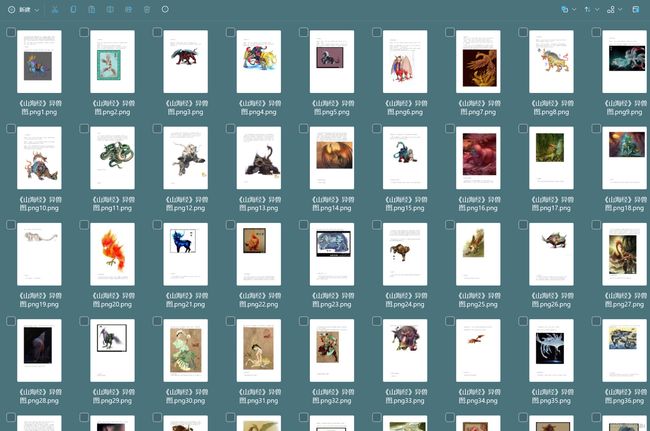
(3)使用spire
public void wordToImage(String wordPath, String imagePath) throws Exception {
File file = new File(wordPath);
String filename = file.getName();
String pathPre = imagePath + File.separator + filename.substring(0, filename.lastIndexOf("."));
//加载Word文档
Document document = new Document();
document.loadFromFile(wordPath);
//将Word文档转换为图片
BufferedImage[] images = document.saveToImages(0, document.getPageCount()-1, ImageType.Bitmap);
//保存图片
for (int i = 0; i < images.length; i++) {
String pathname = pathPre + (i + 1) + ".png";
ImageIO.write(images[i], "PNG", new File(pathname));
}
}
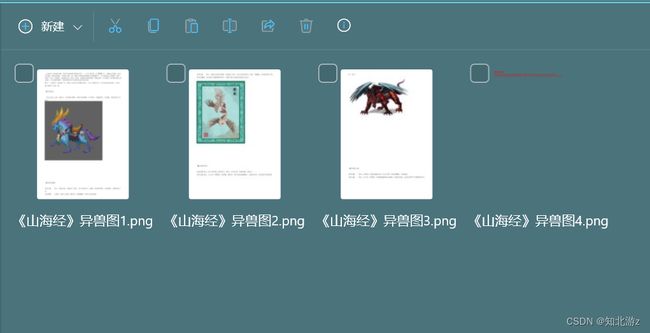
验证结果:
因为使用的是免费版,所以只能生成前三页。。。有超过三页需求的可以选择付费版本。
2、将txt文件转成图片(同word文件转成图片)
(1)使用aspose
public static void txtToImage(String txtPath, String imagePath) throws Exception {
wordToImage(txtPath, imagePath);
}
验证:
public static void main(String[] args) throws Exception {
FileConvertUtil.wordToImage("D:\\书籍\\电子书\\其它\\《山海经》异兽图.doc", "D:\\test\\word");
}
验证结果:

3、将pdf文件转图片
(1)使用aspose
public static void pdfToImage(String pdfPath, String imagePath) throws Exception {
File file = new File(pdfPath);
String filename = file.getName();
String pathPre = imagePath + File.separator + filename.substring(0, filename.lastIndexOf("."));
PDDocument doc = PDDocument.load(file);
PDFRenderer renderer = new PDFRenderer(doc);
for (int i = 0; i < doc.getNumberOfPages(); i++) {
BufferedImage image = renderer.renderImageWithDPI(i, 144); // Windows native DPI
String pathname = pathPre + (i + 1) + ".png";
ImageIO.write(image, "PNG", new File(pathname));
}
doc.close();
}
验证:
public static void main(String[] args) throws Exception {
FileConvertUtil.pdfToImage("D:\\书籍\\电子书\\其它\\自然哲学的数学原理.pdf", "D:\\test\\pdf");
}
验证结果:
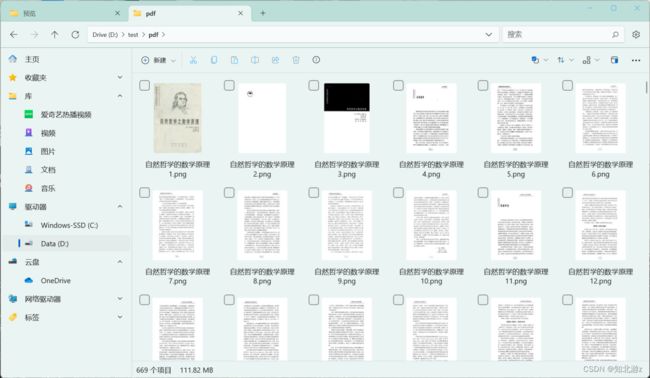
(2)使用pdfbox
public void pdfToImage(String pdfPath, String imagePath) throws Exception {
String pathPre = FileUtil.getNewMultiFileFullPathPre(pdfPath, imagePath);
PDDocument doc = PDDocument.load(new File(pdfPath));
PDFRenderer renderer = new PDFRenderer(doc);
for (int i = 0; i < doc.getNumberOfPages(); i++) {
BufferedImage image = renderer.renderImageWithDPI(i, 144); // Windows native DPI
String pathname = pathPre + (i + 1) + ".png";
ImageIO.write(image, "PNG", new File(pathname));
}
doc.close();
}
验证结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q7MYkt4t-1688054753134)(D:\文章\预览\预览1转图片\pic\pdf转图片pdfbox.png)]
(3)使用spire
public void pdfToImage(String pdfPath, String imagePath) throws Exception {
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile(pdfPath);
File file = new File(pdfPath);
String filename = file.getName();
String pathPre = imagePath + File.separator + filename.substring(0, filename.lastIndexOf("."));
for (int i = 0; i < pdf.getPages().getCount(); i++) {
BufferedImage image = pdf.saveAsImage(i);
String pathname = pathPre + (i + 1) + ".png";
ImageIO.write(image, "png", new File(pathname));
}
}
验证结果:
因为使用的是免费版,所以只有前三页是正常的。。。有超过三页需求的可以选择付费版本。
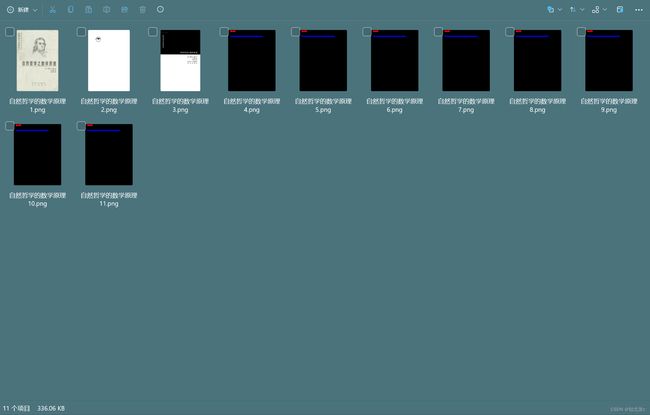
4、将ppt文件转图片
(1)使用aspose
public void pptToImage(String pptPath, String imagePath) throws Exception {
File file = new File(pptPath);
String filename = file.getName();
String pathPre = imagePath + File.separator + filename.substring(0, filename.lastIndexOf("."));
Presentation presentation = new Presentation(pptPath);
for (int i = 0; i < presentation.getSlides().size(); i++) {
ISlide slide = presentation.getSlides().get_Item(i);
BufferedImage image = slide.getThumbnail(1f, 1f);
String path = pathPre + (i + 1) + ".png";
ImageIO.write(image, "png", new File(path));
}
}
验证结果:
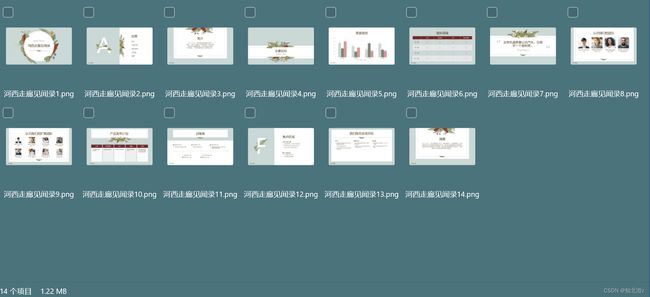
(2)使用pdfbox
public void pptToImage(String pptPath, String imagePath) throws Exception {
File file = new File(pptPath);
String filename = file.getName().substring(0, file.getName().lastIndexOf("."));
List<BufferedImage> images = pptToBufferedImages(pptPath);
String dicPath = imagePath + File.separator + filename;
File dic = new File(dicPath);
if (!dic.exists()) {
dic.mkdir();
}
for (int i = 0; i < images.size(); i++) {
BufferedImage image = images.get(i);
String path = dicPath+ File.separator + filename + (i + 1) + ".png";
ImageIO.write(image, "png", new File(path));
}
}
验证结果:
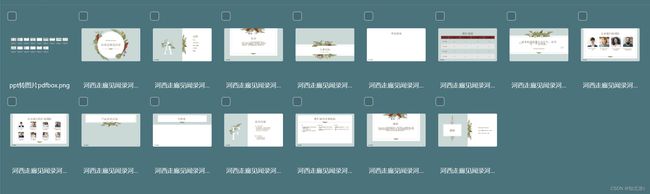
(3)使用spire
验证结果:
免费版ppt转图片生成前10页,有进步。。。有超过10页需求的可以选择付费版本。

三、利用多线程提升文件写入本地的效率
在将牛顿大大的长达669页的巨作《自然哲学的数学原理》时发现执行时间较长,执行花了140,281ms。但其实这种IO密集型的操作是通过使用多线程的方式来提升效率的,于是针对这点,我又写了一版多线程的版本。
同步执行导出 自然哲学的数学原理.pdf 耗时:

优化后的代码如下:
public static void pdfToImageAsync(String pdfPath, String imagePath) throws Exception {
long old = System.currentTimeMillis();
File file = new File(pdfPath);
PDDocument doc = PDDocument.load(file);
PDFRenderer renderer = new PDFRenderer(doc);
int pageCount = doc.getNumberOfPages();
int numCores = Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(numCores);
for (int i = 0; i < pageCount; i++) {
int finalI = i;
executorService.submit(() -> {
try {
BufferedImage image = renderer.renderImageWithDPI(finalI, 144); // Windows native DPI
String filename = file.getName();
filename = filename.substring(0, filename.lastIndexOf("."));
String pathname = imagePath + File.separator + filename + (finalI + 1) + ".png";
ImageIO.write(image, "PNG", new File(pathname));
} catch (Exception ex) {
ex.printStackTrace();
}
});
}
executorService.shutdown();
executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
doc.close();
long now = System.currentTimeMillis();
System.out.println("pdfToImage 多线程 转换完成..用时:" + (now - old) + "ms");
}
多线程执行导出 自然哲学的数学原理.pdf 耗时如下:

从上图可以看到本次执行只花了24045ms,只花了原先差不多六分之一的时间,极大地提升了执行效率。除了pdf,word、txt转图片也可以做这样的多线程改造:
//将word转成图片(多线程)
public static void wordToImageAsync(String wordPath, String imagePath) throws Exception {
Document doc = new Document(wordPath);
File file = new File(wordPath);
String filename = file.getName();
String pathPre = imagePath + File.separator + filename.substring(0, filename.lastIndexOf("."));
int numCores = Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(numCores);
for (int i = 0; i < doc.getPageCount(); i++) {
int finalI = i;
executorService.submit(() -> {
try {
Document extractedPage = doc.extractPages(finalI, 1);
String path = pathPre + (finalI + 1) + ".png";
extractedPage.save(path, SaveFormat.PNG);
} catch (Exception ex) {
ex.printStackTrace();
}
});
}
}
//将txt转成图片(多线程)
public static void txtToImageAsync(String txtPath, String imagePath) throws Exception {
wordToImageAsync(txtPath, imagePath);
}
四、将文件转换成图片流
有的时候我们转成图片后并不需要在本地生成图片,而是需要将图片返回或者上传到图片服务器,这时候就需要将转换后的图片转成流返回以方便进行传输,代码示例如下:
1、将word文件转成图片流
(1)使用aspose
public static List<byte[]> wordToImageStream(String wordPath) throws Exception {
Document doc = new Document(wordPath);
List<byte[]> list = new ArrayList<>();
for (int i = 0; i < doc.getPageCount(); i++) {
try(ByteArrayOutputStream outputStream = new ByteArrayOutputStream()){
Document extractedPage = doc.extractPages(i, 1);
extractedPage.save(outputStream, SaveFormat.*PNG*);
list.add(outputStream.toByteArray());
}
}
return list;
}
(2)使用pdfbox
public List<byte[]> wordToImageStream(String wordPath) throws Exception {
List<BufferedImage> images = new ArrayList<>();
try(FileInputStream fileInputStream = new FileInputStream(wordPath);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()){
XWPFDocument document = new XWPFDocument(fileInputStream);
PdfOptions pdfOptions = PdfOptions.create();
PdfConverter.getInstance().convert(document, byteArrayOutputStream, pdfOptions);
document.close();
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray());
PDDocument doc = PDDocument.load(byteArrayInputStream);
PDFRenderer renderer = new PDFRenderer(doc);
for (int i = 0; i < doc.getNumberOfPages(); i++) {
BufferedImage image = renderer.renderImageWithDPI(i, 144); // Windows native DPI
images.add(image);
}
doc.close();
}
return images.stream().map(image-> {
try {
return FileUtil.imageToByte(image);
} catch (IOException e) {
throw new RuntimeException(e);
}
}).collect(Collectors.toList());
}
(3)使用spire
public List<byte[]> wordToImageStream(String wordPath) throws Exception {
Document document = new Document();
document.loadFromFile(wordPath);
BufferedImage[] bufferedImages = document.saveToImages(ImageType.Bitmap);
return FileUtil.toByteArrays(bufferedImages);
}
2、将txt文件转成图片流
(1)使用aspose
public static List<byte[]> txtToImageStream(String txtPath) throws Exception {
return *wordToImagetream*(txtPath);
}
3、将pdf转成图片流
(1)使用aspose
public static List<byte[]> pdfToImageStream(String pdfPath) throws Exception {
File file = new File(pdfPath);
PDDocument doc = PDDocument.*load*(file);
PDFRenderer renderer = new PDFRenderer(doc);
List<byte[]> list = new ArrayList<>();
for (int i = 0; i < doc.getNumberOfPages(); i++) {
try(ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
BufferedImage image = renderer.renderImageWithDPI(i, 144); // Windows native DPI
ImageIO.*write*(image, "PNG", outputStream);
list.add(outputStream.toByteArray());
}
}
doc.close();
return list;
}
(2)使用pdfbox
public List<byte[]> pdfToImageStream(String pdfPath) throws Exception {
File file = new File(pdfPath);
PDDocument doc = PDDocument.load(file);
PDFRenderer renderer = new PDFRenderer(doc);
List<byte[]> list = new ArrayList<>();
for (int i = 0; i < doc.getNumberOfPages(); i++) {
try (ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
BufferedImage image = renderer.renderImageWithDPI(i, 144); // Windows native DPI
ImageIO.write(image, "PNG", outputStream);
list.add(outputStream.toByteArray());
}
}
doc.close();
return list;
}
(3)使用spire
public List<byte[]> pdfToImageStream(String pdfPath) throws Exception {
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile(pdfPath);
File file = new File(pdfPath);
String filename = file.getName();
List<byte[]> list = new ArrayList<>();
for (int i = 0; i < pdf.getPages().getCount(); i++) {
BufferedImage image = pdf.saveAsImage(i);
list.add(FileUtil.imageToByte(image));
}
return list;
}
4、将ppt文件转图片流
(1)使用aspose
public List<byte[]> pptToImageStream(String pptPath) throws IOException {
List<byte[]> list = new ArrayList<>();
Presentation presentation = new Presentation(pptPath);
for (int i = 0; i < presentation.getSlides().size(); i++) {
ISlide slide = presentation.getSlides().get_Item(i);
BufferedImage image = slide.getThumbnail(1f, 1f);
byte[] bytes = FileUtil.imageToByte(image);
list.add(bytes);
}
return list;
}
(2)使用pdfbox
public List<byte[]> pptToImageStream(String pptPath) throws IOException {
List<BufferedImage> images = pptToBufferedImages(pptPath);
if(CollectionUtils.isEmpty(images)){
return null;
}
return images.stream().map(image-> {
try {
return FileUtil.imageToByte(image);
} catch (IOException e) {
throw new RuntimeException(e);
}
}).collect(Collectors.toList());
}
(3)使用spire
public List<byte[]> pptToImageStream(String pptPath) throws Exception {
List<byte[]> list = new ArrayList<>();
Presentation presentation = new Presentation();
presentation.loadFromFile(pptPath);
for (int i = 0; i < presentation.getSlides().getCount(); i++) {
BufferedImage image = presentation.getSlides().get(i).saveAsImage();
list.add(FileUtil.imageToByte(image));
}
return list;
}
总结
将文件转成图片实现预览的这种方式的优点是:
1、图片在线预览控件比较多,也比较成熟,前端起来比较方便
2、文档转成图片后能有效减少文档内容被复制的情况
3、浏览器也天然支持
这种方式的缺点是:
1、文档往往都不只一页,所有同城的做法将文档的每一页都生成一张图片,所以前后端都需要考虑处理多张图片的问题
2、如果图片都以base64的格式返回给前端,会造成返回体过大的问题,如果返回有加日志还会存在日志体较长,增加日志服务器的问题。
3、因为base64的格式直接返回返回体过长,好一点的做法现将图片上传到图片服务器,只返回图片的url,这样解决了图片返回体过长的问题,但要先将多张图片先上传到图片服务器,这样会不可避免的拖慢接口的返回速度,尤其是在文档页数较多的时候,同时也会增加图片服务器的压力。
解决多图片展示问题的解决方案:
应该如何解决多图片展示问题呢,其实很简单,可以参考开源组件kkfileview解决多图片展示问题的(都参考了为什么不直接拿来用,滑稽表情)的做法,即将生成的多张图片全都放到一个html页面里,用html保持样式并实现多张图片展示,再将html返回。
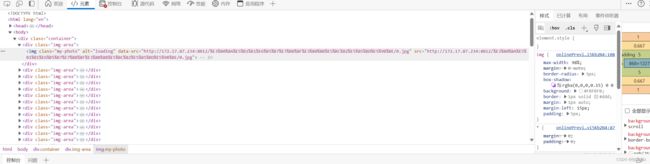
kkfileview展示效果如下:

下图是kkfileview返回的html代码,从html代码我们可以看到kkfileview其实是将文件(txt文件除外)每页的内容都转成了图片,然后将这些图片都嵌入到一个html里,再返回给用户一个html页面。