深度学习之生成对抗网络
一、基本原理
生成对抗网络有一个生成器(Generator,简称G)生成数据和一个鉴别器(Discriminator,简称D)鉴别数据是否与真实数据相似。GAN是半监督学习方式训练的模型,基于神经网络,经常被用在图像处理和半监督学习领域。
生成器作用D:生成和真实数据几乎没有差距的数据
鉴别器的作用G:尽最大努力区分生成器生成的数据和真实数据
训练一个生成器(Generator,简称G),从随机噪声或者潜在变量(Latent Variable)中生成逼真的的样本,同时训练一个鉴别器(Discriminator,简称D)来鉴别真实数据和生成数据,两者同时训练,直到达到一个纳什均衡,生成器生成的数据与真实样本无差别,鉴别器也无法正确的区分生成数据和真实数据.其基本架构如下:
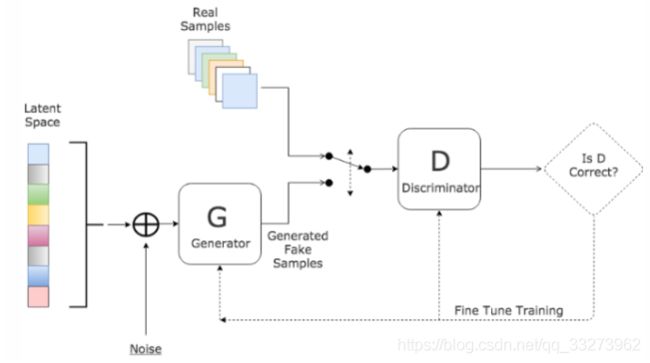
用数学语言描述整个博弈过程的话,就是:假设我们的生成模型是g(z),其中z是一个随机噪声,而g将这个随机噪声转化为数据类型x,拿图片问题举例,这里g的输出就是一张图片。D是一个判别模型,对任何输入x,D(x)的输出是0-1范围内的一个实数,用来判断这个图片是一个真实图片的概率是多大。
二、公式推导
令Pdata和Pz分别代表真实图像的分布与生成图像的分布,我们判别模型D的目标函数如下:
![]()
类似的生成模型的目标是让判别模型无法区分真实图片与生成图片,生成模型G的目标函数如下:
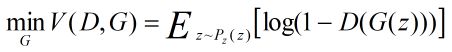
最终目标公式为:
![]()
这里我们对优化公式加以解释: 可以看到,优化D的时候,也就是判别网络,其实没有生成网络什么事,后面的G(z)这里就相当于已经得到的假样本。优化D的公式的第一项,使的真样本x输入的时候,得到的结果越大越好,可以理解,因为需要真样本的预测结果越接近于1越好。对于假样本,需要优化是的其结果越小越好,也就是D(G(z))越小越好,因为它的标签为0。但是第一项是越大,第二项是越小,这不矛盾了,所以呢把第二项改成1-D(G(z)),这样就是越大越好,两者合起来就是越大越好。 那么同样在优化G的时候,这个时候没有真样本什么事,所以把第一项直接却掉了。这个时候只有假样本,但是我们说这个时候是希望假样本的标签是1的,所以是D(G(z))越大越好,但是呢为了统一成1-D(G(z))的形式,那么只能是最小化1-D(G(z)),本质上没有区别,只是为了形式的统一。之后这两个优化模型可以合并起来写,就变成了最开始的那个最大最小目标函数了。
三、训练步骤
我们优化改目标函数是分别对D和g进行交互迭代,固定g,优化D,一段时间后再固定D优化g,直到收敛为止。具体步骤如下:
第1步:定义问题。你想生成假的图像还是文字?你需要完全定义问题并收集数据。
第2步:定义GAN的架构。GAN看起来是怎么样的,生成器和鉴别器应该是多层感知器还是卷积神经网络?这一步取决于你要解决的问题。
第3步:用真实数据训练鉴别器N个epoch。训练鉴别器正确预测真实数据为真。这里N可以设置为1到无穷大之间的任意自然数。
第4步:用生成器产生假的输入数据,用来训练鉴别器。训练鉴别器正确预测假的数据为假。
第5步:用鉴别器的出入训练生成器。当鉴别器被训练后,将其预测值作为标记来训练生成器。训练生成器来迷惑鉴别器。
第6步:重复第3到第5步多个epoch
第7步:手动检查假数据是否合理。如果看起来合适就停止训练,否则回到第3步。这是一个手动任务,手动评估数据是检查其假冒程度的最佳方式。当这个步骤结束时,就可以评估GAN是否表现良好。
四、应用——DCGAN(Deep convolutional NN for GAN)
这里简单讲解DCGAN在图像中的应用。在深度学习中,CNN是对图像分类建模,刻画图像不同层次,抽象信息表达的最有效的模型。在我们画画的时候,通常先考虑构图,然后画轮廓,再画细节,最后填充颜色,这是一个多层级的过程,也就是把图像理解的过程反过来,所以我们在生成图像时,可以运用一种类似反卷积的结构,如下图所示:
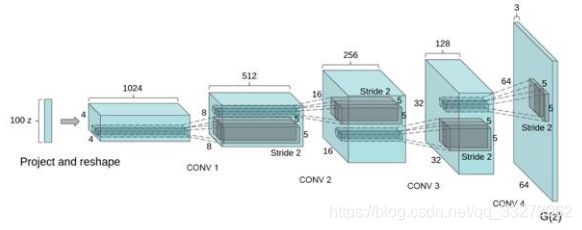
DCGAN采用一个随机噪声向量作为输入,如高斯噪声。输入通过与CNN类似但是相反的结构,将输入放大成二维数据。通过采用这种结构的生成模型和CNN结构的判别模型,DCGAN在图片生成上可以达到相当可观的效果。如下是一些生成的案例照片。

参考:
https://www.msra.cn/zh-cn/news/features/gan-20170511
https://www.zhihu.com/question/56171002
https://www.jianshu.com/p/1937d92be71e
https://blog.csdn.net/liuweizj12/article/details/73741434