SQL:开窗函数(窗口函数)
4、 窗口函数
目录
-
- 4、 窗口函数
-
- 4.1 排序窗口函数rank
- 4.2 rank(), dense_rank(), row_number()区别
- 4.3 、排序截取数据lag(),lead(),ntile(),cume_dist()
- 4.4 聚合函数作为窗口函数
- 4.4、over(- - rows between and )
- 简单理解,就是对查询的结果多出一列,这一列可以是聚合值,也可以是排序值。
- 开窗函数一般就是说的是over()函数,其窗口是由一个 OVER 子句 定义的多行记录
- 开窗函数一般分为两类,聚合开窗函数和排序开窗函数。
简单来说,窗口函数有以下功能:
- 1)同时具有分组和排序的功能
- 2)不减少原表的行数
- 3)语法如下:
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名> [rows between ?? and ???])
<窗口函数>的位置,可以放以下两种函数:
- 1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
- 2) 聚合函数,如sum(). avg(), count(), max(), min()等,rows between…and…
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
3)业务需求“在每组内排名”,比如:
排名问题:每个部门按业绩来排名
topN问题:找出每个部门排名前N的员工进行奖励
4.1 排序窗口函数rank
-- 如果我们想在每个班级内按成绩排名,得到下面的结果。
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking
from 班级表;
我们来解释下这个sql语句里的select子句。rank是排序的函数。要求是“每个班级内按成绩排名”,这句话可以分为两部分:
-
1)每个班级内:按班级分组
partition by用来对表分组。在这个例子中,所以我们指定了按“班级”分组(partition by 班级)
-
2)按成绩排名
order by子句的功能是对分组后的结果进行排序,默认是按照升序(asc)排列。在本例中(order by 成绩 desc)是按成绩这一列排序,加了desc关键词表示降序排列。
通过下图,我们就可以理解partiition by(分组)和order by(在组内排序)的作用了。
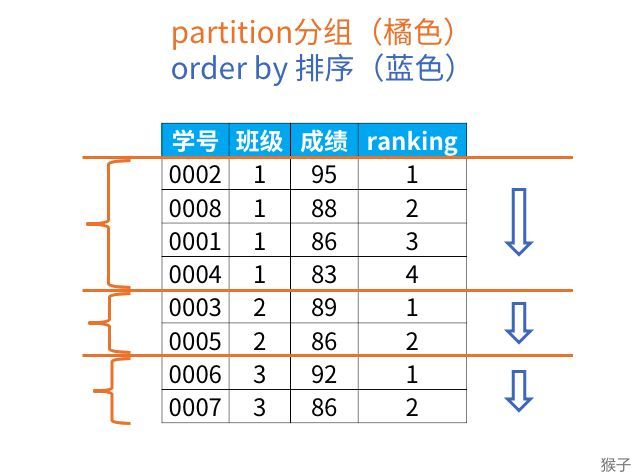
group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数。

注意事项:
-
partition子句可是省略,省略就是不指定分组,只是按成绩由高到低进行了排序。但是,这就失去了窗口函数的功能,所以一般不要这么使用。
-
窗口函数原则上只能写在select子句中
4.2 rank(), dense_rank(), row_number()区别
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级表
得到结果:

从上面的结果可以看出:
rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
4.3 、排序截取数据lag(),lead(),ntile(),cume_dist()
- LAG(col,n,default_val):获取往前第n行数据,col是列名,n是往上的行数,当第n行为null的时候取default_val
- LEAD(col,n, default_val):往后第n行数据,col是列名,n是往下的行数,当第n行为null的时候取default_val
- NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。
- cume_dist(),计算某个窗口或分区中某个值的累积分布。假定升序排序,则使用以下公式确定累积分布:
- 小于等于当前值x的行数 / 窗口或partition分区内的总行数。其中,x 等于 order by 子句中指定的列的当前行中的值。
4.4 聚合函数作为窗口函数
聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
我们来看一下窗口函数是聚合函数时,会出来什么结果:
select *,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表
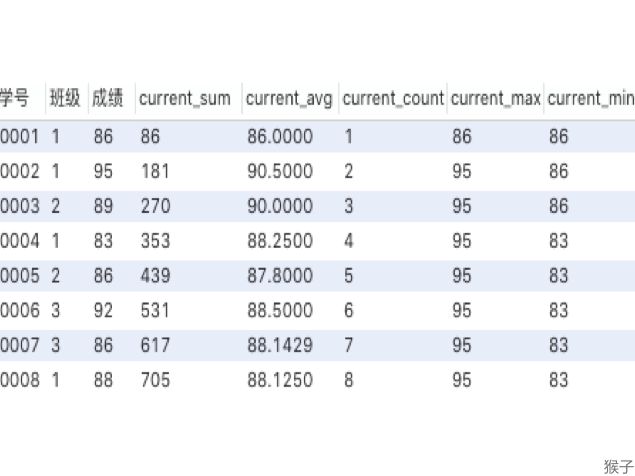
如上图,聚合函数sum在窗口函数中,是对自身记录、及位于自身记录以上的数据进行求和的结果。比如0004号,在使用sum窗口函数后的结果,是对0001,0002,0003,0004号的成绩求和,若是0005号,则结果是0001号~0005号成绩的求和,以此类推。
不仅是sum求和,平均、计数、最大最小值,也是同理,都是针对自身记录、以及自身记录之上的所有数据进行计算,
这样使用窗口函数有什么用呢?
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
4.4、over(- - rows between and )
sum()/... over ([partition by 列名] [order by 列名] [rows between ... and ...] )
-- 从起点到当前行数据聚合
between unbounded preceding and current row
-- 往前2行到往后1行的数据聚合
between 2 preceding and 1 following
- rows必须跟在Order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量。
- OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
- CURRENT ROW:当前行
- n PRECEDING:往前n行数据
- n FOLLOWING:往后n行数据
- UNBOUNDED:起点,unbounded preceding 表示从表数据的起点, unbounded following表示到后面的终点
select name,subject,score,
sum(score) over() as sum1,
sum(score) over(partition by subject) as sum2,
sum(score) over(partition by subject order by score) as sum3,
-- 由起点到当前行的窗口聚合,和sum3一样
sum(score) over(partition by subject order by score rows between unbounded preceding and current row) as sum4,
-- 当前行和前面一行的窗口聚合
sum(score) over(partition by subject order by score rows between 1 preceding and current row) as sum5,
-- 当前行的前面一行和后面一行的窗口聚合
sum(score) over(partition by subject order by score rows between 1 preceding AND 1 following) as sum6,
-- 当前和后面所有的行
sum(score) over(partition by subject order by score rows between current row and unbounded following) as sum7
from t_fraction;
+-------+----------+--------+-------+-------+-------+-------+-------+-------+-------+
| name | subject | score | sum1 | sum2 | sum3 | sum4 | sum5 | sum6 | sum7 |
+-------+----------+--------+-------+-------+-------+-------+-------+-------+-------+
| 孙悟空 | 数学 | 12 | 359 | 185 | 12 | 12 | 12 | 31 | 185 |
| 沙悟净 | 数学 | 19 | 359 | 185 | 31 | 31 | 31 | 104 | 173 |
| 猪八戒 | 数学 | 73 | 359 | 185 | 104 | 104 | 92 | 173 | 154 |
| 唐玄奘 | 数学 | 81 | 359 | 185 | 185 | 185 | 154 | 154 | 81 |
| 猪八戒 | 英语 | 11 | 359 | 80 | 11 | 11 | 11 | 26 | 80 |
| 孙悟空 | 英语 | 15 | 359 | 80 | 26 | 26 | 26 | 49 | 69 |
| 唐玄奘 | 英语 | 23 | 359 | 80 | 49 | 49 | 38 | 69 | 54 |
| 沙悟净 | 英语 | 31 | 359 | 80 | 80 | 80 | 54 | 54 | 31 |
| 孙悟空 | 语文 | 10 | 359 | 94 | 10 | 10 | 10 | 31 | 94 |
| 唐玄奘 | 语文 | 21 | 359 | 94 | 31 | 31 | 31 | 53 | 84 |
| 沙悟净 | 语文 | 22 | 359 | 94 | 53 | 53 | 43 | 84 | 63 |
| 猪八戒 | 语文 | 41 | 359 | 94 | 94 | 94 | 63 | 63 | 41 |
+-------+----------+--------+-------+-------+-------+-------+-------+-------+-------+