R语言常用基本函数,含实例:万字总结
目录
vector:创建向量(默认填充0,空字符,FALSE)
data.frame :可以看作由多个向量组成的表格,每个向量代表表格的一列数据
sequence:创建序列(可以简写为seq)
dim:获取矩阵或数组的维度信息
length
subset:从数据框和向量中提取子集
list
unlist:将列表转换为向量
排序(sort,order,unique,rev)
attr:获取或设置对象的特定属性
attributes:获取或设置对象的所有属性
typeof:获取给定对象的数据类型的函数
names:获取或设置对象的名称
nchar:计算字符向量或字符串的长度
substr: 从字符串中提取子串
format: 格式化数值
formatC: 格式化数值,并将其转换为字符型向量
paste: 将多个对象拼接成一个字符向量的函数
sapply:用于应用函数到向量、列表或数据框的便捷工具函数
strsplit:根据指定的分隔符将一个字符串对象拆分成多个子字符串,并返回一个包含拆分结果的列表或字符向量
charmatch:在向量或矩阵中查找匹配的字符,它返回一个表示匹配位置的整数向量
pmatch: 在向量或矩阵中进行部分匹配
grep:用于在字符向量中查找模式(pattern)匹配的元素,并返回匹配的位置或索引
sub:替换字符串中第一个匹配项的函数
gsub:用于替换字符串中所有匹配项的函数
复数
factor:因子是一种用于表示分类数据的数据类型,它将离散的取值映射为有序或无序的级别
nlevels:获取因子(factor)对象的级别数量
codes:因子的编码
cut:对数值变量进行划分时,可以根据不同的需求选择不同的参数配置
table:获取划分后每个区间的计数
split:根据指定的因子或向量来拆分数据框、列表或向量
aggregate:按照指定的因子或条件对数据进行聚合计算
tapply:根据指定的因子或条件对数据进行分组并应用于每个组的函数
vector:创建向量(默认填充0,空字符,FALSE)
vector(mode, length)
mode:指定向量的数据类型,例如 "numeric"(数值型),"character"(字符型),"logical"(逻辑型)等。length:指定向量的长度,即元素的个数。
(1)创建一个包含整数类型的向量:
# 创建一个包含5个整数的向量
my_vector <- vector("integer", 5)
print(my_vector)
结果
[1] 0 0 0 0 0
(2)创建一个字符型向量:
# 创建包含字符元素的向量
my_vector <- vector("character", 3)
print(my_vector)
结果
[1] " " " " " "
(3) 创建一个逻辑型向量:
# 创建包含逻辑元素的向量
my_vector <- vector("logical", 4)
print(my_vector)
结果
[1] FALSE FALSE FALSE FALSE
(4)直接创建向量
# 创建一个数值型向量
my_vector <- c(1, 2, 3, 4, 5)
print(my_vector)
结果
[1] 1 2 3 4 5
data.frame :可以看作由多个向量组成的表格,每个向量代表表格的一列数据
(1) 创建一个包含姓名和年龄的data.frame
name <- c("Alice", "Bob", "Charlie")
age <- c(25, 30, 35)
my_df <- data.frame(Name = name, Age = age)
print(my_df)
结果
Name Age
1 Alice 25
2 Bob 30
3 Charlie 35
(2)访问列数据
# 访问列数据
print(my_df$Name) # 打印Name列的数据
print(my_df$Age) # 打印Age列的数据
结果
[1] Alice Bob Charlie
[1] 26 31 36
(3)修改列数据
my_df$Age <- c(26, 31, 36) # 将Age列的数据修改为新的值
print(my_df)
结果
Name Age
1 Alice 26
2 Bob 31
3 Charlie 36
sequence:创建序列(可以简写为seq)
(1)生成1~10的序列
seq <- sequence(10)
print(seq)
结果
[1] 1 2 3 4 5 6 7 8 9 10
(2)生成10~1的递减序列
seq <- sequence(10, from = 10, to = 1, by = -1)
#from是起始数字,to是结尾数字,by表示递增或递减的步长
print(seq)
结果
[1] 10 9 8 7 6 5 4 3 2 1
(3)生成步长为2的从1到10的序列
seq <- sequence(5, from = 1, by = 2)
print(seq)
结果
[1] 1 3 5 7 9
(4)创建一个重复的序列:
结果
[1] 1 1 2 2 3
dim:获取矩阵或数组的维度信息
(1)获取矩阵的维度
mat <- matrix(1:6, nrow = 2)
#列出1~6数值的矩阵,矩阵的行数为2
dims <- dim(mat)
print(dims)
#补充
sub_mat <- mat[1:2, ]
print(sub_mat)
[1] 2 3
#补充
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
(2)获取数组维度
#1
arr <- array(1:12, dim = c(2, 3, 2))
print(arr)
#2
dims <- dim(arr)
print(dims)
结果1
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12结果2
[1] 2 3 2
length
(1)计算向量的长度
vec <- c(1, 2, 3, 4, 5)
len <- length(vec)
print(len)
[1] 5
(2)计算列表的长度:
lst <- list("apple", "banana", "orange")
len <- length(lst)
print(len)
[1] 3
(3) 计算数组的长度:
arr <- array(1:12, dim = c(2, 3, 2))
#
len <- length(arr)
print(len)
[1] 12
subset:从数据框和向量中提取子集
(1)从数据框中提取符合条件的子集:
# 创建一个数据框
df <- data.frame(Name = c("Alice", "Bob", "Charlie"),
Age = c(25, 30, 35),
Gender = c("Female", "Male", "Male"))
# 提取年龄大于等于30岁的子集
subset_df <- subset(df, Age >= 30)
print(subset_df)
Name Age Gender
2 Bob 30 Male
3 Charlie 35 Male
(2)从向量中提取符合条件的子集:
# 创建一个向量
vec <- c(10, 5, 8, 3, 6)
# 提取大于等于5的元素
subset_vec <- subset(vec, vec >= 5)
print(subset_vec)
[1] 10 5 8 6
list
(1)创建一个包含多个元素的列表:
# 创建一个列表
my_list <- list("Alice", 25, c(1, 2, 3), TRUE)
# 打印列表
print(my_list)
[[1]]
[1] "Alice"[[2]]
[1] 25[[3]]
[1] 1 2 3[[4]]
[1] TRUE
(2)访问和操作列表中的元素
# 访问列表中的元素
name <- my_list[[1]]
age <- my_list[[2]]
numbers <- my_list[[3]]
is_true <- my_list[[4]]
# 打印提取的元素
print(name)
print(age)
print(numbers)
print(is_true)
[1] "Alice"
[1] 25
[1] 1 2 3
[1] TRUE
(3)向列表中添加元素
# 添加新元素到列表中
my_list[[5]] <- "New element"
# 打印更新后的列表
print(my_list)
[[1]]
[1] "Alice"[[2]]
[1] 25[[3]]
[1] 1 2 3[[4]]
[1] TRUE[[5]]
[1] "New element"
unlist:将列表转换为向量
my_list <- list(a = 1, b = 2, c = 3)
my_vector <- unlist(my_list)
#经过 unlist() 转换后得到了向量 {1, 2, 3}
#其中元素的名称分别为 "a"、"b" 和 "c"
print(my_vector)
a b c
1 2 3
排序(sort,order,unique,rev)
(1)sort:对向量或数据框的元素进行升序排序
# 对向量进行排序
x <- c(5, 2, 8, 3, 1)
sorted_x <- sort(x)
# 打印排序后的向量
print(sorted_x)
[1] 1 2 3 5 8
(2)order: 返回按照给定向量排序的索引(默认升序)
# 获取按照向量排序的索引
x <- c(5, 2, 8, 3, 1)
sorted_index <- order(x)
# 打印排序后的索引
print(sorted_index)
[1] 5 2 4 1 3
索引1表示的是排序最小的值,也就是1,1的位置在第5个,所以显示5,以此类推
如果想结果降序排列,有下面两种写法
#1
x <- c(5, 2, 8, 3, 1)
sorted_index <- order(x, decreasing = TRUE)
print(sorted_index)
#2
x <- c(5, 2, 8, 3, 1)
sorted_index <- order(-x)
print(sorted_index)
[1] 3 1 4 2 5
(3) unique:用于提取向量中的唯一值
# 提取向量中的唯一值
x <- c(2, 1, 3, 2, 1, 4)
unique_values <- unique(x)
# 打印唯一值
print(unique_values)
[1] 2 1 3 4
(4)rev:将向量或列表倒序排列
# 将向量倒序排列
x <- c(1, 2, 3, 4, 5)
reversed_x <- rev(x)
# 打印倒序排列后的向量
print(reversed_x)
[1] 1 3 8 2 5
attr:获取或设置对象的特定属性
(1)设置对象属性
my_vector <- c(1, 2, 3)
attr(my_vector, "description") <- "This is a vector of numbers"
(2)获取对象属性
my_matrix <- matrix(1:9, nrow = 3)
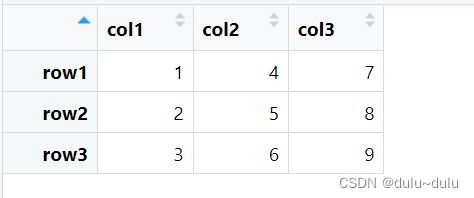
attr(my_matrix, "dimnames") <- list(c("row1", "row2", "row3"), c("col1", "col2", "col3"))
dims <- attr(my_matrix, "dimnames")
print(dims)[[1]] [1] "row1" "row2" "row3" [[2]] [1] "col1" "col2" "col3"
my_matrix如图所示
attributes:获取或设置对象的所有属性
my_vector <- c(1, 2, 3)
attr(my_vector, "description") <- "This is a vector of numbers"
attr(my_vector, "author") <- "John Doe"
all_attributes <- attributes(my_vector)
print(all_attributes)
$description
[1] "This is a vector of numbers"$author
[1] "John Doe"
typeof:获取给定对象的数据类型的函数
(1)向量的数据类型
my_vector <- c(1, 2, 3)
type <- typeof(my_vector)
print(type)
[1] "double"
(2)矩阵的数据类型
my_matrix <- matrix(1:9, nrow = 3)
type <- typeof(my_matrix)
print(type)
[1] "integer"
(3) 字符型数据的数据类型
my_string <- "Hello, World!"
type <- typeof(my_string)
print(type)
[1] "character"
names:获取或设置对象的名称
(1)向量的名称
my_vector <- c(1, 2, 3)
names(my_vector) <- c("a", "b", "c")
print(names(my_vector))
[1] "a" "b" "c"
(2) 列表的名称
my_list <- list(a = 1, b = 2, c = 3)
print(names(my_list))
[1] "a" "b" "c"
(3) 数据框的名称
my_df <- data.frame(x = c(1, 2, 3), y = c(4, 5, 6))
print(names(my_df))
[1] "x" "y"
(4)设置对象名称
my_vector <- c(1, 2, 3)
names(my_vector) <- c("a", "b", "c")
#my_vector 的元素分别设置名称 "a"、"b" 和 "c"nchar:计算字符向量或字符串的长度
my_string <- "Hello, world!"
length <- nchar(my_string)
print(length)[1] 13
substr: 从字符串中提取子串
(1)提取子串
my_string <- "Hello, world!"
substring <- substr(my_string, start = 1, stop = 5)
print(substring)[1] "Hello"
(2)使用负数来指定相对于字符串末尾的位置
my_string <- "Hello, world!"
substring <- substr(my_string, start = -3, stop = -1)
print(substring)
[1] "rld"
format: 格式化数值
x <- 12345.6789
formatted <- format(x, big.mark = ",", decimal.mark = ".", nsmall = 2)
print(formatted)[1] "12,345.68"参数:
nsmall:一个整数参数,用于指定保留的小数位数。
scientific:一个逻辑值参数,用于控制是否使用科学计数法来表示数值。如果设置为TRUE,则使用科学记数法;如果设置为FALSE,则不使用科学计数法。
big.mark:一个字符型参数,用于指定千位分隔符号的显示方式。默认情况下,R 使用逗号,作为千位分隔符号。
decimal.mark:一个字符型参数,用于指定小数部分的小数点符号。默认情况下,R 使用小数点.作为小数点符号。
trim:一个逻辑值参数,用于控制是否删除尾部多余的零。如果设置为TRUE,则删除尾部多余的零;如果设置为FALSE,则保留所有小数位数。
formatC: 格式化数值,并将其转换为字符型向量
x <- 12345.6789
formatted <- formatC(x, format = "f", digits = 2)
print(formatted)[1] "12345.68"参数:
x:要格式化的数据对象,可以是单个数字、向量或矩阵。
format:一个字符型参数,用于指定格式的字符串。你可以使用不同的占位符来表示各种格式,例如%d表示整数、%f表示浮点数、%e表示科学计数法、%s表示字符型等。
digits:一个整数参数,用于指定保留的小数位数。当格式为浮点数时,通过设置digits参数可以控制小数位数。
width:一个整数参数,用于指定输出字符的总宽度。如果设定了width参数,且输出字符的长度不足width,则会在左侧填充空格以达到指定的宽度。
flag:一个字符型参数,用于设置特殊标志。例如,`flag = "#"`` 可以在八进制数格式化时添加前缀 "0",在十六进制数格式化时添加前缀 "0x"。
paste: 将多个对象拼接成一个字符向量的函数
# 示例 1:拼接两个向量
x <- c("Hello", "world")
y <- c("How", "are", "you?")
result <- paste(x, y)
print(result)
# 输出: "Hello How" "world are" " you?"
# 示例 2:指定分隔符
result <- paste(x, y, sep = "-")
print(result)
# 输出: "Hello-How" "world-are" "you?"
# 示例 3:折叠拼接结果
result <- paste(x, y, collapse = " ")
print(result)
# 输出: "Hello world How are you?"
#collapse 参数设置为空字符串,这样多个对象就会按照空格分隔并拼接成一个字符串。
sapply:用于应用函数到向量、列表或数据框的便捷工具函数
# 创建一个数字向量
numbers <- c(1, 2, 3, 4, 5)
# 使用sapply计算每个数字的平方
squared_numbers <- sapply(numbers, function(x) x^2)
# 输出结果
print(squared_numbers)
[1] 1 4 9 16 25
strsplit:根据指定的分隔符将一个字符串对象拆分成多个子字符串,并返回一个包含拆分结果的列表或字符向量
str <- "Hello,world,how,are,you?"
result <- strsplit(str, split = ",")
print(result)
[[1]]
[1] "Hello" "world" "how" "are" "you?"
获取第一个拆分结果
str <- "apple,banana,carrot|dog,cat,rabbit|red,green,blue"
results <- strsplit(str, split = "\\|")
print(results)
first_elements <- sapply(results, function(x) x[[1]])
#返回子列表的第一个元素
print(first_elements)[[1]] [1] "apple,banana,carrot" [2] "dog,cat,rabbit" [3] "red,green,blue"[1] "apple,banana,carrot"
charmatch:在向量或矩阵中查找匹配的字符,它返回一个表示匹配位置的整数向量
charmatch(target, x, nomatch = NA)
target是要查找的目标字符向量。x是被搜索的字符向量。nomatch是当无法找到匹配时要返回的值,默认为NA。
# 创建一个字符向量
fruits <- c("apple", "banana", "orange", "mango")
# 使用charmatch查找元素的位置
match_index <- charmatch("banana", fruits)
# 输出结果
print(match_index)
[1] 2
如果要查找的元素不在字符向量中
# 使用charmatch查找不存在的元素的位置
match_index <- charmatch("grape", fruits, nomatch = 0)
# 输出结果
print(match_index)
[1] 0
模糊匹配
使用==运算符进行模糊匹配:
fruits <- c("apple", "banana", "orange", "mango")
target <- "banana"
# 循环遍历字符向量并进行模糊匹配
matches <- c()
for (i in 1:length(fruits)) {
if (target == fruits[i]) {
matches <- c(matches, i)
}
}
print(fruits[matches])
[1] "banana"
如果是
> target <- "banaba"character(0)
使用%in%运算符进行模糊匹配:
fruits <- c("apple", "banana", "orange", "mango")
target <- c("banaba", "apple")
# 使用向量化操作进行模糊匹配
matches <- fruits %in% target
print(fruits[matches])
[1] "apple"
fruits <- c("apple", "banana", "orange", "mango")
target <- c("banana", "apple")
# 使用向量化操作进行模糊匹配
matches <- fruits %in% target
print(fruits[matches])
[1] "apple" "banana"
pmatch: 在向量或矩阵中进行部分匹配
pmatch(target, vector, duplicates.ok = FALSE)
target:要查找的模式或目标项。vector:要在其中进行匹配的向量或矩阵。duplicates.ok:一个逻辑值,表示是否允许多个匹配项。默认为FALSE,即只返回第一个匹配项的索引。如果设置了duplicates.ok = TRUE,则会返回所有匹配项的索引。
fruits <- c("apple", "banana", "orange", "mango")
target <- "ban"
matches <- pmatch(target, fruits)
print(matches)
[1] 2
fruits <- c("apple", "banana", "orange", "mango")
target <- "pp"
matches <- pmatch(target, fruits)
print(matches)
[1] NA
grep:用于在字符向量中查找模式(pattern)匹配的元素,并返回匹配的位置或索引
grep(pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE, fixed = FALSE, ...)
pattern:要匹配的模式,可以是一个正则表达式或简单的字符模式。x:要在其中进行搜索的向量、列表或数据框。ignore.case:一个逻辑值,表示是否忽略大小写。默认为FALSE。perl:一个逻辑值,表示是否使用Perl正则表达式。默认为FALSE。value:一个逻辑值,表示是否返回匹配的元素本身而不是索引位置。默认为FALSE。fixed:一个逻辑值,表示是否将pattern视为字面字符串而不是正则表达式。默认为FALSE。
fruits <- c("apple", "banana", "orange", "mango")
# 返回包含"an"的元素的索引位置
matches <- grep("an", fruits)
print(matches)
# 输出: [1] 1 2
# 返回以字母"a"开头的元素的索引位置
matches_start_with_a <- grep("^a", fruits)
print(matches_start_with_a)
# 输出: [1] 1
# 返回包含字母"o"或"e"的元素的索引位置
matches_o_or_e <- grep("[oe]", fruits)
print(matches_o_or_e)
# 输出: [1] 1 3 4
# 返回与正则表达式匹配的元素本身
matching_elements <- grep("an", fruits, value = TRUE)
print(matching_elements)
# 输出: [1] "apple" "banana"
# 忽略大小写进行匹配
ignore_case_matches <- grep("O", fruits, ignore.case = TRUE)
print(ignore_case_matches)
# 输出: [1] 3
sub:替换字符串中第一个匹配项的函数
sub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE, fixed = FALSE, ...)
pattern:要匹配的模式,可以是一个正则表达式或简单的字符模式。replacement:要替换匹配项的字符串。x:要在其中进行替换的向量、列表或数据框。ignore.case:一个逻辑值,表示是否忽略大小写。默认为FALSE。perl:一个逻辑值,表示是否使用Perl正则表达式。默认为FALSE。fixed:一个逻辑值,表示是否将pattern视为字面字符串而不是正则表达式。默认为FALSE。
fruit <- "banana"
# 将第一个匹配的"a"替换为"o"
replaced <- sub("a", "o", fruit)
print(replaced)
# 输出: [1] "bonana"
# 忽略大小写进行替换
ignore_case_replaced <- sub("A", "o", fruit, ignore.case = TRUE)
print(ignore_case_replaced)
# 输出: [1] "bonana"
# 将数字替换为空字符串
numbers <- c("value1", "value2", "value3")
numbers_replaced <- sub("[0-9]", "", numbers)
print(numbers_replaced)
# 输出: [1] "value" "value2" "value3"
gsub:用于替换字符串中所有匹配项的函数
gsub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE, fixed = FALSE, ...)
pattern:要匹配的模式,可以是一个正则表达式或简单的字符模式。replacement:要替换匹配项的字符串。x:要在其中进行替换的向量、列表或数据框。ignore.case:一个逻辑值,表示是否忽略大小写。默认为FALSE。perl:一个逻辑值,表示是否使用Perl正则表达式。默认为FALSE。fixed:一个逻辑值,表示是否将pattern视为字面字符串而不是正则表达式。默认为FALSE。...:其他传递给正则表达式替换函数的参数。
fruit <- "banana"
# 将所有匹配的"a"替换为"o"
replaced <- gsub("a", "o", fruit)
print(replaced)
# 输出: [1] "bonono"
# 忽略大小写进行替换
ignore_case_replaced <- gsub("A", "o", fruit, ignore.case = TRUE)
print(ignore_case_replaced)
# 输出: [1] "bonono"
# 将所有数字替换为空字符串
numbers <- c("value1", "value2", "value3")
numbers_replaced <- gsub("[0-9]", "", numbers)
print(numbers_replaced)
# 输出: [1] "value" "value" "value"
复数
(1)complex():创建一个复数。它接受两个参数,分别是实部和虚部
# 创建复数:2 + 3i
z <- complex(real = 2, imaginary = 3)
print(z)
# 输出: [1] 2+3i
(2)Re():返回复数的实部
# 获取复数的实部
real_part <- Re(z)
print(real_part)
# 输出: [1] 2
(3)Im():返回复数的虚部
# 获取复数的虚部
imaginary_part <- Im(z)
print(imaginary_part)
# 输出: [1] 3
(4)Mod():返回复数的模(绝对值)
# 获取复数的模
modulus <- Mod(z)
print(modulus)
# 输出: [1] 3.605551
(5)Arg():返回复数的辐角
# 获取复数的辐角
argument <- Arg(z)
print(argument)
# 输出: [1] 0.9827937
(6)Conj():返回复数的共轭
# 获取复数的共轭
conjugate <- Conj(z)
print(conjugate)
# 输出: [1] 2-3i
factor:因子是一种用于表示分类数据的数据类型,它将离散的取值映射为有序或无序的级别
factor(x, levels, labels, ordered = FALSE)
x:要转换为因子的向量或因子(或其他对象)。levels:可选参数,指定因子的级别。它可以是一个字符向量或整数向量。如果没有指定级别,将使用唯一的x中的取值作为级别。labels:可选参数,指定因子的标签(用于表示每个级别的名字)。如果没有指定标签,将使用级别的字符串表示。ordered:一个逻辑值,表示是否创建有序因子。如果为TRUE,则表示级别之间存在顺序关系,默认为FALSE。
# 创建一个无序因子
x <- c("A", "B", "A", "C", "B")
f <- factor(x)
print(f)
labels <- levels(f)
print(labels)
# 输出: [1] A B A C B
# Levels: A B C
# 创建一个有序因子
y <- c("low", "medium", "high", "low", "high")
o <- factor(y, levels = c("low", "medium", "high"), ordered = TRUE)
print(o)
labels <- levels(o)
print(labels)
# 输出: [1] low medium high low high
# Levels: low < medium < high
# 指定标签的因子
z <- c("male", "female", "female", "male")
g <- factor(z, levels = c("male", "female"), labels = c("M", "F"))
print(g)
labels <- levels(g)
print(labels)
# 输出: [1] M F F M
# Levels: M F
#因子的各水平的名字,可以通过levels进行数据的分类和汇总分析nlevels:获取因子(factor)对象的级别数量
# 创建一个因子
x <- c("A", "B", "A", "C", "B")
f <- factor(x)
# 获取因子的级别数量
num_levels <- nlevels(f)
print(num_levels)
# 输出: 3
codes:因子的编码
# 创建一个因子
x <- c("A", "B", "A", "C", "B")
f <- factor(x)
# 获取因子的代码
codes <- as.integer(f)
print(codes)
# 输出: [1] 1 2 1 3 2
# 将代码转换回级别标签
labels <- labels(f)
print(labels)
# 输出: [1] "A" "B" "C"
注:as.integer:将数据转化为整型
# 将数值转换为整数
x <- 3.14
x_integer <- as.integer(x)
print(x_integer)
# 输出: 3
# 将逻辑值 TRUE 和 FALSE 转换为整数
logic_val <- TRUE
logic_val_integer <- as.integer(logic_val)
print(logic_val_integer)
# 输出: 1
logic_val <- FALSE
logic_val_integer <- as.integer(logic_val)
print(logic_val_integer)
# 输出: 0
# 将字符型转换为整数
text <- "123"
text_integer <- as.integer(text)
print(text_integer)
# 输出: 123
cut:对数值变量进行划分时,可以根据不同的需求选择不同的参数配置
(1)指定分割点
# 创建一个数值向量
x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
# 使用cut()函数将数值划分为三个离散的区间
cuts <- cut(x, breaks = c(0, 5, 8, 10))
print(cuts)
# 输出:
# [1] (0,5] (0,5] (0,5] (0,5] (0,5] (5,8] (5,8] (5,8] (8,10] (8,10]
# Levels: (0,5] (5,8] (8,10]
(2)指定区间数量
# 创建一个数值向量
x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
# 使用cut()函数将数值划分为五个离散的区间
cuts <- cut(x, breaks = 5)
print(cuts)
# 输出:
# [1] (0.992,2.8] (0.992,2.8] (0.992,2.8] (2.8,4.6] (4.6,6.4]
# [6] (6.4,8.2] (8.2,10] (8.2,10] (8.2,10] (8.2,10]
# Levels: (0.992,2.8] (2.8,4.6] (4.6,6.4] (6.4,8.2] (8.2,10]
table:获取划分后每个区间的计数
x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
cuts <- cut(x, breaks = 5)
table(cuts)

split:根据指定的因子或向量来拆分数据框、列表或向量
split(x, f, drop = FALSE, ...)
x:要拆分的对象,可以是数据框、列表或向量。f:用于拆分的因子或向量。drop:逻辑值,表示是否删除空的拆分组。默认为FALSE,即保留空的拆分组。
x <- c(1, 2, 3, 4, 5)
f <- c("A", "B", "A", "B", "A")
result <- split(x, f)
$A
[1] 1 3 5
$B
[1] 2 4
aggregate:按照指定的因子或条件对数据进行聚合计算
aggregate(formula, data, FUN, ...)
formula:用于指定聚合操作的公式,通常形式为y ~ x,其中y是要聚合的变量,x是用于分组的因子或变量。data:要进行聚合计算的数据框或列表。FUN:表示要应用的聚合函数。可以是内置的聚合函数(如sum、mean、max等),也可以是用户自定义的函数。
# 创建一个示例数据框
df <- data.frame(
group = c("A", "A", "B", "B", "A"),
value = c(1, 2, 3, 4, 5)
)
# 使用aggregate()函数计算每个组的平均值
result <- aggregate(value ~ group, data = df, FUN = mean)
print(result)

tapply:根据指定的因子或条件对数据进行分组并应用于每个组的函数
tapply(X, INDEX, FUN, ..., simplify = TRUE)
INDEX:表示分组的因子、列表或数组。FUN:要应用于每个组的函数,可以是内置的函数(如sum、mean、max等),也可以是用户自定义的函数。simplify:逻辑值,表示是否简化结果。默认为TRUE,即使用简化的结果。
# 创建示例向量
x <- c(1, 2, 3, 4, 5)
f <- c("A", "A", "B", "B", "A")
# 使用tapply()函数计算每个组的总和
result <- tapply(x, f, sum)
A B
8 7
整理不易,如有错误或遗漏,请大佬们不吝赐教!!