全网小说下载器,只需书名,一键下载(Python爬虫+tkinter 实现)小白实战案例系统教学!
大家好,我是小曼呐

前言
ttkbootstrap是一个基于Python的开源库,用于创建漂亮且交互式的GUI应用程序。它是在Tkinter框架之上构建的,提供了一系列的Widget组件和样式,可以帮助开发者快速构建现代化的用户界面。
今天做的是这个东西,蓝色的是进度条
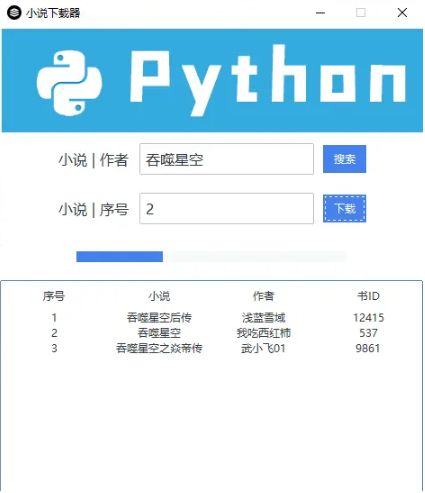
获取数据代码(附上代码)
def get_response(html):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
response = requests.get(url=html, headers=headers)
return response
源码、解答、教程、安装包等资料加V:xiaoyuanllsll 发送验证时记得备注 “M”噢
def search(key):
search_url = f'https://www.xzmncy.com/api/search?q={key}'
search_data = get_response(search_url).json()
search_info = []
num = 1
for index in search_data['data']['search']:
dit = {
'num': num,
'name': index['book_name'],
'author': index['author'],
'book': index['book_list_url'].split('/')[-2],
}
search_info.append(dit)
num += 1
return search_info
def get_info(book):
link = f'https://www.xzmncy.com/list/{book}/'
link_data = get_response(link).text
link_selector = parsel.Selector(link_data)
href = link_selector.css('#list dd a::attr(href)').getall()
href = ['https://www.xzmncy.com' + i for i in href]
return href
def get_content(html):
html_data = get_response(html).text
selector = parsel.Selector(html_data)
title = selector.css('.bookname h1::text').get()
content_list = selector.css('#htmlContent p::text').getall()
content = '\n'.join(content_list)
return title, content
def save(name, title, content):
with open(name+'.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
界面显示
所需模块
import ttkbootstrap as ttk
from PIL import ImageTk, Image
from download import *
from ttkbootstrap.dialogs import Messagebox
实例化创建应用程序窗口
root = ttk.Window(
title="小说下载器", # 设置窗口的标题
themename="litera", # 设置主题
size=(470, 520), # 窗口的大小
position=(100, 100), # 窗口所在的位置
minsize=(0, 0), # 窗口的最小宽高
maxsize=(1920, 1080), # 窗口的最大宽高
resizable=None, # 设置窗口是否可以更改大小
alpha=1.0, # 设置窗口的透明度(0.0完全透明)
)
ico = ImageTk.PhotoImage(Image.open("python.ico"))
root.iconphoto(False, ico)
root.place_window_center() #让显现出的窗口居中
root.resizable(False, False) # 让窗口不可更改大小
root.mainloop()

搜索框
image = Image.open("img\\123123.png")
photo = ImageTk.PhotoImage(image)
ttk.Label(root, image=photo).pack()
key_input_frame = ttk.Frame()
key_input_frame.pack(pady=10)
key_input_key_va = ttk.StringVar()
ttk.Label(key_input_frame, text='小说 | 作者', font=('微软雅黑', 12)).pack(side=ttk.LEFT)
ttk.Entry(key_input_frame, textvariable=key_input_key_va, font=('微软雅黑', 12)).pack(side=ttk.LEFT, padx=10,fill=ttk.BOTH)
num_input_frame = ttk.Frame()
num_input_frame.pack(pady=10)
num_input_key_va = ttk.StringVar()
ttk.Label(num_input_frame, text='小说 | 序号', font=('微软雅黑', 12)).pack(side=ttk.LEFT)
ttk.Entry(num_input_frame, textvariable=num_input_key_va, font=('微软雅黑', 12)).pack(side=ttk.LEFT, padx=10,fill=ttk.BOTH)
frame = ttk.Frame()
frame.pack(fill=ttk.BOTH)

按钮和进度条
ttk.Button(key_input_frame, text='搜索').pack(side=ttk.LEFT)
ttk.Button(num_input_frame, text='下载').pack(side=ttk.LEFT)
progress_bar = ttk.Progressbar(frame, orient='horizontal', length=300, mode='determinate')
progress_bar.pack(pady=20)
显示搜索到的书名、作者等
# 1. 创建字段
columns = ("num", "name", "author", "book")
columns_value = ('序号', '小说', '作者', '书ID')
# 2. 创建表格对象
tree_view = ttk.Treeview(root, show="headings", columns=columns)
# 3. 给表格添加字段名
tree_view.column('num', width=80, anchor='center')
tree_view.column('name', width=80, anchor='center')
tree_view.column('author', width=80, anchor='center')
tree_view.column('book', width=80, anchor='center')
# 4. 设置字段在页面上显示的内容
tree_view.heading('num', text='序号')
tree_view.heading('name', text='小说')
tree_view.heading('author', text='作者')
tree_view.heading('book', text='书ID')
# 5. 将表格对象布局到页面上
tree_view.pack(fill=ttk.BOTH, expand=True)

搜索功能设置
def show():
key = key_input_key_va.get()
search_info = search(key)
# 6. 往表格中添加数据
for index, stu in enumerate(search_info):
tree_view.insert('', index + 1, values=(
stu['num'], str(stu['name']), str(stu['author']), str(stu['book'])))
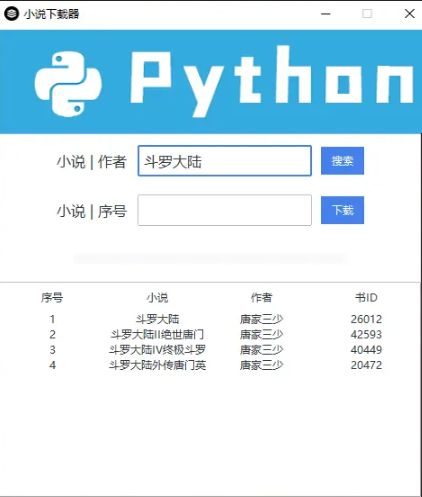
最后运行效果
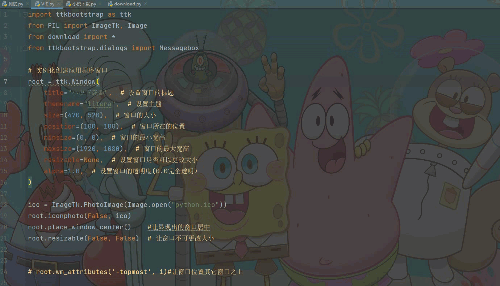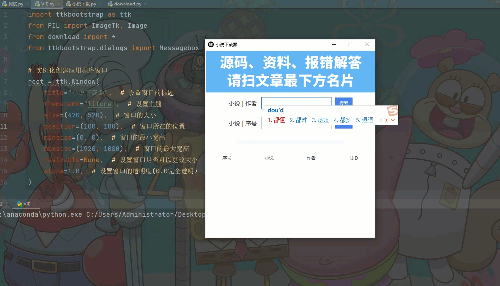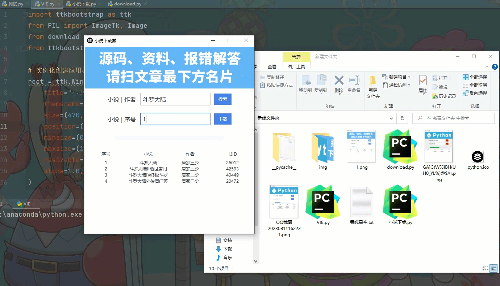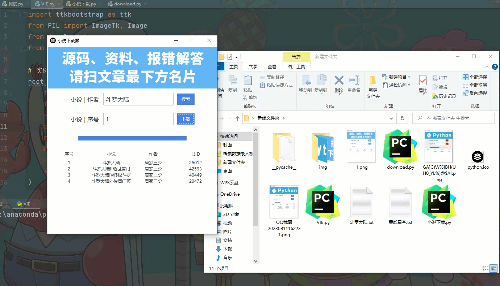
python打造小说下载软件,全网小说一键下载,在线阅读 无水印(附源码)