kallsyms 内核符号表
kallsyms 内核符号表
文章目录
- kallsyms 内核符号表
-
- 生成`kallsyms`
-
- 脚本执行过程
-
- 两次`kallsyms`
- `vmlinux_link`过程
- 三次`ld`
- 程序运行过程
-
- 读标准输入中的符号信息
- 对`percpu`段内容进行修正
- 寻找相对符号的基地址
- 符号排序
- 优化符号表
-
- 生成token表
-
- 字符串学习过程 -- 统计两个字符组合出现的频率
- 生成best表 -- 统计单个字符是否有出现
- 优化符号表算法
-
- 压缩字符串
- 写入符号表
-
- 写入相对于基地址的数据
- 写入符号表个数以及快速查找标记
- 写入字符串查找表
- 内核的`kallsyms`
-
- 根据序号找到符号在字符串压缩流中的位置
- 获取符号的类型及字符串名字
-
- 获得偏移所在的压缩字符串流中的符号类型
-
- 扩展压缩字符串流得到真实的字符串符号
- 一些辅助函数
-
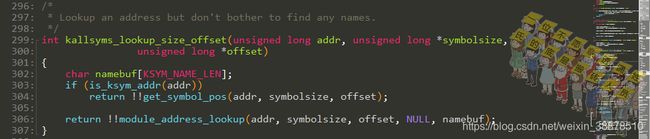
- `__sprint_symbol()`根据输入的地址打印符号
- `kallsyms_lookup_name()`根据输入的名字查看符号地址
- 遍历所有符号执行某些动作
- 判断地址是否在符号表中
个人认为本文的核心部分:
- [两次
kallsyms](# 两次kallsyms)的二次执行kallsyms工具 - [三次
ld](# 三次ld)链接vmlinux的三次链接过程 - [压缩字符串](# 压缩字符串)压缩字符串的算法
__sprint_symbol()根据输入的地址打印符号内核常用的打印符号函数
总结在前面,kallsyms生成的三个元素组合:
-
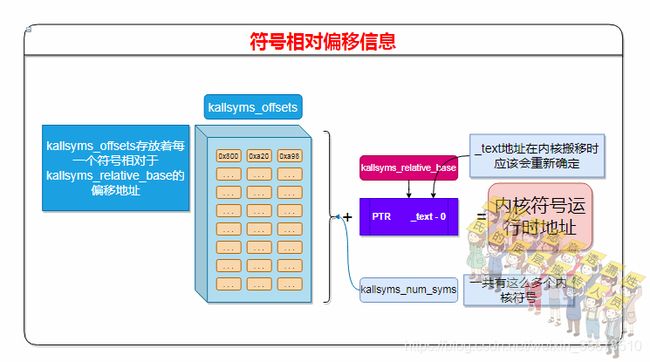
符号相对偏移信息:在内核运行时,会存在内核镜像从底地址搬移到高地址的过程,搬移后内核相对符号的地址与链接时的地址是不一致的,这里记录相对偏移地址是方便符号在运行时实际的地址获取。
kallsyms_offsets记录着每一个符号的偏移量,kallsyms_relative_base则记录着偏移的基地址。
-
符号压缩流信息:在生成符号信息时,如果对所有字符串进行记录,会比较浪费空间。所以内核开发人员想出了压缩字符串的办法。将频次出现较高的字符串存放在
kallsyms_token_table表中,kallsyms_names存放这len+data格式的压缩后数据,kallsyms_num_syms存放着内核符号的个数。为了加快符号的查找,每256个压缩数据记录一下在整个压缩流中的偏移,记录在kallsyms_markers中,方便后续查找。

-
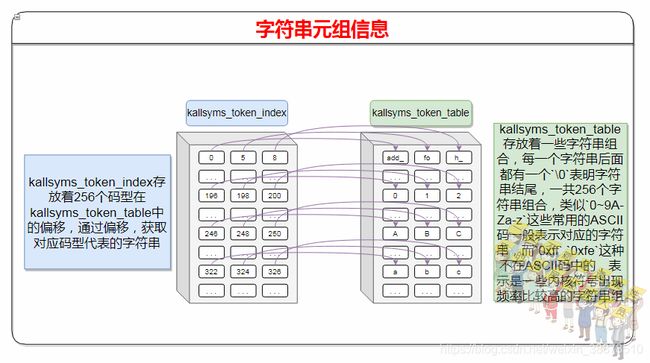
字符串元组信息:
kallsyms_token_table存放这除了ascii可打印的字符串外,还将0xff,0xfe等一些不出现在ascii码中的码型代表一些特殊的字符串。kallsyms_token_index则表明每一个码型在整个字符串元组中的偏移。
所以
- 查找符号地址:第n个符号,则从符号相对偏移信息
kallsyms_offsets中获取第n个数据,加上偏移基地址kallsyms_relative_base,即可获取运行时地址。 - 获取符号类型以及符号字符串:第n个符号,使用
kallsyms_markers快速查找在偏移中的位置,再遍历里面的256个中的某一个,获取压缩后的字符串数据(data通过kallsyms_token_table和kallsyms_token_index扩展后,第一个字符是符号的类型(T,A,U等等),剩下的就是符号的字符串。
生成kallsyms
脚本执行过程
先看scripts/link-vmlinux.sh脚本,里面解释了这个kallsyms的生成过程:
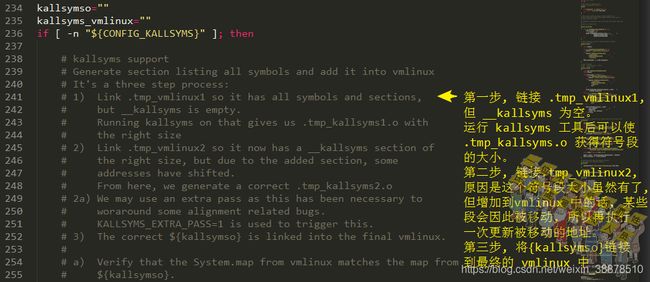
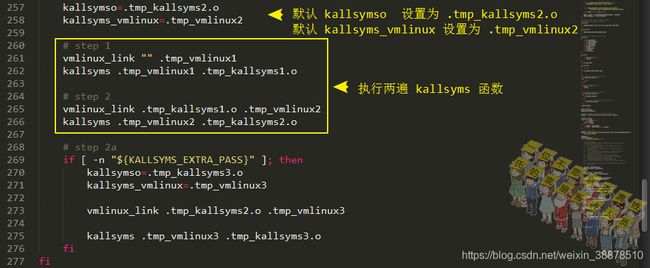
两次kallsyms
看编译过程的日志的话也是可以看到scripts/kallsyms执行了两次的:
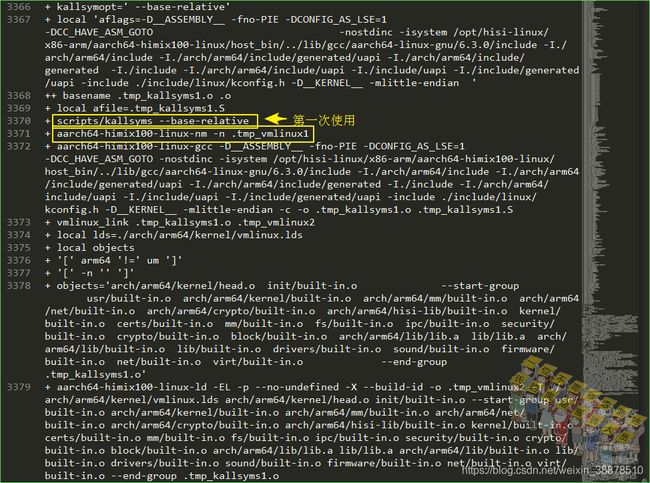

vmlinux_link过程
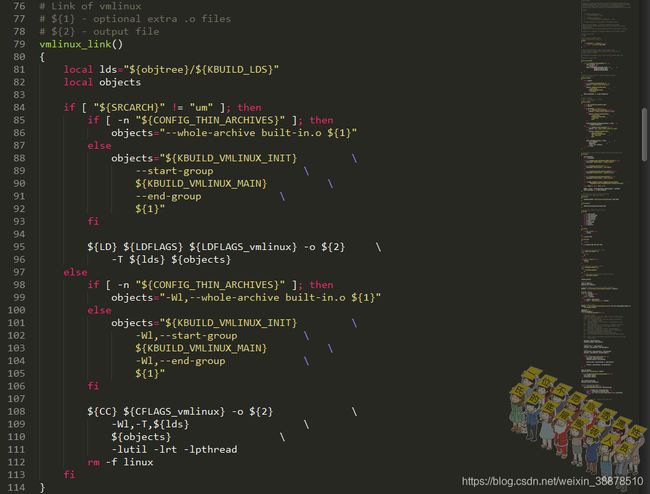
接下来看一下具体的过程,执行kallsyms()前先执行了vmlinux_link(),看一下vmlinux_link():
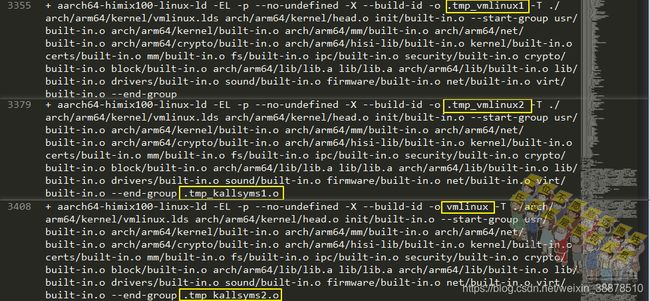
这个直接看日志更直接,第一次vmlinux_link()的参数是'' .tmp_vmlinux1,第二次vmlinux_link()的参数是.tmp_kallsyms2.o vmlinux。
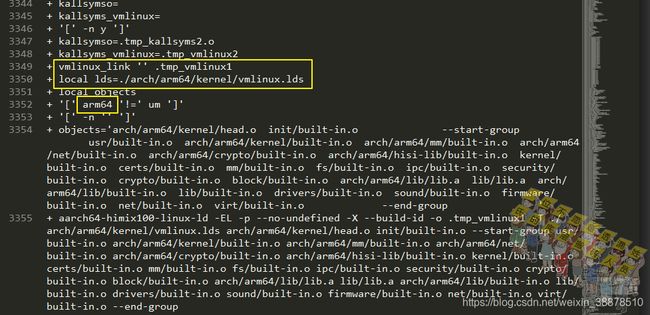
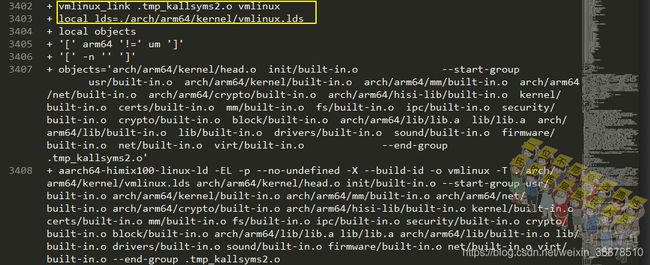
kallsyns()函数最后是通过nm -n工具读取符号表信息,然后通过管道给kallsyms这个程序去处理符号信息,第一次实际执行的是aarch64-himix100-linux-nm -n .tmp_vmlinux1,第二次执行是的aarch64-himix100-linux-nm -n .tmp_vmlinux2。aarch64-himix100-linux-nm -n是按地址排序好的符号信息。
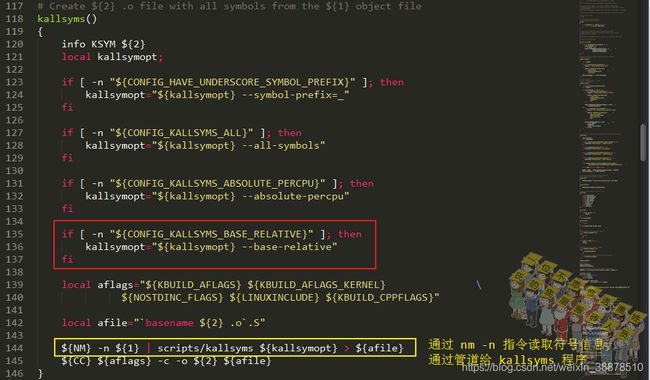
三次ld
生成.tmp_kallsyms1.S或.tmp_kallsyms2.S文件后,生成对应的.tmp_kallsyms1.o或.tmp_kallsyms2.o,再通过链接器重新连接一下生成tmp_kallsyms1或tmp_kallsyms2,最后再链接成vmlinux文件。
看编译记录,是三次链接过程:
程序运行过程
main()函数中,先对输入参数进行判断,这里走的分支是--base-relative分支,

读标准输入中的符号信息
在前面可以看到,标准输入的内容是通过aarch64-himix100-linux-nm -n .tmp_vmlinux1或aarch64-himix100-linux-nm -n .tmp_vmlinux2来的:
读符号信息:
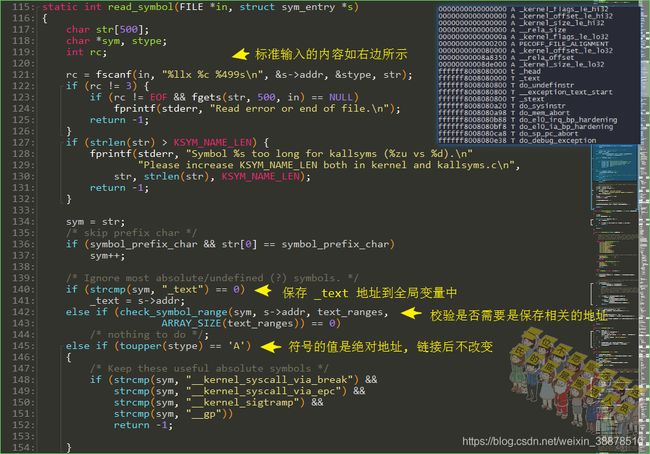
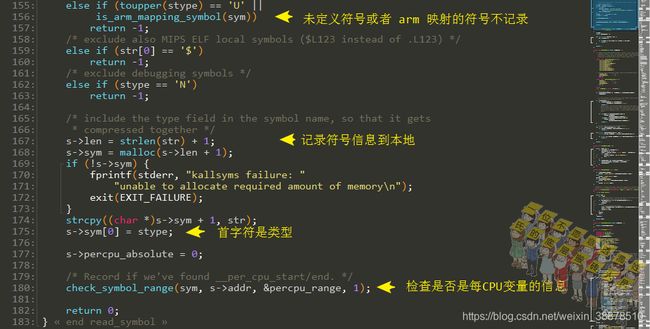
检查是否是一些段的开始和结束地址,如果是的话将这个地址进行记录:

这个addr_range就是一个首地址标志名称和地址、结束标志名称及长度组成。

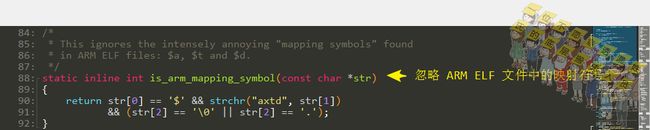
判断是否是ARM-ELF的符号:
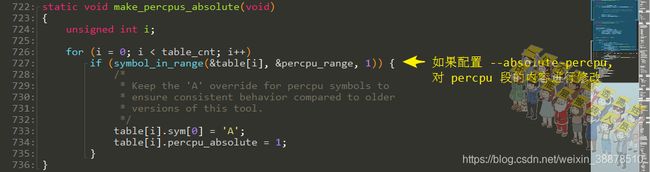
对percpu段内容进行修正
如果配置了--absolute-percpu,那么将会对percpu端的内容进行修正:
寻找相对符号的基地址
遍历符号表,找到相对地址符号的基地址:
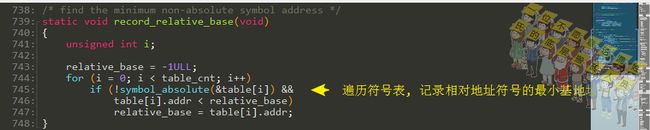
判断的依据是percpu_absolute是否被设置:

符号排序
对符号进行排序:
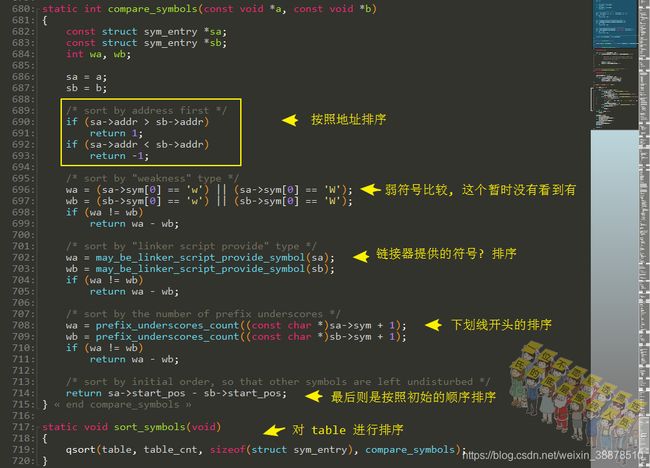
猜测是否是链接器脚本提供的符号:

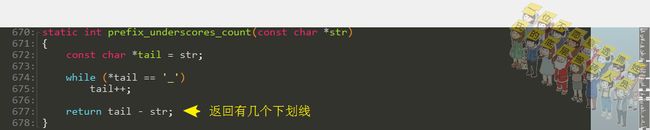
计算有几个下划线:
优化符号表

生成token表
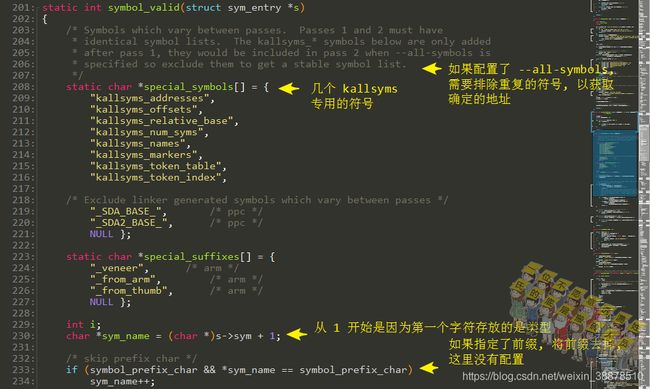
对table里面的字符串进行有效判断,并对字符串进行一个“学习”,记录字符串中两个连续的字符组合出现的频率:

判断符号是否有效:

字符串学习过程 – 统计两个字符组合出现的频率
学习符号表的过程:统计两个字符组合出现的频率。
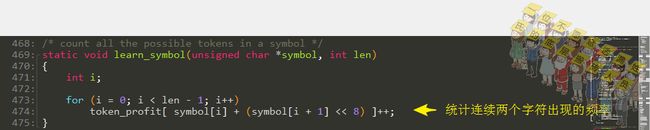
token_profit是一个0x10000长度的数组:
int token_profit[0x10000];从上面的learn_symbol()代码单独拿出来,写一个测试代码看看:
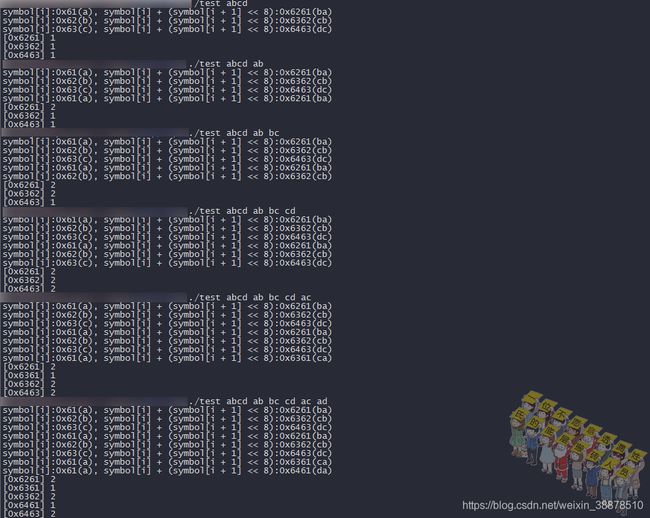
可以看到就是对连续两个字符出现的频率进行统计,所以0x10000这个数组不会越界(连续两个ASCII码最大只能是0xffff)。但为什么第二个字符左移而不是第一个字符左移,还需要再看看。
生成best表 – 统计单个字符是否有出现
遍历检查过后的字符串表,再遍历字符串中的每一个字符,然后这个赋值我就没有看懂了。。。为什么每一次都给这个c赋值到best_table中,那不就覆盖了吗?而且best_table_len[c]长度永远是1?这样看的话就是统计一下这个字符有没有在字符串表中出现过,比如一下?,!这种,在字符串表中应该是不能出现的。
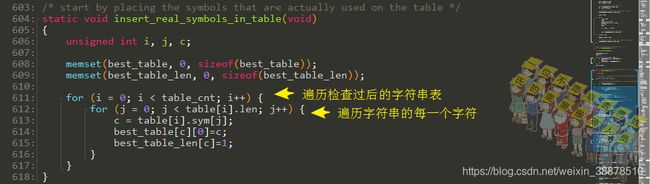
best_table和best_table_len变量入下:
/* the table that holds the result of the compression */
unsigned char best_table[256][2];
unsigned char best_table_len[256];优化符号表算法
这个optimize_result()函数就是核心算法,
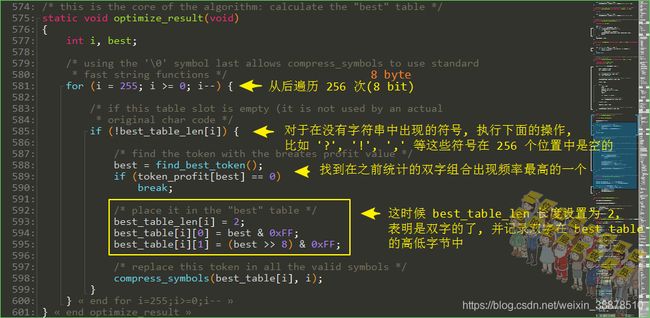
找到出现频率最高的双字组合:遍历 token_profit, 找到出现频率最高的一个元组位置,比如内核的 de(vice), qu(eue)等这些双字符组合出现还是很高的。

-script/)]
压缩字符串
这个是压缩字符串的核心算法:
- 输入参数是出现频次最高双字符组合,以及需要替换的在
256 bit中某个位置 - 遍历字符串表,对每一个字符串查找是否存在和输入参数相同的双字符组合
- 对于出现的组合,更新出现频次
- 将字符串中出现的双字符组合替换为输入的参数,即在
256 bit中某个值 - 调整当前字符串,包括移动和长度,重新执行第4步,直到条件不满足

这里假设ue出现频次最高,输入的idx此时是0xfe,那么queue压缩过程是这样的:
queue字符十六进制表现形式是0x71 0x75 0x65 0x75 0x65ueue被分别替换为0xfe 0xfe,此时queue字符串是0x71 0xfe 0xfe,那么就节省了2 byte的空间
在最后输出的.tmp_kallsyms1.S或.tmp_kallsyms2.S文件中,实际的字符串也只有256个,不信你数:

对于里面出现几个字符串一起的,比如queue_,device_,write,ext4,init等,应该都是经过多次压缩的。
看一下压缩过程中用到的find_token()函数:找到在字符串中与 token 双字符组合一样的开始位置。

forget_symbol()函数减少字符串中连续的双字符组合的个数:

写入符号表
打印相关信息到标志输出中,脚本中使用时重定向标志输出到.tmp_kallsyms1.S或.tmp_kallsyms2.S文件中。里面包含头文件、对齐宏、只读的.rodata段声明。

代码中的注释:
通过相对于运行时镜像中的固定锚点的相对性来提供适当的符号可重定位性,对于绝对地址表,可以使用’_text’,在这种情况下,链接器将在构建时发出最终地址。 否则,使用相对于所有相对符号中遇到的最小值的偏移量,并发出不可重定位的固定偏移量,该偏移量将在运行时固定。
符号名称不能用于构造普通的符号引用,因为符号列表包含已声明为静态且对其.o文件私有的符号。 这样可以防止.tmp_kallsyms.o或任何其他对象引用它们。
写入相对于基地址的数据
这里输出的都是相对于前面优化时计算的relative_base基地址的偏移量,这样可以节省不少的空间。

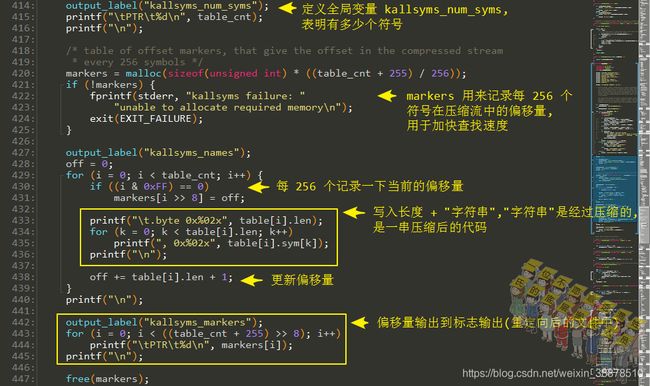
写入符号表个数以及快速查找标记
输出完符号的相对地址后,输出符号的数量,用markers记录每256个符号在压缩流中的偏移地址,用于优化查找速度。
写入字符串查找表
最后将best_table中的代表特殊字符串的数值,比如0xff,0xfe等待这些,恢复回原来的字符串,将字符串输出到标志输出中;最后将查找字符串的偏移量也输出。

看一下都在使用的output_label()函数原型,汇编的.globl声明一个全局变量:
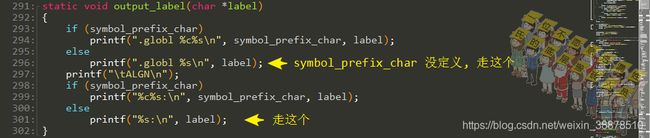
.tmp_kallsyms1.S或.tmp_kallsyms2.S文件中声明的全局变量有这7个,在内核的kallsyms中就会用到这几个变量来查看符号信息:
.globl kallsyms_offsets
.globl kallsyms_relative_base
.globl kallsyms_num_syms
.globl kallsyms_names
.globl kallsyms_markers
.globl kallsyms_token_table
.globl kallsyms_token_index
扩展符号表的过程,一个存在递归的比较难理解的过程:

内核的kallsyms
当前kallsyms配置:
CONFIG_KALLSYMS=y
# CONFIG_KALLSYMS_ALL is not set
# CONFIG_KALLSYMS_ABSOLUTE_PERCPU is not set
CONFIG_KALLSYMS_BASE_RELATIVE=y内核的kallsyms初始化是创建一个proc文件,文件操作集指向kallsyms_operations:

我们执行cat /proc/kallsyms时,执行的函数是kallsyms_open(),里面调用一个__seq_open_private去根据条件遍历,结束后
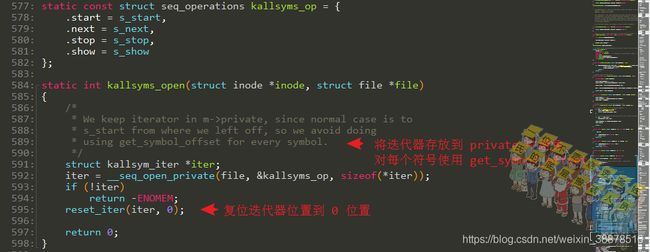
看看一下这个复位迭代器的过程:
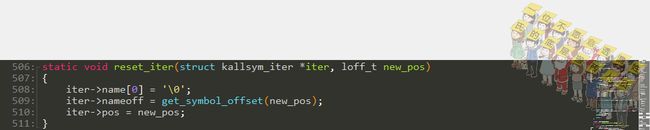
这个迭代器长这个样:
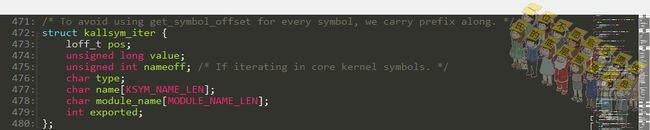
根据序号找到符号在字符串压缩流中的位置
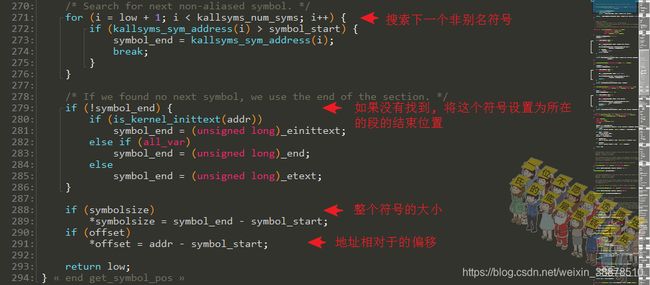
找符号的偏移过程:kallsyms_markers记录了每256个在压缩流中的偏移。比如想找第1000个符号,十六进制是0x3e8,以256个长度为一个单位,那在kallsyms_markers中找到第3(1000/256=3)开始的位置,得到在压缩流kallsyms_names中的起始偏移。kallsyms_names对于每一个字符串记录的形式是长度+字节数据(这里的字节数据并不是实际的字符串名字),根据这个形式,就可以找到想要位置在字符串压缩流中的位置了。

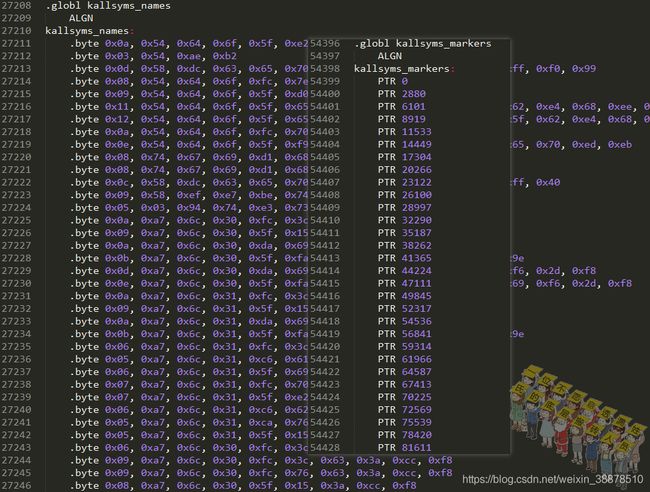
至于里面的kallsyms_names字符串压缩流、kallsyms_markers压缩流快速标记等变量,都是声明的extern,实际是编译过程中加到vmlinux中的,看上面[生成kallsyms](# 生成kallsyms)过程:

kallsyms_names字符串压缩流、kallsyms_markers压缩流快速标记在汇编文件中像下面展示的一样:
接下来看一下遍历打印时用到的kallsyms_op:
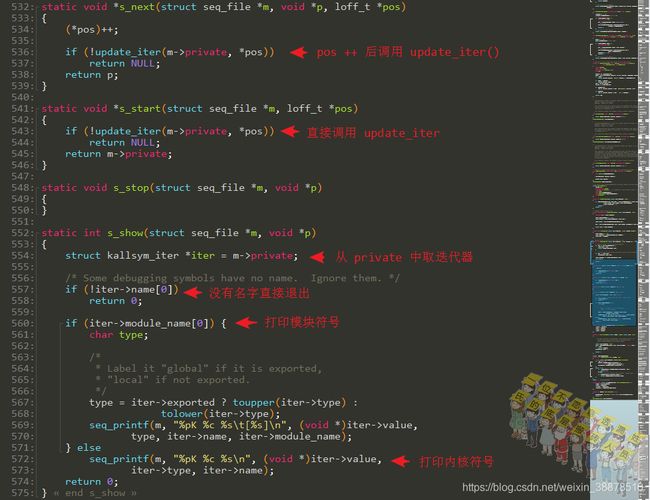
s_start()和s_next()都是调用的update_iter()函数,那看一下这个函数:

获取符号的类型及字符串名字
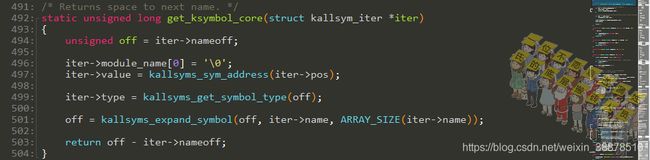
kallsyms_sym_address()返回运行期间的第idx个符号的运行地址:

kallsyms_relative_base记录着相对于_text代码段的地址,因为内核重定向的关系,编译期间的地址和运行期间的地址会不一致,所以kallsyms_relative_base不能直接用绝对地址。kallsyms_offsets则是记录着每一个符号基于这个kallsyms_relative_base的相对偏移地址。
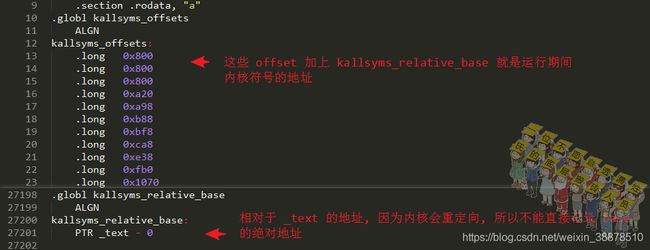
获得偏移所在的压缩字符串流中的符号类型
获得偏移所在的压缩字符串流中的符号类型,在kallsyms工具中,第一个字符是存放的符号类型,且这个符号类型不会被压缩。
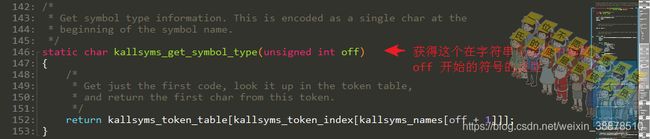
在[根据序号找到符号在字符串压缩流中的位置](# 根据序号找到符号在字符串压缩流中的位置)一节中可以看到kallsyms_names的截图,kallsyms_names[off + 1]是字符串压缩流中基于off偏移的第一个字符。而kallsyms_token_index则代表是在kallsyms_token_table表中的偏移,比如kallsyms_token_index[3]取出来的值是11,那么在kallsyms_token_table表中则表示是字符串tv开始的位置。而比如符号类型是T的话,kallsyms_token_index[T]是284,在kallsyms_token_table的位置是也就是字符T,不信的话就自己再算一下。

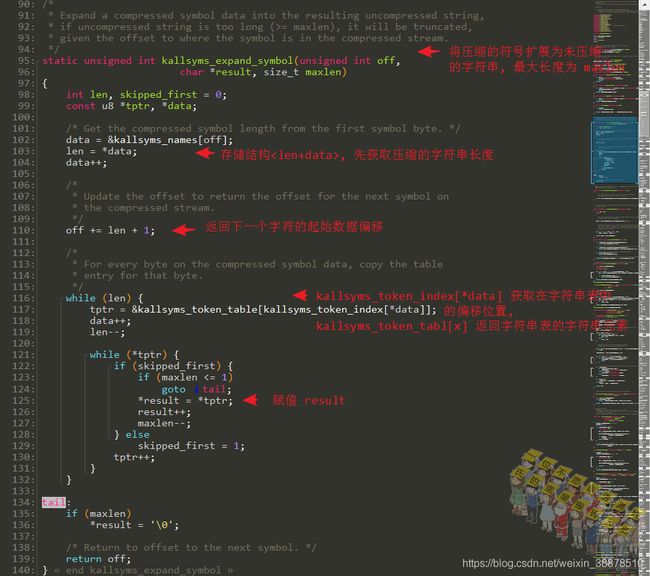
扩展压缩字符串流得到真实的字符串符号
有前面的kallsyms_token_table和kallsyms_token_table基础,那么找到实际真实的符号字符串也就没有难度了。根据存储结构data长度后,找到data里面的每一个byte对应的字符串,最后将结果返回给result。
一些辅助函数
这里代码里面会导出一些辅助函数,这几个函数最后都是调用sprint_symbol()函数或__sprint_symbol()来实现的。
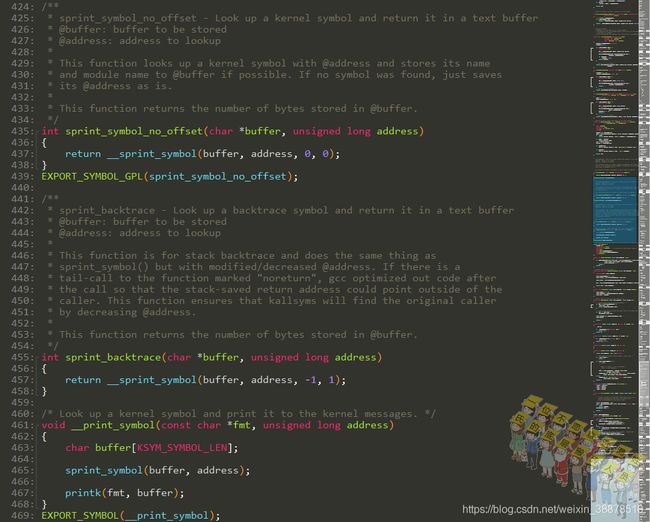
__sprint_symbol()根据输入的地址打印符号
sprint_symbol()函数最后也是调用__sprint_symbol()来实现的,根据输入的地址,找到符号的名字,需要偏移的话加上相关的偏移,如果属于模块,加上模块的名字。

根据地址查找符号:
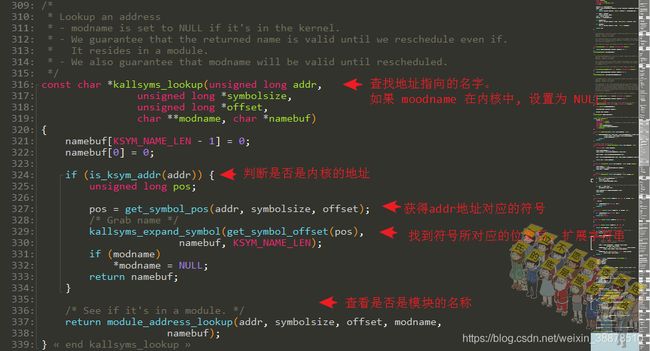
根据地址,使用二分法找到在字符串压缩流中的位置,并找到符号所占的大小以及当前输入地址基于符号起始地址的偏移,最后返回符号在字符串压缩流中的位置。

kallsyms_expand_symbol()看上面[扩展压缩字符串流得到真实的字符串符号](# 扩展压缩字符串流得到真实的字符串符号)章节,kallsyms_sym_address()看上面获取符号的类型及字符串名字章节有介绍。
下面lookup_symbol_attrs()函数和lookup_symbol_name()函数也类似:
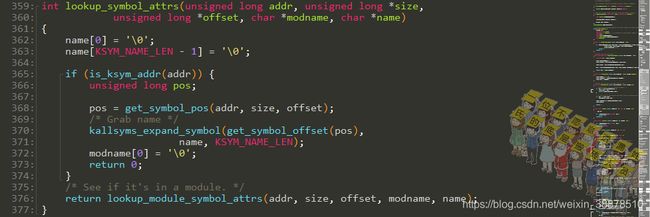
根据地址获取符号名字:
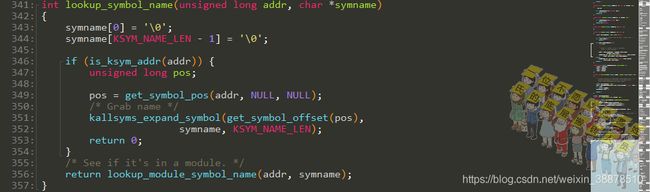
kallsyms_lookup_name()根据输入的名字查看符号地址
这只能是一个一个遍历过去,当前结构好像没有太好的办法。除非以每一个字符开始的起始位置进行一个记录,然后这样可以稍微节省一点时间。

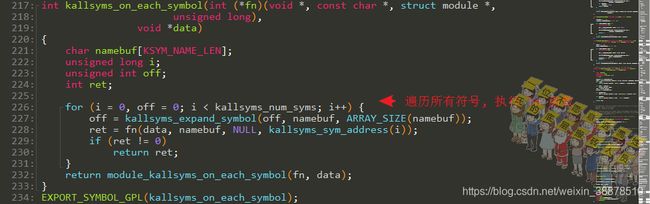
遍历所有符号执行某些动作
遍历,执行。
判断地址是否在符号表中
这个就是简单判断这个地址属不属于符号表中。